

暑期实习准备——Verilog手撕代码(持续更新中。。。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
暑期实习准备——手撕代码
牛客刷题笔记
Verilog快速入门
VL4 移位运算与乘法
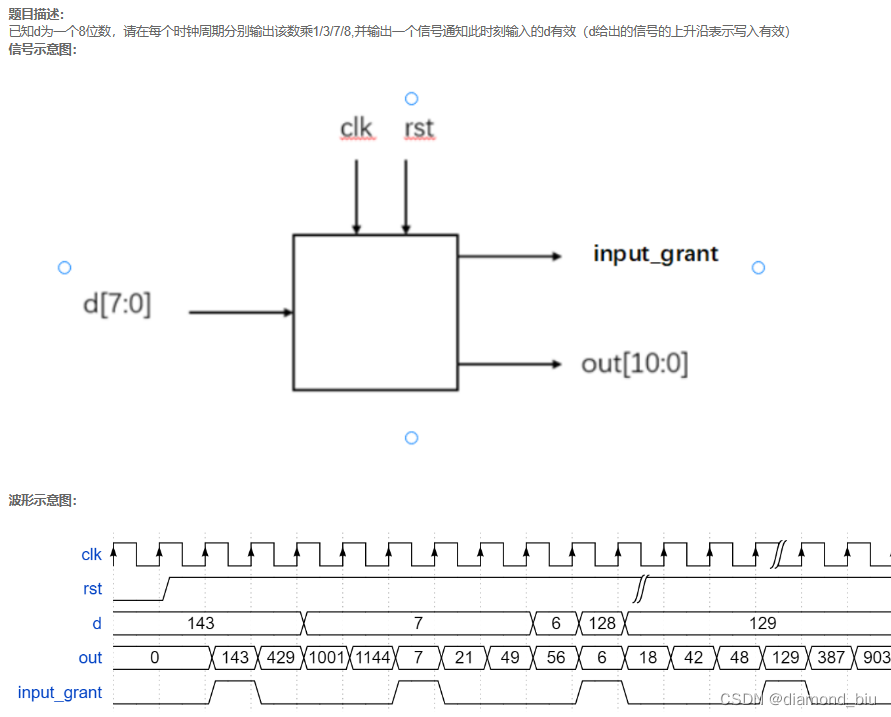
- 要点1:题目用状态机实现经典的两段式模板。
- 要点2:需要一个d_reg信号临时记录当前要加倍的d信号这样才能保证d信号变化时加倍的仍然是原本的d信号注意d_reg<=d;赋值语句应该在11状态即每一轮状态转换结束后开启新一轮状态前。
- 要点3:always @ (posedge clk or negedge rst or current_state) 第二段的敏感事件表套模板的时候误删了current_state信号导致所有的状态机状态转换被延长了一拍因此这里的敏感时间表一定要将记住写current_state。
- 要点4:注意为状态机以及其他输出信号赋初始值。
- 要点5:1、3、7、8倍数通过移位运算和加运算实现不需要乘法运算。
`timescale 1ns/1ns
module multi_sel(
input [7:0]d ,
input clk,
input rst,
output reg input_grant,
output reg [10:0]out
);
reg [1:0] current_state,next_state;
reg[7:0] d_reg;
//*************code***********//
always @ (posedge clk or negedge rst) begin
if(!rst) current_state<=2'b00;
else current_state<=next_state;//非阻塞赋值
end
always @ (posedge clk or negedge rst or current_state) begin
next_state<=2'b00;
if(!rst) begin
input_grant<=1'b0;
out<=11'b0;
d_reg<=d;
end
else begin
case(current_state)
2'b00:begin
input_grant<=1'b1;
out<=d_reg;
next_state<=2'b01;
end
2'b01:begin
input_grant<=1'b0;
out<= d_reg + {2'b0, d_reg, 1'b0};
next_state<=2'b10;
end
2'b10:begin
input_grant<=1'b0;
out<=d_reg + {2'b0, d_reg, 1'b0} + {1'b0 ,d_reg, 2'b00};
next_state<=2'b11;
end
2'b11:begin
input_grant<=1'b0;
out<={d_reg, 3'b000};
next_state<=2'b00;
d_reg<=d;
end
endcase
end
end
//*************code***********//
endmodule
VL5 位拆分与运算
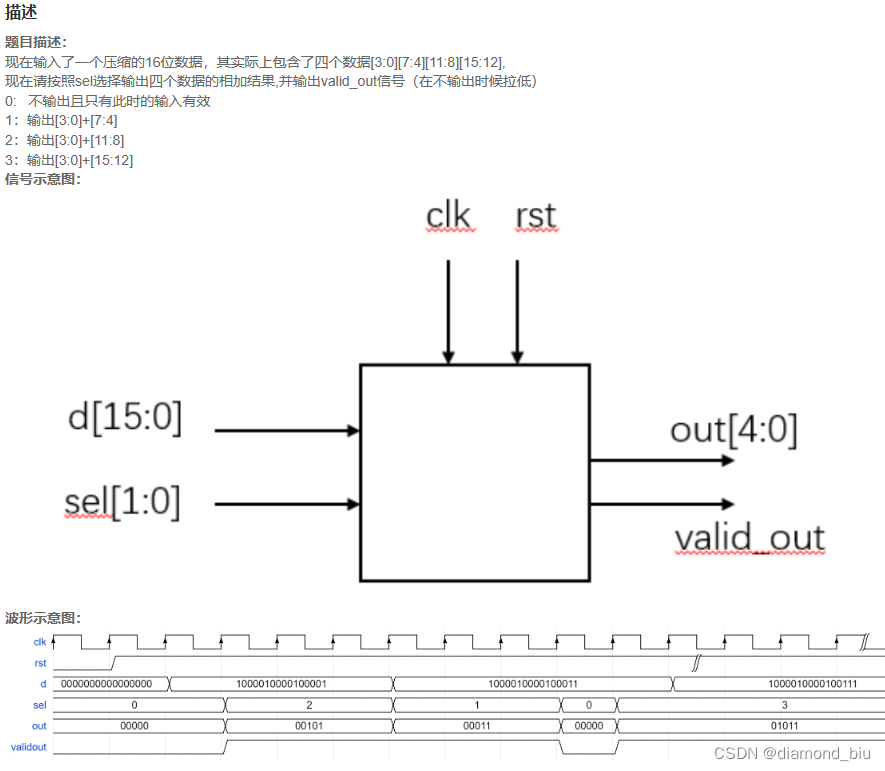
- 要点1:仔细读题注意题目中提到的只有在sel=0时输入才有效因此需要reg_d把输入d锁存。
- 要点2:仔细读题还是要理解题目的意思。
`timescale 1ns/1ns
module data_cal(
input clk,
input rst,
input [15:0]d,
input [1:0]sel,
output reg [4:0]out,
output reg validout
);
//*************code***********//
reg [15:0] reg_d;
always @ (posedge clk or rst or d) begin
if(!rst) begin
out<=5'b0;
validout<=0;
end
else begin
case(sel)
2'b00:begin out<=5'b0; validout<=0; reg_d<=d ;end
2'b01:begin out<=reg_d[3:0]+reg_d[7:4]; validout<=1; end
2'b10:begin out<=reg_d[3:0]+reg_d[11:8]; validout<=1; end
2'b11:begin out<=reg_d[3:0]+reg_d[15:12]; validout<=1; end
endcase
end
end
//*************code***********//
endmodule
VL6 多功能数据处理器
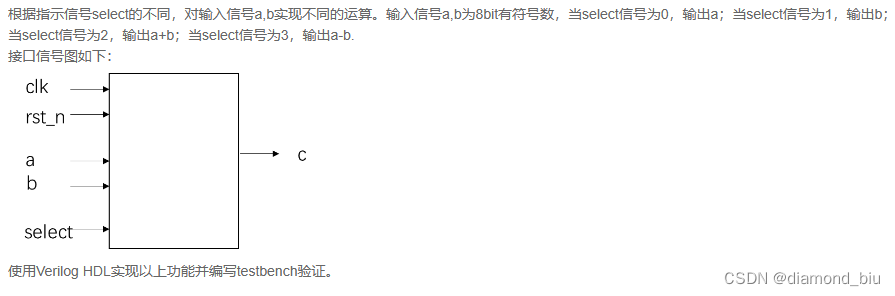
- 要点1:有符号数以补码形式存储可以直接进行加减运算。
- 要点2:
always @ (posedge clk or negedge rst_n)的写法是正确的但有点疑惑是初始状态下就是低电平会不会触发本题既然是正确的就说明初始低电平会触发。
always @ (posedge clk or rst_n)的写法是错误的会在rst_n由0变为1时触发但此时可能并非时钟上升沿造成异常输出。
always @ (posedge clk)的写法会使得初始状态下输出信号处于无效状态额外在always块前加上initial c<=9'b0;这样可以通过测试用例但是initial语句不可综合最好不要使用。
`timescale 1ns/1ns
module data_select(
input clk,
input rst_n,
input signed[7:0]a,
input signed[7:0]b,
input [1:0]select,
output reg signed [8:0]c
);
always @ (posedge clk or negedge rst_n) begin
if(!rst_n) begin
c<=9'b0;
end
else begin
case(select)
2'b00:begin c<=a; end
2'b01:begin c<=b; end
2'b10:begin c<=a+b; end
2'b11:begin c<=a-b; end
endcase
end
end
endmodule
VL8 使用generate…for语句简化代码

- 要点1:必须使用
genvar声明循环变量。 - 要点2:
begin-end之间插入赋值语句begin后面必须声明循环实例的名称。 - 要点3:
generate-for常用来简化assign的赋值assign data_out[i]=data_in[7-i];展开后的8条assign语句是并行赋值的。如在6线-64线、8线-256线译码器中可以用来简化代码。
`timescale 1ns/1ns
module gen_for_module(
input [7:0] data_in,
output [7:0] data_out
);
genvar i;
generate for(i=0;i<=7;i=i+1)
begin:label
assign data_out[i]=data_in[7-i];
end
endgenerate
endmodule
VL9 使用子模块实现三输入数的大小比较
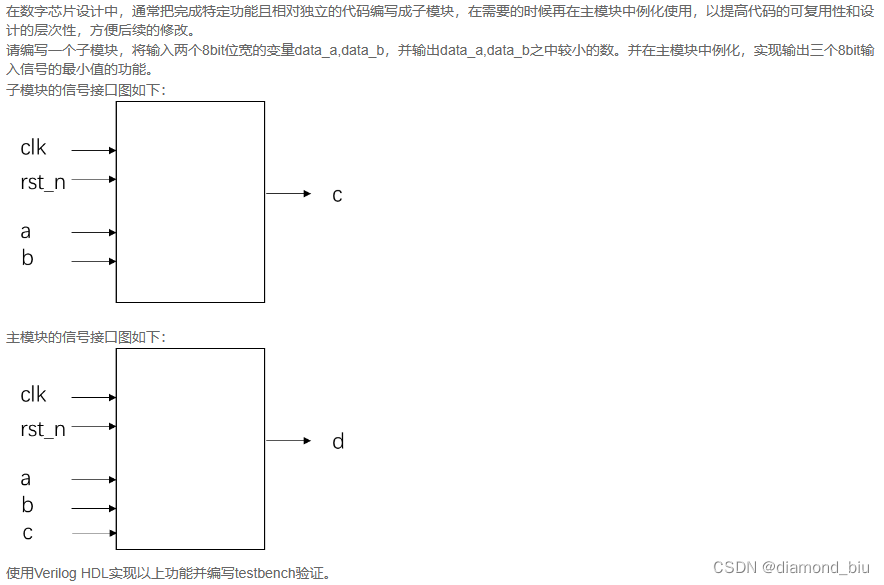
- 要点1:两个比较器会导致进入比较器的三个输入时间不同步需要使用三个子模块才可以正确实现。
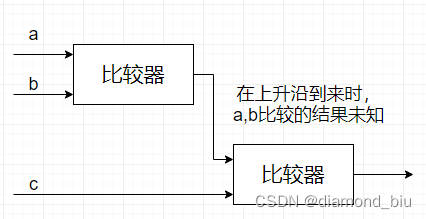
在第一个上升沿ab进入第一个比较器c进入第二个比较器。但是比较器输出是需要时间的在第一个上升沿c立刻进入第二个比较器但ab比较器的输出会较晚的进入第二个比较器这就造成了输入时间不同步从而造成输出错误。
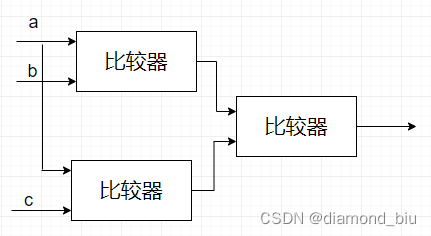
使用三个比较器将c延迟一拍就可以让输入子模块的时间都相等从而不会出现进入时间不同导致的错误。
我们可以对波形进行分析来比较这两种写法的差别testbench如下:
`timescale 1ns/1ns
module testbench();
reg signed [7:0] a,b,c;
reg clk,rst_n;
wire [7:0]d;
main_mod dut(
.clk(clk),
.rst_n(rst_n),
.a(a),
.b(b),
.c(c),
.d(d)
);
always #5 clk = !clk;
initial begin
clk=0;rst_n=0;
#5 rst_n=1;
#10 a=2;b=3;c=4;
#10 a=4;b=2;c=1;
#10 a=5;b=4;c=3;
end
endmodule
三个比较器的仿真波形如下。可以看到每一次比较的结果都在下一个时钟周期输出分别为213。
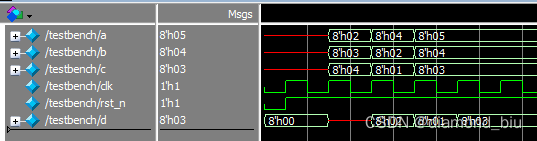
二个比较器的仿真波形如下此时比较结果为123这是因为上一轮a,b的最小值实际上是与当前周期的c进行比较的因此对于第一组输入a和b的比较结果是22和下一组输入的c=1进行了比较所以输出的最小值是1;同样第二组输出a和b的比较结果是22和下一组输入的c=3进行了比较所以输出为2;第二组输出a和b的比较结果是44和下一组输入的c=3进行了比较所以输出为3。

- 要点2:子模块中
c<=(a>b)?b:a;语句需要使用非阻塞赋值。
不知道为什么非阻塞不会报错阻塞会报错显示有用例不通过。使用vivado综合出来的电路这两个是一样的。待解决
但还是复习一下阻塞赋值和非阻塞赋值
非阻塞赋值b <= a;:非阻塞赋值中赋值并不是马上执行的也就是说"always"块内的下一条语句执行后b并不等于a而是保持原来的值。"always"块结束后才进行赋值。
阻塞赋值b=a;:方式是马上执行的。也就是说执行下一条语句时b已等于a。
`timescale 1ns/1ns
module main_mod(
input clk,
input rst_n,
input [7:0]a,
input [7:0]b,
input [7:0]c,
output [7:0]d
);
wire [7:0] ab,ac;
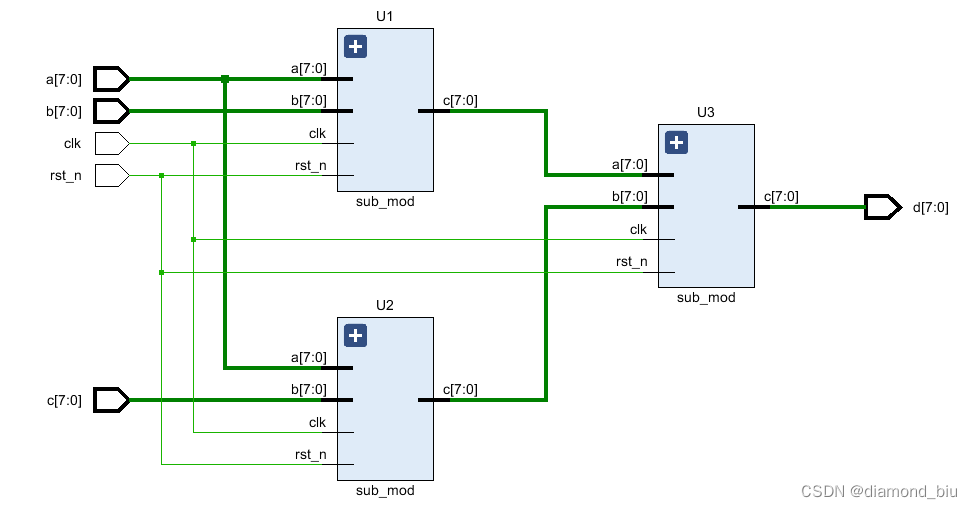
sub_mod U1(.clk(clk),.rst_n(rst_n),.a(a),.b(b),.c(ab));
sub_mod U2(.clk(clk),.rst_n(rst_n),.a(a),.b(c),.c(ac));
sub_mod U3(.clk(clk),.rst_n(rst_n),.a(ab),.b(ac),.c(d));
endmodule
module sub_mod(clk,rst_n,a,b,c);
input clk,rst_n;
input[7:0] a,b;
output [7:0] c;
reg[7:0]c;
always@(posedge clk or negedge rst_n)begin
if(~rst_n)c<=8'b0;
else begin
c<=(a>b)?b:a;
end
end
endmodule
VL11 4位数值比较器电路
要点1:题目中说要用门级描述完成对于1bit数的比较对应的门运算如下A>B对应~A&BA<B对应A&~BA=B对应~(A^B)。
`timescale 1ns/1ns
module comparator_4(
input [3:0] A ,
input [3:0] B ,
output wire Y2 , //A>B
output wire Y1 , //A=B
output wire Y0 //A<B
);
assign Y2=(A[3]>B[3])|((A[3]==B[3])&(A[2]>B[2]))|((A[3]==B[3])&(A[2]==B[2])&(A[1]>B[1]))|((A[3]==B[3])&(A[2]==B[2])&(A[1]==B[1])&(A[0]>B[0]));
assign Y1=(A==B);
assign Y0=(A[3]<B[3])|((A[3]==B[3])&(A[2]<B[2]))|((A[3]==B[3])&(A[2]==B[2])&(A[1]<B[1]))|((A[3]==B[3])&(A[2]==B[2])&(A[1]==B[1])&(A[0]<B[0]));
endmodule
要点2:抽象描述可以写到直接比较A和B。
`timescale 1ns/1ns
module comparator_4(
input [3:0] A ,
input [3:0] B ,
output wire Y2 , //A>B
output wire Y1 , //A=B
output wire Y0 //A<B
);
assign Y2=(A>B)?1:0;
assign Y1=(A==B)?1:0;
assign Y0=(A<B)?1:0;
endmodule
VL12 4bit超前进位加法器电路
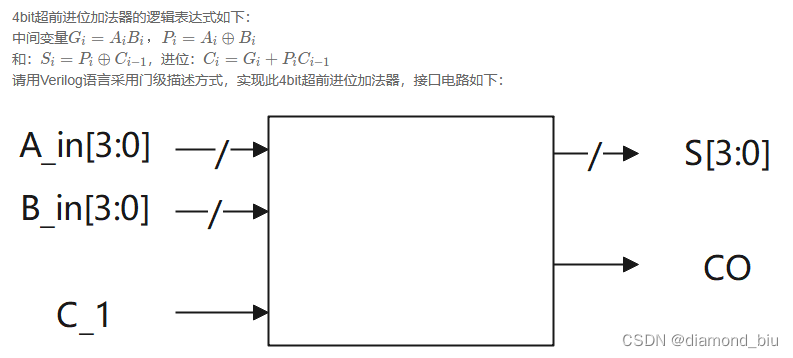
1比特进位加法器的两种实现:
//实现1:逻辑代数
assign sum=a^b^cin;
assign cout=a&b|(cin&(a^b));或者assign cout=(a&b)|(a&cin)|(b&cin);
//实现2:抽象描述
assign {cout,sum}=a+b+cin;
assign cout=(a&b)|(a&cin)|(b&cin);很容易理解即a,b,cin中任意两个或以上为1就进位。
assign cout=a&b|(cin&(a^b));可以理解为除了a,b为1的情况外还有c为1同时 a和b中任意一个为1a^b。
多位数进位加法器
多位数进位加法器的实现有两种方式:串行进位加法器、超前进位加法器。
串行进位加法器就是将1比特加法器级联。
超前进位加法器是对串行全加器进行改良设计的并行加法器以解决普通全加器串联互相进位产生的延迟。
一位全加器的进位的运算逻辑前面的式子是(A^B)这里是(A|B)对结果没有影响|包含了^:
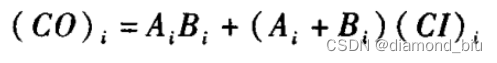
其中令进位函数Gi = AiBi 令进位传送函数Pi = Ai + Bi;
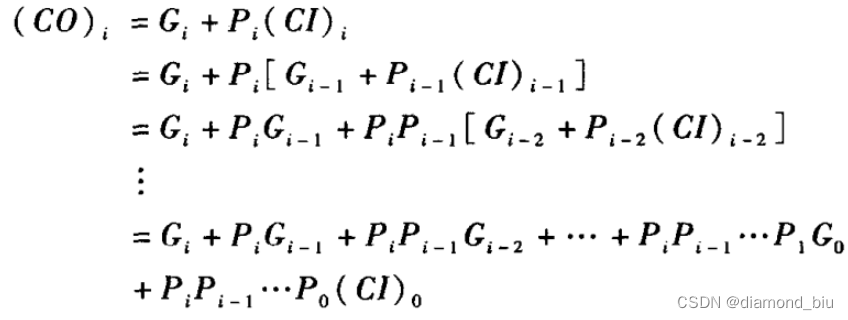
对于4比特超前进位加法器来说进位输出如下:
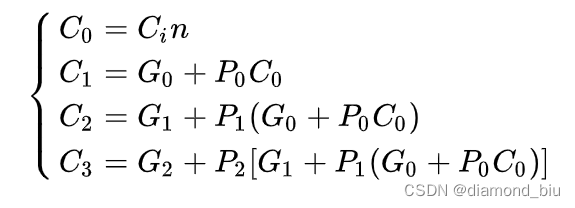
Si=Ai^Bi^(CI)i对应的(CI)i=(CO)i-1即Si=Ai^Bi^(CO)i-1。通过前面的推导已经得出了可得:
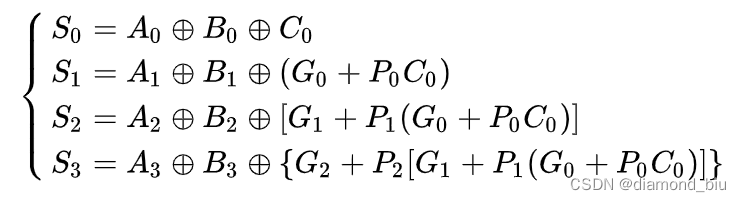
- 要点1:需要明确4bit超前进位加法器的原理与推导过程上一位运算的输出CO是下一位运算的输入CI
COi=(Ai&Bi)|(CIi&(Ai|Bi))。 - 要点2:仿真自测时定义了一个8bit数num每个时钟周期累加1将低4比特和高4比特赋值给A和B需要注意的是给num赋初值要不然仿真波形一片红
`timescale 1ns/1ns
module lca_4(
input [3:0] A_in ,
input [3:0] B_in ,
input C_1 ,
output wire CO ,
output wire [3:0] S
);
wire[3:0] g,p,c;
assign p=A_in|B_in;
assign g=A_in&B_in;
assign c[0]=g[0]|(p[0]&C_1);
assign c[1]=g[1]|(p[1]&(g[0]|(p[0]&C_1)));
assign c[2]=g[2]|(p[2]&(g[1]|(p[1]&(g[0]|(p[0]&C_1)))));
assign c[3]=g[3]|(p[3]&(g[2]|(p[2]&(g[1]|(p[1]&(g[0]|(p[0]&C_1)))))));
assign CO=c[3];
assign S=A_in^B_in^{c[2:0],C_1};
endmodule
测试代码:
`timescale 1ns/1ns
module testbench();
reg[3:0] A_in,B_in;
reg C_1;
wire CO;
wire[3:0] S;
reg[7:0] num;
lca_4 U1(.A_in(A_in),.B_in(B_in),.C_1(C_1),.CO(CO),.S(S));
initial begin
C_1=0;
num=0;
end
always #10 begin
num=num+1;
A_in<=num[3:0];
B_in<=num[7:4];
end
endmodule
VL13 优先编码器电路①
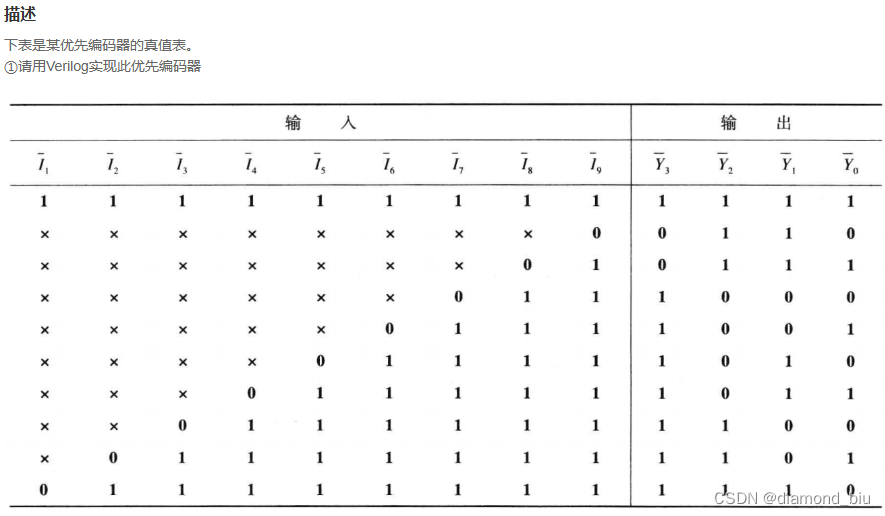
要点1:题目给的是I1-I9注意顺序。
要点2:case、casez和casex三者都是可以综合的。case进行全等匹配casez忽略?或z对应的位进行匹配casex忽略x、?或z对应的位进行匹配。
`timescale 1ns/1ns
module encoder_0(
input [8:0] I_n,
output reg [3:0] Y_n
);
always@(I_n)begin
casez(I_n)
9'b111111111:Y_n<=4'b1111;
9'b0????????:Y_n<=4'b0110;
9'b10???????:Y_n<=4'b0111;
9'b110??????:Y_n<=4'b1000;
9'b1110?????:Y_n<=4'b1001;
9'b11110????:Y_n<=4'b1010;
9'b111110???:Y_n<=4'b1011;
9'b1111110??:Y_n<=4'b1100;
9'b11111110?:Y_n<=4'b1101;
9'b111111110:Y_n<=4'b1110;
endcase
end
endmodule
要点3:《CPU设计实战》这本书中提到在CPU设计中必须遵守的硬性规定是代码中禁止出现casez、casex因此可以采用如下写法看Y9~Y0中出现的第一个0的位置。
`timescale 1ns/1ns
module encoder_0(
input [8:0] I_n,
output [3:0] Y_n
);
assign Y_n=(~I_n[8])?4'b0110:
(~I_n[7])?4'b0111:
(~I_n[6])?4'b1000:
(~I_n[5])?4'b1001:
(~I_n[4])?4'b1010:
(~I_n[3])?4'b1011:
(~I_n[2])?4'b1100:
(~I_n[1])?4'b1101:
(~I_n[0])?4'b1110:
4'b1111;
endmodule
VL14 用优先编码器①实现键盘编码电路

题目描述的不是很清楚。
要点1:GS:按下为1不按为0需要注意的是最后assign GS=(S_n==10'b1111111111)?1'b0:1'b1;并不能只判断S_n[0]==1因为其他按键9~1被按下时S_n[0]也为0;
要点2:最终的输出需要对译码结果取反assign L=~Y_n;
`timescale 1ns/1ns
module encoder_0(
input [8:0] I_n ,
output [3:0] Y_n
);
assign Y_n=(~I_n[8])?4'b0110:
(~I_n[7])?4'b0111:
(~I_n[6])?4'b1000:
(~I_n[5])?4'b1001:
(~I_n[4])?4'b1010:
(~I_n[3])?4'b1011:
(~I_n[2])?4'b1100:
(~I_n[1])?4'b1101:
(~I_n[0])?4'b1110:
4'b1111;
endmodule
module key_encoder(
input [9:0] S_n ,
output wire[3:0] L ,
output wire GS
);
wire[3:0] Y_n;
encoder_0 U1(.I_n(S_n[9:1]),.Y_n(Y_n));
//GS:按下为1不按为0
assign GS=(S_n==10'b1111111111)?1'b0:1'b1;
assign L=~Y_n;
endmodule
VL16 使用8线-3线优先编码器Ⅰ实现16线-4线优先编码器
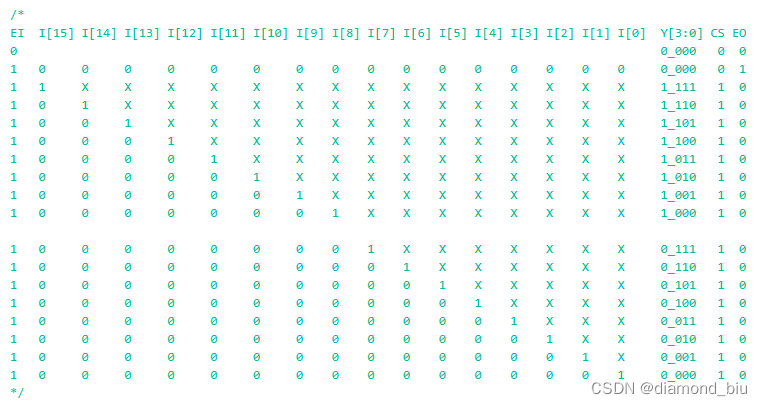
要点1:编码的结果为000时可能有三种情况1译码器没有使能不工作此时GS=0;EO=0;2译码器再工作但无输入,GS=0;EO=1;;3译码器在工作且有输入输入为0000_0001,GS=1;EO=0;;
要点2:参考SNx4HC148 8-Line to 3-Line Priority Encoders理解如何使用两个8-3译码器得到一个16-4译码器。实际就是将两个8-3译码器的EO与EI连接输出取或运算作为译码结果的低3位I[2:0]高位译码器的GS作为译码结果I[3](1表示高位译码器在译码15~80表示在译码0~7)。最终的GS为GS1|GS2。
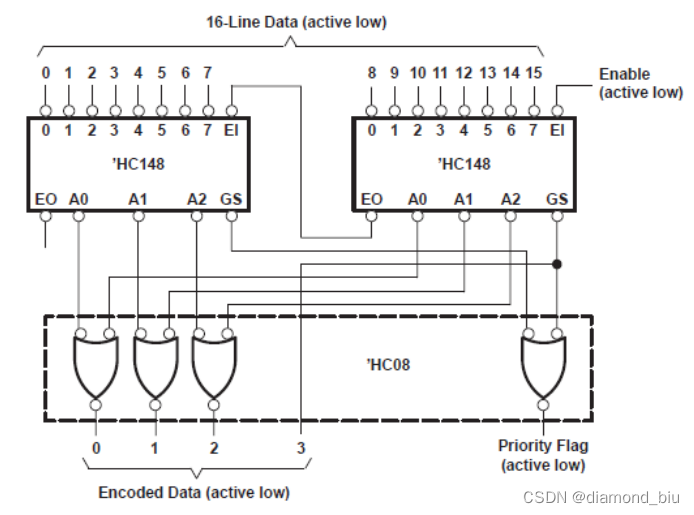
真值表如下:
`timescale 1ns/1ns
module encoder_83(
input [7:0] I ,
input EI ,
output wire [2:0] Y ,
output wire GS ,
output wire EO
);
assign {Y,GS,EO}=(~EI)?5'b00000:
I[7]?5'b11110:
I[6]?5'b11010:
I[5]?5'b10110:
I[4]?5'b10010:
I[3]?5'b01110:
I[2]?5'b01010:
I[1]?5'b00110:
I[0]?5'b00010:
5'b00001;
endmodule
module encoder_164(
input [15:0] A ,
input EI ,
output wire [3:0] L ,
output wire GS ,
output wire EO
);
wire GS1,GS2,EO1;
wire[2:0] L1,L2;
encoder_83 U1(.I(A[15:8]),.EI(EI),.Y(L1[2:0]),.GS(GS1),.EO(EO1));
encoder_83 U2(.I(A[7:0]),.EI(EO1),.Y(L2[2:0]),.GS(GS2),.EO(EO));
assign L={GS1,L1|L2};
assign GS=GS1|GS2;
endmodule
VL17 用3-8译码器实现全减器
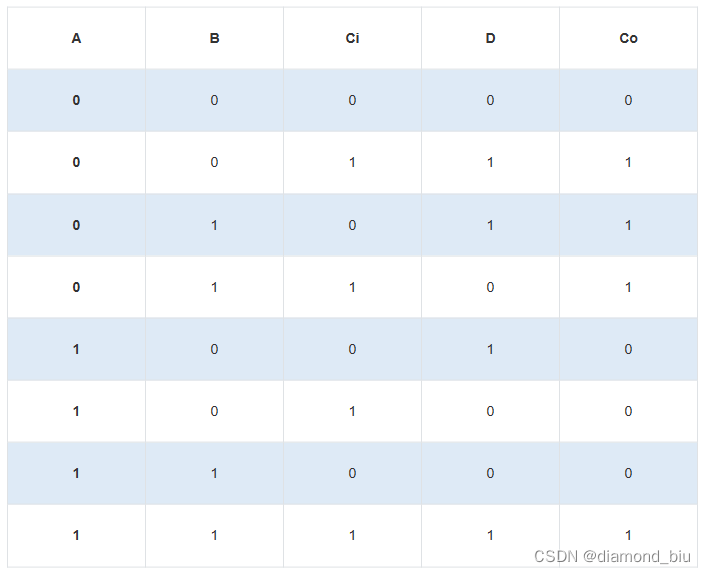
要点1:最小项与最大项。
全减器真值表如下可以看到对于A B Ci来说从上到下一次为最小项m0~m7因此D=m1+m2+m4+m7Co=m1+m2+m3+m7。将A B Ci接入题中3-8译码器译码器输出Yi对应的是mi取反。
`timescale 1ns/1ns
module decoder_38(
input E1_n ,
input E2_n ,
input E3 ,
input A0 ,
input A1 ,
input A2 ,
output wire Y0_n ,
output wire Y1_n ,
output wire Y2_n ,
output wire Y3_n ,
output wire Y4_n ,
output wire Y5_n ,
output wire Y6_n ,
output wire Y7_n
);
wire E ;
assign E = E3 & ~E2_n & ~E1_n;
assign Y0_n = ~(E & ~A2 & ~A1 & ~A0);
assign Y1_n = ~(E & ~A2 & ~A1 & A0);
assign Y2_n = ~(E & ~A2 & A1 & ~A0);
assign Y3_n = ~(E & ~A2 & A1 & A0);
assign Y4_n = ~(E & A2 & ~A1 & ~A0);
assign Y5_n = ~(E & A2 & ~A1 & A0);
assign Y6_n = ~(E & A2 & A1 & ~A0);
assign Y7_n = ~(E & A2 & A1 & A0);
endmodule
module decoder1(
input A ,
input B ,
input Ci ,
output wire D ,
output wire Co
);
wire E3=1,E2_n=0,E1_n=0;
wire m0,m1,m2,m3,m4,m5,m6,m7;
decoder_38 U1(.E1_n(E1_n),.E2_n(E2_n),.E3(E3),
.A0(Ci),.A1(B),.A2(A),
.Y0_n(m0),.Y1_n(m1),.Y2_n(m2),.Y3_n(m3),.Y4_n(m4),.Y5_n(m5),.Y6_n(m6),.Y7_n(m7));
assign D=(~m1)|(~m2)|(~m4)|(~m7);
assign Co=(~m1)|(~m2)|(~m3)|(~m7);
endmodule
VL19 使用3-8译码器①实现逻辑函数
要点1:熟悉逻辑函数的两种表示形式最小项和最大项。以本题为例将逻辑表达式写为最小项形式即L=m1+m3+m6+m7又因为3-8译码器的输出恰好是最小项取反以ABC=111为例对应最小项m7=1对应译码器输出为Y7=0因此只需要将译码器输出取反即为对应的最小项的值。

要点2:题目中表达式的最大项表达式为L=M0+M3+M4+M5其中M0=A+B+C。最大项表式可以由最小项表示推导出。
//module decoder_38省略题目中直接给出了
module decoder0(
input A ,
input B ,
input C ,
output wire L
);
wire E3=1,E2_n=0,E1_n=0;
wire m0,m1,m2,m3,m4,m5,m6,m7;
decoder_38 U1(.E1_n(E1_n),.E2_n(E2_n),.E3(E3),
.A0(C),.A1(B),.A2(A),
.Y0_n(m0),.Y1_n(m1),.Y2_n(m2),.Y3_n(m3),.Y4_n(m4),.Y5_n(m5),.Y6_n(m6),.Y7_n(m7));
assign L=(~m1)|(~m3)|(~m6)|(~m7);
endmodule
Verilog进阶挑战
Verilog企业真题
常见数字IC手撕代码
- 异步fifo。格雷码的镜像对称。格雷码和二进制的互相转换。
- 同步fifo。
- 除法器。
- Wallace乘法器。
- Booth乘法器。
- Booth+Wallace乘法器。
- 超前进位加法器。
- 边沿检测输入消抖毛刺消除。
- 异步复位同步释放。
- 三种计数器。二进制移位移位+反向。
- 无毛刺时钟切换。
- 串行-并行CRC。ARM。
- 线性反馈移位寄存器。
- 握手实现CDC。
- AXI-S接口2T一次传输1T一次传输1T一次传输还要寄存器寄存。Nvidia考题Xilinx有例程。
- 其他简单功能的HDL实现以及状态转换图。序列检测 回文序列检测NVIDIA奇、偶、半分频小数分频自动售货机。