

查询优化器内核剖析之产生候选执行计划&执行计划成本估算
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本篇的议题如下:
产生候选执行计划 执行计划成本估算
产生候选执行计划
我们知道,查询优化器的基本的目标就是为我们的查询语句找出一个比较高效的执行计划。 即使是一个非常简单的查询,也会存在很多的不同方式去访问数据,而这些不同的方式都是可以 得到相同的结果的,所以,查询优化器必须要很“明智的”从这些大量的执行计划中找出了一个 “最佳”的出来。
为了得到最好的计划,查询优化器必须在某些条件的限制下,尽可能多的创建和评估大量 的候选执行计划。看到这里,就有一点需要注意了“查询优化器是尽可能多的创建候选执行计 划”,而不是为一个查询产生所有的执行计划。在 SQL Server 中,我们把一个查询产生的候选执 行计划的集合称之为“搜索空间(search space)”。很显然,搜索空间中的所有的执行计划都返回 相同的结果。
给一张示意图,让大家更好理解一点,如下所示:
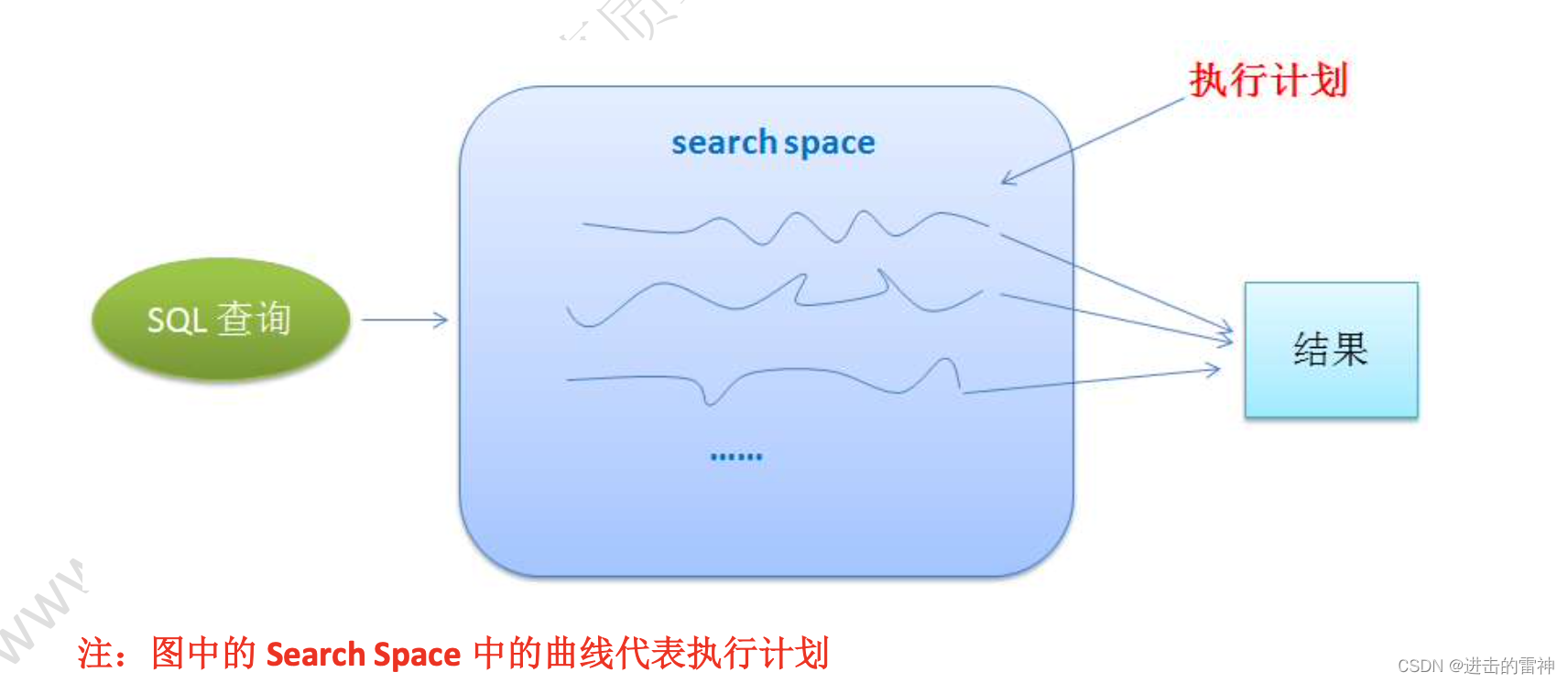
从理论上说,为了找到最佳的执行计划的查询,基于成本的查询优化器应该生成搜索空间 中存在的所有可能的执行计划,并正确估计每个计划的成本。然而,一些复杂的查询可能有成千 上万,或者甚至数百万可能的执行计划,查询优化器不可能去产生并评估一个查询的每一个候选 的执行计划,如果那样,评估所有计划的时间会非常的长,并且严重影响查询的整体的执行时间。
查询优化器必须优化的时间和执行计划的质量之间取得平衡。例如,如果查询优化器花 1 秒钟的时间找到了一个比较好的执行计划,并且这个计划的执行时间是 1 分钟,那么这个时候, 就没有必要再去花费 5 分钟的时间去为这个查询找更优的执行计划。因此 SQL Server 不会做一个 详尽的全部查找,而是尽快找到一个合适的有效的计划。由于查询优化器是有时间限制的,那么 就可能选择的计划可能是最优方案,也有可能只是一些接近最优的方案。
候选的执行计划是在查询优化器的内部通过使用转换规则,启发式算法产生的。候选的执 行计划在优化过程中一直保存在称之为“Memo(中文翻译可能为“备忘录”,以后我们就直接使 用英文名称,很多的技术术语翻译过来之后就变味了)”的内存组件中。从这里我们就可以知道: 如果为了复杂的查询产生所有的候选执行计划势必会占用大量的内存。
我们这里只是简单的介绍一下候选执行计划的产生,后面我们会对每一个步骤进行详细的 分析。
执行计划成本估算
查询优化器需要为产生的候选的执行计划进行成本的估算,从而选择一个成本最低的。为 了估算一个计划的成本,查询优化器会使用一些成本估算的公式来计算一个计划的成本,这些成 本估算公式会考虑很多资源的使用,例如 CPU,I/O,内存等。成本估算主要是取决于算法中采用 的物理操和估算的将要处理的数据记录的量(估算数据记录的量也被称之为“基数估算”)。
为了便于进行基数估算,SQL Server 会使用并且维护统计数据(statistics),统计数据描述了 表中数据的值的分布情况,或者简单的理解为“元数据-描述数据的数据”。一旦采用基数估算得 出了吗,每个操作的成本和对资源的要求,那么查询优化器就会将这个成本数值进行累计,从而 得出整个就会的成本。我们这里不会讨论过多与统计数据相关的知识,在后面中会详细的讲述。
在下一篇文章中,我们会讲述计划的执行与缓存,以及与 Hint 相关的话题。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |