

简单又高大上的项目(应付复试的小demo)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
简单又高大上的项目
图形识别、自然语言处理(语言识别、语音转文字)、文字识别、区块链
1.java实现一个基本的文字识别
引入依赖
<!-- ai 文字识别 -->
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.16.13</version>
</dependency>
picToWord.Sample
调用百度智能云API: https://cloud.baidu.com/?_=1675227888185
package picToWord;
import java.util.*;
import org.json.JSONArray;
import org.json.JSONObject;
import com.baidu.aip.ocr.AipOcr;
public class Sample {
//设置APPID/AK/SK
public static final String APP_ID = "30002607";
public static final String API_KEY = "lQ9sTDm6Bb5QQXnt8iGLuY0x";
public static final String SECRET_KEY = "vhboZlmy0x0FuZYxWnFbrTNHBaUDzwKn";
public static void main(String[] args) {
// 初始化一个AipOcr
AipOcr client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
// client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
// client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 可选:设置log4j日志输出格式,若不设置,则使用默认配置
// 也可以直接通过jvm启动参数设置此环境变量
System.setProperty("aip.log4j.conf", "path/to/your/log4j.properties");
// 调用接口
// String path = "test.jpg";
String path = "D:/vue/Ai/view.jpg";
JSONObject res = client.basicGeneral(path, new HashMap<String, String>());
// getJSONObject是用来转换对象的,一般是{}这个符号括起来的内容,而getJSONArray是用来转换数组的,一般是[]这个符号括起来的内容,
// 参考 https://blog.csdn.net/weixin_44421896/article/details/124076501
JSONArray words_result = res.getJSONArray("words_result");
for (int i = 0; i < words_result.length(); i++) {
// System.out.println(words_result.getJSONObject(i));
JSONObject jsonObject = words_result.getJSONObject(i);
Object words = jsonObject.get("words");
//转化为string类型的
String s = (String) words;
System.out.println(s);
}
System.out.println(res.toString(2));
}
}
2.实现完整的web项目(文字识别)
1.文字识别OCR原理: https://blog.csdn.net/q123456789098/article/details/79760579?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167505712716782425620880%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=167505712716782425620880&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~pc_rank_34-17-79760579-null-null.142v71pc_new_rank,201v4add_ask&utm_term=%E6%96%87%E5%AD%97%E8%AF%86%E5%88%ABOCR%E5%8E%9F%E7%90%86&spm=1018.2226.3001.4187
2.OpenCV+OCR 图像处理字符识别原理及代码:
(6条消息) OpenCV+OCR 图像处理字符识别原理及代码_p312011150的博客-CSDN博客
所需依赖
<!-- ai 文字识别 -->
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.16.13</version>
</dependency>
<!-- thymeleaf-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
2.1 utils.AiUtils
package com.example.demo.utils;
import com.baidu.aip.ocr.AipOcr;
import org.json.JSONArray;
import org.json.JSONObject;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.HashMap;
public class AiUtils {
//设置APPID/AK/SK
public static final String APP_ID = "30002607";
public static final String API_KEY = "lQ9sTDm6Bb5QQXnt8iGLuY0x";
public static final String SECRET_KEY = "vhboZlmy0x0FuZYxWnFbrTNHBaUDzwKn";
public static String picToWords(MultipartFile file) throws IOException {
// 初始化一个AipOcr
AipOcr client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);
/**
* 通用文字识别 client.basicGeneral(image, options); 用户向服务请求识别某张图中的所有文字。
* 身份证识别 client.idcard(image, idCardSide, options); 用户向服务请求识别身份证,身份证识别包括正面和背面。
* 银行卡识别 client.bankcard(image, options); 识别银行卡并返回卡号和发卡行。
* 驾驶证识别 client.drivingLicense(image, options); 对机动车驾驶证所有关键字段进行识别。
* 行驶证识别 client.vehicleLicense(image, options);
* 车牌识别 client.plateLicense(image, options); 识别机动车车牌,并返回号牌号码和车牌颜色。
* 火车票识别 client.trainTicket(image,EImgType.FILE, options) 支持对红、蓝火车票的13个关键字段进行结构化识别,包括车票号码、始发站、目的站、车次、日期、票价、席别、姓名、座位号、身份证号、售站、序列号、时间。
* 数字识别 client.numbers(image,options); 对图片中的数字进行提取和识别,自动过滤非数字内容,仅返回数字内容及其位置信息,识别准确率超过99%。
* 二维码识别 client.qrcode(file, options); 对图片中的二维码、条形码进行检测和识别,返回存储的文字信息。
* 手写文字识别 client.handwritingUrl(url, options); client.handwriting(file, options); 支持对图片中的手写中文、手写数字进行检测和识别,针对不规则的手写字体进行专项优化,识别准确率可达90%以上。
*/
// 调用接口
JSONObject res = client.basicGeneral(file.getBytes(), new HashMap<String, String>());
// getJSONObject是用来转换对象的,一般是{}这个符号括起来的内容,而getJSONArray是用来转换数组的,一般是[]这个符号括起来的内容,
// 参考 https://blog.csdn.net/weixin_44421896/article/details/124076501
JSONArray words_result = res.getJSONArray("words_result");
String result = "";
for (int i = 0; i < words_result.length(); i++) {
// System.out.println(words_result.getJSONObject(i));
JSONObject jsonObject = words_result.getJSONObject(i);
Object words = jsonObject.get("words");
//转化为string类型的
String s = (String) words;
result += s + "";
// System.out.println(result);
}
return result;
}
}
2.2 controller.AiController
package com.example.demo.controller;
import com.example.demo.utils.AiUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@RestController
public class AiController {
@RequestMapping("/pic")
public String PicToWord(@RequestParam("file") MultipartFile file) throws IOException {
String res = AiUtils.picToWords(file);
System.out.println(res);
return res;
}
}
2.3resources\templates\index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Ai Studio</title>
<!-- 引入样式 -->
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
</head>
<body>
<h1>普通文本识别</h1>
<div id="app">
<el-upload
class="upload-demo"
drag
action="/pic"
multiple
:on-success="dealSuccess">
<i class="el-icon-upload"></i>
<div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>
<div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>
</el-upload>
<!-- 输出图片中文字的内容 -->
<!-- <el-input v-model="words" ></el-input>-->
<el-input
type="textarea"
:rows="4"
v-model="words">
</el-input>
<h1>身份证识别</h1>
<h1>票据识别</h1>
</div>
</body>
<!-- import Vue before Element -->
<script src="https://unpkg.com/vue@2/dist/vue.js"></script>
<!-- import JavaScript 引入组件库 -->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<script>
new Vue({
el: '#app',
data:{
words:''
},
methods:{
dealSuccess(res,file){
console.log("res",res)
console.log("file",file)
this.words = res;
}
}
})
</script>
</html>
3. 人工智能项目背后知识学习
参考: https://www.paddlepaddle.org.cn/tutorials/projectdetail/4676538
这方面我也没有搞得很明白,所以我想通过考研,在研究生阶段来继续对它进行了解
学习项目背后的人工智能相关的技术和算法。以及常见名词,概念
1.通过 百度PaddlePaddle平台学习。
2.通过 bilibili 学习
4. 图像识别的实现及前后端分离(图像识别)
4.1controller.AiController
package com.example.demo.controller;
import com.example.demo.utils.AiFace;
import com.example.demo.utils.AiUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@RestController
public class AiController {
@RequestMapping("/img")
public String ImgToWord(@RequestParam("file") MultipartFile file) throws IOException {
String res = AiFace.imgRecognition(file);
System.out.println(res);
return res;
}
}
4.2utils.AiFace
package com.example.demo.utils;
import com.baidu.aip.imageclassify.AipImageClassify;
import org.json.JSONArray;
import org.json.JSONObject;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.HashMap;
public class AiFace {
//设置APPID/AK/SK
public static final String APP_ID = "30013654";
public static final String API_KEY = "q52mwPN5nWYGBGrApmGaEwIE";
public static final String SECRET_KEY = "eSVgkcpNsSWb51wZIdFFZbeujyf3bOHY";
public static String imgRecognition(MultipartFile file) throws IOException {
// 初始化一个AipImageClassify
AipImageClassify client = new AipImageClassify(APP_ID, API_KEY, SECRET_KEY);
/** 通用物体和场景识别 client.advancedGeneral(image, options); 输出图片中的多个物体及场景标签。
* 植物识别 client.plantDetect(image, options)
* 动物识别 client.animalDetect(image, options)
* 果蔬识别 client.ingredient(image, options); 输出图片中的果蔬食材结果。
* logo商标识别 client.logoSearch(image, options);
* 菜品识别 client.dishDetect(image, options); 输出图片的菜品名称、卡路里信息、置信度.
* 通用物体和场景识别 client.advancedGeneral(image, options); 输出图片中的多个物体及场景标签。
* 车辆识别 client.carDetect(image, options); 即对于输入的一张图片(可正常解码,且长宽比适宜),输出图片的车辆品牌及型号。
* score:置信度,0-1 , 是有多大几率是什么
*/
// 调用接口
// String path = "D:/vue/Ai/pic1.png";
JSONObject res = client.advancedGeneral(file.getBytes(), new HashMap<String, String>());
// System.out.println(res.toString(2));
return res.toString(2);
}
}
4.3index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Ai Studio</title>
<!-- 引入样式 -->
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
<style>
.a1{
align-items: center;
color: #f0c239;
width: 800px;
height: 600px;
border: 1px solid #5F9EA0;
margin: auto;
text-align: center;
}
.el-textarea__inner{
height: 200px;
}
</style>
</head>
<body>
<div id="app">
<div class="a1" >
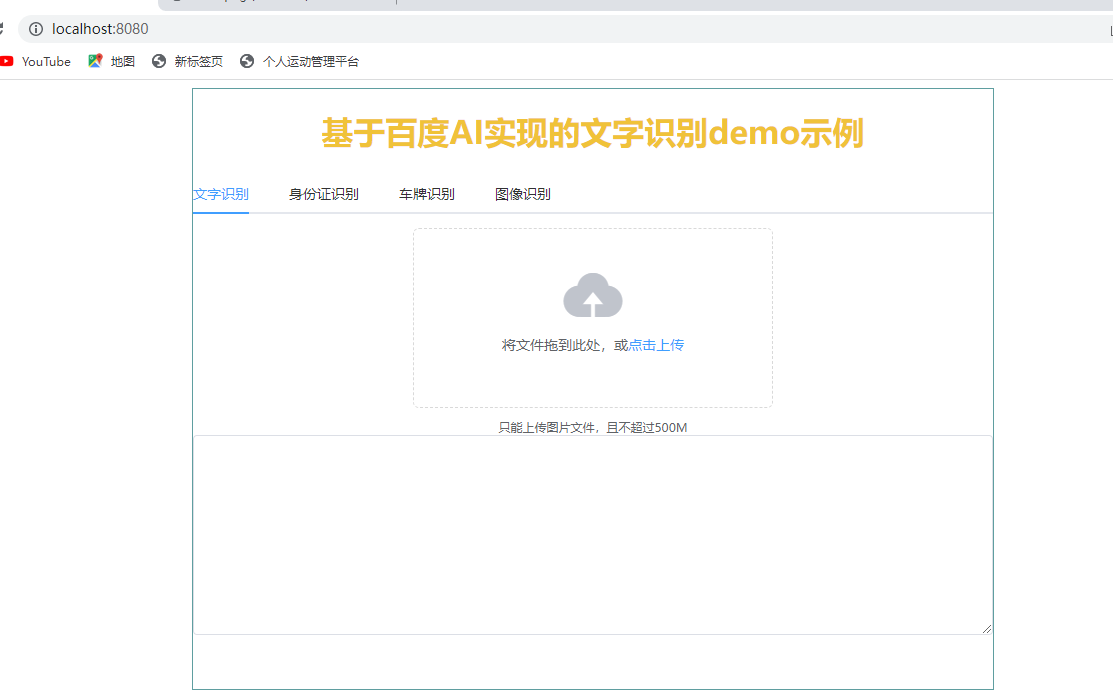
<h1 >基于百度AI实现的文字识别demo示例</h1>
<el-tabs v-model="activeName" >
<el-tab-pane label="文字识别" name="first">
<!-- 文字识别-->
<el-upload
class="upload-demo"
drag
action="/pic"
multiple
:on-success="dealSuccess">
<i class="el-icon-upload"></i>
<div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>
<div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>
</el-upload>
<!-- 输出图片中文字的内容 -->
<!-- <el-input v-model="words" ></el-input>-->
<el-input
type="textarea"
:rows="10"
v-model="words">
</el-input>
</el-tab-pane>
<el-tab-pane label="身份证识别" name="second">身份证识别</el-tab-pane>
<el-tab-pane label="车牌识别" name="third">
<el-upload
class="upload-demo"
drag
action="/car"
multiple
:on-success="carRecognition">
<i class="el-icon-upload"></i>
<div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>
<div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>
</el-upload>
<el-input
type="textarea"
:rows="10"
v-model="carpic">
</el-input>
</el-tab-pane>
<el-tab-pane label="图像识别" name="fourth">
<el-upload
class="upload-demo"
drag
action="/img"
multiple
:on-success="ImageRecognition">
<i class="el-icon-upload"></i>
<div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>
<div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>
</el-upload>
<el-input
type="textarea"
:rows="8"
v-model="imgpic">
</el-input>
</el-tab-pane>
</el-tabs>
</div>
<!-- <h1>普通文本识别</h1>-->
<!-- <el-upload-->
<!-- class="upload-demo"-->
<!-- drag-->
<!-- action="/pic"-->
<!-- multiple-->
<!-- :on-success="dealSuccess">-->
<!-- <i class="el-icon-upload"></i>-->
<!-- <div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>-->
<!-- <div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>-->
<!-- </el-upload>-->
<!--<!– 输出图片中文字的内容 –>-->
<!--<!– <el-input v-model="words" ></el-input>–>-->
<!-- <el-input-->
<!-- type="textarea"-->
<!-- :rows="4"-->
<!-- v-model="words">-->
<!-- </el-input>-->
<!-- <hr/>-->
<!-- <h1>身份证识别</h1>-->
<!-- <hr/>-->
<!-- <h1>车牌识别</h1>-->
<!-- <el-upload-->
<!-- class="upload-demo"-->
<!-- drag-->
<!-- action="/car"-->
<!-- multiple-->
<!-- :on-success="carRecognition">-->
<!-- <i class="el-icon-upload"></i>-->
<!-- <div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>-->
<!-- <div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>-->
<!-- </el-upload>-->
<!-- <el-input-->
<!-- type="textarea"-->
<!-- :rows="4"-->
<!-- v-model="carpic">-->
<!-- </el-input>-->
<!-- <hr/>-->
<!-- <h1>图像识别</h1>-->
<!-- <el-upload-->
<!-- class="upload-demo"-->
<!-- drag-->
<!-- action="/img"-->
<!-- multiple-->
<!-- :on-success="ImageRecognition">-->
<!-- <i class="el-icon-upload"></i>-->
<!-- <div class="el-upload__text">将文件拖到此处,或<em>点击上传</em></div>-->
<!-- <div class="el-upload__tip" slot="tip">只能上传图片文件,且不超过500M</div>-->
<!-- </el-upload>-->
<!-- <el-input-->
<!-- type="textarea"-->
<!-- :rows="4"-->
<!-- v-model="imgpic">-->
<!-- </el-input>-->
</div>
</body>
<!-- import Vue before Element -->
<script src="https://unpkg.com/vue@2/dist/vue.js"></script>
<!-- import JavaScript 引入组件库-->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<script>
new Vue({
el: '#app',
data:{
words:'',
imgpic:'',
carpic:'',
activeName:'first'
},
methods:{
dealSuccess(res,file){
console.log("res",res)
console.log("file",file)
this.words = res;
},
ImageRecognition(res,file){
console.log("res",res)
console.log("file",file)
//将Array数组转换成JSON格式数组
this.imgpic = JSON.stringify(res.result);
},
carRecognition(res,file){
console.log("res",res)
this.carpic = JSON.stringify(res.words_result);
},
}
})
</script>
</html>
5.NLP自然语言处理(重点)开发及Python开发介绍
NLP自然语言处理 。 需要了解:NLP特点,优势、劣势,即基本实现原理。
6.区块链的基本理论知识
区块链技术与应用 学习的课程 :https://study.163.com/course/introduction/1006145002.htm?inLoc=ss_ssjg_tjlb_区块链
比特币和区块链 区别:跟先有鸡还是先有蛋是一样的道理
区块链主要是 概念多
主要考察:
- 1.区块链的数据结构 链式结构 默克尔树...
- 2.密码学 hash ,对称加密,非对称密码...
- 3.共识算法
区块链
区块链: 区块链就是一个大型分布式数据库,并且这个数据库是只能 查询和新增,不能删除和修改。
区块链特点: 只能查询 新增,不能删除和修改, 每一个群成员就是一个完整的数据库(比如 QQ群 微信群)
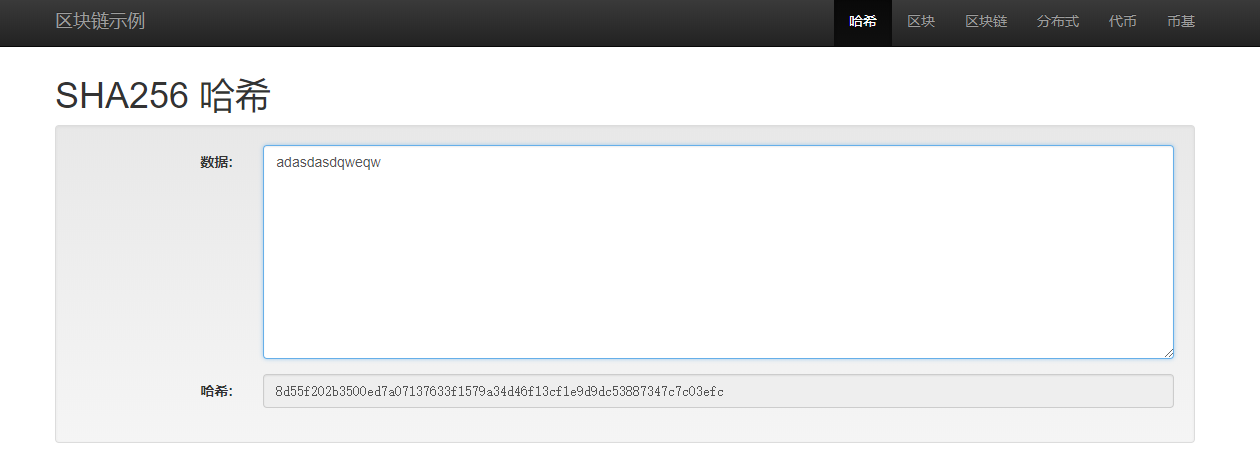
Hash
任意长度的数据和字符串 转化为一个固定长度的字符串
https://andersbrownworth.com/blockchain/hash
区块
比特币
中本聪 --论文 -- 比特币 一种点对点的电子现金系统
比特币: 1枚比特币= 211974 RBM
比特币设计原理:
设计一种数字货币需要考虑哪些问题?
中心化机构(银行、微信、支付宝)
非中心化的机构
7.以太坊和智能合约
ETH(以太坊)
区块链 2.0
智能合约(一个脚本代码)
智能合约相当于是跑在区块链上的代码
区块链共识算法:特点:
分布式共识算法
POW: 工作量证明(prove of work)
区块链共识算法总结(PBFT,Raft,PoW,PoS,DPoS,Ripple) - 小尾学长 - 博客园 (cnblogs.com)
POS:股权证明
8.人工智能基础及基本概念
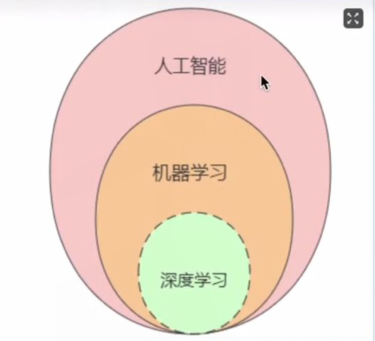
1.机器学习与深度学习和人工智能又是什么关系?
其实他们之间是包含与被包含的关系,下面展示了他们之间的关系图,如下所示

2.机器学习形式分类
机器学习是人工智能的主要表现形式,其学习形式主要分为:有监督学习、无监督学习、半监督学习等,对于“监督”一词,其实你可以把这个词理解为习题的“参考答案”,专业术语叫做“标记”。比如有监督学习就是有参考答案的学习,而无监督就是无参考答案。
1)有监督学习
有监督学习(supervised learning),需要你事先准备好要输入数据(训练样本)与真实的输出结果(参考答案),然后通过计算机的学习得到一个预测模型,再用已知的模型去预测未知的样本,这种方法被称为有监督学习。这也是最常见的机器学习方法。简单来说,就像你已经知道了试卷的标准答案,然后再去考试,相比没有答案就去考试准确率会更高,也更容易。
2)无监督学习
理解了有监督学习,那么无监督学习理解起来也变的容易。所谓无监督学习(unsupervised learning)就是在没有“参考答案”的前提下,计算机仅根据样本的特征或相关性,就能实现从样本数据中训练出相应的预测模型。
除了上述两种学习形式外,还有半监督学习和强化学习,有兴趣可以自己研究一下。
一句话描述学习方式
监督学习:训练数据包括正确的结果。
无监督学习:训练数据不包括正确的结果。
半监督学习:训练数据包含少量正确结果。
强化学习:根据每次结果收获的奖惩进行学习,根据结果实现优化。
监督学习包含:线性回归、逻辑回归、决策树、神经网铬、卷积神经网络、循环神经网铬等。
无监督学习:聚类算法。
混合学习:一般指监督学习+无鉴督学习
3.预测结果分类
根据预测结果的类型,我们可以对上述学习形式做具体的问题划分,这样就可以具体到实际的应用场景中,比如有监督学习可以划分为:回归问题 和 分类问题。如果预测结果是离散的,通常为分类问题,而为连续的,则是回归问题。
1)回归&分类
连续和离散是统计学中的一种概念,全称为“连续变量”和“离散变量”。比如身高,从1.2m到1.78m这个长高的过程就是连续的,身高只随着年龄的变化一点点的长高。那么什么是“离散变量”呢?比如超市每天的销售额,这类数据就是离散的,因为数据不是固定,可能多也可能少。关于什么是“回归”和“分类”在后续内容中会逐步讲解。
2)聚类
无监督学习是一种没有“参考答案”的学习形式,它通过在样本之间的比较、计算来实现最终预测输出,比如聚类问题,那什么是“聚类”?其实可以用一个成语表述“物以类聚,人以群分“,将相似的样本聚合在一起后,然后进行分析。关于聚类也会在后续内容中逐步讲解。
在学习机器学习技术的过程中,我们会遇到很多专业术语或者生僻词汇,这些名词大多数来自于数学或者统计学领域,比如模型、数据集、样本、熵,以及假设函数、损失函数等,这些属词汇于基本的常识,但是如果你第一次接触的话,也会感觉到些许惊慌。在下一节我们将介绍机器学习的常用术语。
本节需要知道的知识点:
1、人工智能、机器学习、深度学习是什么关系?
上面呢个图
2、什么是机器学习?
单从定义上来说,机器学习是一种功能、方法,或者更具体的说是一种算法,它能够赋予机器进行学习的能力,从而使机器完成一些通过编程无法直接实现的功能。但从具体的实践意义来说,其实机器学习是利用大量数据训练出一个最优模型,然后再利用此模型预测出其他数据的一种方法。比如要识别猫、狗照片就要拿它们各自的照片提炼出相应的特征(比如耳朵、脸型、鼻子等),从而训练出一个俱有预测能力的模型。
3、机器学习有哪些学习形式?
有监督学习、无监督学习、半监督学习、强化学习
4、预测结果有哪些类型,分别是什么?
回归&分类 和 聚类
9.机器学习专业术语
机器学习常用术语
机器学习是一门专业性很强的技术,它大量地应用了数学、统计学上的知识,因此总会有一些蹩脚的词汇,这些词汇就像“拦路虎”一样阻碍着我们前进,甚至把我们吓跑。因此认识,并理解这些词汇是首当其冲的任务。本节将介绍机器学习中常用的基本概念,为后续的知识学习打下坚实的基础。
机器学习术语
1)模型
模型这一词语将会贯穿整个教程的始末,它是机器学习中的核心概念。你可以把它看做一个“魔法盒”,你向它许愿(输入数据),它就会帮你实现愿望(输出预测结果)。整个机器学习的过程都将围绕模型展开,训练出一个最优质的“魔法盒”,它可以尽量精准的实现你许的“愿望”,这就是机器学习的目标。 如股票预测模型,房价预测模型、天气预测模型....
2)数据集
数据集,从字面意思很容易理解,它表示一个承载数据的集合,如果说“模型”是“魔法盒”的话。那么数据集就是负责给它充能的“能量电池”,简单地说,如果缺少了数据集,那么模型就没有存在的意义了。数据集可划分为“训练集”和“测试集”,它们分别在机器学习的“训练阶段”和"预测输出阶段”起着重要的作用。
3)样本&特征
样本指的是数据集中的数据,一条数据被称为”一个样本”,通常情况下,样本会包含多个特征值期来描述数据,比如现在有一组描述人形态的数据”180 70 25”如果单看数据你会非常茫然,但是用”特征”描述后就会变得容易理解,如下所示:
| 身高 | 体重 | 年龄 |
|---|---|---|
| 180 | 70 | 25 |
| 179 | 68 | 26 |
由上图可知数据集的构成是“一行一样本,一列一特征”。特征值也可以理解为数据的相关性,每一列的数据都与这一列的特征值相关。
4)向量
任何一门算法都会涉及到许多数学上的术语或者公式。在本教程写作的过程中也会涉及到很多数学公式,以及专业的术语,在这里我们先对常用的基本术语做一下简单讲解。
第一个常用术语就是“向量”,向量是机器学习的关键术语。向量在线性代数中有着严格的定义。向量也称欧几里得向量、几何向量、矢量,指具有大小和方向的量。您可以形象地把它的理解为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量对应的量叫做数量(物理学中称标量),数量只有大小,没有方向。向量既有大小又有方向
在机器学习中,模型算法的运算均基于线性代数运算法则,比如行列式、矩阵运算、线性方程等等。其实对于这些运算法则学习起来并不难,它们都有着一定运算规则,只需套用即可,因此你也不必彷徨,可参考向量运算法则。向量的计算可采用NmuPy来实现,如下所示:
import numpy as np
#构建向量数组
a=np.array([-1,2])
b=np.array([3,-1])
#加法
a_b=a+b
#数乘
a2=a*2
b3=b*(-3)
#减法
b_a=a-b
print(a_b,a2,b3,b_a)
#矩阵乘法
a=np.array([1,2],[3,4])
b=np.array([4,3],[2,1])
c=np.matmul(a,b)
print(c)
简而言之,数据集中的每一个样本都是一条具有向量形式的数据。
- 矩阵
矩阵也是一个常用的数据术语,你可以把矩阵看成由向量组成的二维数组,数据集就是以二维矩阵的形式存储数据的,你可以把它形象的理解为电子表格“一行一样本,一列一特征”表现形式如下:
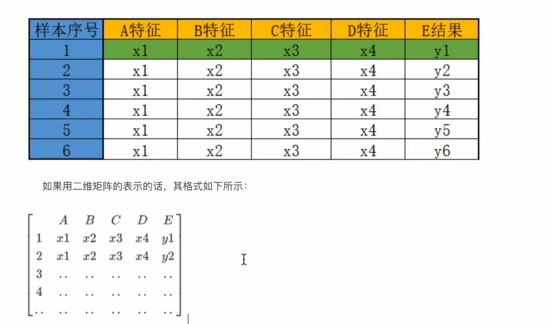
假设函数&损失函数
机器学习在构建模型的过程中会应用大量的数学函数,正因为如此很多初学者对此产生畏惧,那么它们真会有这么可怕吗?其实我认为至少没有你想的那么可怕。从编程角度来看,这些函数就相当于模块中内置好的方法,只需要调用相应的方法就可以达成想要的目的。而要说难点,首先你要理解你的应用场景,然后根据实际的场景去调用相应的方法,这才是你更应该关注的问题。
假设函数和损失函数是机器学习中的两个重要概念,它并非某个模块下的函数方法,而是我们根据实际应用场景确定的一种函数形式,就像你解决数学的应用题目一样,根据题意写出解决问题的方程组。下面分别来看一下它们的含义。
1)假设函数
假设函数(Hypothesis Function)可表述为y=f(x)其中X表示输入数据,而y表示输出的预测结果,而这个结果需要不断的优化才会达到预期的结果,否则会与实际值偏差较大。
2)损失函数
损失函数(Loss Function)又叫目标函数,简写为L(x),这里的×是假设函数得出的预测结果“y”,如果L(x)的返回值越大就表示预测结果与实际偏差越大,越小则证明预测值越来越“逼近”真实值,这才是机器学习最终的目的。因此损失函数就像一个度量尺,让你知道“假设函数”预测结果的优劣,从而做出相应的优化策略。
3)优化方法
“优化方法”可以理解为假设函数和损失函数之间的沟通桥梁。通过L(x)可以得知假设函数输出的预测结果与实际值的偏差值,当该值较大时就需要对其做出相应的调整,这个调整的过程叫做“参数优化”,而如何实现优化呢?这也是机器学习过程中的难点。其实为了解决这一问题,数学家们早就给出了相应的解决方案,比如梯度下降、牛顿方与拟牛顿法、共轭梯度法等等。因此我们要做的就是理解并掌握“科学巨人”留下的理论、方法。
对于优化方法的选择,我们要根据具体的应用场景来选择应用哪一种最合适,因为每一种方法都有自己的优劣势,所以只有合适的才是最好的。
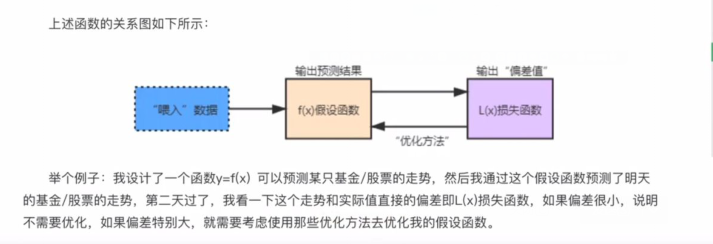
拟合&过拟合&欠拟合
拟合是机器学习中的重要概念,也可以说,机器学习的研究对象就是让模型能更好的拟合数据,那到底如何理解“拟合”这个词呢?
1)拟合
形象地说,“拟合”就是把平面坐标系中一系列散落的点,用一条光滑的曲线连接起来,因此拟合也被称为“曲线拟合”。拟合的曲线一般用函数进行表示,但是由于拟合曲线会存在许多种连接方式,因此就会出现多种拟合函数。通过研究、比较确定一条最佳的“曲线”也是机器学习中一个重要的任务。如下图所示,展示一条拟合曲线(蓝色曲线):
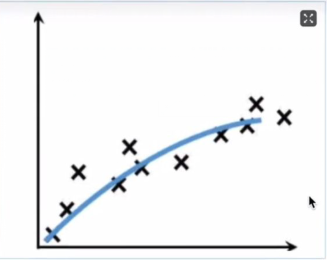
如何理解拟合,举个例子:上图假设为超市每天的营业额,通过对历史数据拟合出来一条拟合曲线,通过这个拟合曲线去预测未来的营业额。
提示:很多和数学相关的编程语言都内置计算拟合曲线的函数,比如MATLAB、Python Scipy等,在后续内容中还会介绍。
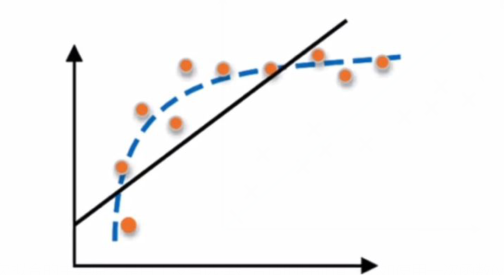
2)过拟合
过拟合(overfitting)与是机器学习模型训练过程中经常遇到的问题,所谓过拟合,通俗来讲就是模型的泛化能力较差,也就是过拟合的模型在训练样本中表现优越,但是在验证数据以及测试数据集中表现不佳。(我在股票预测模型中的表现特别好,每一天都全部都吻合,但是一旦预测股票,天天被割韭菜~)
举一个简单的例子,比如你训练一个识别狗狗照片的模型,如果你只用金毛犬的照片训练,那么该模型就只吸纳了金毛狗的相关特征,此时让训练好的模型识别一只“泰迪犬”,那么结果可想而知,该模型会认为“泰迪”不是一条狗。如下图所示:
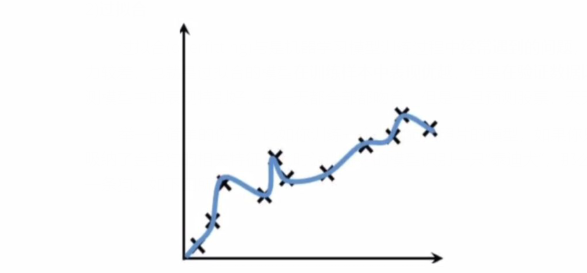
过拟合问题在机器学习中经常遇到,主要是因的训练时样本过少,特征值过多导致的,后续还会详细介绍。
3)欠拟合
欠拟合(underfitting)恰好与过拟合相反,它指的是“曲线”不能很好的“拟合"数据。在训练和测试阶段,欠拟合模型表现均较差,无法输出理想的预测结果。如下图所示:
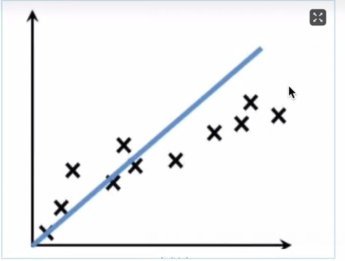
造成欠拟合的主要原因是由于没有选择好合适的特征值,比如使用一次函数(y=kx+b)去拟合具有对数特征值的散落点(y=log2x),示例图如下所示:
欠拟合和过拟合是机器学习中会遇到的问题,这两种情况都不是我期望看到的,因此要避免,关于如何处理类似问题,在后续内容中还会陆续讲解,本节只需要大家熟悉并理解常见的机器学习术语和一些概念即可。
本节需要知道的知识点:
1、机器学习常用术语?
