

大数据技术12:Hive简介及核心概念
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言2007年编写Pig虽然比MapReduce编程简单但是还是要学习。于是Facebook发布了Hive支持使用SQL语法进行大数据计算写个Select语句进行数据查询Hive会将SQL语句转化成MapReduce计算程序。这样熟悉数据库的数据分析师和工程师便可以无门槛地使用大数据进行数据分析和处理了Hive出现后大大降低了Hadoop的使用难度迅速得到开发者和企业的追捧。
一、Hive简介
Hive 是一个构建在 Hadoop 之上的数据仓库它可以将结构化的数据文件映射成表并提供类 SQL 查 询功能用于查询的 SQL 语句会被转化为 MapReduce 作业然后提交到 Hadoop 上运行。
Hive是基于Hadoop的一个数据仓库工具用来进行数据提取、转化、加载这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表并提供SQL查询功能能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低可以通过类似SQL语句实现快速MapReduce统计使MapReduce变得更加简单而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
Hive特点
-
简单、容易上手 (提供了类似 sql 的查询语言 hql)使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析
-
灵活性高可以自定义用户函数 (UDF) 和存储格式
-
为超大的数据集设计的计算和存储能力集群扩展容易;
-
统一的元数据管理可与 prestoimpalasparksql 等共享数据
-
执行延迟高不适合做数据的实时处理但适合做海量数据的离线处理。
二、Hive的体系架构
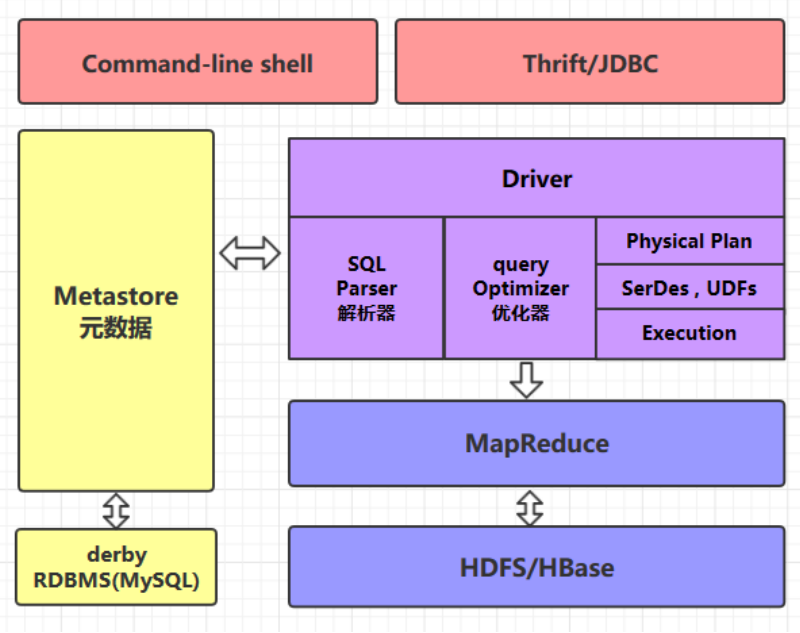
2.1 command-line shell & thrift/jdbc
可以用 command-line shell 和 thriftjdbc 两种方式来操作数据
command-line shell通过 hive 命令行的的方式来操作数据
thriftjdbc通过 thrift 协议按照标准的 JDBC 的方式操作数据。
2.2 Metastore
在 Hive 中表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认 存储在 Hive 内置的 derby 数据库中但由于 derby 只能有一个实例也就是说不能有多个命令行客户 端同时访问所以在实际生产环境中通常使用 MySQL 代替 derby。
Hive 进行的是统一的元数据管理就是说你在 Hive 上创建了一张表然后在 prestoimpala
sparksql 中都是可以直接使用的它们会从 Metastore 中获取统一的元数据信息同样的你在 presto impalasparksql 中创建一张表在 Hive 中也可以直接使用。
2.3 HQL的执行流程
Hive 在执行一条 HQL 的时候会经过以下步骤
1. 语法解析Antlr 定义 SQL 的语法规则完成 SQL 词法语法解析将 SQL 转化为抽象 语法树
AST Tree
2. 语义解析遍历 AST Tree抽象出查询的基本组成单元 QueryBlock
3. 生成逻辑执行计划遍历 QueryBlock翻译为执行操作树 OperatorTree
4. 优化逻辑执行计划逻辑层优化器进行 OperatorTree 变换合并不必要的
ReduceSinkOperator减少 shuffle 数据量
5. 生成物理执行计划遍历 OperatorTree翻译为 MapReduce 任务
6. 优化物理执行计划物理层优化器进行 MapReduce 任务的变换生成最终的执行计划。
三、Hive数据类型
3.1 基本数据类型
Hive 表中的列支持以下基本数据类型
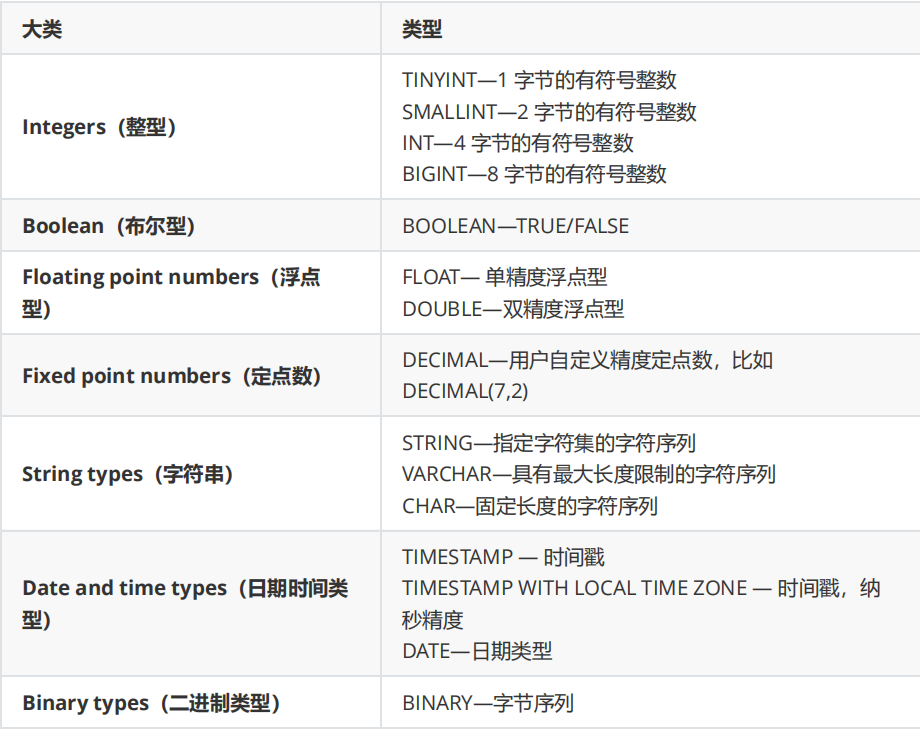
TIMESTAMP 和 TIMESTAMP WITH LOCAL TIME ZONE 的区别如下
-
TIMESTAMP WITH LOCAL TIME ZONE用户提交时间给数据库时会被转换成数据库所
-
在的时区来保存。查询时则按照查询客户端的不同转换为查询客户端所在时区的时间。
-
TIMESTAMP 提交什么时间就保存什么时间查询时也不做任何转换。
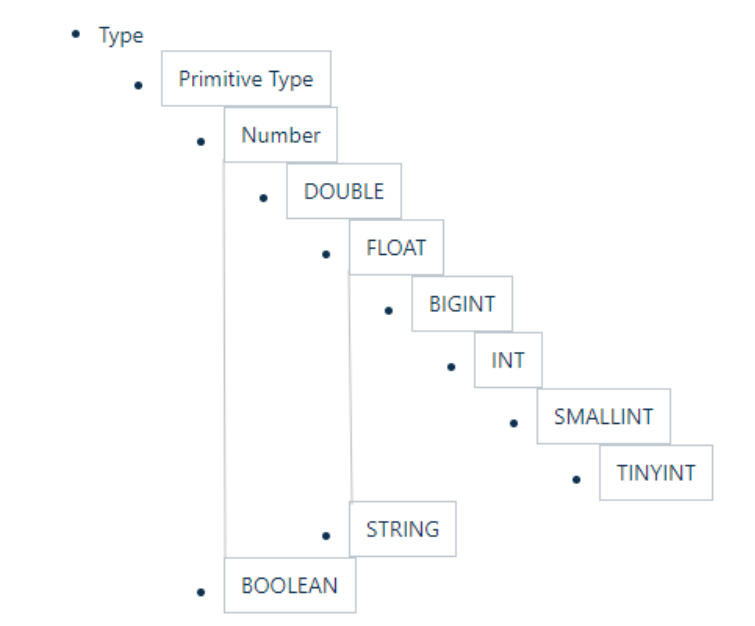
3.2 隐式转换
Hive 中基本数据类型遵循以下的层次结构按照这个层次结构子类型到祖先类型允许隐式转换。例 如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是按照类型层次结构允许将 STRING 类 型隐式转换为 DOUBLE 类型。
3.3 复杂类型

3.4 示例
如下给出一个基本数据类型和复杂数据类型的使用示例
CREATE TABLE students(
name STRING, -- 姓名
age INT, -- 年龄
subject ARRAY<STRING>, --学科
score MAP<STRING,FLOAT>, --各个学科考试成绩
address STRUCT<houseNumber:int, street:STRING, city:STRING, province
STRING> --家庭居住地址
) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";四、Hive内容格式
当数据存储在文本文件中必须按照一定格式区别行和列如使用逗号作为分隔符的 CSV 文件
(Comma-Separated Values) 或者使用制表符作为分隔值的 TSV 文件 (Tab-Separated Values)。但此时 也存在一个缺点就是正常的文件内容中也可能出现逗号或者制表符。
所以 Hive 默认使用了几个平时很少出现的字符这些字符一般不会作为内容出现在文件中。Hive默认 的行和列分隔符如下表所示。

CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;五、Hive存储格式
5.1 支持的存储格式
Hive 会在 HDFS 为每个数据库上创建一个目录数据库中的表是该目录的子目录表中的数据会以文 件的形式存储在对应的表目录下。Hive 支持以下几种文件存储格式

5.2 指定存储格式
通常在创建表的时候使用 STORED AS 参数指定
各个存储文件类型指定方式如下
-
STORED AS TEXTFILE
-
STORED AS SEQUENCEFILE
-
STORED AS ORC
-
STORED AS PARQUET
-
STORED AS AVRO
-
STORED AS RCFILE
六、内部表和外部表
内部表又叫做管理表 (Managed/Internal Table)创建表时不做任何指定默认创建的就是内部表。想 要创建外部表 (External Table)则需要使用 External 进行修饰。 内部表和外部表主要区别如下

六、Linux环境下Hive的安装
6.1、安装Hive
1下载并解压
下载所需版本的 Hive这里我下载版本为 cdh5.15.2 。下载地址http://archive.cloudera.com/cdh
5/cdh/5/
# 下载后进行解压
tar -zxvf hive-1.1.0-cdh5.15.2.tar.gz2配置环境变量
添加环境变量
vim /etc/profile
export HIVE_HOME=/usr/app/hive-1.1.0-cdh5.15.2
export PATH=$HIVE_HOME/bin:$PATH使得配置的环境变量立即生效
source /etc/profile3修改配置
1. hive-env.sh
进入安装目录下的 conf/ 目录拷贝 Hive 的环境配置模板 flume-env.sh.template
cp hive-env.sh.template hive-env.sh修改 hive-env.sh 指定 Hadoop 的安装路径
HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.22. hive-site.xml
新建 hive-site.xml 文件内容如下主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop001:3306/hadoop_hive?
createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>4拷贝数据库驱动
将 MySQL 驱动包拷贝到 Hive 安装目录的 lib 目录下, MySQL 驱动的下载地址为https://dev.mysql. com/downloads/connector/j/

5初始化元数据库
-
当使用的 hive 是 1.x 版本时可以不进行初始化操作Hive 会在第一次启动的时候会自动进行初始化但不会生成所有的元数据信息表只会初始化必要的一部分在之后的使用中用到其余表时会自动创建
-
当使用的 hive 是 2.x 版本时必须手动初始化元数据库。初始化命令
# schematool 命令在安装目录的 bin 目录下由于上面已经配置过环境变量在任意位置执行即可
schematool -dbType mysql -initSchema这里我使用的是 CDH 的 hive-1.1.0-cdh5.15.2.tar.gz 对应 Hive 1.1.0 版本可以跳过这一
步。
6 启动
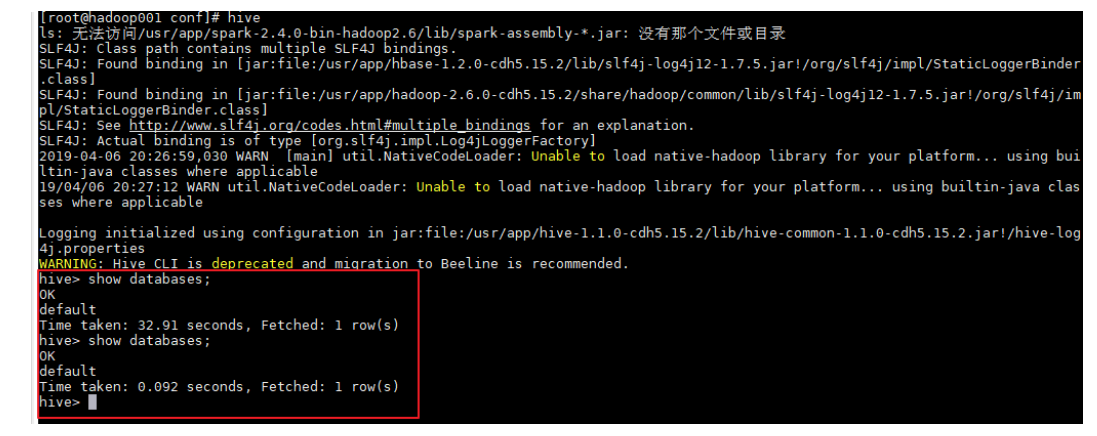
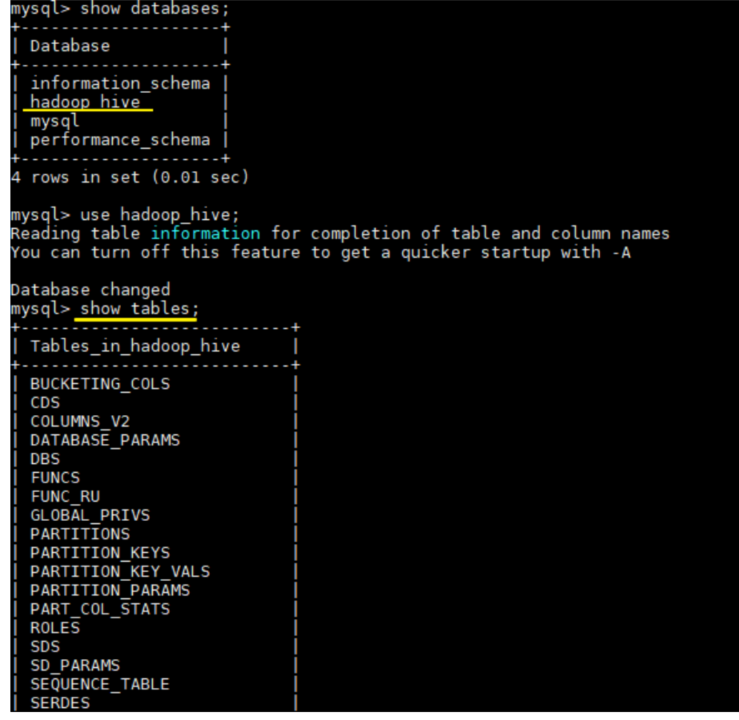
由于已经将 Hive 的 bin 目录配置到环境变量直接使用以下命令启动成功进入交互式命令行后执行 show databases 命令无异常则代表搭建成功。
6.2、HiveServer2/beeline
Hive 内置了 HiveServer 和 HiveServer2 服务两者都允许客户端使用多种编程语言进行连接但是 HiveServer 不能处理多个客户端的并发请求因此产生了 HiveServer2。HiveServer2HS2允许远 程客户端可以使用各种编程语言向 Hive 提交请求并检索结果支持多客户端并发访问和身份验证。 HS2 是由多个服务组成的单个进程其包括基于 Thrift 的 Hive 服务TCP 或 HTTP和用于 Web UI 的 Jetty Web 服务。
HiveServer2 拥有自己的 CLI 工具——Beeline。Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于 目前 HiveServer2 是 Hive 开发维护的重点所以官方更加推荐使用 Beeline 而不是 Hive CLI。以下主 要讲解 Beeline 的配置方式。
6.2.1 修改Hadoop配置
修改 hadoop 集群的 core-site.xml 配置文件增加如下配置指定 hadoop 的 root 用户可以代理本机 上所有的用户。
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>之所以要配置这一步是因为 hadoop 2.0 以后引入了安全伪装机制使得 hadoop 不允许上层系统 如 hive直接将实际用户传递到 hadoop 层而应该将实际用户传递给一个超级代理由该代理在 hadoop 上执行操作以避免任意客户端随意操作 hadoop。如果不配置这一步在之后的连接中可能 会抛出 AuthorizationException 异常。
6.2.2 启动hiveserver2
由于上面已经配置过环境变量这里直接启动即可
# nohup hiveserver2 &6.2.3 使用beeline
可以使用以下命令进入 beeline 交互式命令行出现 Connected 则代表连接成功。
# beeline -u jdbc:hive2://hadoop001:10000 -n root