

自然语言入门NRL-数据处理基础知识
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
数据处理基础知识 Data Processing Basics
【写在前面以下所讲都基于你对机器学习有一定的基础知识至少应该知道什么激活函数反向更新梯度下降全连接层等等基本术语不懂的可以先去补一下深度学习基本概念、CNN、VGGNet】
数据可分为数值数据numberic features和非数值数据类别数据 categorical features。在训练模型之前我们需要把categorical features转化为机器学习模型能理解的数值特征。

拿上述这张表举例年龄是数值特征numberic features没问题35>31 ok 性别是二元特征binary feature可以用1代表男人0代表女人。
国籍Nationality是一个类别特征categorical features。一共197个国家。我们需要用数字向量numeric vectors来表示国家。国籍如果用1代表US2代表China3代表India那US+Chain=India么显然不对。所以这个时候我们得用one-hot encoding
US -> [1,0,0, 0,.,0].
China -> [0, 1, 0,0,..,0].
India -> [0, 0, 1,0,..,0].
所以上述那张表可以表示为
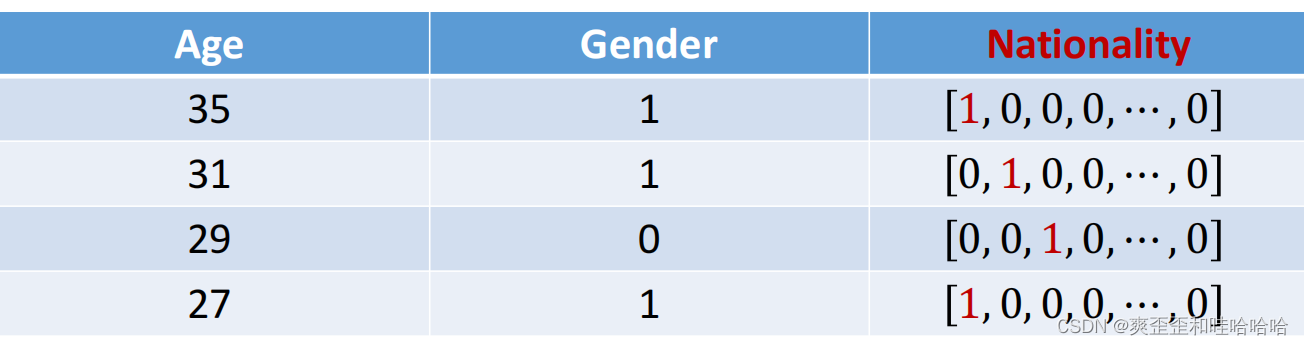
我们使用199-dim 数值向量表示人的特征(年龄、性别、国籍)。
•eg将(age, gender, nationality)转换为vector

懂了上述道理我们来讲处理文本数据Processing Text Data
处理文本数据Processing Text Data
Step 1: 分词(文本到单词) Tokenization (Text to Words)
给定一段文本 text (string), e.g.,
S = “… to be or not to be…”.
我们先拆分文本成一个词语words的list
L = […, to, be, or, not, to, be, …]
Step 2计算字频 Count Word Frequencies
统计词频并按照词频大小排序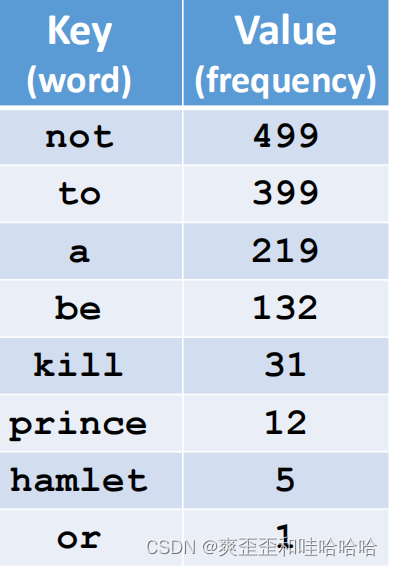
Step 3One-Hot 编码 Encoding
将每个单词映射到索引 。Map every word to its index.
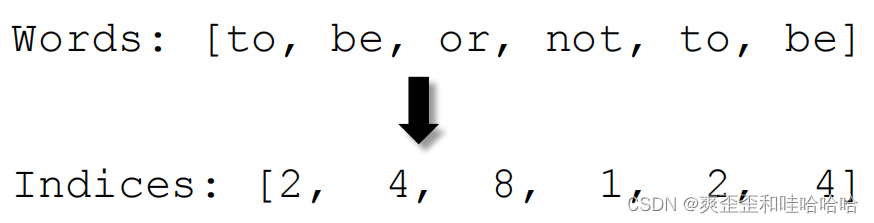
上述表就变成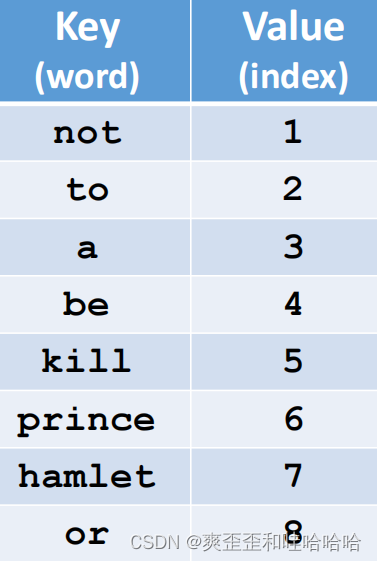
如果需要将每个index转换为 one-hot vector.one-hot的dim长度为单词的词数。然后用没有的没有的index或者null来代替拼写错误的词比如说bi英语里没有bi这个单词。

参考
https://github.com/wangshusen/DeepLearning