2、假设函数&损失函数?
3、拟合&过拟合&欠拟合?
参考资料:《C语言中文网-机器学习算法》
10.基本人工智能工具的介绍与使用
1 python
这个不用我多说,自己去安装,教程可以参考我的博客:
2 numpy (矩阵计算)
NumPy(https://numpy.org/)属于 Python 的第三方扩展程序包,它是 Python 科学计算的基础库,提供了多维数组处理、线性代数、傅里叶变换、随机数生成等非常有用的数学工具。
NumPy 的安装方式非常简单,在安装好 Python 的基础上使用包管理器来安装,命令如下所示:
pip install numpy
使用案例:
a=np.array([[1,2],[3,4]])
b=np.array([[4,3],[2,1]])
# 矩阵乘法
c=np.matmul(a,b)
# 普通逐个相乘
result=np.multiply(a,b)
#1 2 4 3
#3 4 2 1
print(c)
print(result)
3 pandas(读取文件)
Pandas 属于 Python 第三方数据处理库,它基于 NumPy 构建而来,主要用于数据的处理与分析。我们知道对于机器学习而言数据是尤为重要,如果没有数据就无法训练模型。Pandas 提供了一个简单高效的 DataFrame 对象(类似于电子表格),它能够完成数据的清洗、预处理以及数据可视化工作等。除此之外,Pandas 能够非常轻松地实现对任何文件格式的读写操作,比如 CSV 文件、json 文件、excel 文件。
Pandas 安装非常简单,同样可以使用 pip 包管理器完成安装,如下所示:
pip install pandas
使用参考:
import pandas as pd
#前提是自己有data.csv 要不然报filenotfound错误
data = pd.read_csv('data.csv')
# 取x列
x = data.loc[:,'x']
print(x)
y = data.loc[:,'y']
print(y)
z = data.loc[:,'y'][x>20]
print(z)
np_array = np.array(x)
print(np_array)
x.to_csv('data_new.csv')
4 Matplotlib(数据可视化)
Matplotlib 是 Python 中最受欢迎的数据可视化软件包之一,支持跨平台运行,它是 Python 常用的 2D 绘图库,同时它也提供了一部分 3D 绘图接口。Matplotlib 通常与 NumPy、Pandas 一起使用,是数据分析中不可或缺的重要工具之一。
案例
import matplotlib
from matplotlib import pyplot as plt
%matplotlib inline
x = [1,2,3,4,5]
y = [5,4,3,2,1]
# 绘制连线图
plt.plot(x,y)
plt.title('y vs x')
plt.xlabel('x')
plt.ylabel('y')
plt.show( )
#绘制散点图
plt.scatter(x,y)
plt.show( )
5 Scikit-Learn(算法库)
最后介绍机器学习中的重要角色 Scikit-Leran(官网:https://scikit-learn.org/stable/),它是一个基于 Python 语言的机器学习算法库。Scikit-Learn 主要用 Python 语言开发,建立在 NumPy、Scipy 与 Matplotlib 之上,它提供了大量机器学习算法接口(API),因此你可以把它看做一本“百科全书”。由于 Scikit-Learn 的存在极大地提高了机器学习的效率,让开发者无须关注数学层面的公式、计算过程,有更多的更多的时间与精力专注于业务层面,从而解决实际的应用问题。
Scikit-Learn 的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。本教程将围绕机器算法的讲解 Scikit-Learn 实际的应用。 Scikit-Learn 安装也非常简单,执行以下命令即可安装:
pip install scikit-learn
11.线性回归
11.1回归分析
回归分析:根据数据,确定两种或两种以上变量间相互依赖的定量关系。
函数表达式为:
y=f(x1,x2,x3...xn)
如 y=ax+b, y=ax1+bx2+c
x代表的就是指的影响因素, 如 y=ax1+bx2+c可以指:多大面积 和 是不是学区房
11.2线性回归
线性回归:回归分析中,变量与因变量存在线性关系。
函数表达为: y=ax+b
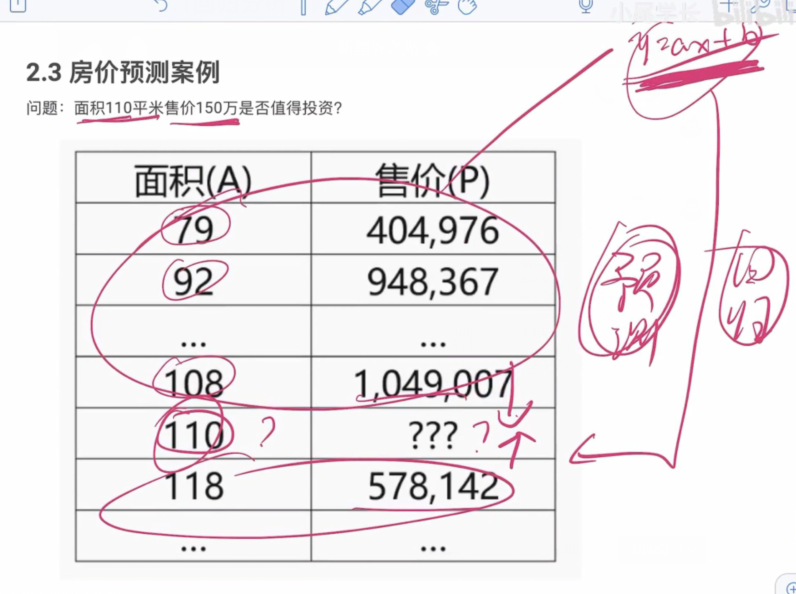
11.3房价预测案例
问题:面积110平米售价150万是否值得投资?
步骤:
1.设P为价格A为面积,确定P、A间的定量关系。即P=f(A)
2.根据关系预测合理价格。P=f(110)
3.做出判断
问题:如何求出函数P=f(A)
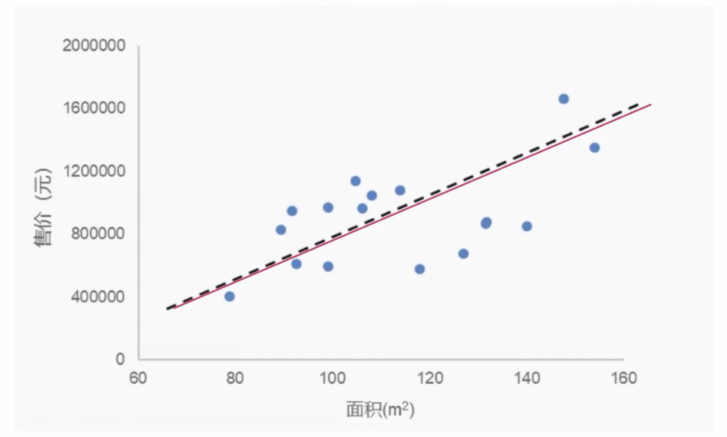
使用线性模型y=ax+b去拟合现有的数据。那么问题就在于如何去寻找a和b。
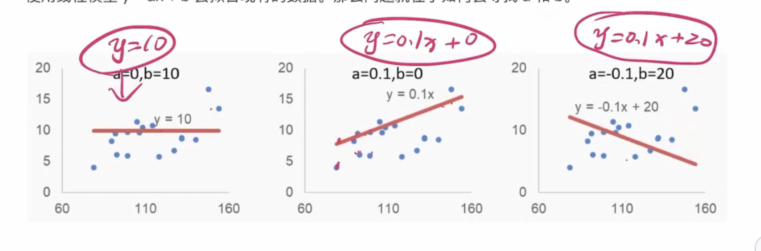
哪一个a和b比较合适呢?

