

Linux shell 多线程开发以及模板使用,详细一文透彻
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Linux shell 多线程开发以及模板使用
序
在日常工作中通常是起一个终端通过 shell 连接我们的跳板机服务器为此服务器提供一个进程供我们使用。但我们通常都是一条一条命令的运行在某些需要并发的场景时就显得捉襟见肘。所以在大数据中必须要学会 shell 的多线程操作这样能够极大的提升某些重复可并发的任务的时间。
模板
先扔出模板供大家参考
#!/bin/bash
# Copyright◎2022, Maggot. All rights reserved.
#
# This program is about concurrent program.
# Date: 2023-1-14
# Auth: huangyichun
# Version: 0.1
max_multithreading=5
[ -e /tmp/fd1_hyc ] || mkfifo /tmp/fd1_hyc
exec 3<>/tmp/fd1_hyc
rm -rf /tmp/fd1_hyc
for ((i=1;i<=$max_multithreading;i++))
do
echo >&3
done
for loop in {1..10}
do
read -u3
{
# do something like:
echo now ${loop} is running
sleep 3s
echo now ${loop} is done
# &3 ++
echo >&3
} &
done
wait
echo all tasks done
exec 3>&-
bash loop.sh
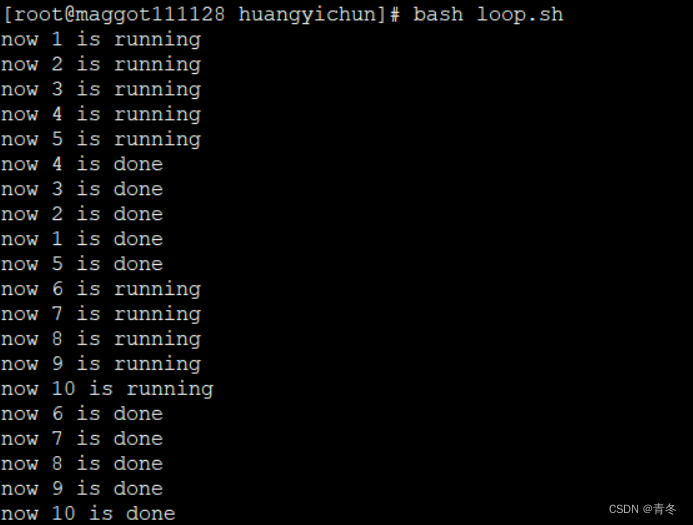
可以看到我们的打印是像是有批次似的每批次 5 个一起打印。
代码分析
&
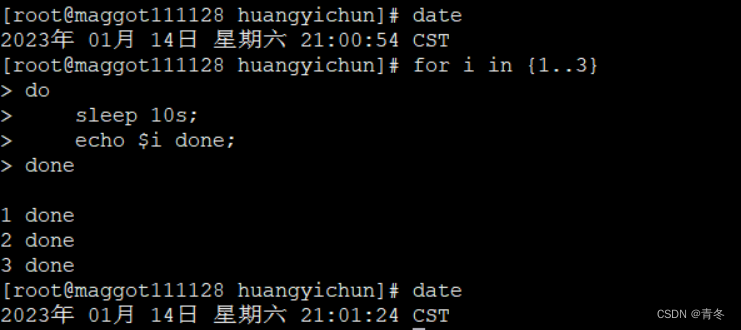
& 符号在 shell 中代表将该行的命令放入后台执行比如下述程序为线性执行循环 sleep 10s 三次那么需要 30 秒才能运行完毕
date
for i in {1..3}
do
sleep 10s;
echo $i done;
done
date
如果我们在循环主体中使用 &那么可以将整个代码块放入后台开新的子线程运行
date
for i in {1..3}
do
{
sleep 10s;
echo $i done;
} &
done
date
jobs # 查看后台任务
pstree -ah $$ # 使用 pstree 打印当前线程树如果命令不存在可以使用 yum -y install psmisc 进行安装
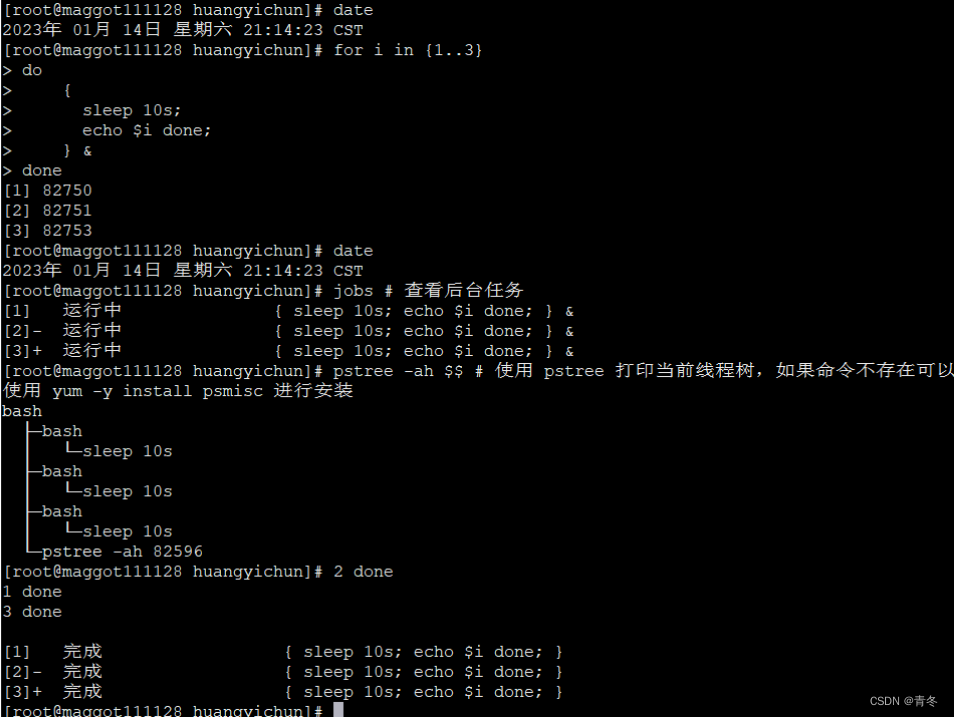
我们使用 {} 将循环主体进行包裹这样整个 {……} 内容变成了一个代码块然后使用 & 将整个代码块都在子进程中运行。那么我们主进程将会继续运行打印时间等其他信息。
我们使用 jobs 查看了后台的任务并且使用 pstree 命令打印了当前进程的进程树可以看到有三个 bash sleep 挂在我们当前进程之下。等待 10 秒后三个打印的任务同时完成并且还有类似 [1]、[2]、[3] 的标识打印完成。
很明显这样已经可以实现 shell 的多线程处理任务了但有个小问题在 java 中线程池一定是有上限的这样我们才能控制一个任务的最大并发数。比如当前需要运行 10000 个任务我们不大可能直接启动 10000 个任务而是选择 20 的并发去运行程序所以还需要在 shell 中进行一个并发管控的方式。
令牌桶、管道 mkfifo
在流量控制中我们可以使用令牌桶进行流量管控。类似于在一个篮子中放入一定量的入门劵每个人来的时候先去获取入门券这样才能进入房间门。没有获得入门券的会一直尝试获取入门券然后才能进入。令牌桶也是这样在一个桶中不断产生令牌只有获取到令牌的才能够去请求资源。
那么在 shell 中有类似的吗有那便是管道也可以模拟类似的场景。我们一般使用 | 来创建一个无名管道管道符左边的输出会变成右边的输入当然这样使用是没有流量控制的。所以我们需要使用 mkfifo 来创建一个先进先出命名管道手动放入一些令牌数据然后需要运行的程序必须从管道中先获取令牌数据才能运行主题否则就等待。
因为管道中的数据只会被获取一次更有利于令牌桶的实现。
所以我们通过以下命令创建了一个先进先出管道
# 判断是否存在不存在时创建命令管道 fd1_hyc
[ -e /tmp/fd1_hyc ] || mkfifo /tmp/fd1_hyc
ls -ltr /tmp/fd1_hyc
file /tmp/fd1_hyc

这个文件的类型为 p标示是一个 pipe 先进先出的管道。
重定向文件的描述符
在之前《Linux 重定向》章节中我们讲解了文件描述符的使用 Linux redict 重定向 。
那个时候我们讲解了 0、1、2 分别为标准输入、标准输出、错误输出。那么如果我们想要定义其他的文件描述符我们就可以使用 exec 来进行指定
exec 3<>/tmp/fd1_hyc # 绑定描述符 3 与 /tmp/fd1_hyc
echo 123 > /tmp/fd1_hyc
cat /tmp/fd1_hyc # 第一次获取数据
cat /tmp/fd1_hyc # 第二次获取数据
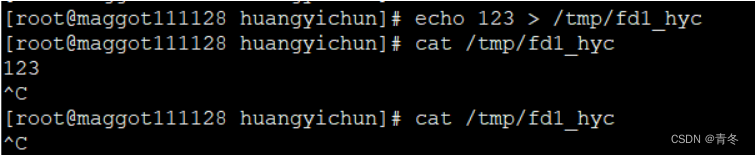
上面命令将 3 和 /tmp/fd1_hyc 文件进行了绑定将标准输入和输出进行绑定。也就是说如果我们读取 3等于读取 /tmp/df1_hyc 也就是我们的管道文件。进行两次 cat 获取数据的操作但只有第一次获取到了数据说明管道中的数据只会被读取一次然后就消失了。
注意文件描述符为自然数且必须大于 2小于
limit -n
当然不能一直存在 3 这种文件操作符在使用完毕后通过下面命令进行释放掉在释放之前3 一直代表的都是管道文件
exec 3>&- # 将描述符 3 进行释放
管道标准输入与输出
在 Linux 中可以使用 read 命令来获取标准输入而且是按照行为单位来获取数据也就是说每次 read 都会获取单行的数据。一般用于键盘的标准输入在之前的 shell 中也有展示。当然也可以使用 read 命令从管道中每次获取一行数据。
# 按行写入数据
echo line1 > /tmp/fd1_hyc
echo line2 > /tmp/fd1_hyc
echo line3 > /tmp/fd1_hyc
# 按行获取数据
read -u3 line ; echo $line
read -u3 line ; echo $line
read -u3 line ; echo $line
# 3 已经和 /tmp/fd1_hyc 进行了绑定
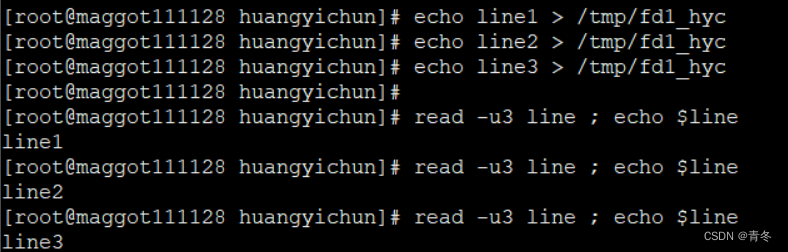
那么如果管道中并没有数据read 命令会一直等待直到获取数据。当然也可以使用其他如 -t 参数设置超时时间但这部分不在本章节讨论各位可以查看 read 的使用手册了解。
所以刚好我们可以使用 echo 来写入一行数据创建令牌然后使用 read 去读整行消费令牌。再让每个子任务运行完毕时也写入一行数据创建令牌使得其他子进程得以运行。这样便实现了整个 shell 的并发控制。
等待所有任务运行完毕
在本小节前半段讲解了后台程序的运行。可以通过 jobs 进行查看 & 挂起的任务那么我们也要一个方法来获取所有子进程是否都运行完毕了这样才可以打印全部任务运行完毕或者调用某些接口。那么在 shell 中有 wait 命令可以等待当前进程的子进程全部运行完毕。
sleep 5s &
jobs
wait
jobs
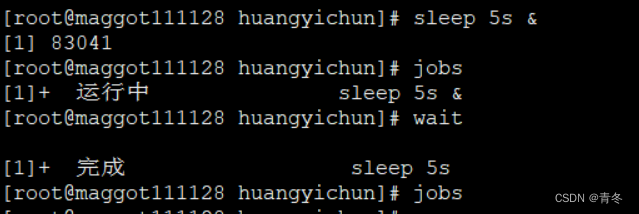
在 wait 处一直等待子进程执行完毕后才执行最后的 jobs。
使用场景
当并发上传数据到 hadoop 对应的目录时
#!/bin/bash
# Copyright◎2022, Maggot. All rights reserved.
#
# This program is put file to hdfs
# Date: 2023-1-14
# Auth: huangyichun
# Version: 0.1
max_multithreading=5
[ -e /tmp/fd1_hyc ] || mkfifo /tmp/fd1_hyc
exec 3<>/tmp/fd1_hyc
rm -rf /tmp/fd1_hyc
for ((i=1;i<=$max_multithreading;i++))
do
echo >&3
done
for filename in `ls `
do
read -u3
{
echo `date` ${filename} is running
# get filepath
filepath=hdfs:///tmp/${${filename%%.*}}/${filename}
hadoop fs -mkdir ${filepath}
hadoop fs -put ${filename} ${filepath}
echo n`date` ${filename} is done
# &3 ++
echo >&3
} &
done
wait
echo all tasks done
exec 3>&-
并发跑 spark-sql 任务
#!/bin/bash
# Copyright◎2022, Maggot. All rights reserved.
#
# This program run sql sed 20 days
# Date: 2023-1-14
# Auth: huangyichun
# Version: 0.1
max_multithreading=3
[ -e /tmp/fd1_hyc ] || mkfifo /tmp/fd1_hyc
exec 3<>/tmp/fd1_hyc
rm -rf /tmp/fd1_hyc
for ((i=1;i<=$max_multithreading;i++))
do
echo >&3
done
for date in {1..20}
do
read -u3
{
date=`date -d "20230114 ${date} day" +"%Y-%m-%d"`
echo `date` ${filename} is running
spark-sql --master yarn --deploy-mode client --driver-cores 1 \
--driver-memory 3G --num-executors 3 --executor-cores 1 \
--executor-memory 4G --queue root.users.hive -f /home/huangyichun/sql/sqls/${date}.sql
echo n`date` ${filename} is done
echo >&3
} &
done
wait
echo all tasks done
exec 3>&-