

hbase hfile文件格式 详解_hbase数据文件存储格式
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.HFile详解HFile文件分为以下六大部分
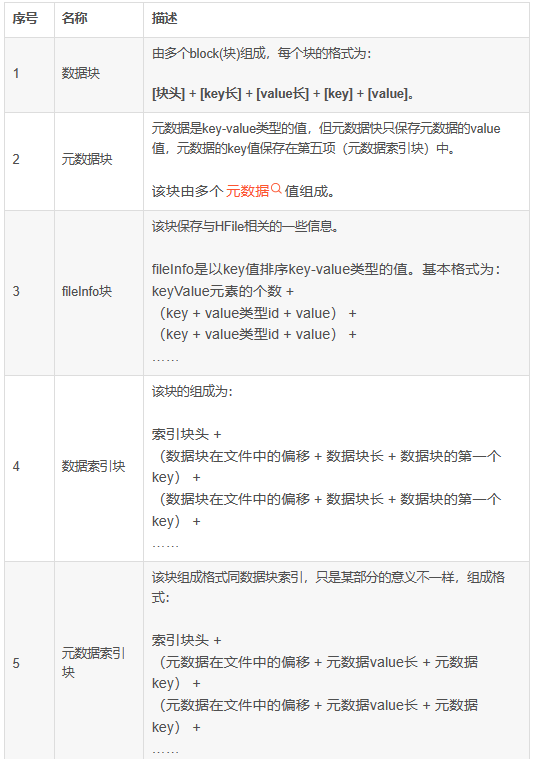
1.1.数据块详解数据块组成图如下:
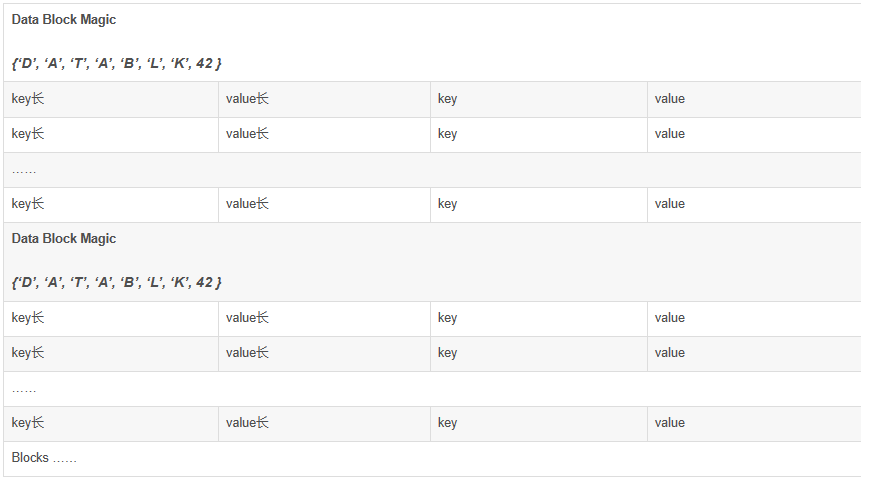
数据块部分由多个block块组成,每个数据块由块头 + 多个cell(key-value对)集合组成,如上图。每个数据块的大小在创建表的列族的时候可以指定,默认为(64 * 1024)。 1. 块大小的设定由HColumnDescriptor.setBlockSize(int)指定,默认(64 * 1024)。 2. 块大小设置,块设置的越小,访问速度越快,但数据块索引越大,消耗的内存越多。因为在加载HFile时会把数据块索引全部加载到内存中。 数据块组成说明: 1. Data Block Magic – 数据块头,8字节,固定字节如下:{‘D’, ‘A’, ‘T’, ‘A’, ‘B’, ‘L’, ‘K’, 42 }。 2. key长 – 4字节整型,记录每个cell的key的长度。 3. value长 – 4字节整型,记录每个cell的value的长度。 4. key – cell的key值,byte[]类型,组成如下: rowKey的长(2字节)+ rowKey + family的长(1字节) + family + qualify + timestampe(8字节) + keyType类型(1字节) 1)rowKey的长度不能大于0x7fff(32767). 2)rowKey不能为空。 3)family(列族)的长度不能大于0x7f(127) 4)qualify(限定符)的长度不能大于(0x7fffffff(2147483647) – row长度 – family长度)。 5. value – cell的value值,byte[]类型,value值不能为空。 例如:在hbase中有一个表(student),其中有一个列族(info),该列族不压缩。其中的rowkey用学号表示,现在插入一个记录(rowkey=’033′, qualify=’age’, value=’19′)。那么该记录将被表示成一个cell(key-value对)保存到HFile中,那么该cell在HFile中的内容如下:
问题: 1. 块大小的设置策略? 2. keyType的说明? 3. compress压缩的说明?
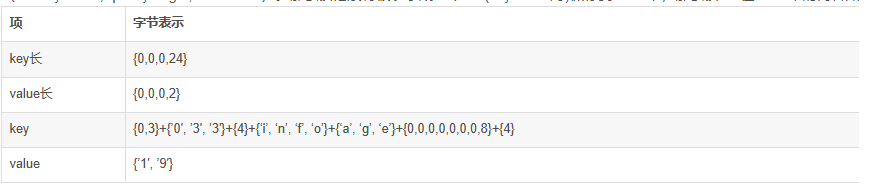
1.2.元数据块详解每个元数据是key-value类型的值,新增的元数据会按照从小到大的顺序排序。 在StoreFile中,如果使用BloomFilter,则StoreFile将会把BloomFilter的信息保存到HFile中的元数据中, 元数据块中只保存元数据的value值,key值保存在元数据索引块中。格式如下:
每个元数据由元数据头+元数据值组成。
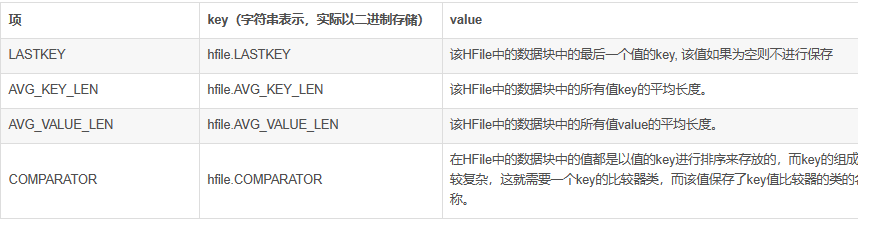
1.3.FileInfo详解fileInfo中保存的信息为key-value类型的值,其中key与value都是byte[]类型。每个新增的值在内部都以值key顺序从小到大进行排序。fileInfo保存了与该HFile相关的一些信息,其中有系统保留的一些固定的值,这些值的key以”hfile.”为前缀。也可以保存用户自定义的一些值,但这些值的key不能以”hfile.”开头。其中系统内部保留的一些值如下:
fileInfo在HFile中的格式如下:
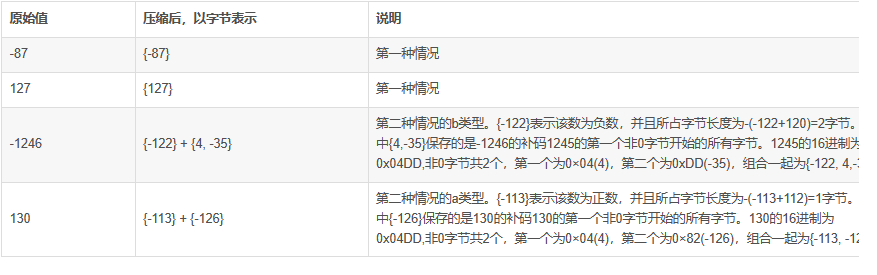
fileInfo各项说明: 1. filInfo中所有值(key-value对)的个数,整型,四字节。 2. key值,保存fileInfo中值得key值。在HFile中的组成为 key长+key 其中key长以压缩的整型保存,整型类型包括(byte,short,int,long),如果该整数用i表示,详细说明如下: 1. 当-112 <= i <= 127 时,用一个字节保存实际值。 2. 其他情况下,第一个字节表示该整型与正负与该整数占字节长度,随后存储的是从该整数补码的高位算起的第一个非0字节的所有值。如果第一个字节为v,详细说明如下: a) 当-120<=i<=-113时,表示该值为正数,该数所占字节为-(v+112) b) 当-128<=i<=-121时,表示该值为负数,该数所占字节为-(v+120) 例如:
3. value值,保存fileInfo中值的value值。在HFile中的组成为 value长+value 其中value长以压缩的整型保存,压缩整型具体格式参考key值中关于压缩整型的说明。
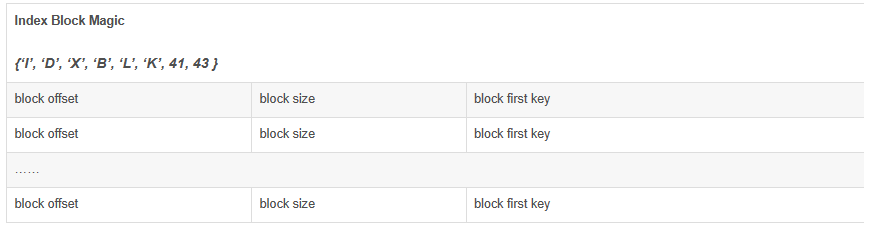
1.4.数据块索引数据块索引保存的是每一个数据块在HFile文件中的位置、大小信息以及每个块的第一个cell的key值。格式如下:
格式各项说明: 1. block offset 块在HFile中偏移,long(8字节)。 2. block size 块大小,int(4字节)。 3. block first key 块中第一个cell(key-value)值得key.该值的组成为(key的长(压缩整型表示)+key值)
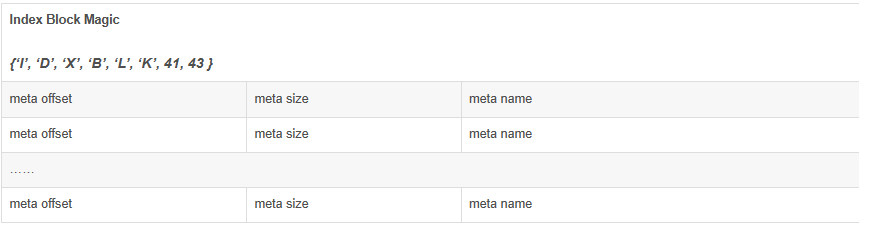
1.5.元数据块索引该数据块的格式与数据库索引相同,元数据块索引保存的是每一个元数据在HFile文件中的位置、大小信息以及每个元数据的key值。格式如下:
格式各项说明: 1. meta offset 元信息在HFile中偏移,long(8字节)。 2. meta size 元信息数据大小,int(4字节)。 3. meta name 元信息中的key值.该值的组成为(key的长(压缩整型表示)+key值)
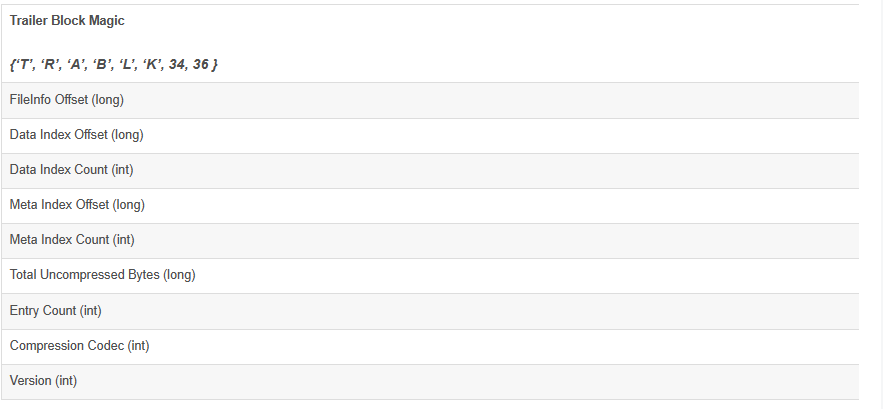
1.6.文件尾文件尾主要保存了该HFile的一些基本信息。格式比较简单,如下:
说明如下: 1. FileInfo Offset – FileInfo信息在HFile中的偏移。long(8字节)。 2. DataIndex Offset – 数据块索引在HFile中的偏移。long(8字节)。 3. DataIndex Count – 数据块索引的个数。int(4字节)。 4. MetaIndex Offset – 元数据索引块在HFile中的偏移。long(8字节)。 5. MetaIndex Count – 元数据索引块的个数。int(4字节)。 6. TotalUncompressedBytes – 未压缩的数据块部分的总大小。long(8字节)。 7. Entry Count – 数据块中所有cell(key-value)的个数。int(4字节) 8. Compression Codec – 压缩算法为enum类型,该值表示压缩算法代码。(LZO-0,GZ-1,NONE-2),int(4字节) 9. Version – 版本信息。当前该版本值为1. int(4字节)。
--------------------------------------
Sumary: Protobuf BinarySearch 本篇主要讲HFileV2的相关内容,包括HFile的构成、解析及怎么样从HFile中快速找到相关的KeyValue.基于Hbase 0.98.1-hadoop2,本文大部分参考了官方的资源,大家可以先阅读下这篇官方文档,Reference Guide:http://hbase.apache.org/book/apes03.html。其实也就是跟我们发行包内dos/book下的其中一篇。dos下有很多有用的文章,有时间的时候建议大家还是细读一下。 研究HFile也有一些时间了,源码也大概研究了下,做了不少试验,庖丁解牛远远谈不上,但是还是很详细地分享一下HFile的方方面面,像拆零件一样,把它一件一件地拆开看看,究竟是什么东西,怎么组织在一起的。 图1 这张图也是摘自上面那篇文章,主要分四部分:Scanned block section,Non-scanned block section,Load-on-open-section,以及Trailer. Scanned block section : 即存储数据block部分 Non-scanned block section :元数据block部分,主要存放meta信息,即BloomFilter信息。 Load-on-open-section :这部分数据在RegionServer启动时,实例化Region并创建HStore时会将所有StoreFile的Load-on-open-section加载进内存,主要存放了Root Data Index,meta Index,File Info及BooleamFilter的metadata等。除了Fields for midkey外,每部分都是一个HFileBlock.下面会详细去讲这块。 Trailer :文件尾,主要记录version版本,不同的版本Trailer的字段不一样,及Trailer的字段相关信息。 在拆解HFile过程中,我们从下而上地开始分析,HBase本身也是这样,首先要知道Version版本,才知道怎么去加载它们。在开始讲解之前,我们应先获得一份HFile数据,其实很简单,直接从hdfs上下载到本地即可,我使用的数据是我上一篇文章中做测试生成的,10W rows, 70W KeyValue,26M左右。 Trailer : 文件最后4位,即一个整型数字,为version信息,我们知道是V2.而V2的Trailer长度为212字节。除去MagicCode(BlockType) 8字节及 Version 4字节外,剩余206字节记录了整个文件的一些重要的字段信息,而这些字段信息是由protobuf组成的,下面我们尝试山寨一把,自主解析下Trailer的所有信息。 实践1: step1: 准备一份描述Trailer的Protobuf. Hbase的源码包下,有一个hbase-protocol sub module.它包含了HBase的所有Protobuf,包括序列化要用到的实体及RPC的定义。我们找到HFile.proto,我们只选取一小部分 新建我们自已的Protobuf文件 : HFile.proto 从proto文件可以看出,Trailer主要记录了Load-on-open-section相关的信息,应该花点时间去做些结合和对比。 step2:使用Protobuf命令生成java代码.(刚好我之前在hadoop环境中编译过源码,安装了protobuf) protoc HFile.proto --java_out=. 将生成的java类拷到我们的项目中. step3. 编写java代码解析Trailer. 输出结果: 至此,Trailer已经完全解析完成,接下来开始下一部分: Load-on-open-section: RegionServer托管着0...n个Region,Region管理着一个或多个HStore,其中HStore就管理着一个MemStore及多个StoreFile. 所在RegionServer启动时,会扫描所StoreFile,加载StoreFile的相关信息到内存,而这部分内容就是Load-on-open-section,主要包括 Root数据索引,miidKyes(optional),Meta索引,File Info,及BloomFilter metadata等. 数据索引: 数据索引是分层的,可以1-3层,其中第一层,即Root level Data Index,这部分数据是处放在内存区的。一开始,文件比较小,只有single-level,rootIndex直接定位到了DataBlock。当StoreFile变大时,rootIndex越来越大,随之所耗内存增大,会以多层结构存储数据索引.当采用multi-level方式,level=2时,使用root index和leaf index chunk,即内存区的rootIndex定位到的是 leafIndex,再由leafIndex定位到Datablock。当一个文件的datablock非常多,采用的是三级索引,即rootIndex定位到intermediate index,再由intermediate index定位到leaf index,最后定位到data block.可以看看上面图1所示,各个level的index都是分布在不同的区域的。但每部分index是以HFileBlock格式存放的,后面会比较详细地讲HFileBlock,说白了,就是HFile中的一个块。 Fileds for midKey: 这部分数据是Optional的,保存了一些midKey信息,可以快速地定位到midKey,常常在HFileSplit的时候非常有用。 MetaIndex: 即meta的索引数据,和data index类似,但是meta存放的是BloomFilter的信息,关于BloomFilter由于篇幅就不深入讨论了. FileInfo: 保存了一些文件的信息,如lastKey,avgKeylen,avgValueLen等等,一会我们将会写程序将这部分内容解析出来并打印看看是什么东西。同样,FileInfo使用了Protobuf来进行序列化。 Bloom filter metadata: 分为GENERAL_BLOOM_META及DELETE_FAMILY_BLOOM_META二种。 OK,下面开始操刀分割下Load-on-open-section的各个小块,看看究竟有什么东西。在开始分析之前,上面提到了一个HFileBlock想先看看。从上面可以看出来,其实基本每个小块都叫HFileBlock(除field for midkey),在Hbase中有一个类叫HFileBlock与之对应。从V2开始,即我们当前用的HFile版本,HFileBlock是支持checksum的,默认地使用CRC32,由此HFileBlock由header,data,checksum三部分内容组成,如下图所示。其中Header占了33个字节,字段是一样的,而每个block的组织会有些小差异. 图2 了解了HFileBlock的结构,我们下面开始正式解析内存区中的各个index的block内容。首先我们根据图2我们抽象出一个简单的HFileBlock实体。 实验2: HFileBlock的解析.及BlockReader内部类 2.编写HFileBlock遍历器,代码有点长,折叠起来吧,有兴趣可以看看,详细完整代码还是下载附件项目吧, 开始解析Root Data Index和metaIndex .在Trailer解析后,我们可以得到Load-on-open-section内容的相关信息,可以构造字节数组,将这部分字节码load进内存进行解析,在解析之前先讲下FileInfo FileInfo的内容是以ProtoBuf放式存放的,与Trailer类似,我们先创建FileInfo.proto 编译: protoc FileInfo.proto --java_out=. 编写测试类: 以上就是解析HFile Load-on-open-section部分的各个fileblock内容,完整代码请下载附带的地址。 Scanned block section: 关于bloomfilter先不分析了。 Non-scanned block section: 这部分内容就是真正的数据块,从图1看出,这部分数据是分datablock存储的,默认地,每个datablock占64K,如果是多层的index的话,部分index block也会存放在这里,由于我的测试数据,是single-level的,所以只针对单级的index分析。 的single-level情况下,内存的rootDataIndex记录了每个datablock的偏移量,大小及startKey信息,主要是为了快速地定位到KeyValue的位置,在HFile中查找或者seek到某个KeyValue时,首先会在内存中,对rootDataIndex进行二分查找,单级的index可以直接定位DataBlock,然后通过迭代datablock定位到KeyValue所在的位置,而2-3层时,上面也略有提及,大家有时间的话,可以做多点研究这部分。 弱弱提句:在HStore中,会有cache将这些datablock缓存起来,使用LRU算法,这样会提高不少性能。 每个DataBlock同样也是一个HFileBlock,也包括header,data,checksum信息,可以用我们之前写的BlockIterator就可以搞定。下面使用代码,去遍历一个datablock看看。 实验3: 编写KeyValue遍历器 编写测试代码:
OK,基本上是这些内容了。有点抱歉一开篇讲得有点大了,其实没有方方面面都讲得很详细。meta,bloomfilter部分没有详细分析,大家有时间可以研究后,分享一下。 源码我将我测试的Hfile也附带上传了,压缩后有3M多,完整代码请下载:下载源码
|


| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |