

实训笔记7.19
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
实训笔记7.19
7.19
一、座右铭
我的故事你说我的文字我落我值几两你定我去何方我挑。
二、Hadoop的HDFS分布式文件存储系统的相关原理性内容
2.1 HDFS上传数据的流程
2.2 HDFS下载数据的流程
2.1~2.2客户端Client 主节点NameNode 从节点DataNode
2.3 HDFS中NameNode和SecondaryNameNode工作机制涉及到HDFS的元数据管理操作
- 一个概念和两个文件元数据、edits编辑日志文件、fsimage镜像文件元数据的持久点检查文件
- SNN的检查点机制每间隔一段时间或者记录数到达一定的数量HDFS就会把edits文件和fsimage文件合并
- NameNode如果元数据丢失的恢复机制
- 把SNN的拷贝过来的edits文件和fismage文件复制到NN的所在目录下可能会造成元数据的丢失
- 设置NameNode的多目录存储可以百分百恢复元数据但是多目录只能在同一个节点上配置
- 使用HA高可用安装模式
- HDFS的集群安全模式的问题
- HDFS启动之后到能正常对外提供访问的这一段时间成为集群的安全模式
- 元数据加载成功同时整个HDFS集群99.9%的block数据块满足最小备份数的时候
2.4 HDFS中NameNode和DataNode的工作机制涉及到HDFS的集群管理操作
- DataNode存储的block数据块除了包含数据本身以外还包含数据块的校验和保证block块的完整性的。。。
- NameNode和DataNode的心跳机制 每隔3秒
- NameNode认为DataNode死亡的掉线时限时长
2*掉线的检测时间5分钟+10*心跳时间
三、Hadoop的新的从节点服役和旧的从节点退役HDFS-DataNode、YARN-NodeManager–HDFS、YARN的运行中的操作
-
新节点的服役
dfs.hosts -
旧节点的退役dfs.hosts.exclude|
退役的时候HDFS会把退役节点上的block块迁移到没有退役的节点上
四、Hadoop的MapReduce分布式计算框架
4.1 基本概念
4.1.1 MapReduce的分布式计算思想
- Mapper阶段
- mapper阶段是用来分数据的
- Mapper阶段处理数据之前数据文件会按照指定的规则划分为不同的切片数据块然后Mapper阶段启动多个MapTask去处理每一个切片的数据 MapTask的数量是自动确定的是和切片的数量一一对应的
- Reducer阶段
- Reducer阶段是用来合数据的
- Reducer阶段是Mapper阶段之后执行的处理的数据是Mapper处理完成的数据Reducer会启动多个ReduceTask每一个ReduceTask负责处理Mapper阶段输出的一部分数据 ReduceTask的数量不是自动确定的而是我们手动指定一般ReduceTask的数量在手动指定的时候需要和分区数保持一致
4.1.2 MapReduce运行过程中相关的一些进程
- MRAPPMaster
- MapTask
- ReduceTask
4.1.3 MapReduce编程规范
- 编写Mapper阶段的计算逻辑MapTask的计算逻辑
- 编写Reduce阶段的计算逻辑ReduceTask的计算逻辑
- 编写Driver驱动程序整合MR程序输入路径、Mapper阶段、Reducer阶段、输出路径
4.2 MapReduce的工作流程原理简单版本
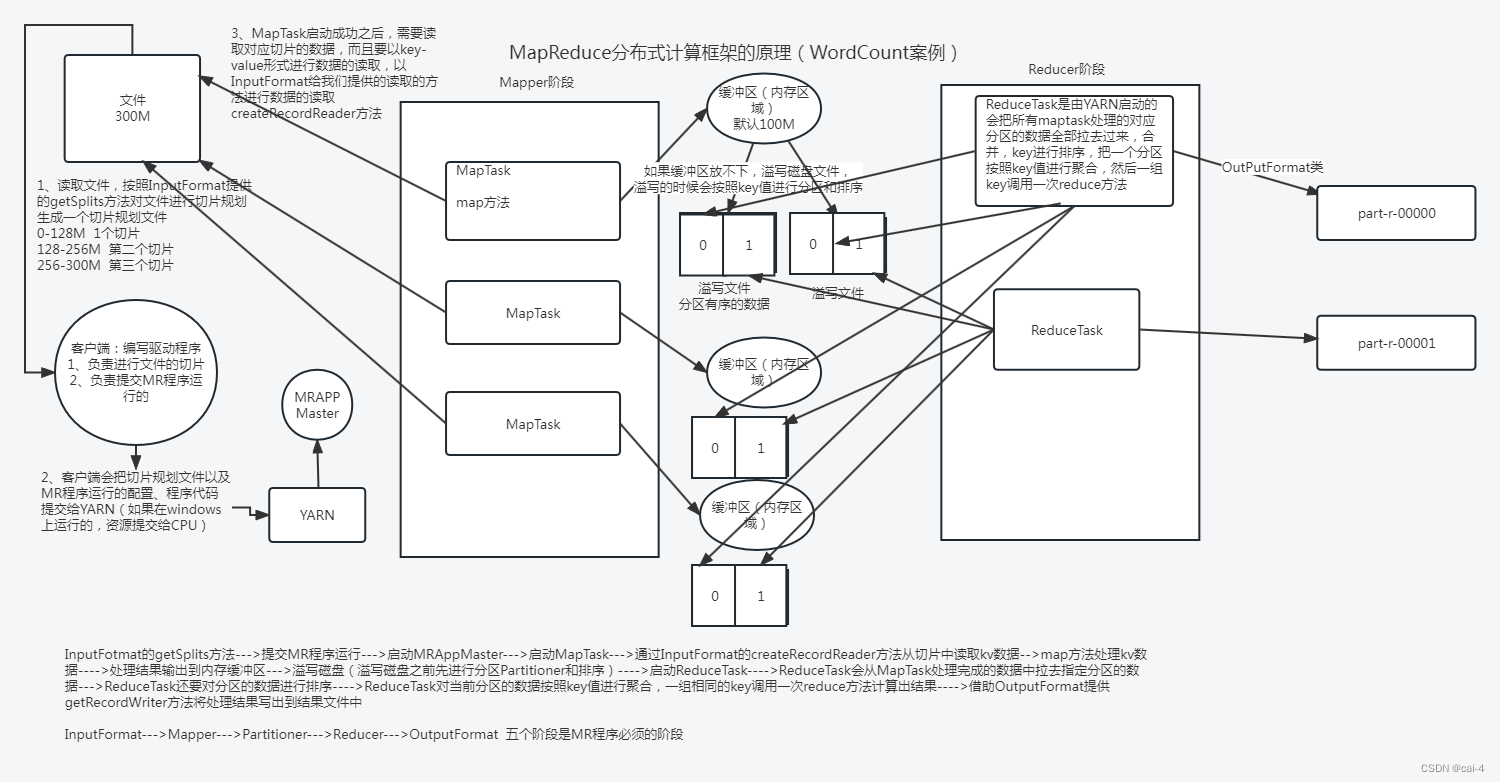
4.3 MapReduce的中序列化机制问题
- MR程序的Map阶段和Reduce阶段都是要求输入的数据和输出的数据必须得是key-value键值对类型的数据而且key-value必须得是序列化类型的数据
- 序列化将Java中的某种数据类型转成二进制数据
- 反序列化将二进制数据转换成某种数据类型
- MR程序之所以要求输入和输出的数据是K-V类型的是因为MR程序是一个分布式计算程序MR程序可以在多个节点上同时运行的而且多个计算程序计算出来的结果可能跨节点跨网络进行数据传输的。如果数据要跨节点跨网络传输要求数据必须是二进制数据。
- Hadoop在进行Key-Value的序列化的时候没有采用Java的序列化机制Serializable、Externalizable因为Java的序列化机制非常的笨重的因此Hadoop基于Java的序列化机制方式提供了一种全新的专门适用于MR程序的轻量级的序列化机制。
- Hadoop中提供了两个接口Writable、WritableComparable,Hadoop提供的两个序列化机制
- Writable
- 只有序列化和反序列化的效果如果我们自定义的一个数据类型Java类要想当MR程序的K-V使用的话Java必须实现Writable接口重写两个方法通过这两个方法规定序列化和反序列化的内容
- Writable的使用方式类似于Java中Externalizable序列化机制
- WritableComparable
- 接口除了具备序列化和反序列化的能力以外还具备一个比较大小关系的方法
- 如果自定义的数据类型Java类想当MR程序中的key值来使用必须实现此接口让自定义数据类型既可以进行序列化反序列化还可以进行大小的比较判断 如果自定义的数据类型只想当作MR程序中的value来使用只需要实现Writable接口即可不需要比较大小。
- Writable
- Hadoop常见的序列化类型Hadoop把Java中包装类和String类型已经给我们封装好了对应的Hadoop序列化类型—实现了WritableComparable接口
| 类型 | 方法名 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| string | Text |
| map | MapWritable |
| array | ArrayWritable |
-
【注意】 1、如果以后MR程序运行没有报错但是输出目录没有任何的内容一般可能是因为输入和输出的key-value的自定义类型没有实现序列化 2、如果自定义的JavaBean充当Reducer阶段输出key-value时最好把toString方法给重写了否则Reducer最后输出的结果是JavaBean的地址值
4.4 MR程序运行的核心阶段的细节性知识
4.4.1 MR程序在运行过程中涉及到的阶段和作用
- InputFormat阶段两个作用
- 负责对输入的数据进行切片切片的数据和Mapper阶段的MapTask的数量是相对应的
- 负责MapTask读取切片数据时如果将切片的数据转换成为Key-value类型的数据包括key-value的数据类型的定义
- Mapper阶段——作用处理每一个切片数据的计算逻辑
- Partitioner阶段——map阶段处理完成的数据输出到缓冲区溢写磁盘的时候必须进行分区
- Combiner阶段可以存在可以不存在——相当于是一个Reducer只不过这个reducer是针对于当前的MapTask有效
- Reducer阶段———作用就是用来聚合所有MapTask的数据聚合起来之后计算逻辑的编写
- OutputFormat阶段———作用就是Reducer阶段输出的数据如何以key-value的形式输出到最终的目的地
4.4.2 MR程序运行的的第一个阶段InputFormat阶段
-
InputFormat是一个抽象类提供了两个抽象方法
getSplits这个方法是用来进行输入数据文件的切片计算的createRecordReader这个方法是MapTask读取切片数据时是按照行读取还是按照其他规则读取包括读取时key-value分别代表什么含义什么类型
-
常用的InputFormat的实现类
-
FileInputFormat(是InputFormat的默认实现类)FileInputFormat是专门用来读取文件数据时使用的输入格式化类但是FileInputFormat也是一个抽象类
-
FileInputFormat抽象类有五个常用的非抽象子类
-
TextInputFormat(是FileInputFormat默认实现类)
-
如何切片
-
两个核心参数
MinSplitSize=1LMaxSplitSize=Long.MAX_VALUEconfguration("mapreduce.input.fileinputformat.split.minsize",xxxL)configuration("mapreduce.input.fileinputformat.split.maxsize",xxxL) -
每一个输入文件单独进行切片
-
每一个文件先获取它的blockSize然后计算文件的切片大小
splitSize=Math.max(minSize, Math.min(maxSize, blockSize)) -
先判断文件是否能被切片如果文件是一个压缩包.gz、.zip,单独成为一个切片如果文件能被切片判断文件的长度是否大于splitSize的1.1倍如果不大于 文件单独成为一个切片如果大于1.1倍按照splitsize切一片然后将剩余的大小和splitsize继续比较
-
示例
- 第一种情况 a.tar.gz 300M blocksize 128M 有一个数据切片300M
- 第二种情况blocksize均为128M a.txt 200M 两个切片一个切片128M 第二个切片72M b.txt 130M 一个切片130M
-
【注意】
TextInputFormat是按照SplitSize进行切片的默认情况下SplitSize=文件的BlockSize
如果你要让SplitSize大于blockSize那么我们需要在MR程序调整minsize的大小即可
如果你要让SplitSize小于BlockSize 那么需要MR程序调整maxSize的大小即可
-
-
如何读取数据成为key-value
-
-
KeyValueTextInputFormat
-
NLineInputFormat
-
CombineInputFormat
-
SequenceFileInputFormat
-
-
-
如何自定义InputFormat实现类
五、MR程序运行的问题总结
-
MR程序运行需要在控制台输出日志MR程序控制台输出的日志能清洗看到MR程序切片数量以及MapTask的数量和ReduceTask的数量 但是默认情况下控制台是无法输出日志的如果要输出日志信息我们需要对代码进行修改
-
需要在项目的resources目录引入log4j.properties文件 日志信息输出文件文件当中定义了我们如何输出日志信息
-
引入一个日志框架的依赖如果没有这个依赖那么日志文件不会生效输出 pom.xml
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.21</version> </dependency>
-
六、代码示例
package com.sxuek.flow;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
/**
* JavaBean是Java中一种很干净的类类中只具备私有化的属性、构造器、getter setter方法 hashCode equals方法 toString方法
* 实体类实体类又是一种特殊的JavaBean当JavaBean是和数据库中数据表对应的类的时候JavaBean称之为实体类
*
* JavaBean可以自己手动生成也可以使用lombok的技术基于注解快速的创建JavaBean这个类
* Lombok使用要慎重Lombok对代码的侵占性是非常大的
*
* 如果自定义的JavaBean要当MR程序的输入和输出的KV值最好让JavaBean存在一个无参构造器MR程序底层反射构建这个类的对象
* 如果自定义的JavaBean要充当Reducer阶段的KEY和Value,那也就意味着JavaBean的结果要写到最终的结果文件当中JavaBean的数据往结果文件写的格式是按照
* JavaBean的toString方法去写的。
*/
public class FlowBean implements Writable {
//public class FlowBean {
private Long upFlow;//上行流量
private Long downFlow; //下行流量
private Long sumFlow; //总流量
public FlowBean() {
}
public FlowBean(Long upFlow, Long downFlow, Long sumFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = sumFlow;
}
public Long getUpFlow() {
return upFlow;
}
public void setUpFlow(Long upFlow) {
this.upFlow = upFlow;
}
public Long getDownFlow() {
return downFlow;
}
public void setDownFlow(Long downFlow) {
this.downFlow = downFlow;
}
public Long getSumFlow() {
return sumFlow;
}
public void setSumFlow(Long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
FlowBean flowBean = (FlowBean) o;
return Objects.equals(upFlow, flowBean.upFlow) && Objects.equals(downFlow, flowBean.downFlow) && Objects.equals(sumFlow, flowBean.sumFlow);
}
@Override
public int hashCode() {
return Objects.hash(upFlow, downFlow, sumFlow);
}
@Override
public String toString() {
return upFlow+"\t"+downFlow+"\t"+sumFlow;
}
/**
* 序列化写的方法
* @param out <code>DataOuput</code> to serialize this object into.
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化读取数据的方法
* @param in <code>DataInput</code> to deseriablize this object from.
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
}
package com.sxuek.flow;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 现在有一个文件 phone_data.txt,文件中记录着手机号消耗的流量信息
* 文件中每一行数据代表一条手机的流量消耗每一条数据是以\t制表符分割的多个字段组成的
* 使用MR程序统计每一个手机号消耗的总的上行流量、总的下行流量、总流量
*/
public class FlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.68.101:9000");
// configuration.set("mapreduce.input.fileinputformat.split.minsize",150*1024*1024+"");
//maxsize 100M minsize 1L blocksize 128M
configuration.set("mapreduce.input.fileinputformat.split.maxsize",100*1024*1024+"");
Job job = Job.getInstance(configuration);
/**
* MR程序封装的时候按道理需要指定InputFormat类只有指定了这个实现类才能实现切片和kv数据的读取
* 但是MR程序有个机制如果没有指定InputFormat的实现类默认就会实现FileInputFormat的一个实现子类TextInputFormat当作默认的切片机制
* 和KV数据读取的InputFormat类
*/
// job.setInputFormatClass(TextInputFormat.class);
//封装输入的文件路径 输入路径可以是一个 也可以是多个 输入路径可以是文件也可以是文件夹
/**
* 默认切片机制 每一个文件单独切片 n个文件 最小有n个文件
* splitSize 100M
* 文件能否被切割、文件的大小是否大于splitsize的1.1倍
* 300M 100M 100M 100M
* 120M 100M 20M
*/
FileInputFormat.setInputPaths(job,new Path("/test1"));
//封装Mapper阶段
job.setMapperClass(FlowMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//封装Reducer阶段
job.setReducerClass(FlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setNumReduceTasks(1);
//封装输出结果路径
//MR程序要求输出路径不能提前存在 如果提前存在会报错
Path path = new Path("/output");
//是用来解决输出目录如果存在MR程序报错问题的
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:9000"), configuration, "root");
if (fs.exists(path)){
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job,path);
//最后提交程序运行即可
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
package com.sxuek.flow;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 读取切片数据一行数据读取一次 而且读取的key value LongWritable Text
* 输出的key value 是Text FlowBean
*
*/
public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] array = line.split("\t");
String phoneNumber = array[1];
Long upFlow = Long.parseLong(array[array.length - 3]);
Long downFlow = Long.parseLong(array[array.length - 2]);
FlowBean flowBean = new FlowBean(upFlow,downFlow,upFlow+downFlow);
//需要将这一条数据以手机号为key 以flowbean为value输出给reduce
context.write(new Text(phoneNumber),flowBean);
}
}
package com.sxuek.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException {
//计算手机号消耗的总的上行 下行 总流量 values中每一条流量的上 下 总累加起来即可
long upFlowSum = 0L;
long downFlowSum = 0L;
long sumFlowSum = 0L;
for (FlowBean value : values) {
upFlowSum += value.getUpFlow();
downFlowSum += value.getDownFlow();
sumFlowSum += value.getSumFlow();
}
//需要以手机号为key 以flowbean为value将结果输出flowbean需要将我们计算出来总流量信息封装起来
FlowBean flowBean = new FlowBean(upFlowSum,downFlowSum,sumFlowSum);
context.write(key,flowBean);
}
}
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |