

flume整合数据到kafka,sparkStreaming消费数据,并存储到hbase和redis中
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
2、第二步从kafka中获取数据信息写了一个自定义方法getStreamingContextFromHBase
3、第三步、消费数据解析数据并将数据存入hbase不同的表中和redis中
4、第四步提交消费的kafka的偏移量到 hbase的表中进行管理
使用flume采集我们的日志数据然后将数据放入到kafka当中去通过sparkStreaming消费我们的kafka当中的数据然后将数据保存到hbase并且将海口数据保存到redis当中去实现实时轨迹监控以及历史轨迹回放的功能

为了模拟数据的实时生成我们可以通过数据回放程序来实现订单数据的回放功能
1、模拟数据生成
1、海口订单数据上传
将海口数据上传到node01服务器的/kkb/datas/sourcefile这个路径下node01执行以下命令创建文件夹然后上传数据
mkdir -p /kkb/datas/sourcefile
2、成都轨迹日志数据
将成都数据上传到node02服务器的/kkb/datas/sourcefile这个路径下node02执行以下命令创建文件夹然后上传数据
mkdir -p /kkb/datas/sourcefile
3、因为没有实际应用所以写一个脚本对数据不断复制追加
在node01服务器的/home/hadoop/bin路径下创建shell脚本用于数据的回放
cd /home/hadoop/bin
vim start_stop_generate_data.sh
#!/bin/bash
scp /home/hadoop/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar node02:/home/hadoop/
#休眠时间控制
sleepTime=1000
if [ ! -n "$2" ];then
echo ""
else
sleepTime=$2
fi
case $1 in
"start" ){
for i in node01 node02
do
echo "-----------$i启动数据回放--------------"
ssh $i "source /etc/profile;nohup java -jar /home/hadoop/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar /kkb/datas/sourcefile /kkb/datas/destfile $2 > /dev/null 2>&1 & "
done
};;
"stop"){
for i in node02 node01
do
echo "-----------停止 $i 数据回放-------------"
ssh $i "source /etc/profile; ps -ef | grep FileOperate-1.0-SNAPSHOT-jar | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
脚本赋权
cd /home/hadoop/bin
chmod 777 start_stop_generate_data.sh
启动脚本
sh start_stop_generate_data.sh start 3000
停止脚本
sh start_stop_generate_data.sh stop
2、flume采集数据
逻辑机构如下
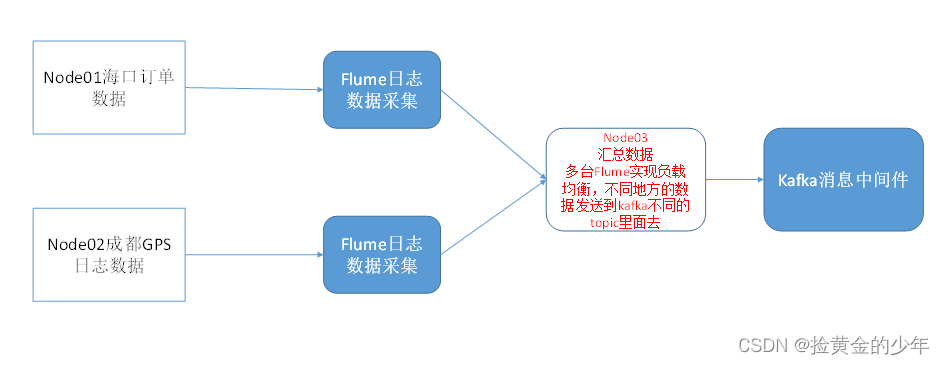
1、node01配置flume的conf文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/haikou.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = hai_kou_gps_topic
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
#a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#flume监听的文件数据发送到此kafka的主题当中
#a1.sinks.k1.topic = hai_kou_gps_topic
#a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
#a1.sinks.k1.batchSize = 20
#a1.sinks.k1.requiredAcks = 1
#a1.sinks.k1.producer.linger.ms = 1
#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
sources文件数据来源
channels 文件数据通道
sinks 文件数据输出
其中关键的就是在sources配置过滤器方便node03数据集中处理的时候将不同的数据分配给不同的kafka的topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = hai_kou_gps_topic
2、node02开发flume的配置文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume_client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/datas/flume_temp/flume_posit/chengdu.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/datas/destfile/part.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = cheng_du_gps_topic
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
#a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#flume监听的文件数据发送到此kafka的主题当中
#a1.sinks.k1.topic = cheng_du_gps_topic
#a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
#a1.sinks.k1.batchSize = 20
#a1.sinks.k1.requiredAcks = 1
#a1.sinks.k1.producer.linger.ms = 1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
关键配置信息
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = cheng_du_gps_topic
3、node03开发flume的配置文件
cd /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/
vim flume2kafka.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/datas/flume_temp/flume_check
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/datas/flume_temp/flume_cache
#定义sink
#flume监听轨迹文件内容的变化 tuch gps
#配置sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
flume监听的文件数据发送到此kafka的主题当中
a1.sinks.k1.topic = %{type}
a1.sinks.k1.brokerList= node01:9092,node02:9092,node03:9092
a1.sinks.k1.batchSize = 20
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.producer.linger.ms = 1
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
将 传入信息的key为type的value值作为sink数据输出端kafka的topic
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
flume监听的文件数据发送到此kafka的主题当中
a1.sinks.k1.topic = %{type}
4、开发flume启动停止脚本
cd /home/hadoop/bin/
vim flume_start_stop.sh
#!/bin/bash
case $1 in
"start" ){
for i in node03 node02 node01
do
echo "-----------启动 $i 采集flume-------------"
if [ "node03" = $i ];then
ssh $i "source /etc/profile;nohup /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/bin/flume-ng agent -n a1 -c /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf -f /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume2kafka.conf -Dflume.root.logger=info,console > /dev/null 2>&1 & "
else
ssh $i "source /etc/profile;nohup /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/bin/flume-ng agent -n a1 -c /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf -f /kkb/install/apache-flume-1.6.0-cdh5.14.2-bin/conf/flume_client.conf -Dflume.root.logger=info,console > /dev/null 2>&1 & "
fi
done
};;
"stop"){
for i in node03 node02 node01
do
echo "-----------停止 $i 采集flume-------------"
ssh $i "source /etc/profile; ps -ef | grep flume | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
chmod 777 flume_start_stop.sh
开启flume脚本
sh flume_start_stop.sh start
停止flume脚本
sh flume_start_stop.sh stop
5、node01执行以下命令创建kafka的topic
cd /kkb/install/kafka/
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 9 --topic cheng_du_gps_topic

bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 9 --topic hai_kou_gps_topic

6、启动并查看kafka的数据
node01执行以下命令启动订单回放脚本
cd /home/hadoop/bin/
sh start_stop_generate_data.sh start 3000
node01启动flume采集数据脚本
cd /home/hadoop/bin/
sh flume_start_stop.sh start
消费数据
cd /kkb/install/kafka/
bin/kafka-console-consumer.sh --topic cheng_du_gps_topic --zookeeper node01:2181,node02:2181,node03:2181
成都kafka消费数据

bin/kafka-console-consumer.sh --topic hai_kou_gps_topic --zookeeper node01:2181,node02:2181,node03:2181
海口kafka消费数据
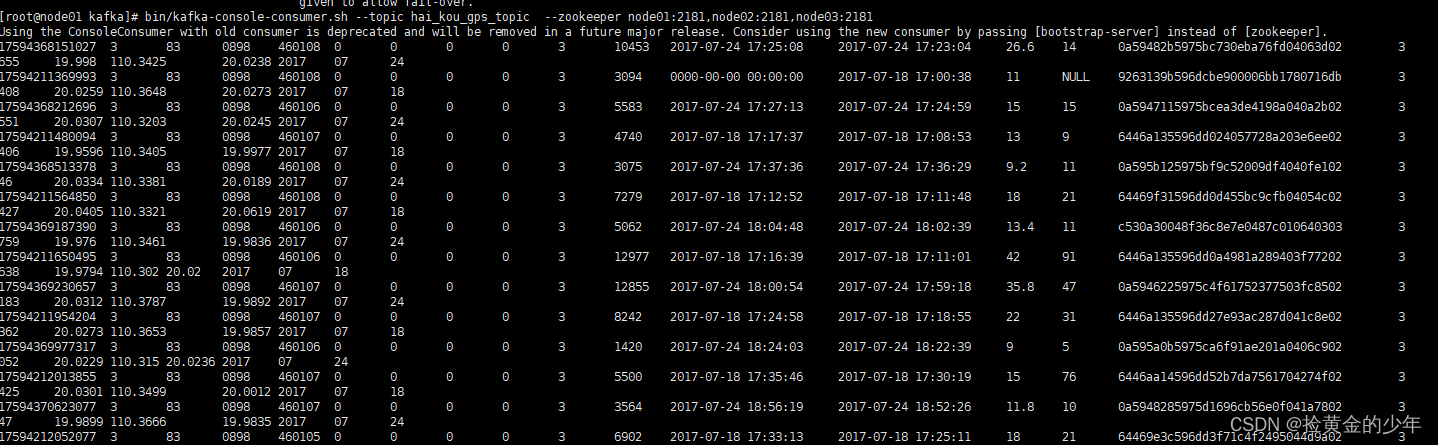
3、SparkStreaming消费kafka中的数据
主要程序如下
package com.travel.programApp
import java.util.regex.Pattern
import com.travel.common.{ConfigUtil, Constants, HBaseUtil, JedisUtil}
import com.travel.utils.HbaseTools
import org.apache.hadoop.hbase.{Cell, CellUtil, HColumnDescriptor, HTableDescriptor, TableName}
import org.apache.hadoop.hbase.client.{Admin, Connection, Get, Result, Table}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, ConsumerStrategies, ConsumerStrategy, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import redis.clients.jedis.Jedis
import scala.collection.mutable
object StreamingKafka {
def main(args: Array[String]): Unit = {
val brokers = ConfigUtil.getConfig(Constants.KAFKA_BOOTSTRAP_SERVERS)
//KAFKA_BOOTSTRAP_SERVERS=node01:9092,node02:9092,node03:9092
val topics = Array(ConfigUtil.getConfig(Constants.CHENG_DU_GPS_TOPIC), ConfigUtil.getConfig(Constants.HAI_KOU_GPS_TOPIC))
val conf = new SparkConf().setMaster("local[1]").setAppName("sparkKafka")
val group: String = "gps_consum_group"
// "bootstrap.servers" -> brokers,
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> group,
"auto.offset.reset" -> "latest", // earliest,latest,和none
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val context: SparkContext = sparkSession.sparkContext
context.setLogLevel("WARN")
// val streamingContext = new StreamingContext(conf,Seconds(5))
//获取streamingContext
val streamingContext: StreamingContext = new StreamingContext(context, Seconds(1))
//sparkStreaming消费kafka的数据然后将offset维护保存到hbase里面去
//第一步从kafak当中获取数据
val result: InputDStream[ConsumerRecord[String, String]] = HbaseTools.getStreamingContextFromHBase(streamingContext, kafkaParams, topics, group, "(.*)gps_topic")
//第二步将数据保存到hbase以及redis里面去
result.foreachRDD(eachRdd => {
if (!eachRdd.isEmpty()) {
eachRdd.foreachPartition(eachPartition => {
val connection: Connection = HBaseUtil.getConnection
val jedis: Jedis = JedisUtil.getJedis
//判断表是否存在如果不存在就进行创建
val admin: Admin = connection.getAdmin
if (!admin.tableExists(TableName.valueOf(Constants.HTAB_GPS))) {
/**
* 一般Hbase创建表代码结构如下
* TableName myuser = TableName.valueOf("myuser");
* HTableDescriptor hTableDescriptor = new HTableDescriptor(myuser);
* //指定一个列族
* HColumnDescriptor f1 = new HColumnDescriptor("f1");
* hTableDescriptor.addFamily(f1);
* admin.createTable(hTableDescriptor);
*/
val htabgps = new HTableDescriptor(TableName.valueOf(Constants.HTAB_GPS))
htabgps.addFamily(new HColumnDescriptor(Constants.DEFAULT_FAMILY))
admin.createTable(htabgps)
}
//判断海口的GPS表是否存在如果不存在则创建表
if (!admin.tableExists(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER))) {
val htabgps = new HTableDescriptor(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER))
htabgps.addFamily(new HColumnDescriptor(Constants.DEFAULT_FAMILY))
admin.createTable(htabgps)
}
//通过循环遍历分区的数据将每个分区当中的每一条数据都获取出来
eachPartition.foreach(record => {
val consumerRecord: ConsumerRecord[String, String] = HbaseTools.saveToHBaseAndRedis(connection, jedis, record)
})
JedisUtil.returnJedis(jedis)
connection.close()
})
//获取到消费完成的offset的偏移量
val offsetRanges: Array[OffsetRange] = eachRdd.asInstanceOf[HasOffsetRanges].offsetRanges
//将offset保存到hbase里面去默认可以手动提交保存到kafak的一个topic里面去
//将offset保存到kafak里面去
// result.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
for (eachrange <- offsetRanges) {
val startOffset: Long = eachrange.fromOffset
val endOffset: Long = eachrange.untilOffset
val topic: String = eachrange.topic
val partition: Int = eachrange.partition
//将offset保存到hbase里面去
HbaseTools.saveBatchOffset(group, topic, partition + "", endOffset)
}
}
})
streamingContext.start()
streamingContext.awaitTermination()
}
}
1、第一步sparkStreaming的连接
标准的基础连接kafkaParams 为kafka的消费基础信息
val brokers = ConfigUtil.getConfig(Constants.KAFKA_BOOTSTRAP_SERVERS)
//KAFKA_BOOTSTRAP_SERVERS=node01:9092,node02:9092,node03:9092
val topics = Array(ConfigUtil.getConfig(Constants.CHENG_DU_GPS_TOPIC), ConfigUtil.getConfig(Constants.HAI_KOU_GPS_TOPIC))
val conf = new SparkConf().setMaster("local[1]").setAppName("sparkKafka")
val group: String = "gps_consum_group"
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> group,
"auto.offset.reset" -> "latest", // earliest,latest,和none
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val context: SparkContext = sparkSession.sparkContext
context.setLogLevel("WARN")
// val streamingContext = new StreamingContext(conf,Seconds(5))
//获取streamingContext
val streamingContext: StreamingContext = new StreamingContext(context, Seconds(1))
2、第二步从kafka中获取数据信息写了一个自定义方法getStreamingContextFromHBase
val result: InputDStream[ConsumerRecord[String, String]] = HbaseTools.getStreamingContextFromHBase(streamingContext, kafkaParams, topics, group, "(.*)gps_topic")
1、获取hbase中存储的偏移量信息
2、对应的偏移量获取对应的value数据信息
def getStreamingContextFromHBase(streamingContext: StreamingContext, kafkaParams: Map[String, Object], topics: Array[String], group: String, matchPattern: String): InputDStream[ConsumerRecord[String, String]] = {
val connection: Connection = getHbaseConn
val admin: Admin = connection.getAdmin
//拿取到HBASE的存偏移量的表hbase_offset_store的偏移量数据TopicPartition, Long组成的hashMap集合Long表示偏移量位置
//TopicPartition里面封装的有参构造器封装的 topic 主题和partition分区
var getOffset: collection.Map[TopicPartition, Long] = HbaseTools.getOffsetFromHBase(connection, admin, topics, group)
//如果偏移量数组大于0则证明是以前被消费过的所以多传一个参数传入偏移量的值
val result = if (getOffset.size > 0) {
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.SubscribePattern[String, String](Pattern.compile(matchPattern), kafkaParams, getOffset)
val value: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext, LocationStrategies.PreferConsistent, consumerStrategy)
//streamingContext streaming上下文对象
//LocationStrategies.PreferConsistent数据本地性策略
//consumerStrategy消费策略
value
//返回streaming获取到kafka的真实value值
} else {
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.SubscribePattern[String, String](Pattern.compile(matchPattern), kafkaParams)
val value: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext, LocationStrategies.PreferConsistent, consumerStrategy)
value
}
admin.close()
connection.close()
result
}
getHbaseConn方法hbase连接的方法
def getHbaseConn: Connection = {
try {
// GlobalConfigUtils.getProp("hbase.master")自定义的配置信息
val config: Configuration = HBaseConfiguration.create()
config.set("hbase.zookeeper.quorum", GlobalConfigUtils.getProp("hbase.zookeeper.quorum"))
// config.set("hbase.master" , GlobalConfigUtils.getProp("hbase.master"))
config.set("hbase.zookeeper.property.clientPort", GlobalConfigUtils.getProp("hbase.zookeeper.property.clientPort"))
// config.set("hbase.rpc.timeout" , GlobalConfigUtils.rpcTimeout)
// config.set("hbase.client.operator.timeout" , GlobalConfigUtils.operatorTimeout)
// config.set("hbase.client.scanner.timeout.period" , GlobalConfigUtils.scannTimeout)
// config.set("hbase.client.ipc.pool.size","200");
val connection = ConnectionFactory.createConnection(config)
connection
} catch {
case exception: Exception =>
error(exception.getMessage)
error("HBase获取连接失败")
null
}
}
3、第三步、消费数据解析数据并将数据存入hbase不同的表中和redis中
//将数据保存到hbase以及redis里面去 result.foreachRDD(eachRdd => { if (!eachRdd.isEmpty()) { eachRdd.foreachPartition(eachPartition => { val connection: Connection = HBaseUtil.getConnection val jedis: Jedis = JedisUtil.getJedis //判断表是否存在如果不存在就进行创建 val admin: Admin = connection.getAdmin if (!admin.tableExists(TableName.valueOf(Constants.HTAB_GPS))) { /** * 一般Hbase创建表代码结构如下 * TableName myuser = TableName.valueOf("myuser"); * HTableDescriptor hTableDescriptor = new HTableDescriptor(myuser); * //指定一个列族 * HColumnDescriptor f1 = new HColumnDescriptor("f1"); * hTableDescriptor.addFamily(f1); * admin.createTable(hTableDescriptor); */ val htabgps = new HTableDescriptor(TableName.valueOf(Constants.HTAB_GPS)) htabgps.addFamily(new HColumnDescriptor(Constants.DEFAULT_FAMILY)) admin.createTable(htabgps) } //判断海口的GPS表是否存在如果不存在则创建表 if (!admin.tableExists(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER))) { val htabgps = new HTableDescriptor(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER)) htabgps.addFamily(new HColumnDescriptor(Constants.DEFAULT_FAMILY)) admin.createTable(htabgps) } //通过循环遍历分区的数据将每个分区当中的每一条数据都获取出来 eachPartition.foreach(record => { val consumerRecord: ConsumerRecord[String, String] = HbaseTools.saveToHBaseAndRedis(connection, jedis, record) }) JedisUtil.returnJedis(jedis) connection.close() })
存入redis或者hbase的方法
通过逗号隔开判断数据长度进而判断数据是成都GPS日志数据还是海口订单数据
// 成都的数据如下 // 18901e5f392c5ad98d24c296dcb0afe4,0003a1ceaf2979d0bdeff58da7665a41,1475976805,104.05368,30.70332 // 海口的数据如下 // dwv_order_make_haikou_1.order_id dwv_order_make_haikou_1.product_id dwv_order_make_haikou_1.city_id dwv_order_make_haikou_1.district dwv_order_make_haikou_1.county dwv_order_make_haikou_1.type dwv_order_make_haikou_1.combo_type dwv_order_make_haikou_1.traffic_type dwv_order_make_haikou_1.passenger_count dwv_order_make_haikou_1.driver_product_id dwv_order_make_haikou_1.start_dest_distance dwv_order_make_haikou_1.arrive_time dwv_order_make_haikou_1.departure_time dwv_order_make_haikou_1.pre_total_fee dwv_order_make_haikou_1.normal_time dwv_order_make_haikou_1.bubble_trace_id dwv_order_make_haikou_1.product_1level dwv_order_make_haikou_1.dest_lng dwv_order_make_haikou_1.dest_lat dwv_order_make_haikou_1.starting_lng dwv_order_make_haikou_1.starting_lat dwv_order_make_haikou_1.year dwv_order_make_haikou_1.month dwv_order_make_haikou_1.day // 17592719043682 3 83 0898 460107 0 0 0 4 3 4361 2017-05-19 01:09:12 2017-05-19 01:05:19 13 11 10466d3f609cb938dd153738103b0303 3 110.3645 20.0353 110.3665 20.0059 2017 05 19 // 下面是成都的数据成都的数据才有逗号才能分组
def saveToHBaseAndRedis(connection: Connection, jedis: Jedis, eachLine: ConsumerRecord[String, String]): ConsumerRecord[String, String] = { var rowkey = "" //司机ID var driverId = "" //订单ID var orderId = "" //经度 var lng = "" //维度 var lat = "" //时间戳 var timestamp = "" val topic: String = eachLine.topic() val line: String = eachLine.value() //成都数据 if (line.split(",").size > 4) { if (!line.contains("end")) { //非结束数据保存到hbase里面去 //成都数据 val strings: Array[String] = line.split(",") val split: Array[String] = line.split(",") driverId = split(0) orderId = split(1) timestamp = split(2) lng = split(3) lat = split(4) rowkey = orderId + "_" + timestamp val put = new Put(rowkey.getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "CITYCODE".getBytes(), Constants.CITY_CODE_CHENG_DU.getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DRIVERID".getBytes(), driverId.getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "ORDERID".getBytes(), orderId.getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "TIMESTAMP".getBytes(), (timestamp + "").getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "TIME".getBytes(), DateUtils.formateDate(new Date((timestamp + "000").toLong), "yyyy-MM-dd HH:mm:ss").getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "LNG".getBytes(), lng.getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "LAT".getBytes(), lat.getBytes()) val table: Table = connection.getTable(TableName.valueOf(Constants.HTAB_GPS)) table.put(put) table.close() } //数据保存到redis里面去 if (line.split(",").size == 5 || line.contains("end")) { JedisUtil.saveChengDuJedis(line) } //无论如何成都数据都需要往下传递 } else { //海口数据 /** * 17595848583981 3 83 0898 460108 1 0 5 0 0 1642 0000-00-00 00:00:00 2017-09-20 03:20:00 14 NULL 2932979a59c14a3200007183013897db 3 110.4613 19.9425 110.462 19.9398 2017 09 20 */ var rowkey: String = "" val fields: Array[String] = line.split("\t") //println(fields.length) if (fields.length == 24 && !line.contains("dwv_order_make_haikou")) { //订单ID+出发时间作为hbase表的rowkey rowkey = fields(0) + "_" + fields(13).replaceAll("-", "") + fields(14).replaceAll(":", "") val put = new Put(rowkey.getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "ORDER_ID".getBytes(), fields(0).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "PRODUCT_ID".getBytes(), fields(1).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "CITY_ID".getBytes(), fields(2).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DISTRICT".getBytes(), fields(3).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "COUNTY".getBytes(), fields(4).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "TYPE".getBytes(), fields(5).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "COMBO_TYPE".getBytes(), fields(6).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "TRAFFIC_TYPE".getBytes(), fields(7).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "PASSENGER_COUNT".getBytes(), fields(8).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DRIVER_PRODUCT_ID".getBytes(), fields(9).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "START_DEST_DISTANCE".getBytes(), fields(10).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "ARRIVE_TIME".getBytes(), fields(11).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DEPARTURE_TIME".getBytes(), fields(12).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "PRE_TOTAL_FEE".getBytes(), fields(13).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "NORMAL_TIME".getBytes(), fields(14).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "BUBBLE_TRACE_ID".getBytes(), fields(15).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "PRODUCT_1LEVEL".getBytes(), fields(16).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DEST_LNG".getBytes(), fields(17).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DEST_LAT".getBytes(), fields(18).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "STARTING_LNG".getBytes(), fields(19).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "STARTING_LAT".getBytes(), fields(20).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "YEAR".getBytes(), fields(21).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "MONTH".getBytes(), fields(22).getBytes()) put.addColumn(Constants.DEFAULT_FAMILY.getBytes(), "DAY".getBytes(), fields(23).getBytes()) val table: Table = connection.getTable(TableName.valueOf(Constants.HTAB_HAIKOU_ORDER)) table.put(put) table.close() } } eachLine }
将GPS数据存入redis中
public static void saveChengDuJedis(String line) throws ParseException {
Jedis jedis = getJedis();
String[] split = line.split(",");
String orderId = split[1];
if (line.startsWith("end") && line.contains(",")) {
// System.out.println("我终于接受到了一条结束标识了结束订单id为" + orderId);
jedis.lpush(Constants.CITY_CODE_CHENG_DU + "_" + orderId, "end");
//发现了结束标识将订单从实时订单列表里面移除掉
jedis.srem(Constants.REALTIME_ORDERS,Constants.CITY_CODE_CHENG_DU + "_" + orderId);
} else {
String driverId = split[0];
String timestamp = split[2];
String lng = split[3];
String lat = split[4];
//1.存入实时订单单号 使用redis的Set集合自动对相同的订单id进行去重
jedis.sadd(Constants.REALTIME_ORDERS, Constants.CITY_CODE_CHENG_DU + "_" + orderId);
//2.存入实时订单的经纬度信息使用set集合自动对经纬度信息进行去重操作
jedis.lpush(Constants.CITY_CODE_CHENG_DU + "_" + orderId, lng + "," + lat);
//3.存入订单的开始结束时间信息
Order order = new Order();
String hget = jedis.hget(Constants.ORDER_START_ENT_TIME, orderId);
if(StringUtils.isNotEmpty(hget)){
//已经有了数据了
//将获取的数据与已经存在的数据比较如果时间大于起始时间更新结束时间和结束经纬度
Order parseOrder = JSONObject.parseObject(hget, Order.class);
// System.out.println(parseOrder.toString());
//当前数据时间比redis当中的结束时间更大需要更新结束时间和结束经纬度
if(Long.parseLong(timestamp) * 1000 > parseOrder.getEndTime()){
parseOrder.setEndTime(Long.parseLong(timestamp) * 1000);
parseOrder.setGetOfLat(lat);
parseOrder.setGetOfLng(lng);
jedis.hset(Constants.ORDER_START_ENT_TIME, orderId, JSONObject.toJSONString(parseOrder));
}else if(Long.parseLong(timestamp) * 1000 < parseOrder.getStartTime()){
parseOrder.setStartTime(Long.parseLong(timestamp) * 1000);
parseOrder.setGetOnLat(lat);
parseOrder.setGetOnLng(lng);
jedis.hset(Constants.ORDER_START_ENT_TIME, orderId, JSONObject.toJSONString(parseOrder));
}
}else{
//没有数据将起始和结束时间设置成为一样的
//上车经纬度和下车经纬度设置成为一样的
order.setGetOnLat(lat);
order.setGetOnLng(lng);
order.setCityCode(Constants.CITY_CODE_CHENG_DU);
order.setGetOfLng(lng);
order.setGetOfLat(lat);
order.setEndTime(Long.parseLong((timestamp + "000")));
order.setStartTime(Long.parseLong((timestamp + "000")));
order.setOrderId(orderId);
//将对象转换成为字符串存入到redis当中去
jedis.hset(Constants.ORDER_START_ENT_TIME, orderId, JSONObject.toJSONString(order));
}
//每小时订单统计
hourOrderCount(orderId, timestamp);
}
JedisUtil.returnJedis(jedis);
}
4、第四步提交消费的kafka的偏移量到 hbase的表中进行管理
//获取到消费完成的offset的偏移量
val offsetRanges: Array[OffsetRange] = eachRdd.asInstanceOf[HasOffsetRanges].offsetRanges
//将offset保存到hbase里面去默认可以手动提交保存到kafak的一个topic里面去
//将offset保存到kafak里面去
// result.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
for (eachrange <- offsetRanges) {
val startOffset: Long = eachrange.fromOffset
val endOffset: Long = eachrange.untilOffset
val topic: String = eachrange.topic
val partition: Int = eachrange.partition
//将offset保存到hbase里面去
HbaseTools.saveBatchOffset(group, topic, partition + "", endOffset)
}
def saveBatchOffset(group: String, topic: String, partition: String, offset: Long): Unit = {
val conn: Connection = HbaseTools.getHbaseConn
val table: Table = conn.getTable(TableName.valueOf(Constants.HBASE_OFFSET_STORE_TABLE))
val rowkey = group + ":" + topic
val columName = group + ":" + topic + ":" + partition
val put = new Put(rowkey.getBytes())
put.addColumn(Constants.HBASE_OFFSET_FAMILY_NAME.getBytes(), columName.getBytes(), offset.toString.getBytes())
table.put(put)
table.close()
conn.close()
}
hbase_offset_store的存储格式如下