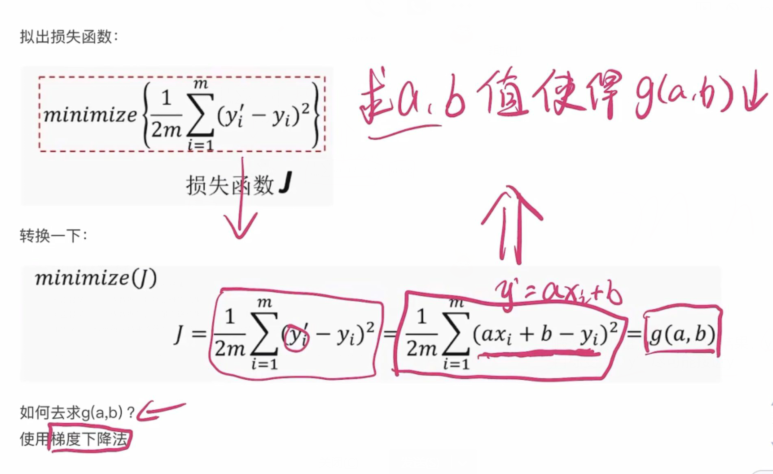
11.4梯度下降法
梯度下降法是寻找极小值的一种方法。通过向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索,直到在极小点收敛。

梯度下降法案例
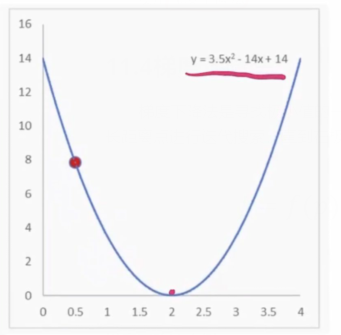

逐渐接近极小值点(p=2)
梯度下降法动态图:
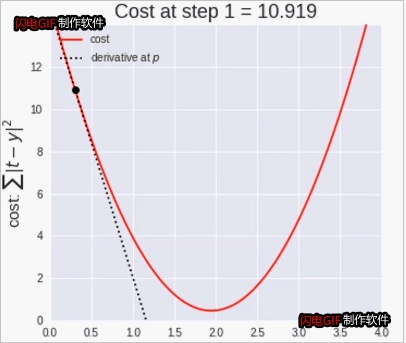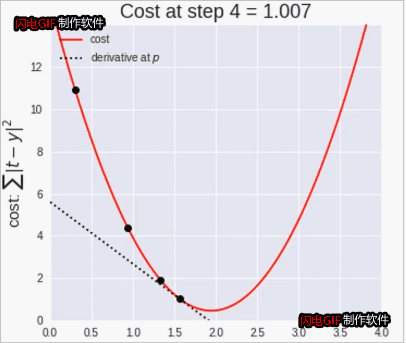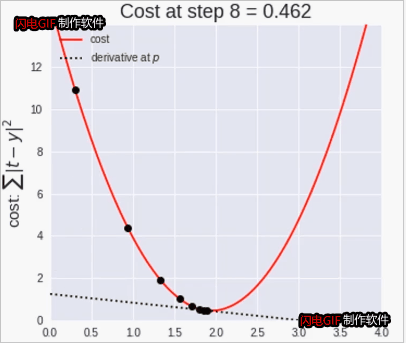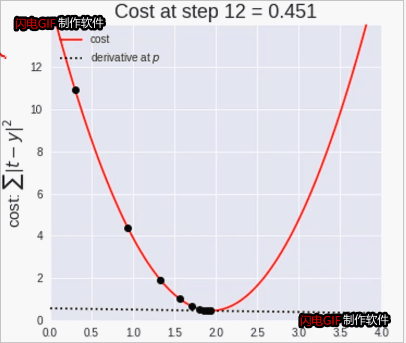
梯度下降法
重复计算直到收敛
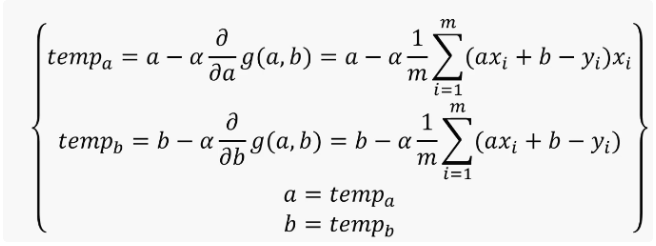

效果展示:
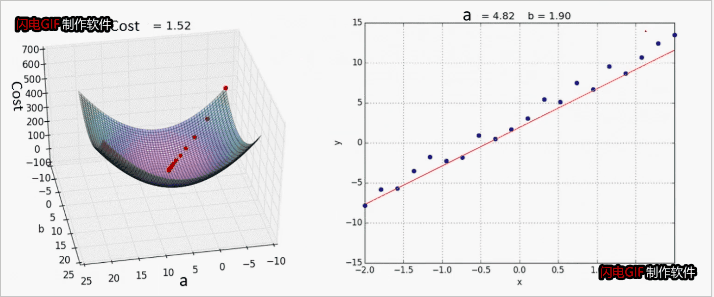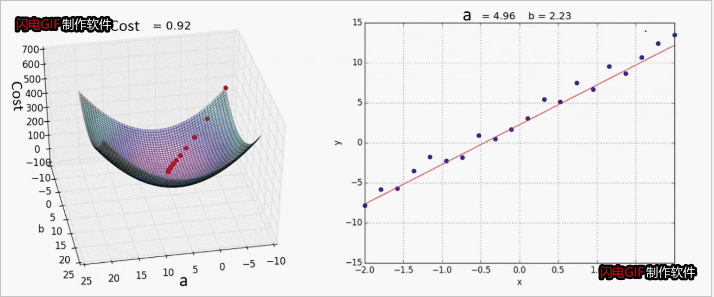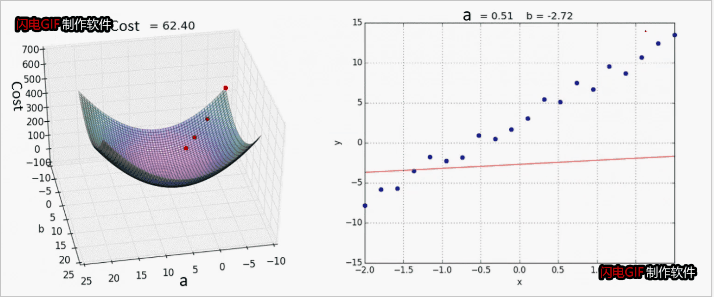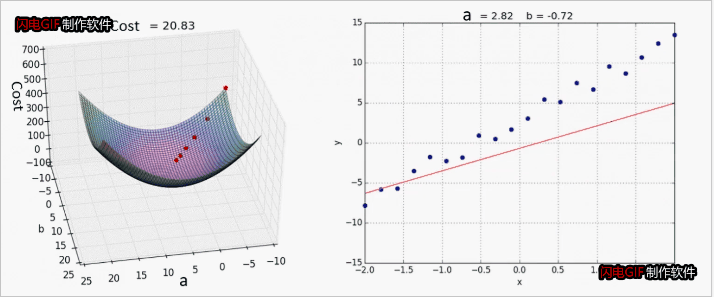
其他线性回归案例
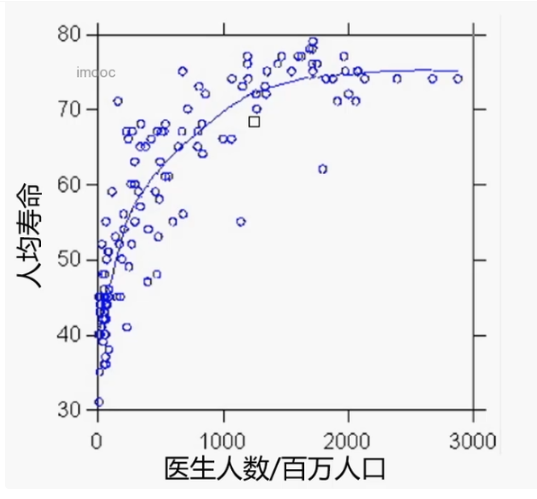
1.百万人口/医生预测平均寿命问题
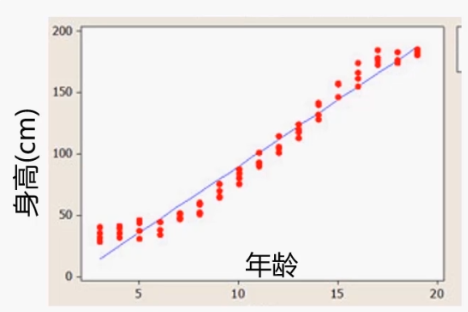
- 年龄预测身高
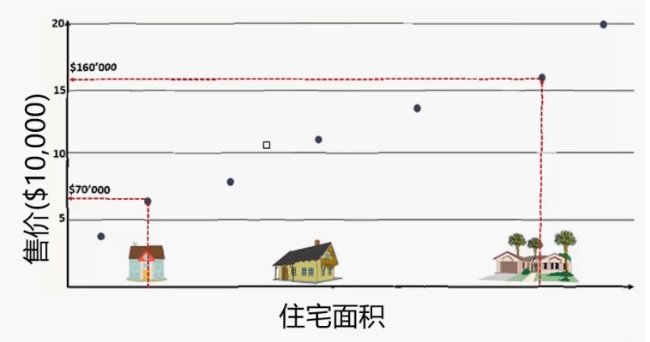
3.住宅面积预测房价
12.-实战:Sklearn求解线性回归问题
1 实战目标
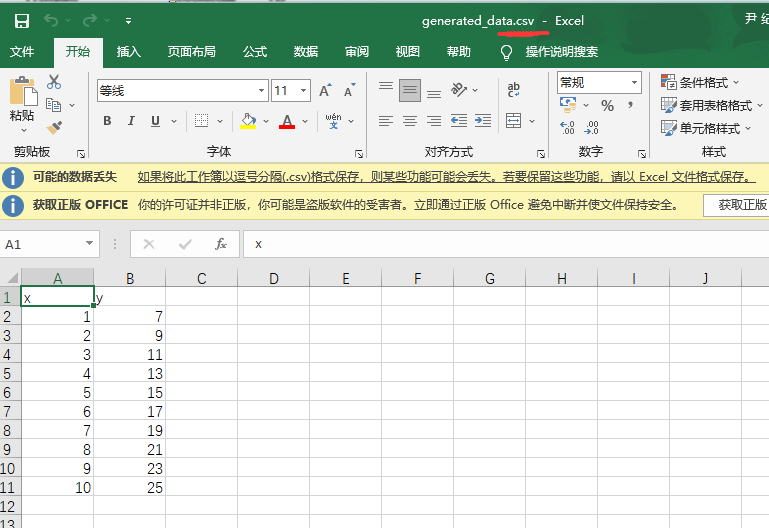
基于generated_data.csv数据,建立线性回归模型,预测x=3.5对应的y值,评估模型表现。
学会用Sklearn求解线性回归问题,寻找a、b (y = ax + b) 并且评估模型的好坏。
数据如下:
2 步骤
第一步:
#加载数据
import pandas as pd
data = pd.read_csv('generated_data.csv')
data.head()
x = data.loc[:,'x']
y = data.loc[:,'y']
print(x,y)
#visualize the data
from matplotlib import pyplot as plt
plt.figure(figsize=(20,20))
#scatter:代表散点图
plt.scatter(x,y)
plt.show()
#set up a linear regression model 设置一个线性回归模型
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
#np.array:进行类型转换 reshape:转换维度,要不然绘制不进去
import numpy as np
x = np.array(x)
x = x.reshape(-1,1)
y = np.array(y)
y = y.reshape(-1,1)
print(type(x),x.shape,type(y),y.shape)
print(type(x),x.shape)
#训练模型
lr_model.fit(x,y)
#预测
y_predict = lr_model.predict(x)
print(y_predict)
#预测3.5
y_3 = lr_model.predict([[3.5]])
print(y_3)
print(y)
#a\b 打印 y=ax+b
a = lr_model.coef_
b = lr_model.intercept_
print(a,b)
3 评估模型表现
y 与y’的均方误差(MSE):
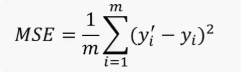
R方值(R2):
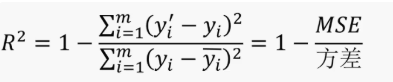
MSE越小越好,R^2分数越接近1越好
# 计算y 与y’的均方误差(MSE)、R方值(R2_score):
from sklearn.metrics import mean_squared_error,r2_score
MSE = mean_squared_error(y,y_predict)
R2 = r2_score(y,y_predict)
print(MSE,R2)
# 画图对比y 与y',可视化模型表现:
from matplotlib import pyplot as plt
plt.figure()
plt.plot(y,y_predict)
plt.show()
y' vs y集中度越高越好(越接近直线分布)
13.-实战: 房价预测模型训练
1.实战任务
基于 usa_housing _price.csv 数据,建立线性回归模型,预测合理房价:
-
1、作业1:以面积为输入变量,建立单因子模型, 评估模型表现,可视化线性回归预测结果
-
2、作业2:以income、house age、numbers of rooms、population、area为输入变量,建立多因子模型,评估模型表现
-
3、预测 Income=65000,,House Age=5, Number of Rooms=5, Population=30000, size=200的合理房价
