

RabbitMQ——RabbitMQ高级特性(消息存储机制、惰性队列,镜像队列,磁盘和内存告警、流控机制)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
摘要
介绍RabbitMQ相关的一些原理,主要内容包括RabbitMQ存储机制、磁盘和内存告警、流控机制、镜像队列。
RabbitMQ存储机制
不管是持久化的消息还是非持久化的消息都可以被写入到磁盘。持久化的消息在到达队列时就被写入到磁盘,并且如果可以,持久化的消息也会在内存中保存一份备份,这样可以提高一定的性能,当内存吃紧的时候会从内存中清除。非持久化的消息一般只保存在内存中,在内存吃紧的时候会被换入到磁盘中,以节省内存空间。这两种类型的消息的落盘处理都在RabbitMQ 的"持久层"中完成。
持久层是一个逻辑上的概念,实际包含两个部分: 队列索引(rabbit queue index) 和消息存储(rabbit_msg_store)。rabbit_queue_index 负责维护队列中落盘消息的信息,包括消息的存储地点、是否己被交付给消费者、是否己被消费者ack 等。每个队列都有与之对应的一个rabbit_queue_index,rabbit_msg_store以键值对的形式存储消息,它被所有队列共享,在每个节点中有且只有一个。
消息的存储
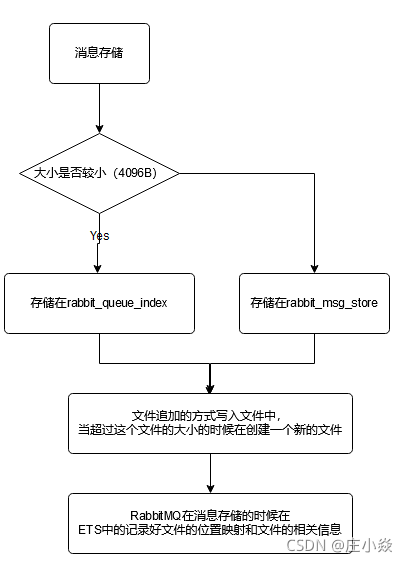
从技术层面上来说,rabbit_msg_store 具体还可以分为msg store persistent 和msg store transient, msg_store_persistent 负责持久化消息的持久化,重启后消息不会丢失; msg_store _transient 负责非持久化消息的持久化,重启后消息会丢失。通常情况下,习惯性地将msg_store_persistent 和msg_store_transient 看成rabbit_msg_store 这样一个整体。
消息(包括消息体、属性和headers) 可以直接存储在rabbit queue index 中,也可以被保存在rabbit_msg_store 中。默认在$RABBITMQ HOME/var/lib/mnesia/rabbit@$HOSTNAME/路径下包含queues 、msg_store persistent 、msg_store _ transient 这3 个文件夹(下面信息中加粗的部分),其分别存储对应的信息。
最佳的配备是较小的消息存储在rabbit_queue_index 中而较大的消息存储在rabbit_msg_store 中。这个消息大小的界定可以通过queue index embed msgs below来配置, 默认大小为4096 ,单位为B 。注意这里的消息大小是指消息体、属性及headers 整体的大小。当一个消息小于设定的大小闹值时就可以存储在rabbit queue index 中,这样可以得到性能上的优化。
rabbit_queue_index 中以顺序(文件名从0 开始累加〉的段文件来进行存储,后缀为" . idx " ,每个段文件中包含固定的SEGMENT ENTRY COUNT 条记录,SEGMENT-ENTRY-COUNT 默认值为16384 。每个rabbit_queue_index 从磁盘中读取消息的时候至少要在内存中维护一个段文件,所以设置queue_index_embed_msgs_below 值的时候要格外谨慎, 一点点增大也可能会引起内存爆炸式的增长。经过rabbit_msg_store 处理的所有消息都会以追加的方式写入到文件中,当一个文件的大小超过指定的限制(file size limit) 后, 关闭这个文件再创建一个新的文件以供新的消息写入。文件名(文件后缀是". rdq") 从0 开始进行累加, 因此文件名最小的文件也是最老的文件。在进行消息的存储时, RabbitMQ会在ETS(Erlang Term Storage) 表中记录消息在文件中的位置映射(Index) 和文件的相关信息(FileSummary)。
消息的读取
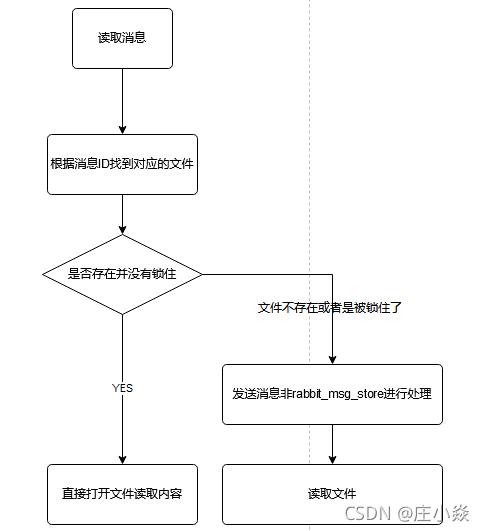
在读取消息的时候,先根据消息的ID(msg id) 找到对应存储的文件,如果文件存在并且未被锁住,则直接打开文件,从指定位置读取消息的内容。如果文件不存在或者被锁住了,则发送请求由rabbit_msg_store 进行处理。
消息的删除
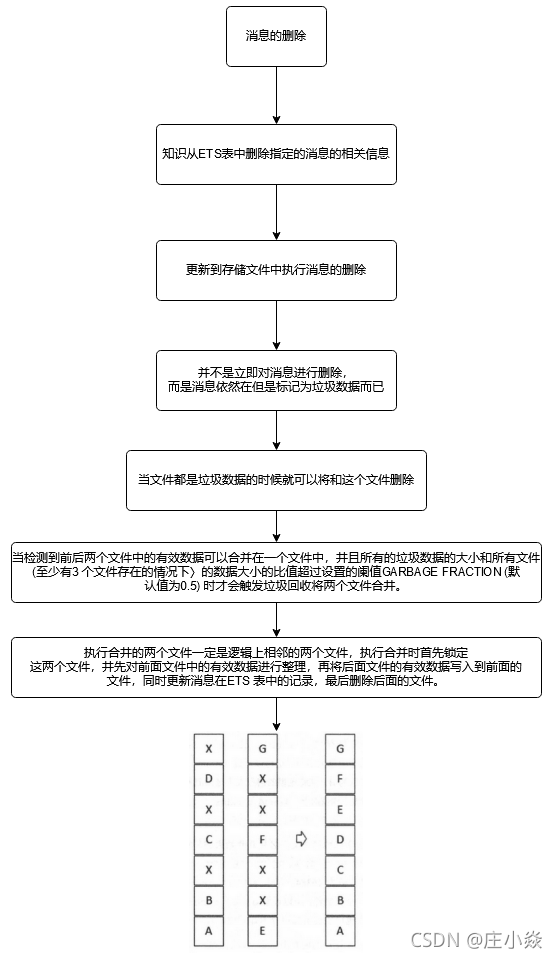
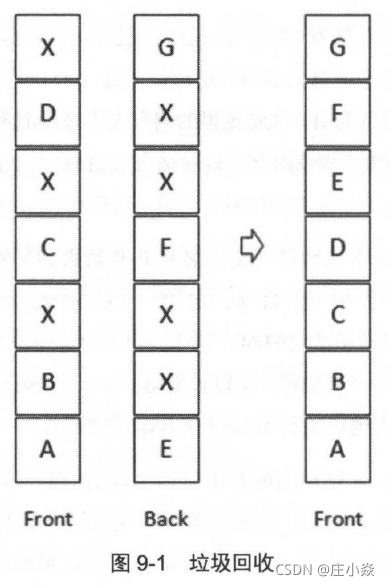
消息的删除只是从ETS 表删除指定消息的相关信息, 同时更新消息对应的存储文件的相关信息。执行消息删除操作时,井不立即对在文件中的消息进行删除,也就是说消息依然在文件中,仅仅是标记为垃圾数据而己。当一个文件中都是垃圾数据时可以将这个文件删除。当检测到前后两个文件中的有效数据可以合并在一个文件中,井且所有的垃圾数据的大小和所有文件(至少有3 个文件存在的情况下〉的数据大小的比值超过设置的阑值GARBAGE FRACTION (默认值为0.5) 时才会触发垃圾回收将两个文件合井。执行合井的两个文件一定是逻辑上相邻的两个文件。如图所示,执行合并时首先锁定这两个文件,井先对前面文件中的有效数据进行整理,再将后面文件的有效数据写入到前面的文件,同时更新消息在ETS 表中的记录,最后删除后面的文件。
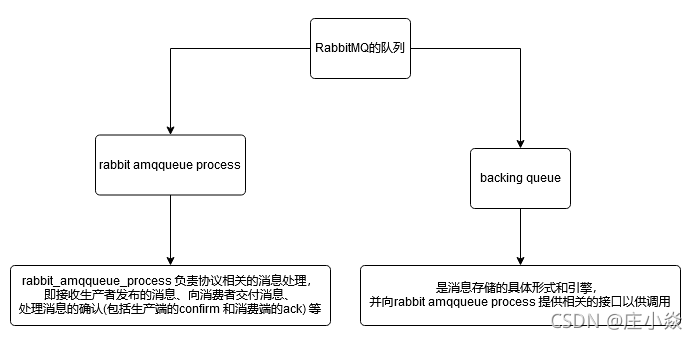
RabbitMQ的队列的结构
通常队列由rabbit_amq_queue_process 和backing_queue 这两部分组成,rabbit_amqqueue_process负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的confirm 和消费端的ack) 等。backing queue是消息存储的具体形式和引擎,并向rabbit amqqueue process 提供相关的接口以供调用。
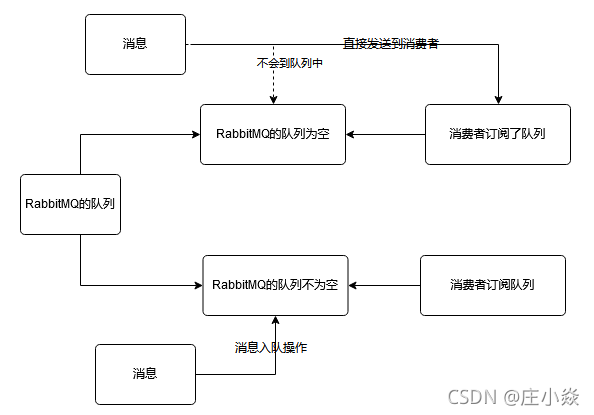
如果消息投递的目的队列是空的,并且有消费者订阅了这个队列,那么该消息会直接发送给消费者,不会经过队列这一步。而当消息无法直接投递给消费者时,需要暂时将消息存入队列,以便重新投递。消息存入队列后,不是固定不变的,它会随着系统的负载在队列中不断地流动,消息的状态会不断发生变化。RabbitMQ 中的队列消息可能会处于以下4 种状态。
- alpha: 消息内容(包括消息体、属性和headers) 和消息索引都存储在内存中。
- beta: 消息内容保存在磁盘中,消息索引保存在内存中。
- gamma: 消息内容保存在磁盘中,消息索引在磁盘和内存中都有。
- delta: 消息内容和索引都在磁盘中。
对于持久化的消息,消息内容和消息索引都必须先保存在磁盘上,才会处于上述状态中的一种。而gamma 状态的消息是只有持久化的消息才会有的状态。
RabbitMQ 在运行时会根据统计的消息传送速度定期计算一个当前内存中能够保存的最大消息数量(target_ram_count) ,如果alpha状态的消息数量大于此值时,就会引起消息的状态转换,多余的消息可能会转换到beta 状态、gamma 状态或者delta 状态。区分这4 种状态的主要作用是满足不同的内存和CPU 需求。alpha 状态最耗内存,但很少消耗CPUodelta状态基本不消耗内存,但是需要消耗更多的CPU 和磁盘I10 操作。delta 状态需要执行两次I/o 操作才能读取到消息, 一次是读消息索引(从rabbit queue index 中), 一次是读消息内容(从rabbit_msg_store 中); beta 和gamma 状态都只需要一次II/O操作就可以读取到消息(从rabbit msg store 中)。
对于普通的没有设置优先级和镜像的队列来说, backing queue 的默认实现是rabbit_variable_queue ,其内部通过5 个子队列Ql 、Q2 , Delta、Q3 和Q4 来体现消息的各个状态。整个队列包括rabbit amqqueue process 和backing queue 的各个子队列,其中Ql 、Q4 只包含alpha 状态的消息, Q2 和Q3 包含beta 和gamma 状态的消息, Delta 只包含delta 状态的消息。一般情况下,消息按照Ql → Q2→ Delta→ Q3 → Q4 这样的顺序步骤进行流动,但并不是每一条消息都一定会经历所有的状态,这个取决于当前系统的负载状况。从Ql 至Q4 基本经历内存到磁盘,再由磁盘到内存这样的一个过程,如此可以在队列负载很高的情况下,能够通过将一部分消息由磁盘保存来节省内存空间,而在负载降低的时候,这部分消息又渐渐回到内存被消费者获取,使得整个队列具有很好的弹性。
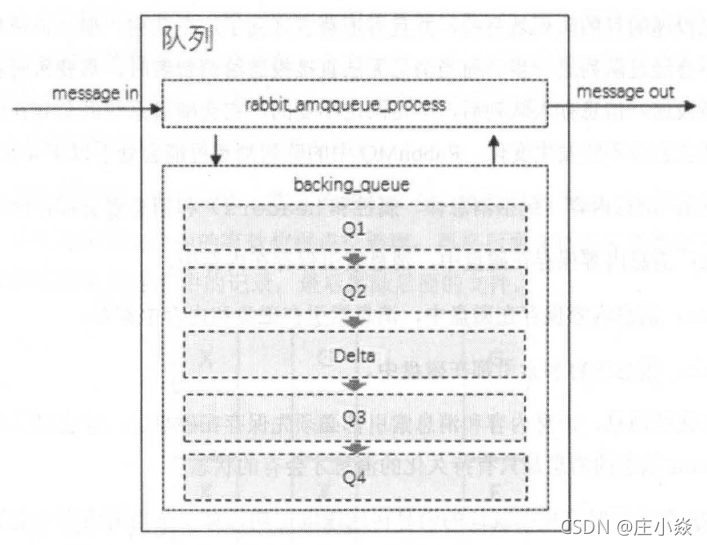
消费者获取消息也会引起消息的状态转换。当消费者获取消息时,首先会从Q4 中获取消息,如果获取成功则返回。如果Q4 为空,则尝试从Q3 中获取消息, 系统首先会判断Q3 是否为空,如果为空则返回队列为空,即此时队列中无消息。如果Q3 不为空,则取出Q3 中的消息,进而再判断此时Q3 和Delta 中的长度,如果都为空,则可以认为Q2 , Delta 、Q3 , Q4 全部为空,此时将Ql 中的消息直接转移至Q4 ,下次直接从Q4 中获取消息。如果Q3 为空, Delta 不为空,则将Delta 的消息转移至Q3 中,下次可以直接从Q3 中获取消息。在将消息从Delta 转移到Q3 的过程中, 是按照索引分段读取的,首先读取某一段,然后判断读取的消息的个数与Delta 中消息的个数是否相等,如果相等,则可以判定此时Delta 中己无消息,则直接将Q2 和刚读取到的消息一并放入到Q3 中:如果不相等,仅将此次读取到的消息转移到Q3。
这里就有两处疑问,第一个疑问是:为什么Q3 为空则可以认定整个队列为空?试想一下,如果Q3 为空, Delta 不为空,那么在Q3 取出最后一条消息的时候, Delta 上的消息就会被转移到Q3 , 这样与Q3 为空矛盾:如果Delta 为空且Q2 不为空,则在Q3 取出最后一条消息时会将Q2 的消息并入到Q3 中,这样也与Q3 为空矛盾: 在Q3 取出最后一条消息之后,如果Q2 、Delta 、Q3 都为空,且Ql 不为空时,则Ql 的消息会被转移到Q4 , 这与Q4 为空矛盾。其实这一番论述也解释了另一个问题: 为什么Q3 和Delta 都为空时,则可以认为Q2 , Delta 、Q3 , Q4 全部
通常在负载正常时,如果消息被消费的速度不小于接收新消息的速度, 对于不需要保证可靠不丢失的消息来说,极有可能只会处于alpha 状态。对于durable 属性设置为true 的消息,它一定会进入gamma 状态,并且在开启publ isher confmn 机制时, 只有到了gamma 状态时才会确认该消息己被接收,若消息消费速度足够快、内存也充足, 这些消息也不会继续走到下一个状态。
在系统负载较高时,己接收到的消息若不能很快被消费掉,这些消息就会进入到很深的队列中去,这样会增加处理每个消息的平均开销。因为要花更多的时间和资源处理"堆积"的消息,如此用来处理新流入的消息的能力就会降低,使得后流入的消息又被积压到很深的队列中继续增大处理每个消息的平均开销,继而情况变得越来越恶化,使得系统的处理能力大大降低。
应对这一问题一般有3 种措施:
- 增加prefetch_count 的值,即一次发送多条消息给消费者, 加快消息被消费的速度
- 采用multiple ack ,降低处理ack 带来的开销
- 流量控制
RabbitMQ惰性队列的原理
RabbitMQ 从3.6.0 版本开始引入了惰性队列( Lazy Queue) 的概念。惰'性队列会尽可能地将消息存入磁盘中,而在消费者消费到相应的消息时才会被加载到内存中,它的一个重要的设计目标是能够支持更长的队列,即支持更多的消息存储。当消费者由于各种各样的原因(比如消费者下线、岩机, 或者由于维护而关闭等〉致使长时间内不能消费消息而造成堆积时, 惰性队列就很有必要了。
默认情况下,当生产者将消息发送到RabbitMQ 的时候, 队列中的消息会尽可能地存储在内存之中,这样可以更加快速地将消息发送给消费者。即使是持久化的消息,在被写入磁盘的同时也会在内存中驻留一份备份。当RabbitMQ 需要释放内存的时候,会将内存中的消息换页至磁盘中,这个操作会耗费较长的时间,也会阻塞队列的操作,进而无法接收新的消息。虽然RabbitMQ 的开发者们一直在升级相关的算法,但是效果始终不太理想,尤其是在消息量特别大的时候。
惰性队列会将接收到的消息直接存入文件系统中,而不管是持久化的或者是非持久化的,这样可以减少了内存的消耗,但是会增加I/O的使用,如果消息是持久化的,那么这样的I/O操作不可避免,惰性队列和持久化的消息可谓是"最佳拍档"。注意如果惰性队列中存储的是非持久化的消息,内存的使用率会一直很稳定,但是重启之后消息一样会丢失。
队列具备两种模式: default 和lazy 。默认的为default 模式,在3.6.0 之前的版本无须做任何变更。lazy模式即为惰性队列的模式,可以通过调用channel.queueDeclare方法的时候在参数中设置,也可以通过Policy 的方式设置,如果一个队列同时使用这两种方式设置,那么Policy 的方式具备更高的优先级。如果要通过声明的方式改变己有队列的模式,那么只能先删除队列,然后再重新声明一个新的。
在队列声明的时候可以通过x-queue-mode 参数来设置队列的模式,取值为default和lazy。下面示例演示了一个惰性队列的声明细节:
Map<String , Object> args = new HashMap<String , Object>();
args . put( "x-queue-mode" , "lazy");
channel. queueDeclare( "myqueue" , false , false , false , args);
对应的Policy 设置方式为:
rabbitmqctl set_policy Lazy " 勺nyqueue$ " ' {"queue-mode ":" lazy" } ' --apply-t 。
queues惰性队列和普通队列相比,只有很小的内存开销。这里很难对每种情况给出一个具体的数值,但是我们可以类比一下:发送l 千万条消息,每条消息的大小为l K.B,并且此时没有任何的消费者,那么普通队列会消耗1.2GB 的内存,而惰性队列只消耗1.5MB 的内存。
如果要将普通队列转变为惰性队列,那么我们需要忍受同样的性能损耗, 首先需要将缓存中的消息换页至磁盘中,然后才能接收新的消息。反之,当将一个惰性队列转变为普通队列的时候,和恢复一个队列执行同样的操作,会将磁盘中的消息批量地导入到内存中。
RabbitMQ的内存告警
当内存使用超过配置的阑值或者磁盘剩余空间低于配置的阑值时, RabbitMQ 都会暂时阻塞( block) 客户端的连接( Connection) 井停止接收从客户端发来的消息,以此避免服务崩溃。与此同时,客户端与服务端的心跳检测也会失效。可以通过rabbitmqctl list connections 命令或者Web 管理界面来查看它的状态。

被阻塞的Connection 的状态要么是blocking ,要么是blocked。前者对应于并不试图发送消息的Connection ,比如消费者关联的Connection ,这种状态下的Connection 可以继续运行。而后者对应于一直有消息发送的Connection ,这种状态下的Connection 会被停止发送消息。注意在一个集群中,如果一个Broker 节点的内存或者磁盘受限,都会引起整个集群中所有的Connection 被阻塞。
理想的情况是当发生阻塞时可以在阻止生产者的同时而又不影响消费者的运行。但是在AMQP 协议中, 一个信道(Channel) 上可以同时承载生产者和消费者, 同一个Connection 中也可以同时承载若干个生产者的信道和消费者的信道,这样就会使阻塞逻辑错乱, 虽然大多数情况下并不会发生任何问题,但还是建议生产和消费的逻辑可以分摊到独立的Connection 之上而不发生任何交集。客户端程序可以通过添加BlockedListener 来监昕相应连接的阻塞信息。
RabbitMQ 服务器会在启动或者执行rabbitmqctl set_Vffi_memory_high_watermark_fraction口命令时计算系统内存的大小。默认情况下vm_memory high watermark 的值为0.4,即内存阑值为0.4, 表示当RabbitMQ 使用的内存超过40%时,就会产生内存告警井阻塞所有生产者的连接。一旦告警被解除(有消息被消费或者从内存转储到磁盘等情况的发生), 一切都会恢复正常。默认情况下将RabbitMQ 所使用内存的阔值设置为40% , 这并不意味着此时RabbitMQ 不能使用超过40% 的内存,这仅仅只是限制了RabbitMQ 的消息生产者。在最坏的情况下, Erlang的垃圾回收机制会导致两倍的内存消耗,也就是80%的使用占比。内存阔值可以通过rabbitmq.config 配置文件来配置,下面示例中设置了默认的内存闽值为0 .4:

RabbitMQ磁盘告警
当剩余磁盘空间低于确定的闽值时, RabbitMQ 同样会阻塞生产者,这样可以避免因非持久化的消息持续换页而耗尽磁盘空间导致服务崩溃。默认情况下,磁盘阈值为50M,这意味着当磁盘剩余空间低于50MB 时会阻塞生产者井停止内存中消息的换页动作。这个阑值的设置可以减小但不能完全消除因磁盘耗尽而导致崩渍的可能性,比如在两次磁盘空间检测期间内,磁盘空间从大于50MB 被耗尽到0MB 。一个相对谨慎的做法是将磁盘阔值设置为与操作系统所显示的内存大小一致。
RabbitMQ 会定期检测磁盘剩余空间,检测的频率与上一次执行检测到的磁盘剩余空间大小有关。正常情况下,每10 秒执行一次检测,随着磁盘剩余空间与磁盘阑值的接近,检测频率会有所增加。当要到达磁盘阑值时,检测频率为每秒10 次,这样有可能会增加系统的负载。
RabbitMQ流控机制
RabbitMQ 可以对内存和磁盘使用量设置阔值,当达到阑值后,生产者将被阻塞Cblock) ,直到对应项恢复正常。除了这两个阔值,从2.8.0 版本开始, RabbitMQ 还引入了流控( Flow Control)机制来确保稳定性。流控机制是用来避免消息的发送速率过快而导致服务器难以支撑的情形。内存和磁盘告警相当于全局的流控(Global Flow Control) ,一旦触发会阻塞集群中所有的Connection ,而本节的流控是针对单个Connection 的,可以称之为Per-Connection Flow Control或者Intemal Flow Control。
流控的原理
Erlang 进程之间并不共享内存Cbina叩类型的除外),而是通过消息传递来通信,每个进程都有自己的进程邮箱Cmailbox) 。默认情况下, Erlang 并没有对进程邮箱的大小进行限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。在RabbitMQ 中,如果生产者持续高速发送,而消费者消费速度较低时,如果没有流控,很快就会使内部进程邮箱的大小达到内存阀值。
RabbitMQ 使用了一种基于信用证算法(credit-based algorithm) 的流控机制来限制发送消息的速率以解决前面所提出的问题。它通过监控各个进程的进程邮箱,当某个进程负载过高而来不及处理消息时,这个进程的进程邮箱就会开始堆积消息。当堆积到一定量时,就会阻塞而不接收上游的新消息。从而慢慢的,上游进程的进程邮箱也会开始堆积消息。当堆积到一定量时也会阻塞而停止接收上游的消息,最后就会使负责网络数据包接收的进程阻塞而暂停接收新的数据。
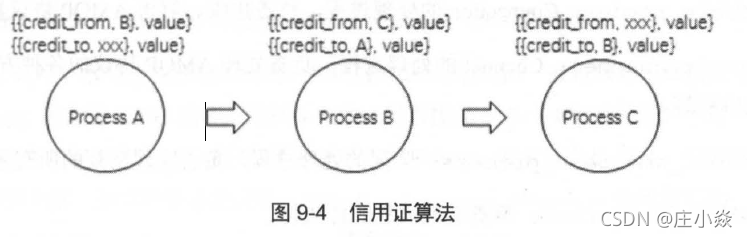
进程A 接收消息井转发至进程B ,进程B 接收消息并转发至进程C 。每个进程中都有一对关于收发消息的credit 值。以进程B 为例, { {credi t from , C} , value}表示能发送多少条消息给C ,每发送一条消息该值减1,当为0 时,进程B 不再往进程C 发送消息也不再接收进程A 的消息。{{credit to , A} , value} 表示再接收多少条消息就向进程A 发送增加credit 值的通知,进程A 接收到该通知后就增加{ {credi t from ,时, value}所对应的值,这样进程A 就能持续发送消息。当上游发送速率高于下游接收速率时, credit值就会被逐渐耗光,这时进程就会被阻塞,阻塞的情况会一直传递到最上游。当上游进程收到来自下游进程的增加credit 值的通知时,若此时上游进程处于阻塞状态则解除阻塞,开始接收更上游进程的消息,一个一个传导最终能够解除最上游的阻塞状态。由此可知,基于信用证的流控机制最终将消息发送进程的发送速率限制在消息处理进程的处理能力范围之内。
一个连接(Connection) 触发流控时会处于"flow" 的状态,也就意味着这个Connection的状态每秒在blocked 和unblocked 之间来回切换数次,这样可以将消息发送的速率控制在服务器能够支撑的范围之内。可以通过rabbitmqctl list connections 命令或者Web管理界面来查看Connection 的状态。

处于flow 状态的Connection 和处于running 状态的Connection 并没有什么不同,这个状态只是告诉系统管理员相应的发送速率受限了。而对于客户端而言,它看到的只是服务器的带宽要比正常情况下要小一些。
流控机制不只是作用于Connection ,同样作用于信道(Channel)和队列。从Connection 到Channel ,再到队列,最后是消息持久化存储形成一个完整的流控链,对于处于整个流控链中的任意进程,只要该进程阻塞,上游的进程必定全部被阻塞。也就是说,如果某个进程达到性能瓶颈,必然会导致上游所有的进程被阻塞。所以我们可以利用流控机制的这个特点找出瓶颈之所在。处理消息的几个关键进程及其对应的顺序关系。
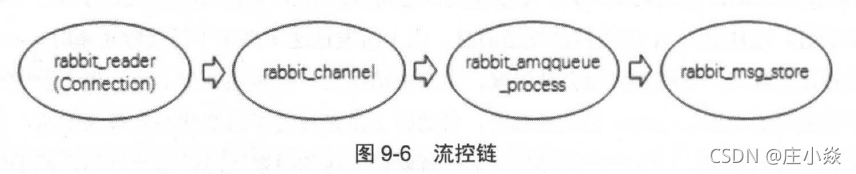
其中的各个进程如下所述。
- rabbi t reader: Connection 的处理进程,负责接收、解析AMQP 协议数据包等。
- rabbit channel: Channel 的处理进程, 负责处理AMQP 协议的各种方法、进行路由解析等。
- rabbit amqqueue process: 队列的处理进程,负责实现队列的所有逻辑。
- rabbit msg store: 负责实现消息的持久化。
当某个Connection 处于flow 状态,但这个Connection 中没有一个Channel 处于flow 状态时,这就意味这个Connection 中有一个或者多个Channel 出现了性能瓶颈。某些Channel 进程的运作(比如处理路由逻辑)会使得服务器CPU 的负载过高从而导致了此种情形。尤其是在发送大量较小的非持久化消息时,此种情形最易显现。
当某个Connection 处于fl ow 状态,并且这个Connection 中也有若干个Channel 处于flow状态,但没有任何一个对应的队列处于flow 状态时,这就意味着有一个或者多个队列出现了性能瓶颈。这可能是由于将消息存入队列的过程中引起服务器CPU 负载过高,或者是将队列中的消息存入磁盘的过程中引起服务器1/0 负载过高而引起的此种情形。尤其是在发送大量较小的持久化消息时,此种情形最易显现。
当某个Connection 处于fl ow 状态,同时这个Connection 中也有若干个Channel 处于flow状态,井且也有若干个对应的队列处于flow 状态时,这就意味着在消息持久化时出现了性能瓶颈。在将队列中的消息存入磁盘的过程中引起服务器1/0 负载过高而引起的此种情形。尤其是在发送大量较大的持久化消息时,此种情形最易显现。
RabbitMQ镜像队列
如果RabbitMQ 集群中只有一个Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable 属性也设置为true,但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过publisherconfmn 机制能够确保客户端知道哪些消息己经存入磁盘,尽管如此, 一般不希望遇到因单点故障导致的服务不可用。
如果RabbitMQ 集群是由多个Broker 节点组成的,那么从服务的整体可用性上来讲,该集群对于单点故障是有弹性的,但是同时也需要注意:尽管交换器和绑定关系能够在单点故障问题上幸免于难,但是队列和其上的存储的消息却不行,这是因为队列进程及其内容仅仅维持在单个节点之上,所以一个节点的失效表现为其对应的队列不可用。
引入镜像队列(Mirror Queue) 的机制,可以将队列镜像到集群中的其他Broker 节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。在通常的用法中,针对每一个配置镜像的队列(以下简称镜像队列〉都包含一个主节点(master) 和若干个从节点(slave) ,相应的结构。
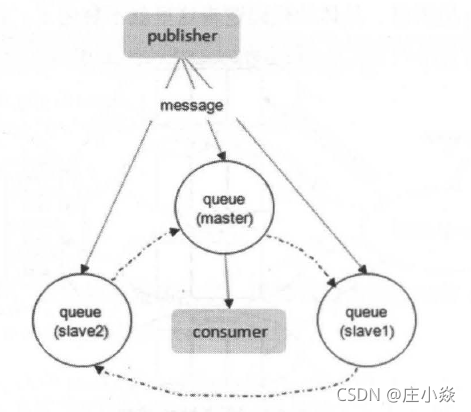
slave会准确地按照master 执行命令的顺序进行动作,故slave 与master 上维护的状态应该是相同的。如果master 由于某种原因失效,那么"资历最老"的slave 会被提升为新的master 。根据slave 加入的时间排序,时间最长的slave 即为"资历最老"。发送到镜像队列的所有消息会被同时发往master 和所有的slave 上,如果此时master 挂掉了,消息还会在slave 上,这样slave提升为master 的时候消息也不会丢失。除发送消息(Basic.Publish) 外的所有动作都只会向master 发送,然后再由master 将命令执行的结果广播给各个slave 。
如果消费者与slave 建立连接井进行订阅消费,其实质上都是从master 上获取消息,只不过看似是从slave 上消费而己。比如消费者与slave 建立了TCP 连接之后执行一个Basic.Get的操作,那么首先是由slave 将Basic.Get 请求发往master ,再由master 准备好数据返回给slave ,最后由slave 投递给消费者。读者可能会有疑问,大多的读写压力都落到了master 上,那么这样是否负载会做不到有效的均衡?或者说是否可以像MySQL 一样能够实现master 写而slave 读呢?注意这里的master 和slave 是针对队列而言的,而队列可以均匀地散落在集群的各个Broker 节点中以达到负载均衡的目的,因为真正的负载还是针对实际的物理机器而言的,而不是内存中驻留的队列进程。
集群中的每个Broker 节点都包含1 个队列的master 和2 个队列的slave , Ql的负载大多都集中在brokerl 上, Q2 的负载大多都集中在broker2 上, Q3 的负载大多都集中在broker3 上,只要确保队列的master 节点均匀散落在集群中的各个Broker 节点即可确保很大程度上的负载均衡(每个队列的流量会有不同,因此均匀散落各个队列的master 也无法确保绝对的负载均衡)。至于为什么不像MySQL 一样读写分离, RabbitMQ 从编程逻辑上来说完全可以实现,但是这样得不到更好的收益,即读写分离并不能进一步优化负载,却会增加编码实现的复杂度,增加出错的可能,显得得不偿失。
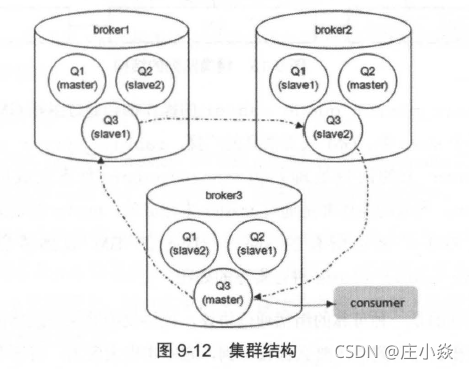
注意要点:
RabbitMQ的镜像队列同时支持publisher confirm 和事务两种机制.在事务机制中,只有当前事务在全部镜像中执行之后,客户端才会收到Tx.Commit-Ok 的消息。同样的,在publisherconfirm 机制中, 生产者进行当前消息确认的前提是该消息被全部进行所接收了。
不同于普通的非镜像队列 ,镜像队列的backing_queue 比较特殊,其实现井非是rabbit_variable_ queue ,它内部包裹了普通backing_queue 进行本地消息消息持久化处理,在此基础上增加了将消息和ack 复制到所有镜像的功能。镜像队列的结构可以参考,master 的backing queue 采用的是rabbit_mirror_queue_master,而slave的backing_queue 实现是rabbit_mirror_queue slave。
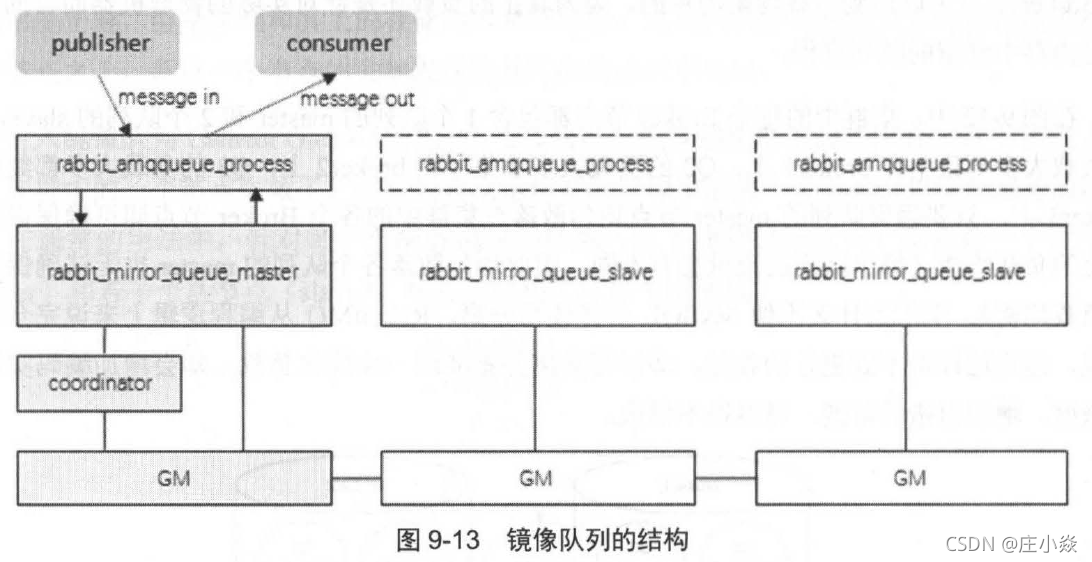
所有对rabbit mirror queue master 的操作都会通过组播GM(Guaranteed Multicast)的方式同步到各个slave 中。GM 负责消息的广播, rabbit mirror queue slave 负责回调处理,而master 上的回调处理是由coordinator 负责完成的。如前所述,除了Basic.Publish ,所有的操作都是通过master 来完成的, master 对消息进行处理的同时将消息的处理通过GM 广播给所有的slave , slave 的GM 收到消息后,通过回调交由rabbit_mirror queue_slave 进行实际的处理。
GM模块实现的是一种可靠的组播通信协议,该协议能够保证组播消息的原子性,即保证组中活着的节点要么都收到消息要么都收不到,它的实现大致为:将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上: 当有节点失效时,相邻的节点会接管以保证本次广播的消息会复制到所有的节点。在master 和slave 上的这些GM 形成一个组(gm_group) ,这个组的信息会记录在Mnesia 中。不同的镜像队列形成不同的组。操作命令从master 对应的GM 发出后,顺着链表传送到所有的节点。由于所有节点组成了一个循环链表, master 对应的GM 最终会收到自己发送的操作命令,这个时候master 就知道该操作命令都同步到了所有的slave 上。
新节点的加入过程如下所示,整个过程就像在链表中间插入一个节点。注意每当一个节点加入或者重新加入到这个镜像链路中时,之前队列保存的内容会被全部清空。
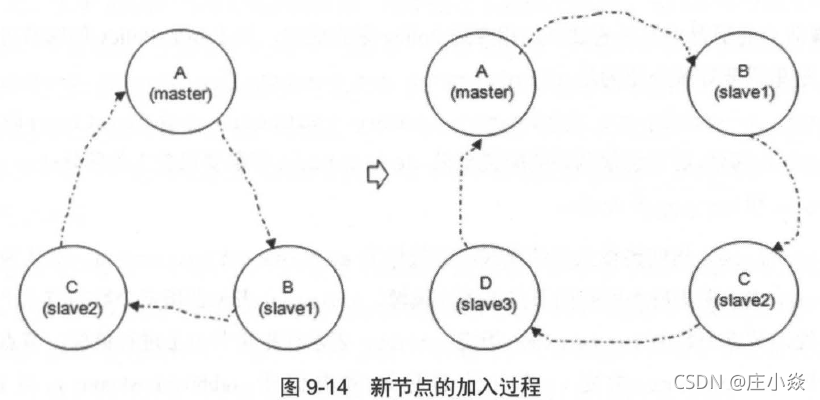
当slave 挂掉之后,除了与slave 相连的客户端连接全部断开,没有其他影响。当master 挂掉之后,会有以下连锁反应:
与master 连接的客户端连接全部断开。
选举最老的slave 作为新的master,因为最老的slave 与旧的master 之间的同步状态应该是最好的。如果此时所有slave 处于未同步状态,则未同步的消息会丢失。
新的master 重新入队所有unack 的消息,因为新的slave 无法区分这些unack 的消息是否己经到达客户端,或者是ack 信息丢失在老的master 链路上,再或者是丢失在老的master 组播ack 消息到所有slave 的链路上,所以出于消息可靠性的考虑,重新入队所有unack 的消息,不过此时客户端可能会有重复消息。
如果客户端连接着slave ,并且Basic.Consume 消费时指定了x-cancel-o 口-hafailover参数,那么断开之时客户端会收到一个Consumer Cancellation Notification 的通知,消费者客户端中会回调Consumer 接口的handleCancel 方法。如果未指定x-cancelon-ha-failover 参数,那么消费者将无法感知master 岩机。
x-cancel-on-ha也ilover 参数的使用示例如下:
Channel channel = . .. ;
Consumer consumer = ..;
Map<String , Object> args = new HashMap<String , Object> () ;
args . put("x-cancel-on-ha-failover" , true);
channel.basicConsume( "my-queue" , false , args , consumer) ;将新节点加入己存在的镜像队列时,默认情况下ha-sync-mode 取值为manual.镜像队列中的消息不会主动同步到新的slave 中,除非显式调用同步命令。当调用同步命令后,队列开始阻塞,无法对其进行其他操作,直到同步完成。当ha-sync-mode 设置为automatic 时,新加入的slav巳会默认同步己知的镜像队列。由于同步过程的限制,所以不建议对生产环境中正在使用的队列进行操作。使用rabbitrnqctl list_queues {口arne) slave_pidssynchronised_slave_pids 命令可以查看哪些slaves 已经完成同步。通过手动方式同步一个队列的命令为rabbitrnqctl sync queue {narne) ,同样也可以取消某个队列的同步操作: rabbitrnqctl cancel sync queue {narne) 。
当所有slave 都出现未同步状态,并且ha-prornote- on -shutdown 设置为when-synced(默认)时,如果master 因为主动原因停掉,比如通过rabbitrnqctl stop 命令或者优雅关闭操作系统,那么slave 不会接管master,也就是此时镜像队列不可用:但是如果master 因为被动原因停掉,比如Erlang 虚拟机或者操作系统崩溃,那么slave 会接管master。这个配置项隐含的价值取向是保证消息可靠不丢失,同时放弃了可用性。如果ha-prornote-on-shutdown 设置为always ,那么不论master 因为何种原因停止, slave 都会接管master ,优先保证可用性,不过消息可能会丢失。
镜像队列中最后一个停止的节点会是master,启动顺序必须是master 先启动。如果slave先启动,它会有30 秒的等待时间,等待master 的启动,然后加入到集群中。如果30 秒内master没有启动, slave 会自动停止。当所有节点因故(断电等)同时离线时,每个节点都认为自己不是最后一个停止的节点,要恢复镜像队列,可以尝试在30 秒内启动所有节点。
RabbitMQ镜像队列实战
有三个rabbitMQ节点,当出现的一个的节点的宕机时候这个节点的消息不能被消费到,有可能丢失有可能存在磁盘中或者是在重启后消息出现丢失问题。但是对于正在线上运行的项目来说是不运行出现的这样的问题。因此需要保证在因为一个节点宕机后,节点队列的消息仍然可以被消费到。因此采用的镜像队列的原因来实现的节点队列消息的高可用性。
出现问题
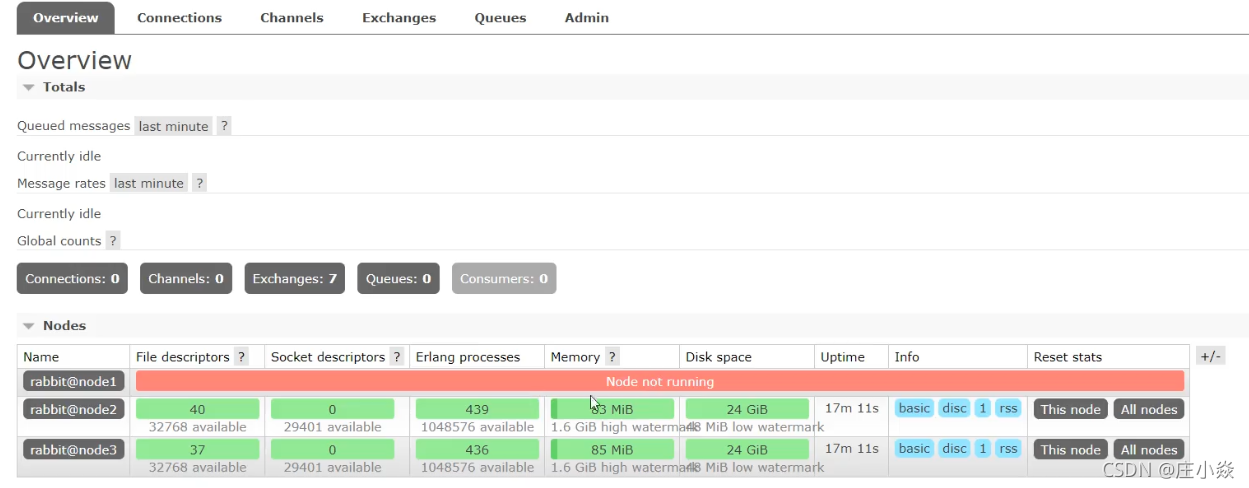
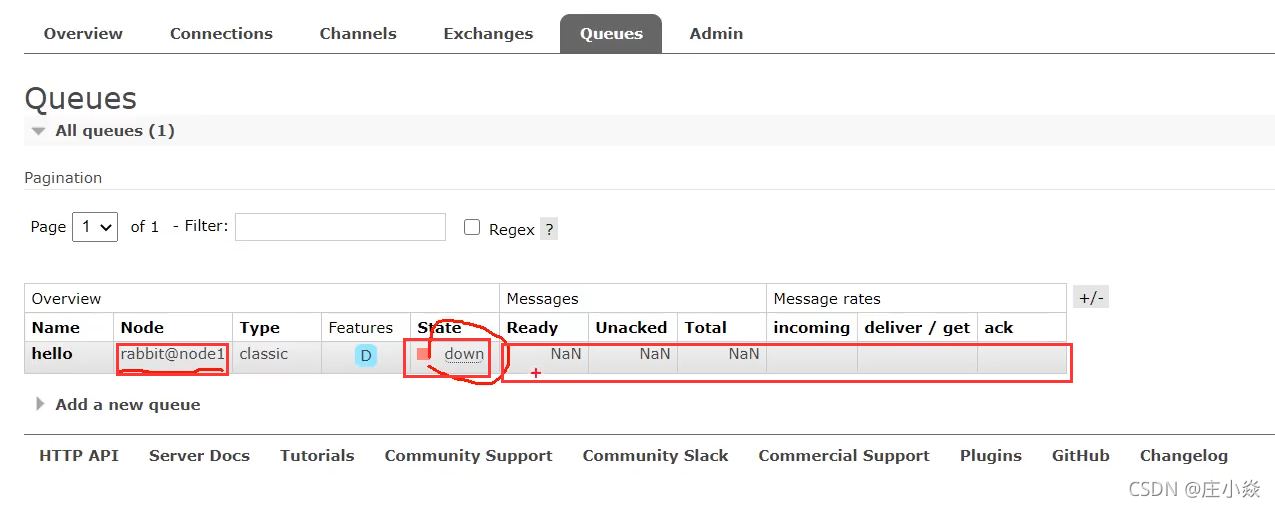
页面设置镜像队列
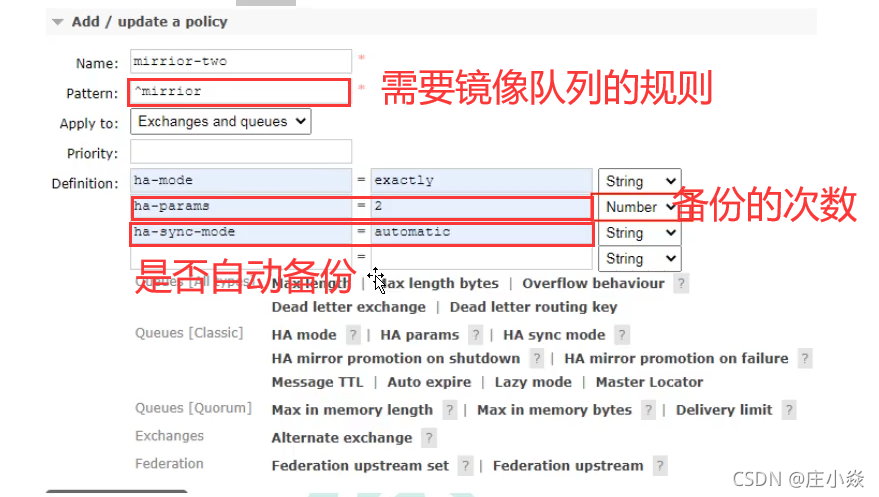
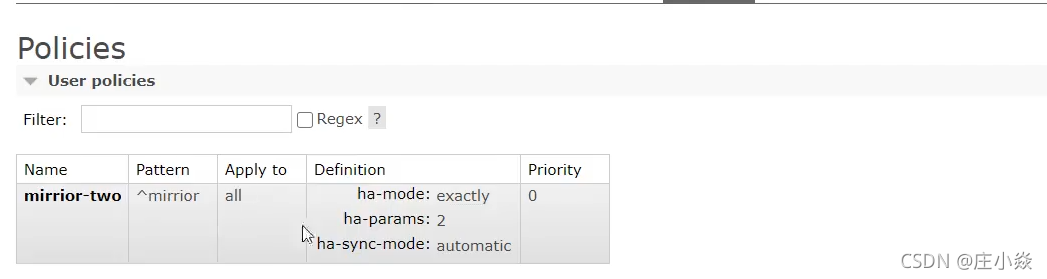
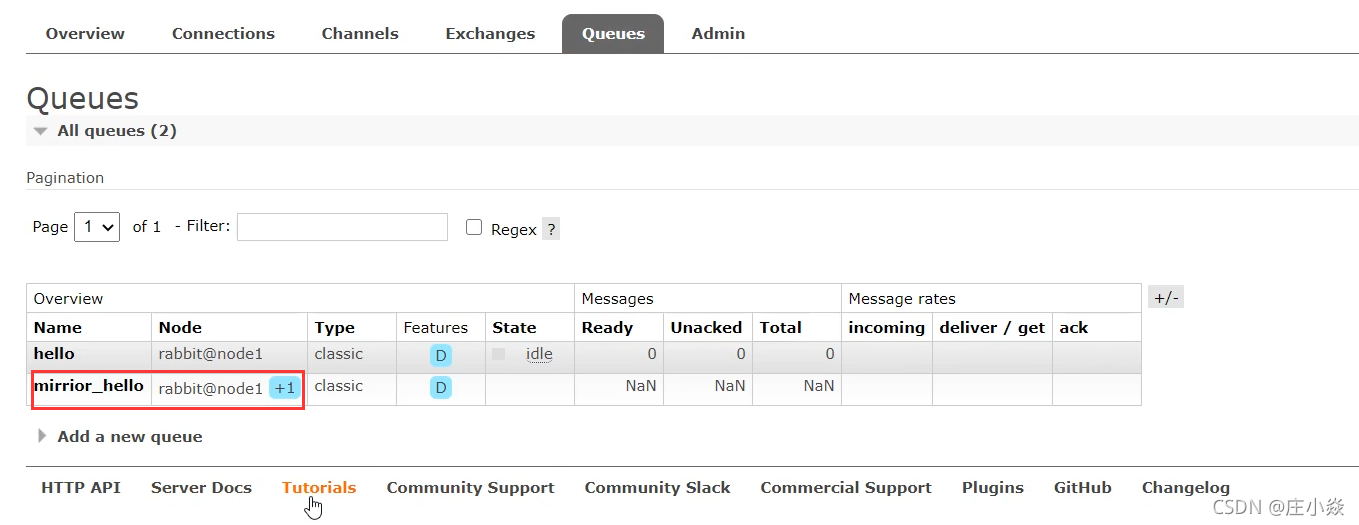
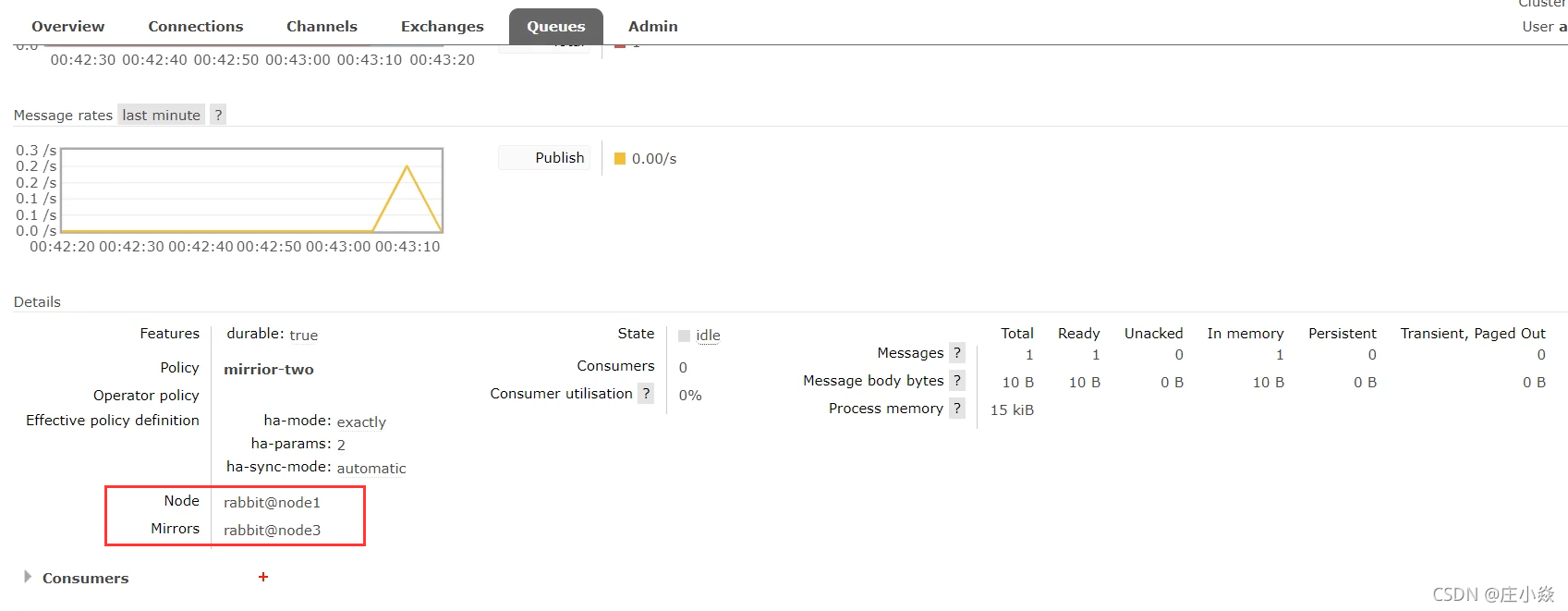
java代码设置镜像队列
镜像队列的问题
镜像队列中某个节点宕掉的后果:
当slave宕掉了,除了与slave相连的客户端连接全部断开之外,没有其他影响。
当master宕掉时,会有以下连锁反应:
- 与master相连的客户端连接全部断开;
- 选举最老的slave节点为master。若此时所有slave处于未同步状态,则未同步部分消息丢失;
- 新的master节点requeue所有unack消息,因为这个新节点无法区分这些unack消息是否已经到达客户端,亦或是ack消息丢失在老的master的链路上,亦或者是丢在master组播ack消息到所有slave的链路上。所以处于消息可靠性的考虑,requeue所有unack的消息。此时客户端可能有重复消息;
- 如果客户端连着slave,并且Basic.Consume消费时指定了x-cancel-on-ha-failover参数,那么客户端会受到一个Consumer Cancellation Notification通知。如果未指定x-cancal-on-ha-failover参数,那么消费者就无法感知master宕机,会一直等待下去。
这就告诉我们,集群中存在镜像队列时,重新master节点有风险。
镜像队列中节点启动顺序,非常有讲究:
假设集群中包含两个节点,一般生产环境会部署三个节点,但为了方便说明,采用两个节点的形式进行说明。
场景1:A先停,B后停
该场景下B是master,只要先启动B,再启动A即可。或者先启动A,再在30s之内启动B即可恢复镜像队列。(如果没有在30s内回复B,那么A自己就停掉自己)
场景2:A,B同时停
该场景下可能是由掉电等原因造成,只需在30s内联系启动A和B即可恢复镜像队列。
场景3:A先停,B后停,且A无法恢复。
因为B是master,所以等B起来后,在B节点上调用rabbitmqctl forget_cluster_node A以接触A的cluster关系,再将新的slave节点加入B即可重新恢复镜像队列。
场景4:A先停,B后停,且B无法恢复
该场景比较难处理,旧版本的RabbitMQ没有有效的解决办法,在现在的版本中,因为B是master,所以直接启动A是不行的,当A无法启动时,也就没版本在A节点上调用rabbitmqctl forget_cluster_node B了,新版本中forget_cluster_node支持-offline参数,offline参数允许rabbitmqctl在离线节点上执行forget_cluster_node命令,迫使RabbitMQ在未启动的slave节点中选择一个作为master。当在A节点执行rabbitmqctl forget_cluster_node -offline B时,RabbitMQ会mock一个节点代表A,执行forget_cluster_node命令将B提出cluster,然后A就能正常启动了。最后将新的slave节点加入A即可重新恢复镜像队列
场景5:A先停,B后停,且A和B均无法恢复,但是能得到A或B的磁盘文件
这个场景更加难以处理。将A或B的数据库文件($RabbitMQ_HOME/var/lib目录中)copy至新节点C的目录下,再将C的hostname改成A或者B的hostname。如果copy过来的是A节点磁盘文件,按场景4处理,如果拷贝过来的是B节点的磁盘文件,按场景3处理。最后将新的slave节点加入C即可重新恢复镜像队列。
场景6:A先停,B后停,且A和B均无法恢复,且无法得到A和B的磁盘文件
无解。
启动顺序中有一个30s 的概念,这个是MQ 的时间间隔,用于检测master、slave是否可用,因此30s 非常关键。
对于生产环境MQ集群的重启操作,需要分析具体的操作顺序,不可无序的重启,会有可能带来无法弥补的伤害(数据丢失、节点无法启动)。
简单总结下:镜像队列是用于节点之间同步消息的机制,避免某个节点宕机而导致的服务不可用或消息丢失,且针对排他性队列设置是无效的。另外很重要的一点,镜像队列机制不是负载均衡。
博文参考
RabbitMQ镜像队列集群搭建、与SpringBoot整合 - Tom-shushu
带你从头进行RabbitMQ安装、集群搭建、镜像队列配置和代码验证【附源码】_Java知音_51CTO博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |