

PySpark 之 SparkSQL 编程
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1. DataFrame 的创建
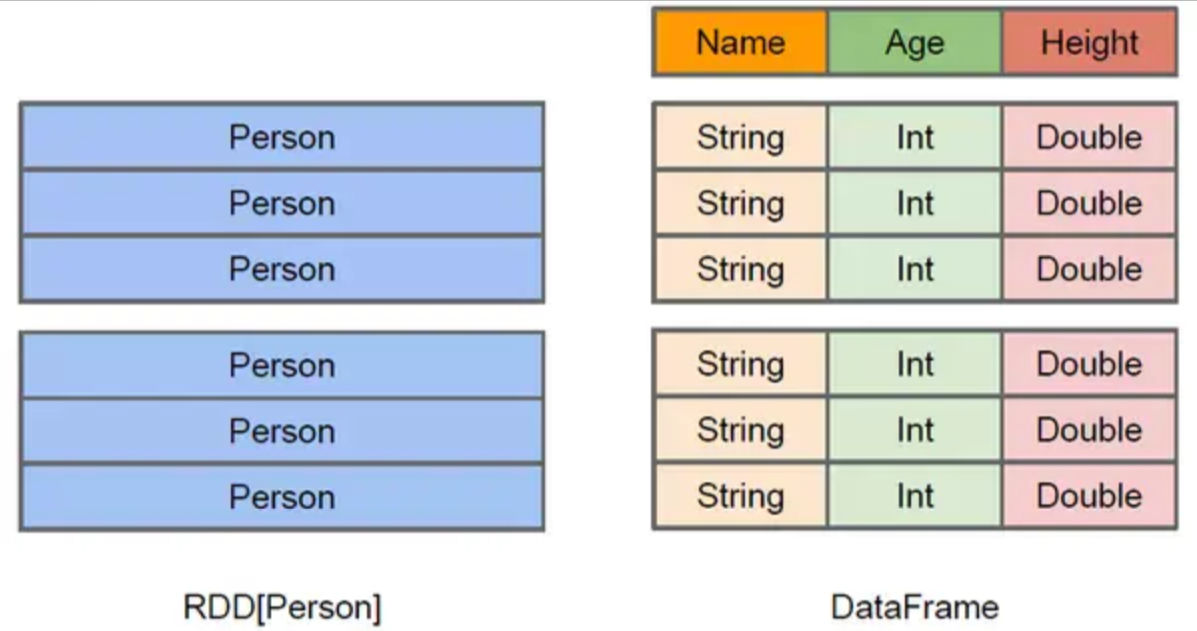
1.1 RDD 和 DataFrame 的区别
RDD是一种弹性分布式数据集Spark中的基本抽象。表示一种不可变的、分区储存的集合可以进行并行操作DataFrame是一种以列对数据进行分组表达的分布式集合DataFrame等同于Spark SQL中的关系表。相同点是他们都是为了支持分布式计算而设计
注意
rdd在Excutor上跑的大部分是Python代码只有少部分是java字节码而SparkSQL在Excutor上跑的全是Java字节码因此其性能要比rdd更好灵活性也更好
1.1 二元组
# coding=utf-8
from pyspark.sql import SparkSession
session = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = session.sparkContext
# 使用二元组创建DataFrame
a = [('Alice', 1)]
df = session.createDataFrame(a, ['name', 'age'])
df.show()
+-----+---+
| name|age|
+-----+---+
|Alice| 1|
+-----+---+
1.2 键值对
# 键值对
b = [{'name': 'Alice', 'age': 1}]
df = session.createDataFrame(b)
df.show()
1.3 rdd 创建
# rdd 创建
c = [('Alice', 1)]
rdd = sc.parallelize(c)
df = session.createDataFrame(data=rdd, schema=['name', 'age'])
df.show()
1.4 基于 rdd 和 ROW 创建
# 基于rdd和ROW创建DataFrame
from pyspark import Row
d = [('Alice', 1)]
rdd = sc.parallelize(d)
Person = Row("name", "age")
person = rdd.map(lambda r: Person(*r))
df = session.createDataFrame(person)
df.show()
1.5 基于 rdd 和 StructType 创建
# 基于rdd和StructType创建DataFrame
from pyspark.sql.types import StructType, StringType, IntegerType, StructField
e = [('Alice', 1)]
rdd = sc.parallelize(e)
schema = StructType(
[
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
]
)
df = session.createDataFrame(rdd, schema)
df.show()
1.6 基于 pandas 创建
# 基于 pandas 创建
import pandas as pd
# 方法一
f = [('Alice', 1)]
df = session.createDataFrame(data=pd.DataFrame(f), schema=['name', 'age'])
df.show()
# 方法二
pdf = pd.DataFrame([("LiLei",18),("HanMeiMei",17)],columns = ["name","age"])
df = spark.createDataFrame(pdf)
df.show()
1.7 从文件读取创建
# person.json
{"name": "rose", "age": 18}
{"name": "lila", "age": 19}
# person.csv
name,age
rose,18
lila, 19
# person.txt
rose
lila
创建方式
# 从文件读取
df1 = session.read.json('person.json')
df1.show()
df2 = session.read.load('person.json', format='json')
df2.show()
df3 = session.read.csv('person.csv', sep=',', header=True)
df3.show()
# 可从 hdfs 中读取
df4 = session.read.text(paths='person.txt')
df4.show()
运行结果
+---+----+
|age|name|
+---+----+
| 18|rose|
| 19|lila|
+---+----+
+---+----+
|age|name|
+---+----+
| 18|rose|
| 19|lila|
+---+----+
+----+---+
|name|age|
+----+---+
|rose| 18|
|lila| 19|
+----+---+
+-----+
|value|
+-----+
| rose|
| lila|
+-----+
1.8 从MySQL 数据库读取
from pyspark import SparkContext
from pyspark.sql import SQLContext
import pyspark.sql.functions as F
sc = SparkContext("local", appName="mysqltest")
sqlContext = SQLContext(sc)
df = sqlContext.read.format("jdbc").options(
url="jdbc:mysql://localhost:3306/mydata?user=root&password=mysql&"
"useUnicode=true&characterEncoding=utf-8&useJDBCCompliantTimezoneShift=true&"
"useLegacyDatetimeCode=false&serverTimezone=UTC ", dbtable="detail_data").load()
df.show(n=5)
sc.stop()
注意需要先下载安装Mysql-connector-java.jar
1.9 toDF方法
rdd = sc.parallelize([("LiLei", 15, 88), ("HanMeiMei", 16, 90), ("DaChui", 17, 60)])
df = rdd.toDF(["name", "age", "score"])
df.show()
1.10 读取hive数据表
session.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
session.sql("LOAD DATA LOCAL INPATH 'data/kv1.txt' INTO TABLE src")
df = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
df.show(5)
1.11 读取 parquet 文件
df = session.read.parquet("data/users.parquet")
df.show()
参考文章
2. DataFrame 保存文件
可以保存成 csv 文件、json文件、parquet 文件或者保存成 hive 数据表
# 保存成 csv 文件
df = session.read.format("json").load("data/people.json")
df.write.format("csv").option("header","true").save("people.csv")
# 先转换成 rdd 再保存成 txt 文件
df.rdd.saveAsTextFile("people.txt")
# 保存成 json 文件
df.write.json("people.json")
# 保存成 parquet 文件, 压缩格式, 占用存储小, 且是 spark 内存中存储格式加载最快
df.write.partitionBy("age").format("parquet").save("namesAndAges.parquet")
df.write.parquet("people.parquet")
# 保存成 hive 数据表
df.write.bucketBy(42, "name").sortBy("age").saveAsTable("people")
3. 常用 API 操作
3.1 Action 操作
常用 Action 操作包括 show、count、collect、describe、take、head、first 等操作
# coding=utf-8
from pyspark import Row
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, StructField
session = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = session.sparkContext
info_list = [("rose", 15, 'F'), ("lila", 16, 'F'), ("john", 17, 'M')]
schema = ["name", "age", "gender"]
df = session.createDataFrame(info_list, schema)
df.show(n=2, truncate=True, vertical=False)
print(df.count())
data_list = df.collect()
print(data_list)
print(df.first()) # 返回第一行
print(df.take(2)) # 以Row对象的形式返回DataFrame的前几行
print(df.head(2)) # 返回前 n 行
print(df.describe()) # 探索性数据分析
df.printSchema() # 以树的格式输出到控制台
运行结果
# df.show()
+----+---+------+
|name|age|gender|
+----+---+------+
|rose| 15| F|
|lila| 16| F|
+----+---+------+
only showing top 2 rows
# df.count()
3
# df.collect()
[Row(name='rose', age=15, gender='F'), Row(name='lila', age=16, gender='F'), Row(name='john', age=17, gender='M')]
# df.first()
Row(name='rose', age=15, gender='F')
# df.take(2)
[Row(name='rose', age=15, gender='F'), Row(name='lila', age=16, gender='F')]
# df.head(2)
[Row(name='rose', age=15, gender='F'), Row(name='lila', age=16, gender='F')]
# df.describe()
DataFrame[summary: string, name: string, age: string, gender: string]
# df.priceSchema()
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
3.2 类 RDD 操作
DataFrame 与 RDD 之间可以相互转换
# df ---> rdd
df.rdd
# rdd ---> df
df.toDF(schema)
DataFrame 转换为 rdd 后一些常用的 rdd 操作也是支持的比如distinct、cache、sample、foreach、intersect、except、map、flatMap、filter但是不够灵活
# coding=utf-8
from pyspark import Row
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, StructField
from pyspark.sql.functions import *
session = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = session.sparkContext
# 类 rdd 操作转换为 rdd使用 .rdd
data_list = [("Hello World",), ("Hello Python",), ("Hello Spark",)]
schema = ['value']
df = session.createDataFrame(data_list, schema)
df.show()
+------------+
| value|
+------------+
| Hello World|
|Hello Python|
| Hello Spark|
+------------+
rdd = df.rdd # 转换为 rdd
print(rdd.collect()) # [Row(value='Hello World'), Row(value='Hello Python'), Row(value='Hello Spark')]
1、map
# 转换为大写再转换为 df
df_rdd = rdd.map(lambda x: Row(x[0].upper()))
df_rdd.toDF(schema).show()
+------------+
| value|
+------------+
| HELLO WORLD|
|HELLO PYTHON|
| HELLO SPARK|
+------------+
2、flatMap
# df_flat = rdd.flatMap(lambda x: x[0].split(" "))
# print(df_flat.collect()) # ['Hello', 'World', 'Hello', 'Python', 'Hello', 'Spark']
df_flat = rdd.flatMap(lambda x: x[0].split(" ")).map(lambda x: Row(x)).toDF(schema)
df_flat.show()
+------+
| value|
+------+
| Hello|
| World|
| Hello|
|Python|
| Hello|
| Spark|
+------+
3、filter
# 过滤只有以 Python 结尾的值
df_filter = rdd.filter(lambda x: x[0].endswith('Python'))
print(df_filter.collect())
df_filter.toDF(schema).show()
[Row(value='Hello Python')]
+------------+
| value|
+------------+
|Hello Python|
+------------+
4、distinct 去重
df_flat.distinct().show()
+------+
| value|
+------+
| World|
| Hello|
|Python|
| Spark|
+------+
5、cache 缓存
df.cache() # 缓存
df.unpersist() # 去掉缓存
6、sample 抽样
df_sample = df.sample(False, 0.6, 0)
df_sample.show()
+------------+
| value|
+------------+
| Hello World|
|Hello Python|
| Hello Spark|
+------------+
7、intersect 交集
df2 = session.createDataFrame([["Hello World"], ["Hello Scala"], ["Hello Spark"]]).toDF("value")
df_intersect = df.intersect(df2)
df_intersect.show()
+-----------+
| value|
+-----------+
|Hello Spark|
|Hello World|
+-----------+
8、exceptAll 补集
# 无补集
df_except = df.exceptAll(df2)
df_except.show()
3.2.1 df 转换 rdd 后 map、flatMap、filter区别
1、rdd.map
def func_1(row):
print(row)
return row[0].upper()
rdd1 = rdd.map(lambda row: func_1(row))
print(rdd1.collect()) # ['HELLO WORLD', 'HELLO PYTHON', 'HELLO SPARK']
# 每一个 row
Row(value='Hello Spark')
Row(value='Hello Python')
Row(value='Hello World')
2、rdd.filter
def func_2(row):
print(row)
return row
rdd2 = rdd.filter(lambda row: func_2(row))
print(rdd2.collect()) # [Row(value='Hello World'), Row(value='Hello Python'), Row(value='Hello Spark')]
# 每一个 row
Row(value='Hello Spark')
Row(value='Hello Python')
Row(value='Hello World')
3、rdd.flatMap
def func_3(row):
print(row)
print(dir(row))
print(len(row)) # 1
return row[0].split(" ")
rdd3 = rdd.flatMap(lambda row: func_3(row))
print(rdd3.collect()) # ['Hello', 'World', 'Hello', 'Python', 'Hello', 'Spark']
# 每一个 row
Row(value='Hello Spark')
Row(value='Hello Python')
Row(value='Hello World')
总结
rowRow对象 类似于list在上面每个row只有一个元素filter后返回的仍然是Row对象而map、flatMap却是Python对象
3.3 类 SQL操作
类 sql 操作比类 rdd 操作更为灵活包括查询 select、selectExpr、where、表连接 join、union、unionAll、表分组 groupby、agg、pivot 等
# coding=utf-8
from pyspark import Row
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, StructField
from pyspark.sql.functions import *
session = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = session.sparkContext
info_list = [("rose", 15, 'F'), ("lila", 16, 'F'), ("john", 17, 'M'), ('david', 18, None)]
schema = ["name", "age", "gender"]
df = session.createDataFrame(info_list, schema)
df.show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
+-----+---+------+
3.3.1 表查询
常用方法有select、filter、selectExpr、where
# 选择某列限制查询条数 limit
df.select('name').limit(2).show()
+----+
|name|
+----+
|rose|
|lila|
+----+
# 选择多列并对某列进行计算
df.select('name', df['age'] + 1).show()
+-----+---------+
| name|(age + 1)|
+-----+---------+
| rose| 16|
| lila| 17|
| john| 18|
|david| 19|
+-----+---------+
# 选择多列并对某列进行计算最后对计算的列名进行重命名
df.select('name', -df['age'] + 2021).toDF('name', 'birthday').show()
+-----+--------+
| name|birthday|
+-----+--------+
| rose| 2006|
| lila| 2005|
| john| 2004|
|david| 2003|
+-----+--------+
# selectExpr 使用 UDF 函数指定别名
import datetime
session.udf.register('getBirthYear', lambda age: datetime.datetime.now().year - age)
df.selectExpr('name', 'getBirthYear(age) as birth_year', 'UPPER(gender) as gender').show()
+-----+----------+------+
| name|birth_year|gender|
+-----+----------+------+
| rose| 2006| F|
| lila| 2005| F|
| john| 2004| M|
|david| 2003| null|
+-----+----------+------+
# where 查询条件
df.where('gender="M" and age=17').show()
+----+---+------+
|name|age|gender|
+----+---+------+
|john| 17| M|
+----+---+------+
# filter 查询
df.filter(df['age'] > 16).show()
df.filter('gender = "M"').show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| john| 17| M|
|david| 18| null|
+-----+---+------+
+----+---+------+
|name|age|gender|
+----+---+------+
|john| 17| M|
+----+---+------+
3.3.2 表连接 join、union
df_score = session.createDataFrame([('john', 'M', 88), ('rose', 'F', 90), ('david', 'M', 50)],
schema=['name', 'gender', 'score'])
df_score.show()
| name|gender|score|
+-----+------+-----+
| john| M| 88|
| rose| F| 90|
|david| M| 50|
+-----+------+-----+
# join 单个字段连接
df.join(df_score.select('name', 'score'), 'name').show()
+-----+---+------+-----+
| name|age|gender|score|
+-----+---+------+-----+
|david| 18| null| 50|
| john| 17| M| 88|
| rose| 15| F| 90|
+-----+---+------+-----+
# join 多个字段连接
df.join(df_score, ['name', 'gender']).show()
+----+------+---+-----+
|name|gender|age|score|
+----+------+---+-----+
|john| M| 17| 88|
|rose| F| 15| 90|
+----+------+---+-----+
# 指定连接方式"inner","left","right","outer","semi","full","leftanti","anti"等
df.join(df_score, ['name', 'gender'], 'right').show()
+-----+------+----+-----+
| name|gender| age|score|
+-----+------+----+-----+
| john| M| 17| 88|
|david| M|null| 50|
| rose| F| 15| 90|
+-----+------+----+-----+
# 灵活指定连接关系
df_mark = df_score.withColumnRenamed('gender', 'sex')
df_mark.show()
+-----+---+-----+
| name|sex|score|
+-----+---+-----+
| john| M| 88|
| rose| F| 90|
|david| M| 50|
+-----+---+-----+
df.join(df_mark, (df['name'] == df_mark['name']) & (df['gender'] == df_mark['sex']), 'inner').show()
+----+---+------+----+---+-----+
|name|age|gender|name|sex|score|
+----+---+------+----+---+-----+
|john| 17| M|john| M| 88|
|rose| 15| F|rose| F| 90|
+----+---+------+----+---+-----+
# 合并 union
df_student = session.createDataFrame([("Jim", 18, "male"), ("Lily", 16, "female")], schema=["name", "age", "gender"])
df.union(df_student).show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
| Jim| 18| male|
| Lily| 16|female|
+-----+---+------+
3.3.2 groupBy、agg 分组聚合
# 分组 groupBy
from pyspark.sql import functions as F
# 按性别进行分组再找出最大值
df.groupBy('gender').max('age').show()
+------+--------+
|gender|max(age)|
+------+--------+
| F| 16|
| null| 18|
| M| 17|
+------+--------+
# 分组后聚合groupBy、agg mean 求平均值
df.groupBy('gender').agg(F.mean('age').alias('mean_age'), F.collect_list('name').alias('names')).show()
+------+--------+------------+
|gender|mean_age| names|
+------+--------+------------+
| F| 15.5|[rose, lila]|
| null| 18.0| [david]|
| M| 17.0| [john]|
+------+--------+------------+
df.groupBy('gender').agg(F.expr('avg(age)'), F.expr('collect_list(name)')).show()
+------+--------+------------------+
|gender|avg(age)|collect_list(name)|
+------+--------+------------------+
| F| 15.5| [rose, lila]|
| null| 18.0| [david]|
| M| 17.0| [john]|
+------+--------+------------------+
分组透视
# 表分组后透视groupBy,pivot
df_student = session.createDataFrame([("LiLei", 18, "male", 1), ("HanMeiMei", 16, "female", 1),
("Jim", 17, "male", 2), ("DaChui", 20, "male", 2)]).toDF("name", "age", "gender",
"class")
df_student.show()
df_student.groupBy("class").pivot("gender").max("age").show()
+---------+---+------+-----+
| name|age|gender|class|
+---------+---+------+-----+
| LiLei| 18| male| 1|
|HanMeiMei| 16|female| 1|
| Jim| 17| male| 2|
| DaChui| 20| male| 2|
+---------+---+------+-----+
+-----+------+----+
|class|female|male|
+-----+------+----+
| 1| 16| 18|
| 2| null| 20|
+-----+------+----+
窗口函数
# 窗口函数
df2 = session.createDataFrame([("LiLei", 78, "class1"), ("HanMeiMei", 87, "class1"),
("DaChui", 65, "class2"), ("RuHua", 55, "class2")]) \
.toDF("name", "score", "class")
df2.show()
dforder = df2.selectExpr("name", "score", "class",
"row_number() over (partition by class order by score desc) as order")
dforder.show()
+---------+-----+------+
| name|score| class|
+---------+-----+------+
| LiLei| 78|class1|
|HanMeiMei| 87|class1|
| DaChui| 65|class2|
| RuHua| 55|class2|
+---------+-----+------+
+---------+-----+------+-----+
| name|score| class|order|
+---------+-----+------+-----+
| DaChui| 65|class2| 1|
| RuHua| 55|class2| 2|
|HanMeiMei| 87|class1| 1|
| LiLei| 78|class1| 2|
+---------+-----+------+-----+
3.4 类 Excel 操作
包括增加、删除列替换某些值、去除、填充空行等操作
info_list = [("rose", 15, 'F'), ("lila", 16, 'F'), ("john", 17, 'M'), ('david', 18, None)]
schema = ["name", "age", "gender"]
df = session.createDataFrame(info_list, schema)
df.show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
+-----+---+------+
1、列操作
# 增加列
df_new = df.withColumn('year', -df['age'] + 2021)
df_new.show()
+-----+---+------+----+
| name|age|gender|year|
+-----+---+------+----+
| rose| 15| F|2006|
| lila| 16| F|2005|
| john| 17| M|2004|
|david| 18| null|2003|
+-----+---+------+----+
# 更换列顺序
df_new.select('name', 'age', 'year', 'gender').show()
+-----+---+----+------+
| name|age|year|gender|
+-----+---+----+------+
| rose| 15|2006| F|
| lila| 16|2005| F|
| john| 17|2004| M|
|david| 18|2003| null|
+-----+---+----+------+
# 删除列
df_new.drop('year').show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
+-----+---+------+
# 列名重命名
df_new.withColumnRenamed('gender', 'sex').show()
+-----+---+----+----+
| name|age| sex|year|
+-----+---+----+----+
| rose| 15| F|2006|
| lila| 16| F|2005|
| john| 17| M|2004|
|david| 18|null|2003|
+-----+---+----+----+
2、排序 sort
# 排序
df.sort(df['age'].desc()).show() # asc
+-----+---+------+
| name|age|gender|
+-----+---+------+
|david| 18| null|
| john| 17| M|
| lila| 16| F|
| rose| 15| F|
+-----+---+------+
# 根据多个字段排序
df.orderBy(df['age'].desc(), df['gender'].desc()).show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
|david| 18| null|
| john| 17| M|
| lila| 16| F|
| rose| 15| F|
+-----+---+------+
3、去除、填充空行
# 去除 nan 值行
df.na.drop().show()
# df.dropna().show()
# 填充 nan 值
df.fillna('M').show()
# df.na.fill('M').show()
4、替换
# 替换某些值
df.na.replace({"": "M", "david": "lisi"}).show()
# df.replace({"": "M", "david": "lisi"}).show()
+----+---+------+
|name|age|gender|
+----+---+------+
|rose| 15| F|
|lila| 16| F|
|john| 17| M|
|lisi| 18| null|
+----+---+------+
5、去重
# 去重默认根据全部字段
df2 = df.unionAll(df)
df2.show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
+-----+---+------+
df2.dropDuplicates().show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| john| 17| M|
|david| 18| null|
| rose| 15| F|
| lila| 16| F|
+-----+---+------+
# 去重根据部分字段
df.dropDuplicates(['age']).show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| john| 17| M|
|david| 18| null|
| rose| 15| F|
| lila| 16| F|
+-----+---+------+
6、其他
# 简单聚合
df.agg({'name': 'count', 'age': 'avg'}).show()
+-----------+--------+
|count(name)|avg(age)|
+-----------+--------+
| 4| 16.5|
+-----------+--------+
# 汇总信息
df.describe().show()
+-------+-----+------------------+------+
|summary| name| age|gender|
+-------+-----+------------------+------+
| count| 4| 4| 3|
| mean| null| 16.5| null|
| stddev| null|1.2909944487358056| null|
| min|david| 15| F|
| max| rose| 18| M|
+-------+-----+------------------+------+
# 频率超过 0.5 的年龄和性别
df.stat.freqItems(('age', 'gender'), 0.5).show()
+-------------+----------------+
|age_freqItems|gender_freqItems|
+-------------+----------------+
| [16]| [F]|
+-------------+----------------+
4. 与 SQL 交互
除了上述常用 api 操作外还可以将 DataFrame 注册为临时表视图或者全局表视图然后使用 SQL 语句来操作 DataFrame另外也可以对 hive 进行增删改查。
4.1 注册视图与 SQL 交互
1、注册为临时视图
info_list = [("rose", 15, 'F'), ("lila", 16, 'F'), ("john", 17, 'M'), ('david', 18, None)]
schema = ["name", "age", "gender"]
df = session.createDataFrame(info_list, schema)
df.show()
# 注册为临时视图生命周期与 SparkSession 关联
df.createOrReplaceTempView('people')
session.sql('select * from people WHERE age = "18" ').show()
+-----+---+------+
+-----+---+------+
|david| 18| null|
+-----+---+------+
2、注册为全局视图
# 注册为全局视图生命周期与 Spark 应用关联
df.createOrReplaceGlobalTempView('people1')
session.sql('select t.gender, collect_list(t.name) as names from global_temp.people1 t group by t.gender ').show()
+------+------------+
|gender| names|
+------+------------+
| F|[rose, lila]|
| null| [david]|
| M| [john]|
+------+------------+
session.newSession().sql('select * from global_temp.people1').show()
+-----+---+------+
| name|age|gender|
+-----+---+------+
| rose| 15| F|
| lila| 16| F|
| john| 17| M|
|david| 18| null|
+-----+---+------+