2 步骤如下
作业1:
# 加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('usa_housing_price.csv')
data.head()
#数据散点图展示
%matplotlib inline
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(10,10))
# subplot(231) 代表两行三列的第一个图
fig1 =plt.subplot(231)
plt.scatter(data.loc[:,'Avg. Area Income'],data.loc[:,'Price'])
plt.title('Price VS Income')
fig2 =plt.subplot(232)
plt.scatter(data.loc[:,'Avg. Area House Age'],data.loc[:,'Price'])
plt.title('Price VS House Age')
fig3 =plt.subplot(233)
plt.scatter(data.loc[:,'Avg. Area Number of Rooms'],data.loc[:,'Price'])
plt.title('Price VS Number of Rooms')
fig4 =plt.subplot(234)
plt.scatter(data.loc[:,'Area Population'],data.loc[:,'Price'])
plt.title('Price VS Area Population')
fig5 =plt.subplot(235)
plt.scatter(data.loc[:,'size'],data.loc[:,'Price'])
plt.title('Price VS size')
plt.show()
#定义 x 和 y
X = data.loc[:,'size']
y = data.loc[:,'Price']
y.head()
# 转换维度
X = np.array(X).reshape(-1,1)
print(X.shape)
#线性回归模型
from sklearn.linear_model import LinearRegression
LR1 = LinearRegression()
#训练模型
LR1.fit(X,y)
#预测
y_predict_1 = LR1.predict(X)
print(y_predict_1)
#模型评估
from sklearn.metrics import mean_squared_error,r2_score
mean_squared_error_1 = mean_squared_error(y,y_predict_1)
r2_score_1 = r2_score(y,y_predict_1)
print(mean_squared_error_1,r2_score_1)
# 绘图
fig6 = plt.figure(figsize=(8,5))
plt.scatter(X,y)
plt.plot(X,y_predict_1,'r') # 'r':代表红色
plt.show()
作业2
#定义多因子x
#删除掉Price列
X_multi = data.drop(['Price'],axis=1)
X_multi
#第二个线性模型
LR_multi = LinearRegression()
#train the model
LR_multi.fit(X_multi,y)
#多因子预测
y_predict_multi = LR_multi.predict(X_multi)
print(y_predict_multi)
#模型评估
mean_squared_error_multi = mean_squared_error(y,y_predict_multi)
r2_score_multi = r2_score(y,y_predict_multi)
print(mean_squared_error_multi,r2_score_multi)
print(mean_squared_error_1)
#绘图
fig7 = plt.figure(figsize=(8,5))
plt.scatter(y,y_predict_multi)
plt.show()
fig8 = plt.figure(figsize=(8,5))
plt.scatter(y,y_predict_1)
plt.show()
X_test = [65000,5,5,30000,200]
X_test = np.array(X_test).reshape(1,-1)
print(X_test)
y_test_predict = LR_multi.predict(X_test)
print(y_test_predict)
实战结果
线性回归房价实战summary:
1、通过搭建线性回归模型,实现单因子的房屋价格预测;
2、在单因子模型效果不好的情况下,通过考虑更多的因子,建立了多因子模型;
3、多因子模型达到了更好的预测效果,r2分数为0.91;
4、实现了预测结果的可视化,直观对比预测价格与实际价格的差异。
14.逻辑回归
我们知道有监督学习分为“回归问题”和“分类问题”,前而我们已经认识了什么是“回归问题”,从本节开始我们将讲解“分类问题”的相关算法。在介绍具体的算法前,我们先聊聊到底什么是分类问题。
1.什么是分类问题?
其实想要理解“分类”问题非常的简单,我们不妨拿最简单的“垃级分类处理”的过程来认识一下这个词。现在考虑以下场景:
小明拎着两个垃圾袋出门倒垃级,等走到垃级回收站的时候。小明发现摆放着两个垃级桶。上面分别贴着“可回收”与“不可回收”。小明经过自己的判断后,把自己右手的垃极故进了贴有“不可回收”的垃极桶内,而左手的垃圾袋放进了“可回收”的垃圾桶内,最终完成了这次倒垃吸的过程。
其实上述“倒垃级”的案例就说明了“分类问题”的过程。“可回收”与“不可回收”是两种预测分类,而小明是主观判断的个体,他通过自己日常接触的知识对“垃圾种类”做出判断,我们把这个程称作“模型训练”,只有通过“训练”才可以更加准确地判断“垃吸”的种类。小明进行了两次投放动作,每一次投故都要对“垃圾”种类做出预先判断,最终决定投放到哪个垃吸桶内。这就是根据模型训练的结果进行预测的整个过程。
除了垃圾分类之外,我们常见的还有垃圾邮件分类,一般来说我们如何去判断邮件是否是垃圾邮件?一般来说只要发件人中含一些乱七八遭的符号例如「sda#&*sd@123.com」、「dsah%qwe@889.com」并且邮件中包含「赌博」「博彩」「同城yp」「百家乐」这些彩票会被我们认为是垃圾邮件。
下面对上述分类过程做简单总结:
-
类别标签:“可回收”与“不可回收”,“是”或“不是”。(含参考答案的训练集)·
-
模型训练:以小明为主体,把他所接受的知识、经验做为模型训练的参照。(获取特征)·
-
预测:投放垃圾的结果,预测分类是否正确,并输出预测结果。
分类问题是当前机器学习的研究热点,它被广泛应用到各个领域,比图像识别、垃圾邮件处理、预测天气、疾病诊断、文字识别等等。“分类问题”的预测结果是离散的,它比线性回归要更加复杂,那么我们应该从何处着手处理“分类问题”呢,这就需要使用到我们的分类算法。
1.分类算法
1.1逻辑回归算法
1.2.KNN近邻算法
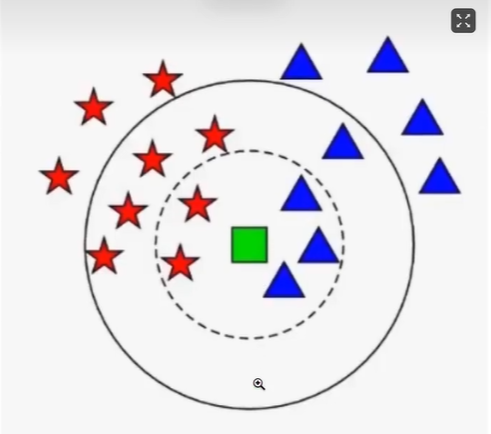
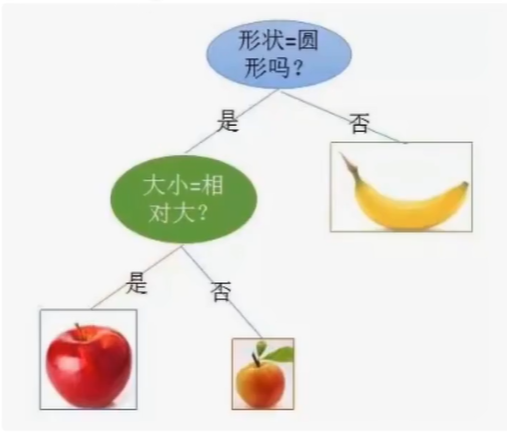
1.3.决策树
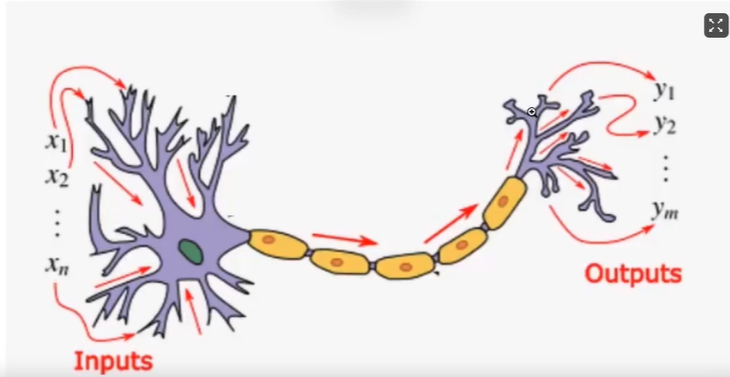
1.4神经网络
2 Logistic回归算法
也许乍一看算法名字,你会认为它是用来解决“回归问题”的算法,但其实它是针对“分类问题”的算法。
2.1逻辑回归介绍
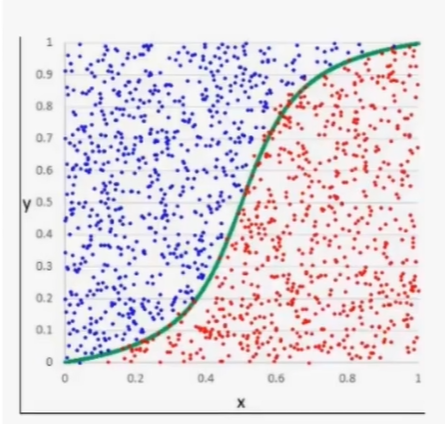
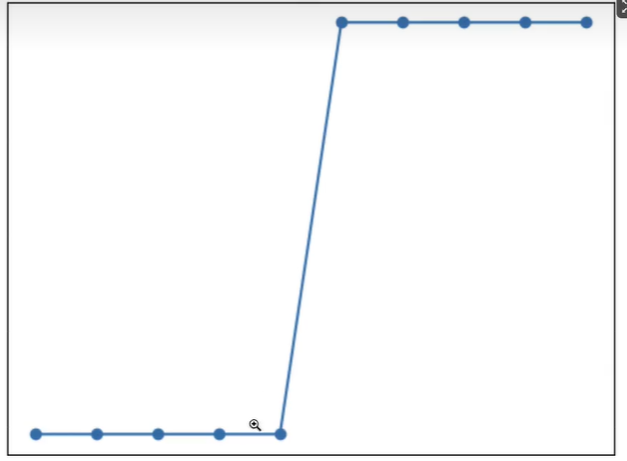
Logistic回归算法,又叫做逻辑回归算法,或者LR算法(Logistic Regression)。分类问题同样也可以基于“线性模型”构建。“线性模型”最大的特点就是“直来直去”不会打弯,而我们知道,分类问题的预测结果是“离散的”,即对输出数据的类别做判断。比如将类别预设条件分为“0”类和“1”类(或者“是”或者“否”)那么图像只会在“0”和“1”之间上下起伏,如下图所示:
此时你就可能会有很多疑问,线性回归函数不可能“拟合”上述图像。没错,所以接下来我们要学习另一个线性函数Logistic函数。
注意:在机器学习中,L0gsc函数通常用来解决二元分类问题,也就是涉及两个预设类别的问题,而当类别数量超过两个时就需要使用Softmax函数来解决。
19世纪统计学家皮埃尔·弗朗素瓦~韦吕勒发明了pgsc函数,该通数的叫法有很多,比如在神经网络算法中被称为Sigmoid函数,也有人称它为Logistic曲线。其函数图像如下所示:
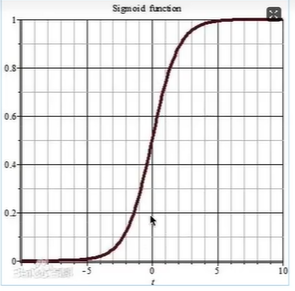

e称为自然常数,也就是一个因定值的“常量”,e-z是以e为庭、z为变量的指数函数,还可以写为e-x,在编写程序代码时,通常将其写为exp(-x)
Logistic函数也称为S型生长曲线,取值范国为(0,1),它可以将一个实数映射到(0,1)的区间,非常适合做二元分类。当Z=0时,该函数的取值为0.5,随着z的增大,对应的函数值将逼近于1;而随着z的减小,其函数值将逼近于0。
对于L0gstc函数而言,坐标轴0是一个有着特殊意义坐标,越靠近0和越远离0会出现两种醒然不同的情况:任何大于0.5的数据都会被划分到“1”种;而小于0.5会被归如到“0”类。因此你可以把L0gstc看做解决二分类问题的分类器。如果想要L0gsc分类器预测准确,那么×的取值距离0越远越好,这样结果值才能无限逼近于0或者1,该函数能够很好的拟合”二分类问题函数图像。
2.2损失函数
逻辑回归的最小损失函数如下:

整理一下:

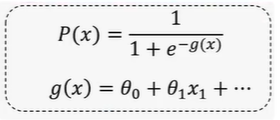
如何求的最小值?min(J)
还是使用梯度下降法

参考文档:
15.研究生复试项目 直播答疑
1.简历怎么书写?
百度 超级简历: https://www.wondercv.com/
百度飞浆 、百度人工智能
在简历上写了解比特币 区块链的知识
项目时间可以写 : 2021年09月--2021年12月 2022年01月--2022年02月
通过做线性回归汽车预测模型,让我对人工智能更加感兴趣,所以坚定了我要考研的信心,
要是问一些回答不上来的问题:就说 后来就开始准备复试了,暂时还没有了解其他的,想通过读研期间继续深入学习。
该大学是我一直憧憬的大学,希望老师们可以给我一个来该校继续学习的机会, 谢谢老师。
16.研究生复试面试专题
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |