分布式日志和链路追踪-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
分布式日志
实现思路
分布式日志框架服务的实现思路基本是一致的如下
- 日志收集器微服务中引入日志客户端将记录的日志发送到日志服务端的收集器然后以某种方式存储
- 数据存储一般使用ElasticSearch分布式存储把收集器收集到的日志格式化然后存储到分布式存储中
- web服务利用ElasticSearch的统计搜索功能实现日志查询和报表输出
比较知名的分布式日志服务包括
- ELKelasticsearch、Logstash、Kibana
- GrayLog
ELK存在的问题
- 不能处理多行日志比如Mysql慢查询Tomcat/Jetty应用的Java异常打印
- 不能保留原始日志只能把原始日志分字段保存这样搜索日志结果是一堆Json格式文本无法阅读。
- 不符合正则表达式匹配的日志行被全部丢弃。
Graylog的优点
- 一体化方案安装方便不像ELK有3个独立系统间的集成问题。
- 采集原始日志并可以事后再添加字段比如http_status_coderesponse_time等等。
- 自己开发采集日志的脚本并用curl/nc发送到Graylog Server发送格式是自定义的GELFFlunted和Logstash都有相应的输出GELF消息的插件。自己开发带来很大的自由度。实际上只需要用inotifywait监控日志的modify事件并把日志的新增行用curl/netcat发送到Graylog Server就可。
- 搜索结果高亮显示就像google一样。
- 搜索语法简单比如
source:mongo AND reponse_time_ms:>5000避免直接输入elasticsearch搜索json语法 - 搜索条件可以导出为elasticsearch的搜索json文本方便直接开发调用elasticsearch rest api的搜索脚本。
GrayLog的使用
GrayLog的流程框架图

流程如下
- 微服务中的GrayLog客户端发送日志到GrayLog服务端
- GrayLog把日志信息格式化存储到Elasticsearch
- 客户端通过浏览器访问GrayLogGrayLog访问Elasticsearch
这里MongoDB是用来存储GrayLog的配置信息的这样搭建集群时GrayLog的各节点可以共享配置。
GrayLog的安装
此时我们需要在docker中安装Mongodb, elasticSearchGrayLog。
#部署Elasticsearch
docker run -d \
--name elasticsearch \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.17.5
#部署MongoDB
docker run -d \
--name mongodb \
-p 27017:27017 \
--restart=always \
-v mongodb:/data/db \
-e MONGO_INITDB_ROOT_USERNAME=sl \
-e MONGO_INITDB_ROOT_PASSWORD=123321 \
mongo:4.4
#部署 分别设置es和mongo的地址
docker run \
--name graylog \
-p 9000:9000 \
-p 12201:12201/udp \
-e GRAYLOG_HTTP_EXTERNAL_URI=http://192.168.150.101:9000/ \
-e GRAYLOG_ELASTICSEARCH_HOSTS=http://192.168.150.101:9200/ \
-e GRAYLOG_ROOT_TIMEZONE="Asia/Shanghai" \
-e GRAYLOG_WEB_ENDPOINT_URI="http://192.168.150.101:9000/:9000/api" \
-e GRAYLOG_PASSWORD_SECRET="somepasswordpepper" \
-e GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 \
-e GRAYLOG_MONGODB_URI=mongodb://sl:123321@192.168.150.101:27017/admin \
-d \
graylog/graylog:4.3命令解读
- 端口信息
-
-p 9000:9000GrayLog的http服务端口9000-p 12201:12201/udpGrayLog的GELF UDP协议端口用于接收从微服务发来的日志信息
- 环境变量
-
-e GRAYLOG_HTTP_EXTERNAL_URI对外开放的ip和端口信息这里用9000端口-e GRAYLOG_ELASTICSEARCH_HOSTSGrayLog依赖于ES这里指定ES的地址-e GRAYLOG_WEB_ENDPOINT_URI对外开放的API地址-e GRAYLOG_PASSWORD_SECRET密码加密的秘钥-e GRAYLOG_ROOT_PASSWORD_SHA2密码加密后的密文。明文是admin账户也是admin-e GRAYLOG_ROOT_TIMEZONE="Asia/Shanghai"GrayLog容器内时区-e GRAYLOG_MONGODB_URI指定MongoDB的链接信息
graylog/graylog:4.3使用的镜像名称版本为4.3
进行测试
访问对应的9000端口。
 集成微服务进行测试
集成微服务进行测试
导入依赖
<dependency>
<groupId>biz.paluch.logging</groupId>
<artifactId>logstash-gelf</artifactId>
<version>1.15.0</version>
</dependency>修改Logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--scan: 当此属性设置为true时配置文件如果发生改变将会被重新加载默认值为true。-->
<!--scanPeriod: 设置监测配置文件是否有修改的时间间隔如果没有给出时间单位默认单位是毫秒。当scan为true时此属性生效。默认的时间间隔为1分钟。-->
<!--debug: 当此属性设置为true时将打印出logback内部日志信息实时查看logback运行状态。默认值为false。-->
<configuration debug="false" scan="false" scanPeriod="60 seconds">
<springProperty scope="context" name="appName" source="spring.application.name"/>
<!--文件名-->
<property name="logback.appname" value="${appName}"/>
<!--文件位置-->
<property name="logback.logdir" value="/data/logs"/>
<!-- 定义控制台输出 -->
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} - [%thread] - %-5level - %logger{50} - %msg%n</pattern>
</layout>
</appender>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<File>${logback.logdir}/${logback.appname}/${logback.appname}.log</File>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<FileNamePattern>${logback.logdir}/${logback.appname}/${logback.appname}.%d{yyyy-MM-dd}.log.zip</FileNamePattern>
<maxHistory>90</maxHistory>
</rollingPolicy>
<encoder>
<charset>UTF-8</charset>
<pattern>%d [%thread] %-5level %logger{36} %line - %msg%n</pattern>
</encoder>
</appender>
<appender name="GELF" class="biz.paluch.logging.gelf.logback.GelfLogbackAppender">
<!--GrayLog服务地址-->
<host>udp:192.168.150.101</host>
<!--GrayLog服务端口-->
<port>12201</port>
<version>1.1</version>
<!--当前服务名称-->
<facility>${appName}</facility>
<extractStackTrace>true</extractStackTrace>
<filterStackTrace>true</filterStackTrace>
<mdcProfiling>true</mdcProfiling>
<timestampPattern>yyyy-MM-dd HH:mm:ss,SSS</timestampPattern>
<maximumMessageSize>8192</maximumMessageSize>
</appender>
<!--evel:用来设置打印级别大小写无关TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF-->
<!--不能设置为INHERITED或者同义词NULL。默认是DEBUG。-->
<root level="INFO">
<appender-ref ref="stdout"/>
<appender-ref ref="GELF"/>
</root>
</configuration>这样就实现了微服务的分布式日志。
调用work服务的查询方法日志就会出现在控制面板上。
日志回收策略
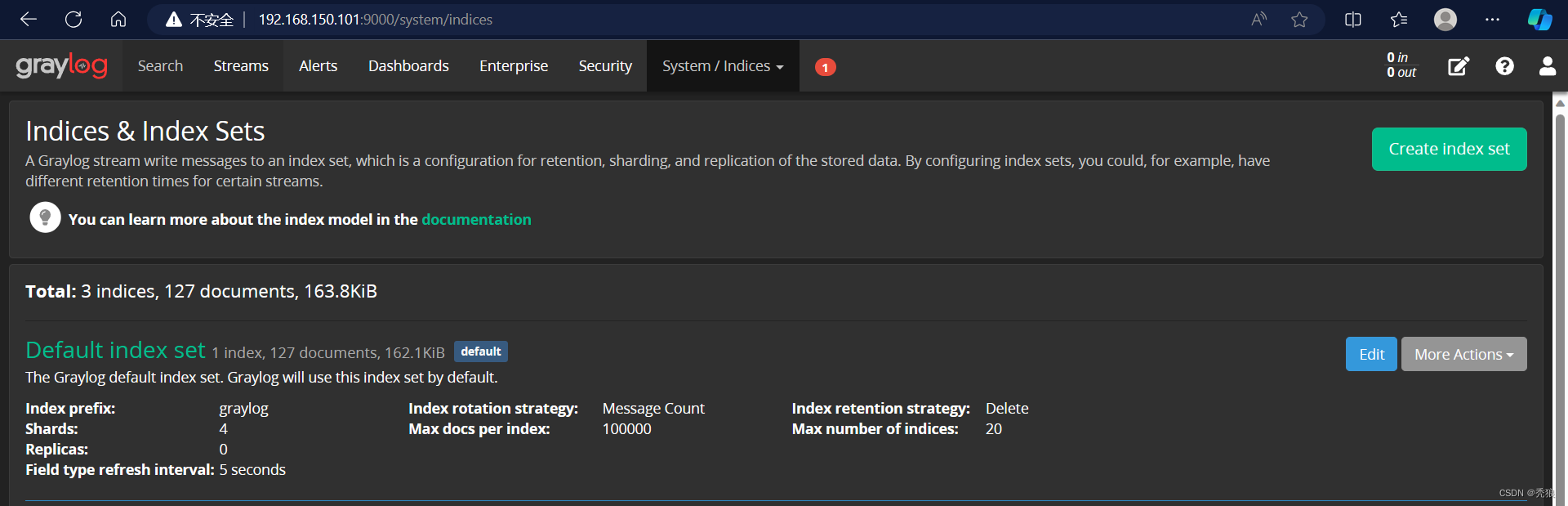 点击Default index set的Edit进行设置日志的回收策略。
点击Default index set的Edit进行设置日志的回收策略。
日志的回策略有三种。
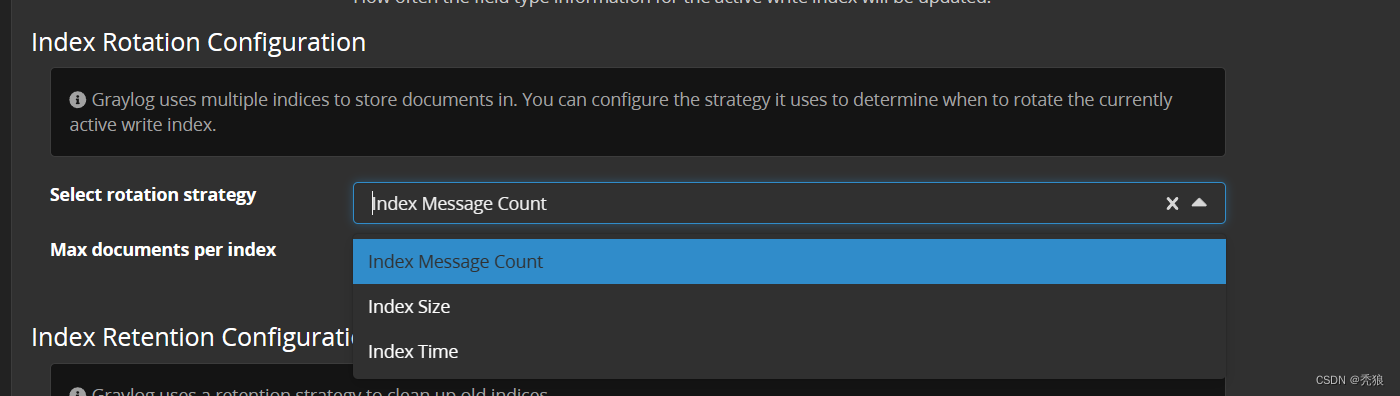
分别是
Index Message Count按照日志数量统计默认超过20000000条日志开始清理Index Size按照日志大小统计默认超过1GB开始清理Index Time按照日志日期清理默认日志存储1天
搜索语法
搜索语法的格式
#不指定字段默认从message字段查询
输入undo
#输入两个关键字关系为or
undo 统计
#加引号是需要完整匹配
"undo 统计"
#指定字段查询level表示日志级别ERROR3、WARNING4、NOTICE5、INFO6、DEBUG7
level: 6
#或条件
level:(6 OR 7)自定义展示字段
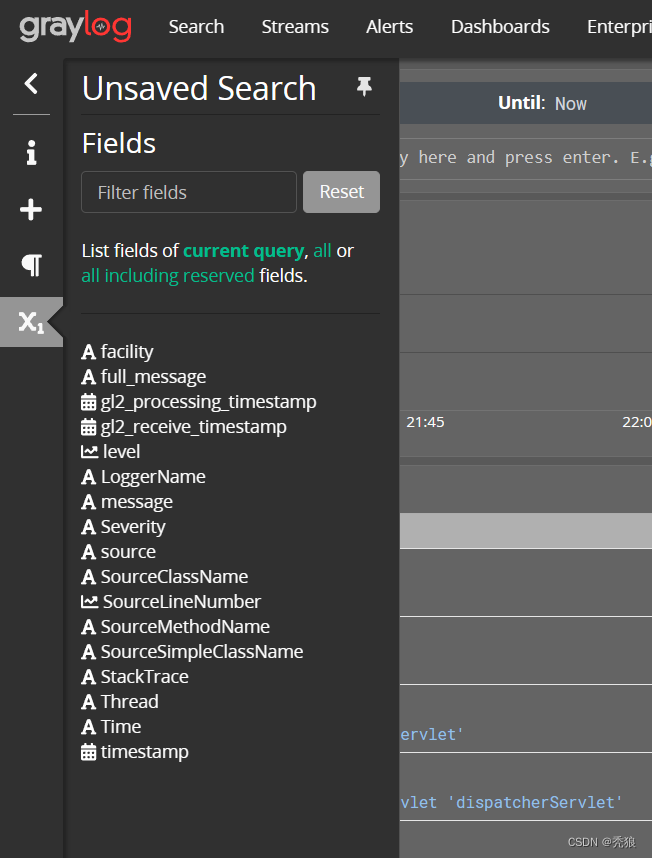
可以在allMessage中显示字段。
 这里添加了level字段。
这里添加了level字段。
日志统计仪表
创建仪表
点击Create new dashboard创建一个新的仪表。
 在该仪表中我们可以进行DIY。
在该仪表中我们可以进行DIY。
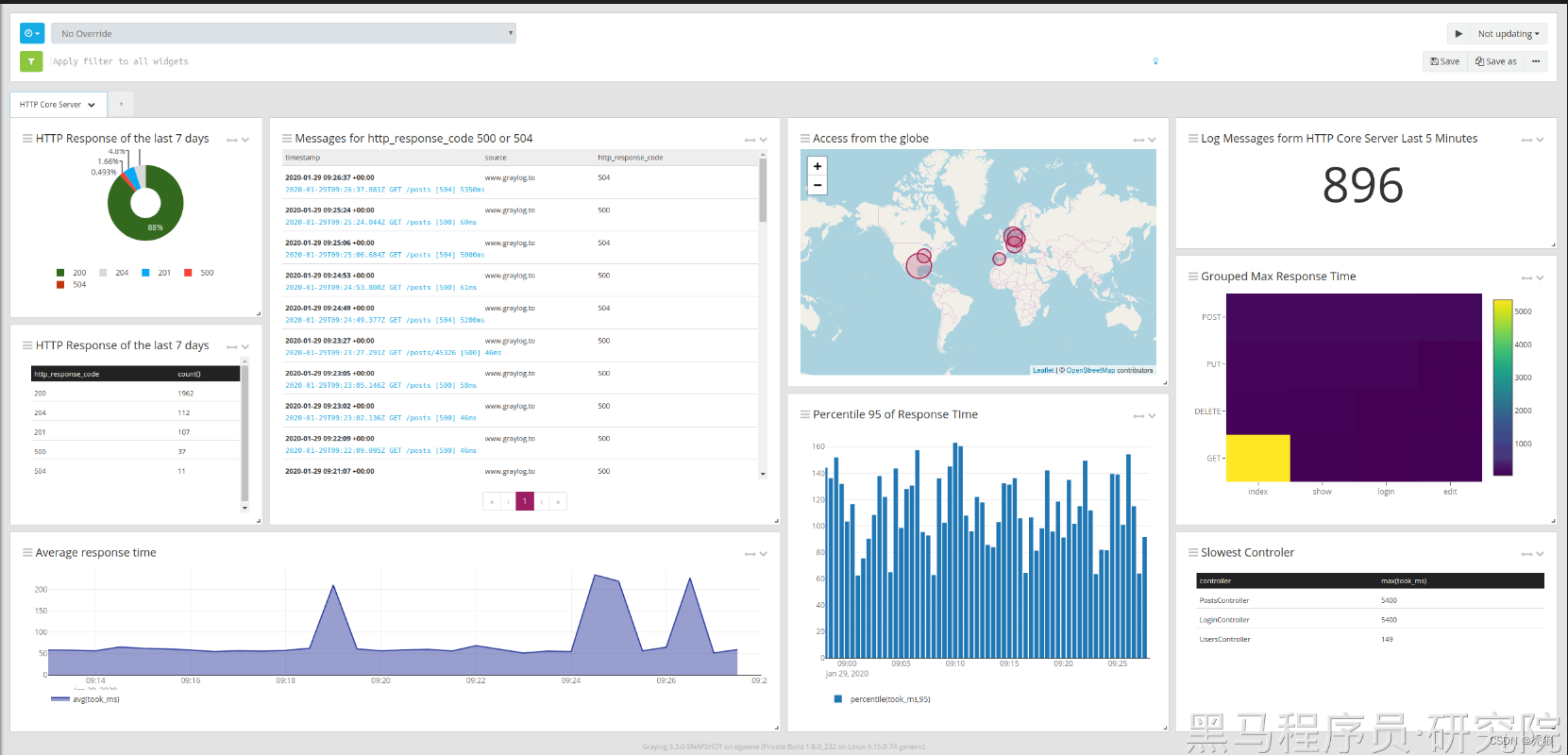
可以DIY成这种效果。
分布式日志面试题
问: 在服务中你们通常会进入哪些信息呢?
答: 会记录: 服务的名称日志的级别日志的详细信息时间对应的类调用的方法。
问: 那会在什么时候进行记录日志?
答: 在有异常信息和调用重要方法时的参数传入时会记录日志。
链路追踪
APM
什么是APM?
随着微服务架构的流行一次请求往往需要涉及到多个服务因此服务性能监控和排查就变得更复杂
- 不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现
- 服务有可能布在了几千台服务器横跨多个不同的数据中心
因此就需要一些可以帮助理解系统行为、用于分析性能问题的工具以便发生故障的时候能够快速定位和解决问题这就是APM系统全称是Application Performance Monitor当然也有叫 Application Performance Management tools
APM最早是谷歌公开的论文提到的 Google Dapper。Dapper是Google生产环境下的分布式跟踪系统自从Dapper发展成为一流的监控系统之后给google的开发者和运维团队帮了大忙所以谷歌公开论文分享了Dapper。
原理
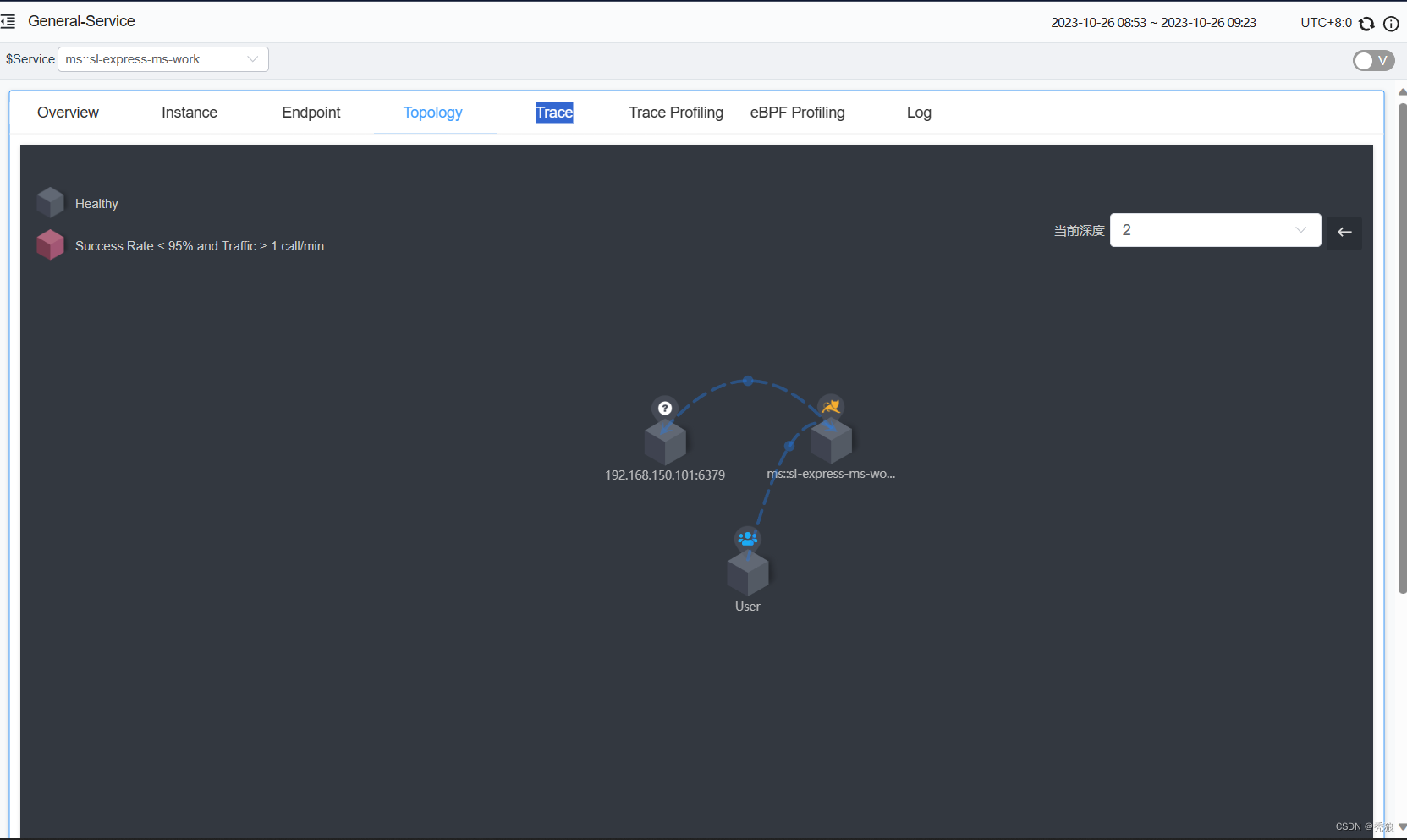
- 包括前端A两个中间层B和C以及两个后端D和E
- 当用户发起一个请求时首先到达前端A服务然后分别对B服务和C服务进行RPC调用
- B服务处理完给A做出响应但是C服务还需要和后端的D服务和E服务交互之后再返还给A服务最后由A服务来响应用户的请求
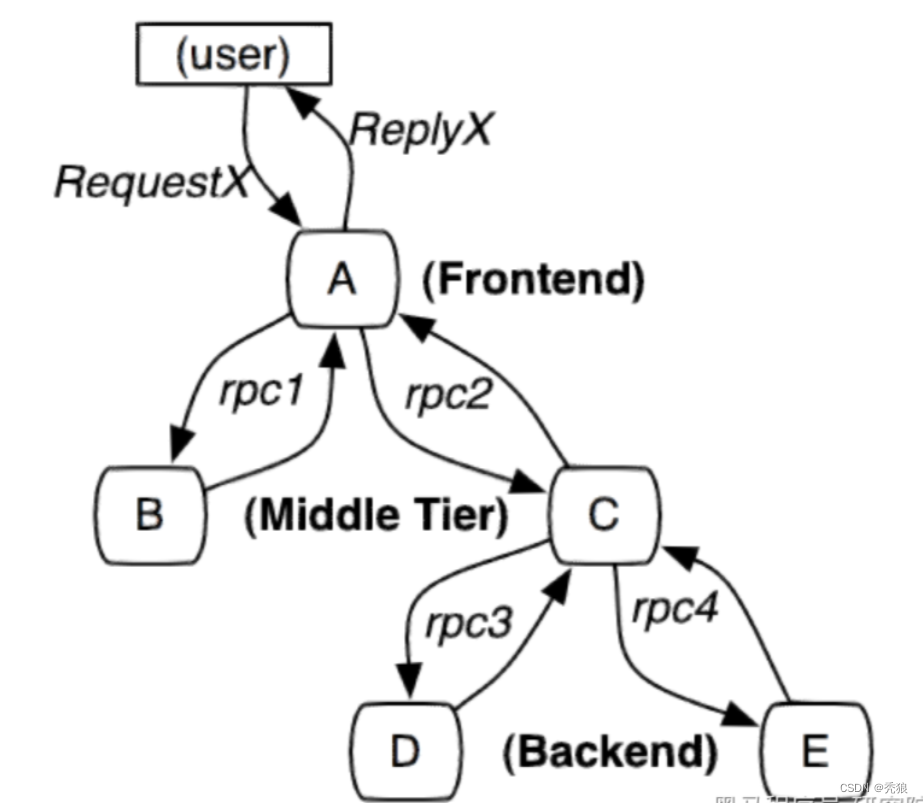
如何才能实现跟踪呢需要明白下面几个概念
- 探针负责在客户端程序运行时收集服务调用链路信息发送给收集器
- 收集器负责将数据格式化保存到存储器
- 存储器保存数据
- UI界面统计并展示
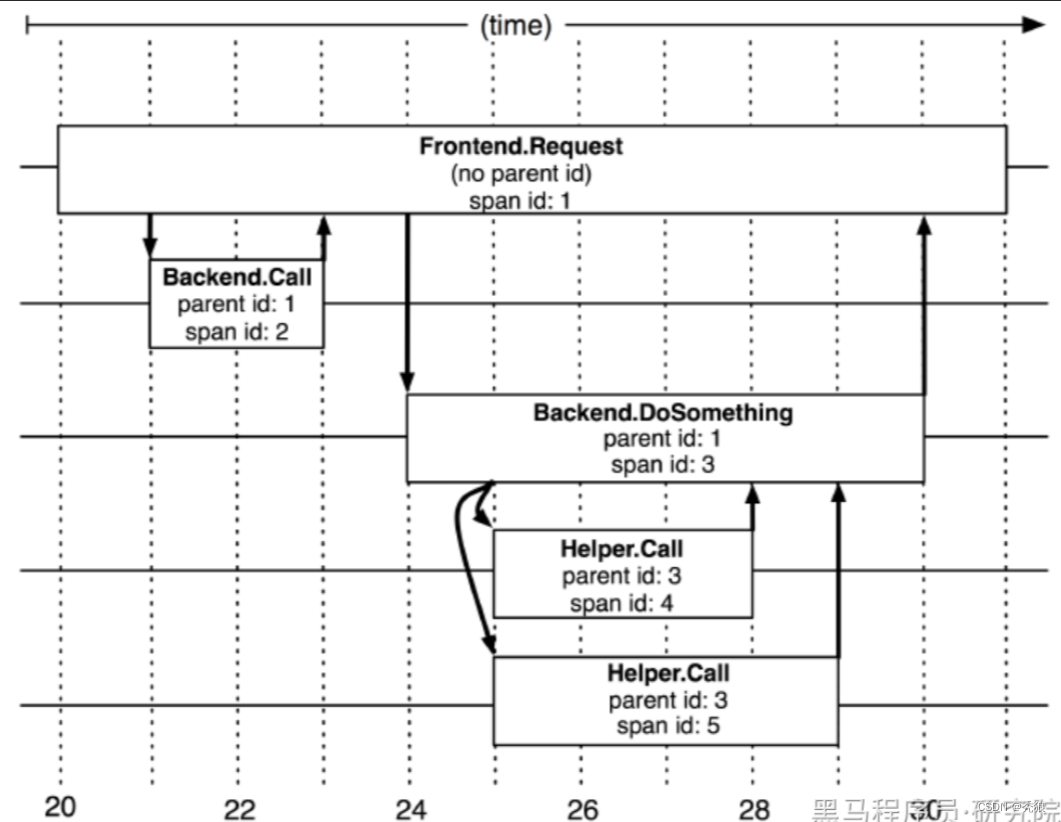
探针会在链路追踪时记录每次调用的信息Span是基本单元一次链路调用可以是RPCDB等没有特定的限制创建一个span通过一个64位ID标识它同时附加Annotation作为payload负载信息用于记录性能等数据。
span的基本结构
type Span struct {
TraceID int64 // 用于标示一次完整的请求id
Name string //名称
ID int64 // 当前这次调用span_id
ParentID int64 // 上层服务的调用span_id 最上层服务parent_id为null代表根服务root
Annotation []Annotation // 记录性能等数据
Debug bool
}
Skywalking的使用
主要的特征
- 多语言探针或类库
-
- Java自动探针追踪和监控程序时不需要修改源码。
- 社区提供的其他多语言探针
- 多种后端存储 ElasticSearch H2
- 支持OpenTracing
-
- Java自动探针支持和OpenTracing API协同工作
- 轻量级、完善功能的后端聚合和分析
- 现代化Web UI
- 日志集成
- 应用、实例和服务的告警
部署安装
#在此之前需要部署es
#oap服务需要指定Elasticsearch以及链接信息
docker run -d \
-e TZ=Asia/Shanghai \
--name oap \
-p 12800:12800 \
-p 11800:11800 \
-e SW_STORAGE=elasticsearch \
-e SW_STORAGE_ES_CLUSTER_NODES=192.168.150.101:9200 \
apache/skywalking-oap-server:9.1.0
#部署ui需要指定oap服务
docker run -d \
--name oap-ui \
-p 48080:8080 \
-e TZ=Asia/Shanghai \
-e SW_OAP_ADDRESS=http://192.168.150.101:12800 \
apache/skywalking-ui:9.1.0访问对应的端口48080。
微服务探针
我们需要在对应的微服务中添加探针。
需要准备Keywalking-gent文件在资源中获取
打开Idea在对应的微服务上添加VM的配置
#在探针处添加skywalking-agent.jar在电脑的对应位置
#设置服务的名称
#设置skywalking的面板地址
-javaagent:D:\skywalking-agent\skywalking-agent.jar
-Dskywalking.agent.service_name=ms::sl-express-ms-work
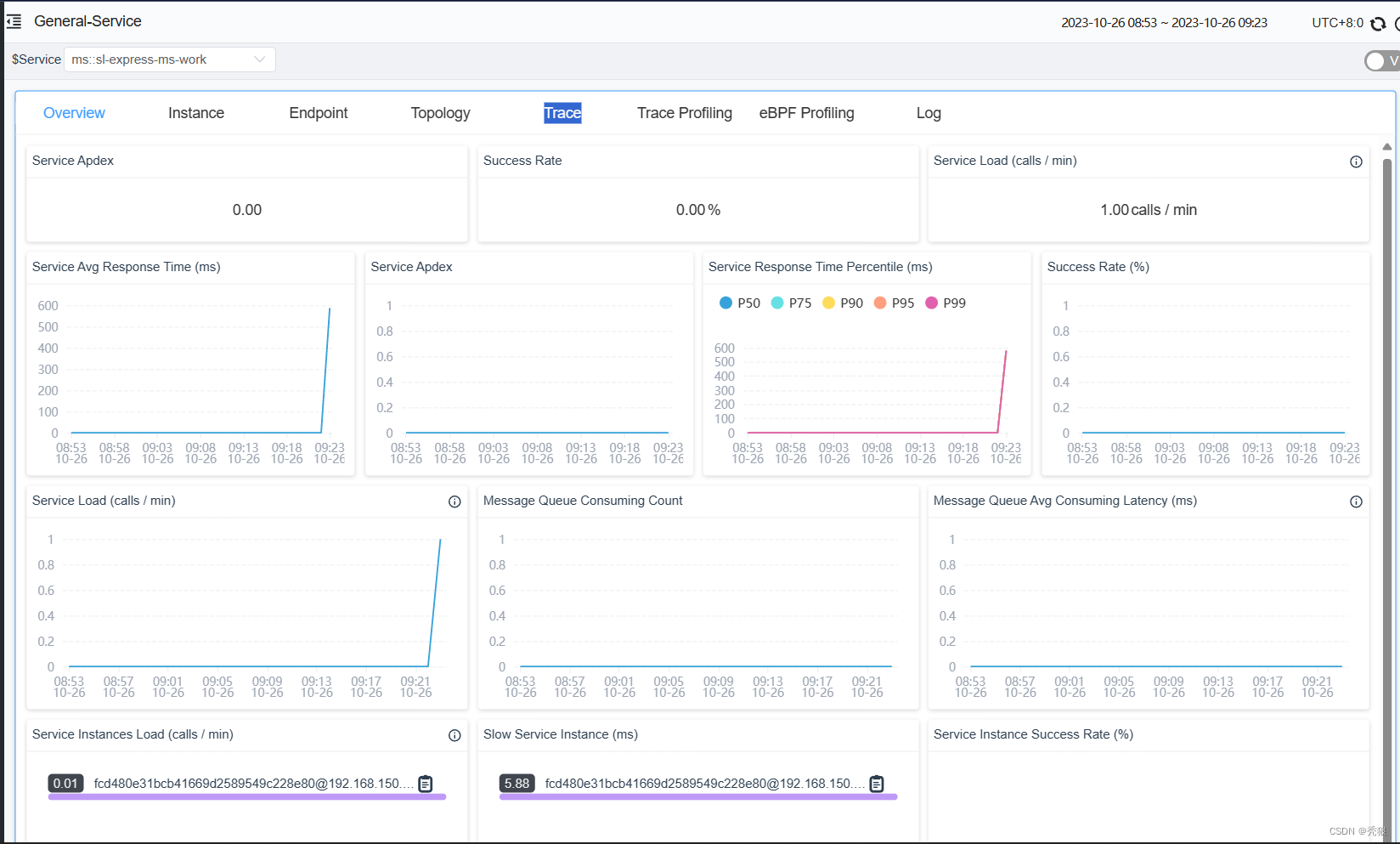
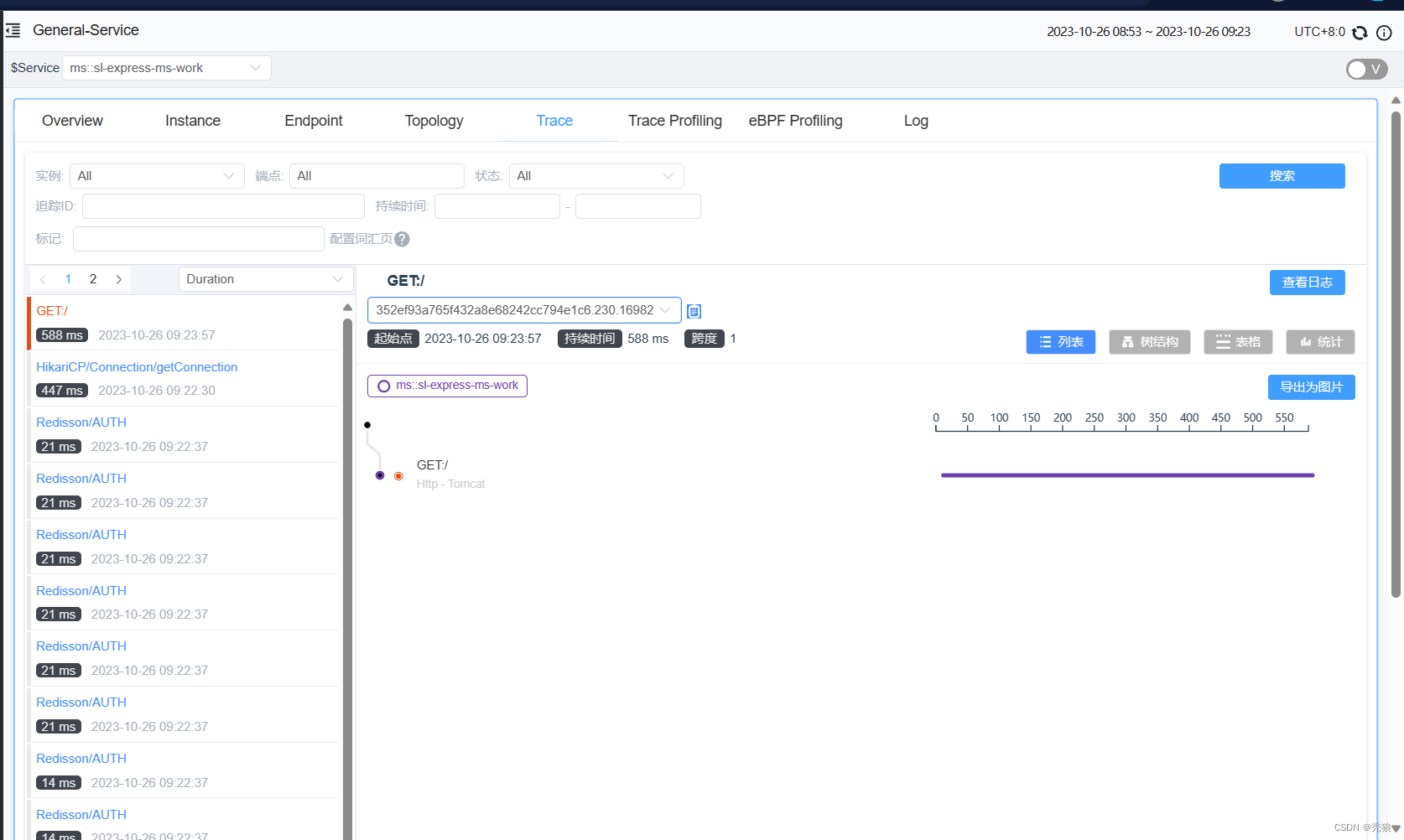
-Dskywalking.collector.backend_service=192.168.150.101:11800进行配置效果为下:
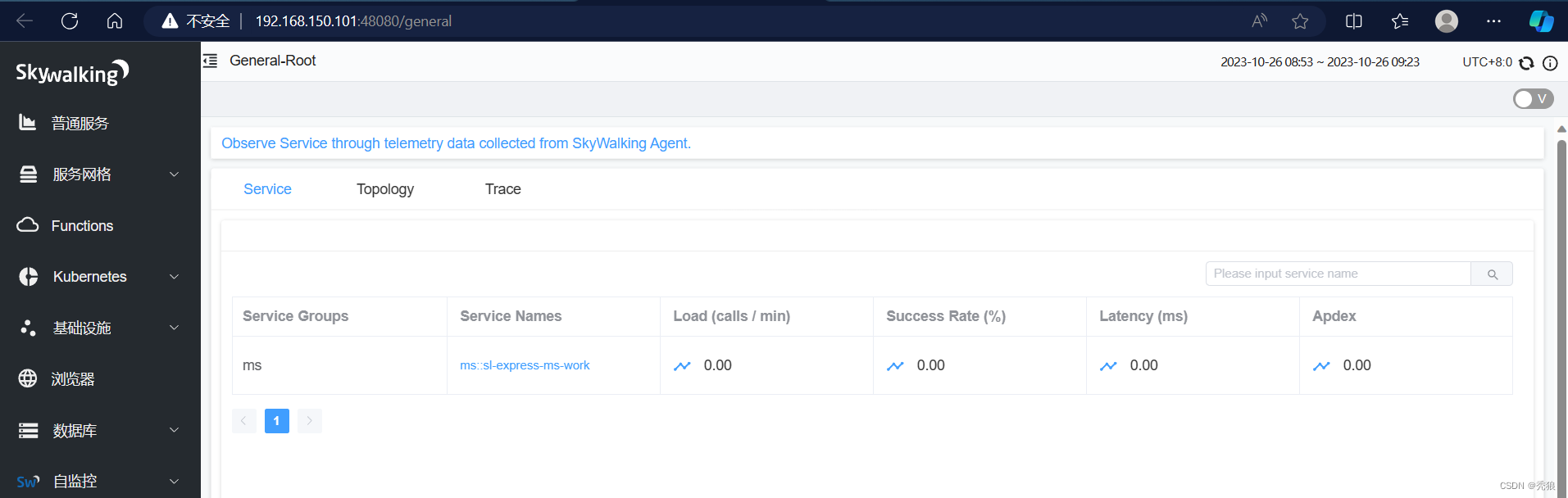
访问接口进行测试