kubeadm安装k8s 1.25高可用集群
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
1、实验环境规划
- 操作系统centos7.9
- 配置 4Gib内存/4vCPU/60G硬盘
- 网络NAT模式
- k8s版本1.25
- 容器运行时环境containerd
环境搭建所用到的镜像几yaml配置文件
链接https://pan.baidu.com/s/15Z1yVzatCE6Td7r2YjmA7g?pwd=l99n
提取码l99n
| k8s集群角色 | IP | 主机名 | 安装组件 |
|---|---|---|---|
| 控制节点 | 192.168.75.140 | master | apiserver、controller-manager、schedule、kubelet、etcd、kube-proxy、容器运行时、calico、keepalived、nginx |
| 工作节点 | 192.168.75.141 | node1 | Kube-proxy、calico、coredns、容器运行时、kubelet |
| 工作节点 | 192.168.75.142 | node2 | Kube-proxy、calico、coredns、容器运行时、kubelet |
2、主机初始化
2.1 修改机器IP变成静态IP
[root@master ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
NAME=ens33
IPADDR=192.168.75.140
GATEWAY=192.168.75.2
NETMASK=255.255.255.0
DNS1=192.168.75.2
UUID=2ad31ee7-5a6e-4fda-a25a-6de555151092
DEVICE=ens33
ONBOOT=yes
2.2 更新yum源和操作系统
在各个节点执行如下命令更新yum源和操作系统
yum update -y
2.3 关闭selinux
三台节点均关闭selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
修改selinux配置文件之后重启机器selinux配置才能永久生效重启之后登录到机器执行如下命令
getenforce
如果显示Disabled说明selinux已经关闭
2.4 配置主机名
在三台机器上执行对应的命令修改主机名
hostnamectl set-hostname master && bash
hostnamectl set-hostname node1 && bash
hostnamectl set-hostname node2 && bash
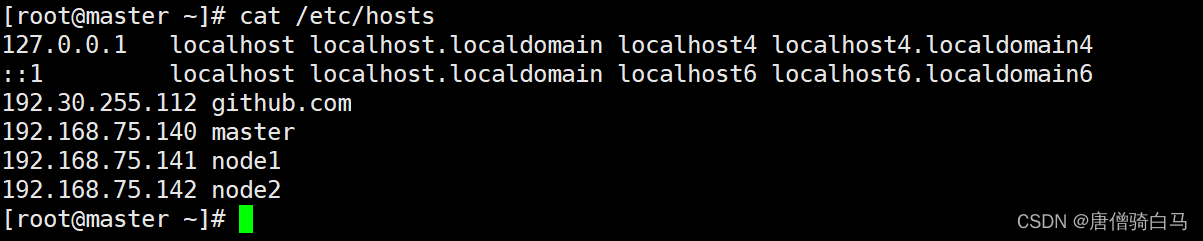
2.5 配置主机hosts文件相互之间通过主机名互相访问
修改每台机器的/etc/hosts文件文件最后增加如下内容
192.168.75.140 master
192.168.75.141 node1
192.168.75.142 node2
修改之后的文件如下:
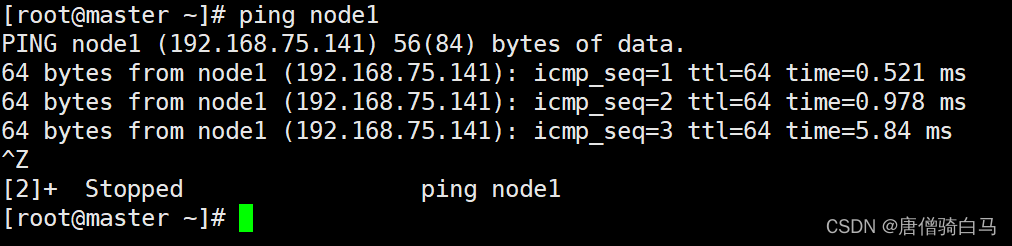
测试连通性
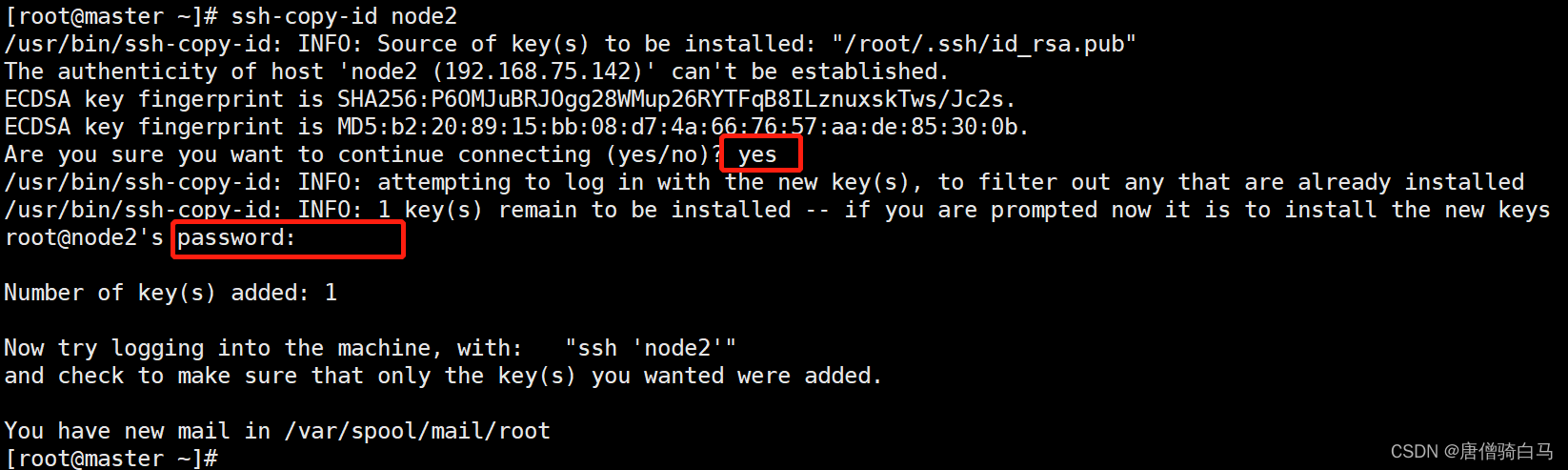
2.6 配置主机之间无密码登录
配置maser到其他机器免密登录
#一路回车不输入密码
[root@master ~]# ssh-keygen
# 把本地生成的密钥文件和私钥文件拷贝到远程主机输入yes和机器密码
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id node1
[root@master ~]# ssh-copy-id node2
配置node1到其他机器免密登录
[root@node1 ~]# ssh-keygen
[root@node1 ~]# ssh-copy-id master
[root@node1 ~]# ssh-copy-id node1
[root@node1 ~]# ssh-copy-id node2
配置node2到其他机器免密登录
[root@node2 ~]# ssh-keygen
[root@node2 ~]# ssh-copy-id master
[root@node3 ~]# ssh-copy-id node1
[root@node3 ~]# ssh-copy-id node2
免密登录测试

2.7 关闭交换分区swap提升性能
三台机器均临时关闭
[root@master ~]# swapoff -a
[root@node1 ~]# swapoff -a
[root@node2 ~]# swapoff -a
永久关闭三台机器均注释swap挂载给swap这行开头加一下注释

为什么要关闭swap交换分区
Swap是交换分区如果机器内存不够会使用swap分区但是swap分区的性能较低k8s设计的时候为了能提升性能默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭如果没关闭那就初始化失败。如果不想要关闭交换分区安装k8s的时候可以指定--ignore-preflight-errors=Swap来解决。
2.8 修改机器内核参数
三台机器均执行如下命令修改内核参数
[root@master ~]# modprobe br_netfilter
You have new mail in /var/spool/mail/root
[root@master ~]# cat > /etc/sysctl.d/k8s.conf <<EOF
> net.bridge.bridge-nf-call-ip6tables = 1
> net.bridge.bridge-nf-call-iptables = 1
> net.ipv4.ip_forward = 1
> EOF
[root@master ~]# sysctl -p /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
sysctl是做什么的
在运行时配置内核参数-p从指定的文件加载系统参数如不指定即从/etc/sysctl.conf中加载
为什么要执行modprobe br_netfilter
修改/etc/sysctl.d/k8s.conf文件增加如下三行参数
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
sysctl -p /etc/sysctl.d/k8s.conf出现报错
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
解决方法
modprobe br_netfilter
为什么开启net.bridge.bridge-nf-call-iptables内核参数
在centos下安装docker执行docker info出现如下警告
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决办法
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
为什么要开启net.ipv4.ip_forward = 1参数
kubeadm初始化k8s如果报错
就表示没有开启ip_forward需要开启。
net.ipv4.ip_forward是数据包转发
出于安全考虑Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时其中一块收到数据包根据数据包的目的ip地址将数据包发往本机另一块网卡该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
要让Linux系统具有路由转发功能需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况其值为0时表示禁止进行IP转发如果是1,则说明IP转发功能已经打开。
2.9 关闭firewalld防火墙
三台机器均执行如下命令关闭firewalld防护墙
systemctl stop firewalld ; systemctl disable firewalld
2.10 配置阿里云的repo源
三台机器均执行如下命令配置国内安装docker和containerd的阿里云的repo源
[root@master ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
2.11 配置安装k8s组件需要的阿里云的repo源
三台机器均执行如下命令配置repo源
[root@master ~]# cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
2.12 配置时间同步
三台机器均执行如下命令进行时间同步
[root@master ~]# yum install ntpdate -y
[root@master ~]# ntpdate cn.pool.ntp.org
[root@master ~]# crontab -e
* */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
2.13 安装基础软件包
三台机器均执行如下命令安装基础包
[root@master ~]# yum install -y device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack telnet ipvsadm
3、安装containerd服务
3.1 安装containerd
三台机器均执行如下命令安装和配置containerd
[root@master ~]# yum install containerd.io-1.6.6 -y
# 接下来生成 containerd 的配置文件:
[root@master ~]#mkdir -p /etc/containerd
[root@master ~]# containerd config default > /etc/containerd/config.toml
修改配置文件
打开/etc/containerd/config.toml
把SystemdCgroup = false修改成SystemdCgroup = true
把sandbox_image = "k8s.gcr.io/pause:3.6"修改成
sandbox_image="registry.aliyuncs.com/google_containers/pause:3.7"
配置 containerd 开机启动
[root@master ~]# systemctl enable containerd --now
修改/etc/crictl.yaml文件并启动containerd
[root@master ~]# cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
[root@master ~]# systemctl restart containerd
备注docker也要安装docker跟containerd不冲突安装docker是为了能基于dockerfile构建镜像
三台机器均安装docker并设置开机自启动
[root@master ~]# yum -y install docker-ce
[root@master ~]# systemctl enable docker.service --now
配置containerd镜像加速器k8s所有节点均按照以下配置
编辑vim /etc/containerd/config.toml文件
找到config_path = ""修改成如下目录
config_path = "/etc/containerd/certs.d"
mkdir /etc/containerd/certs.d/docker.io/ -p
vim /etc/containerd/certs.d/docker.io/hosts.toml
#写入如下内容
[host."https://vh3bm52y.mirror.aliyuncs.com",host."https://registry.docker-cn.com"]
capabilities = ["pull"]
重启containerd
systemctl restart containerd
配置docker镜像加速器k8s所有节点均按照以下配置
vim /etc/docker/daemon.json写入如下内容
{
"registry-mirrors": ["https://gii2szbf.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com"]
}
重启docker
systemctl restart docker
4、安装初始化k8s需要的软件包
所有k8s节点均使用如下命令安装并设置开机自启
[root@master ~]# yum install -y kubelet-1.25.0 kubeadm-1.25.0 kubectl-1.25.0
[root@master ~]# systemctl enable kubelet
注每个软件包的作用
Kubeadm: kubeadm是一个工具用来初始化k8s集群的
kubelet: 安装在集群所有节点上用于启动Pod的kubeadm安装k8sk8s控制节点和工作节点的组件都是基于pod运行的只要pod启动就需要kubelet
kubectl: 通过kubectl可以部署和管理应用查看各种资源创建、删除和更新各种组件
5、kubeadm初始化k8s集群
设置容器运行时
[root@master ~]# crictl config runtime-endpoint /run/containerd/containerd.sock
[root@node1 ~]# crictl config runtime-endpoint /run/containerd/containerd.sock
[root@node2 ~]# crictl config runtime-endpoint /run/containerd/containerd.sock
使用kubeadm初始化k8s集群只在master执行
[root@master ~]# kubeadm config print init-defaults > kubeadm.yaml
根据我们自己的需求修改配置比如修改 imageRepository 的值kube-proxy 的模式为 ipvs需要注意的是由于我们使用的containerd作为运行时所以在初始化节点的时候需要指定cgroupDriver为systemd
[root@master ~]# cat kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.75.140 #控制节点的ip
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock #指定containerd容器运行时
imagePullPolicy: IfNotPresent
name: node
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers # 镜像地址
kind: ClusterConfiguration
kubernetesVersion: 1.25.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 #指定pod网段 需要新增加这个
scheduler: {}
#在文件最后插入以下内容复制时要带着---
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
基于kubeadm.yaml初始化k8s集群
[root@master ~]# ctr -n=k8s.io images import k8s_1.25.0.tar.gz
[root@node1~]# ctr -n=k8s.io images import k8s_1.25.0.tar.gz
[root@node2~]# ctr -n=k8s.io images import k8s_1.25.0.tar.gz
备注k8s_1.25.0.tar.gz这个文件如何来的
这个文件把安装k8s需要的镜像都集成好了这个是我第一次安装1.25.0这个版本获取到对应的镜像通过ctr images export 这个命令把镜像输出到k8s_1.25.0.tar.gz文件如果大家安装其他版本那就不需要实现解压镜像可以默认从网络拉取镜像即可。
ctr是containerd自带的工具有命名空间的概念若是k8s相关的镜像都默认在k8s.io这个命名空间所以导入镜像时需要指定命令空间为k8s.io
使用ctr命令指定命名空间导入镜像
ctr -n=k8s.io images import k8s_1.25.0.tar.gz
查看镜像可以看到可以查询到了
crictl images
初始化k8s
[root@master ~]# kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification
显示如下说明安装完成
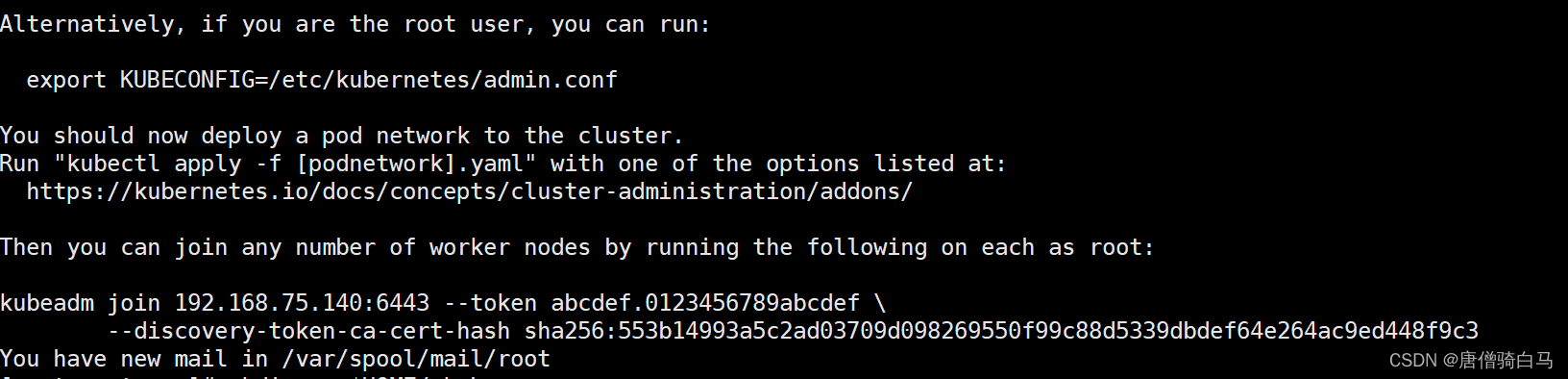
特别提醒--image-repository registry.aliyuncs.com/google_containers为保证拉取镜像不到国外站点拉取手动指定仓库地址为registry.aliyuncs.com/google_containers。kubeadm默认从k8s.gcr.io拉取镜像。 我们本地有导入到的离线镜像所以会优先使用本地的镜像。
mode: ipvs 表示kube-proxy代理模式是ipvs如果不指定ipvs会默认使用iptables但是iptables效率低所以我们生产环境建议开启ipvs阿里云和华为云托管的K8s也提供ipvs模式如下
配置kubectl的配置文件config相当于对kubectl进行授权这样kubectl命令可以使用这个证书对k8s集群进行管理
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master ~]#
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node NotReady control-plane 31s v1.25.0
6、扩容k8s集群-添加工作节点至集群
在master上查看加入节点的命令
[root@master ~]# kubeadm token create --print-join-command
kubeadm join 192.168.75.140:6443 --token 3abn6h.rbx947azsb5yb9p9 --discovery-token-ca-cert-hash sha256:553b14993a5c2ad03709d098269550f99c88d5339dbdef64e264ac9ed448f9c3
把node1加入k8s集群
[root@node1 ~]# kubeadm join 192.168.75.140:6443 --token 3abn6h.rbx947azsb5yb9p9 --discovery-token-ca-cert-hash sha256:553b14993a5c2ad03709d098269550f99c88d5339dbdef64e264ac9ed448f9c3 --ignore-preflight-errors=SystemVerification
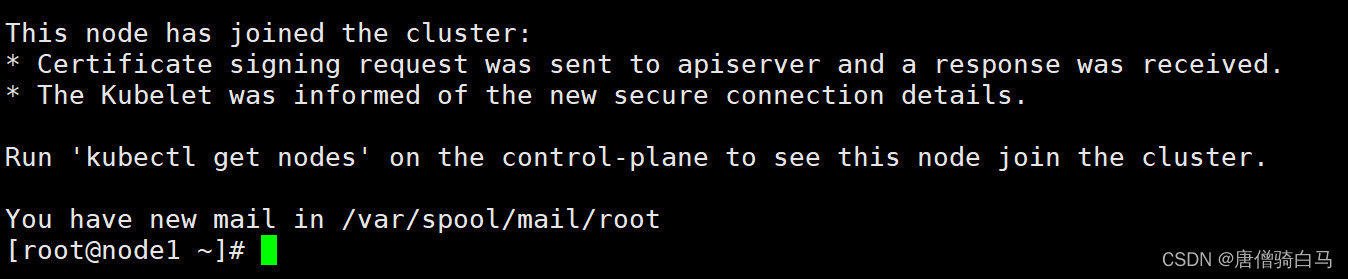
看到上面说明node1节点已经加入到集群了充当工作节点
在master上查看集群节点状况

可以对node1打个标签显示work
[root@master ~]# kubectl label nodes node1 node-role.kubernetes.io/work=work
node/node1 labeled
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node NotReady control-plane 10m v1.25.0
node1 NotReady work 98s v1.25.0
按照如上方法将第二个节点添加至集群
7、安装kubernetes网络组件-Calico
把安装calico需要的镜像calico.tar.gz传到master、node1、node2节点手动解压
[root@master ~]# ctr -n=k8s.io images import calico.tar.gz
[root@node1~]# ctr -n=k8s.io images import calico.tar.gz
[root@node2~]# ctr -n=k8s.io images import calico.tar.gz
上传calico.yaml到master上使用yaml文件安装calico 网络插件 。
[root@master ~]# kubectl apply -f calico.yaml
注在线下载配置文件地址是 https://docs.projectcalico.org/manifests/calico.yaml
查看集群情况已经ready
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node Ready control-plane 17m v1.25.0
node1 Ready work 9m19s v1.25.0
node2 Ready work 6m34s v1.25.0
7.1 Calico架构图
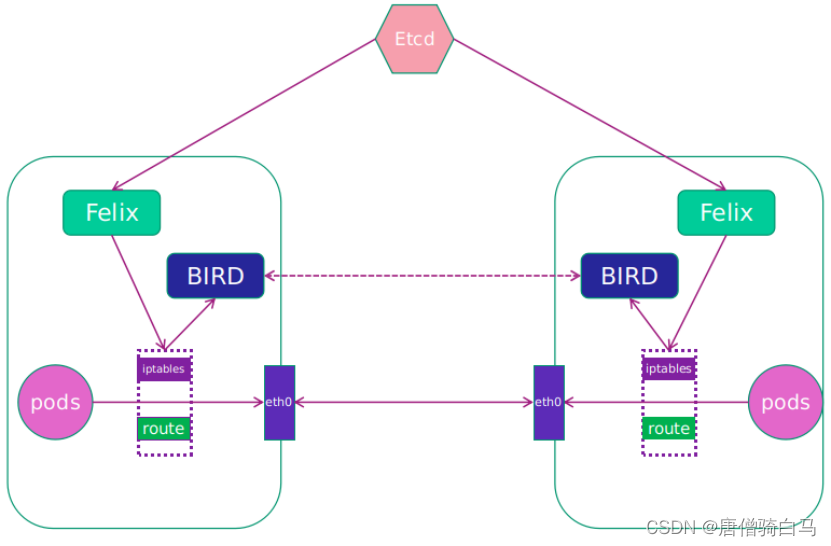
Calico网络模型主要工作组件
1.Felix运行在每一台 Host 的 agent 进程主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。保证跨主机容器网络互通。
2.etcd分布式键值存储相当于k8s集群中的数据库存储着Calico网络模型中IP地址等相关信息。主要负责网络元数据一致性确保 Calico 网络状态的准确性
3.BGP ClientBIRDCalico 为每一台 Host 部署一个 BGP Client即每台host上部署一个BIRD。 主要负责把 Felix 写入 Kernel 的路由信息分发到当前 Calico 网络确保 Workload 间的通信的有效性
4.BGP Route Reflector在大型网络规模中如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制因为所有节点之间俩俩互联需要 N^2 个连接为了解决这个规模问题可以采用 BGP 的 Router Reflector 的方法通过一个或者多个 BGP Route Reflector 来完成集中式的路由分发。
7.2 calico网络插件配置文件说明
……
containers:
# Runs calico-node container on each Kubernetes node. This
# container programs network policy and routes on each
# host.
- name: calico-node
image: docker.io/calico/node:v3.18.0
……
env:
# Use Kubernetes API as the backing datastore.
- name: DATASTORE_TYPE
value: "kubernetes"
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
#pod网段
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
calico-node服务的主要参数如下:
CALICO_IPV4POOL_IPIP是否启用IPIP模式。启用IPIP模式时Calico将在Node上创建一个名为tunl0的虚拟隧道。IP Pool可以使用两种模式BGP或IPIP。使用IPIP模式时设置CALICO_IPV4POOL_IPIP=“Always”不使用IPIP模式时设置CALICO_IPV4POOL_IPIP=“Off”此时将使用BGP模式。
IP_AUTODETECTION_METHOD获取Node IP地址的方式默认使用第1个网络接口的IP地址对于安装了多块网卡的Node可以使用正则表达式选择正确的网卡例如"interface=eth.*"表示选择名称以eth开头的网卡的IP地址。
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33"
扩展calico的IPIP模式和BGP模式对比分析
1IPIP
把一个IP数据包又套在一个IP包里即把IP层封装到IP层的一个 tunnel它的作用其实基本上就相当于一个基于IP层的网桥一般来说普通的网桥是基于mac层的根本不需要IP而这个ipip则是通过两端的路由做一个tunnel把两个本来不通的网络通过点对点连接起来
calico以ipip模式部署完毕后node上会有一个tunl0的网卡设备这是ipip做隧道封装用的,也是一种overlay模式的网络。当我们把节点下线calico容器都停止后这个设备依然还在执行 rmmodipip命令可以将它删除。
2BGP
BGP模式直接使用物理机作为虚拟路由路vRouter不再创建额外的tunnel
边界网关协议BorderGateway Protocol, BGP是互联网上一个核心的去中心化的自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统AS之间的可达性属于矢量路由协议。BGP不使用传统的内部网关协议IGP的指标而是基于路径、网络策略或规则集来决定路由。因此它更适合被称为矢量性协议而不是路由协议通俗的说就是将接入到机房的多条线路如电信、联通、移动等融合为一体实现多线单IP
BGP 机房的优点服务器只需要设置一个IP地址最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的不会占用服务器的任何系统
官方提供的calico.yaml模板里默认打开了ip-ip功能该功能会在node上创建一个设备tunl0容器的网络数据会经过该设备被封装一个ip头再转发。这里calico.yaml中通过修改calico-node的环境变量CALICO_IPV4POOL_IPIP来实现ipip功能的开关默认是Always表示开启Off表示关闭ipip。
- name: CLUSTER_TYPE
value: "k8s,bgp"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
总结
calico BGP通信是基于TCP协议的所以只要节点间三层互通即可完成即三层互通的环境bird就能生成与邻居有关的路由。但是这些路由和flannel host-gateway模式一样需要二层互通才能访问的通因此如果在实际环境中配置了BGP模式生成了路由但是不同节点间pod访问不通可能需要再确认下节点间是否二层互通。
为了解决节点间二层不通场景下的跨节点通信问题calico也有自己的解决方案——IPIP模式
8、测试在k8s创建pod是否可以正常访问网络
把busybox-1-28.tar.gz上传到node1和node2节点手动解压
[root@node1 ~]# ctr -n k8s.io images import busybox-1-28.tar.gz
[root@node2 ~]# ctr -n k8s.io images import busybox-1-28.tar.gz
[root@master ~]# kubectl run busybox --image docker.io/library/busybox:1.28 --image-pull-policy=IfNotPresent --restart=Never --rm -it busybox -- sh
If you don't see a command prompt, try pressing enter.
/ # ping www.baidu.com
PING www.baidu.com (14.215.177.39): 56 data bytes
64 bytes from 14.215.177.39: seq=0 ttl=127 time=9.070 ms
64 bytes from 14.215.177.39: seq=1 ttl=127 time=8.929 ms
^Z[1]+ Stopped ping www.baidu.com
通过上面可以看到能访问网络说明calico网络插件已经被正常安装了
/ # nslookup kubernetes.default.svc.cluster.local
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default.svc.cluster.local
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
10.96.0.10 就是我们coreDNS的clusterIP说明coreDNS配置好了。
解析内部Service的名称是通过coreDNS去解析的。
注意busybox要用指定的1.28版本不能用最新版本最新版本nslookup会解析不到dns和ip
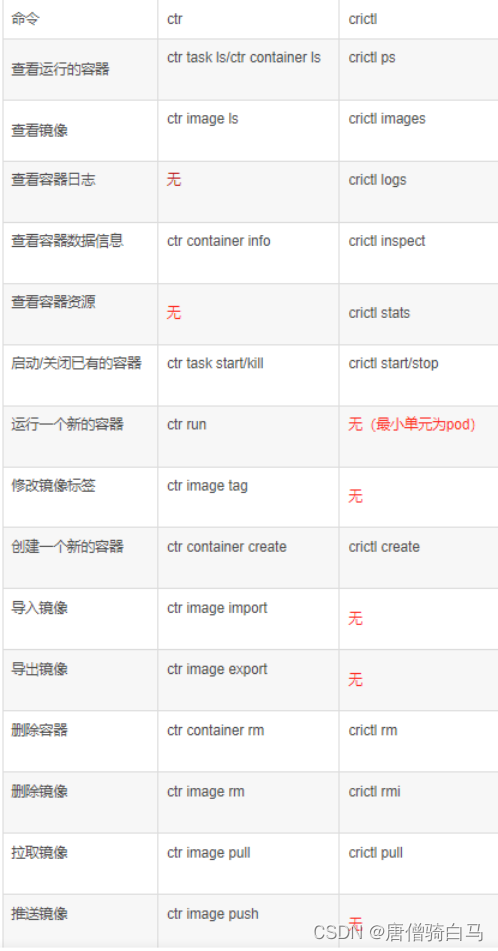
9、ctr和crictl区别
背景在部署k8s的过程中经常要对镜像进行操作拉取、删除、查看等
问题使用过程中会发现ctr和crictl有很多相同功能也有些不同那区别到底在哪里
说明
1.ctr是containerd自带的CLI命令行工具crictl是k8s中CRI容器运行时接口的客户端k8s使用该客户端和containerd进行交互
2.ctr和crictl命令具体区别如下也可以–help查看。crictl缺少对具体镜像的管理能力可能是k8s层面镜像管理可以由用户自行控制能配置pod里面容器的统一镜像仓库镜像的管理可以有habor等插件进行处理。