

SparkSQL源码分析系列02-编译环境准备
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
本文主要描述一些阅读Spark源码环境的准备工作会涉及到源码编译插件安装等。
1. 克隆代码。
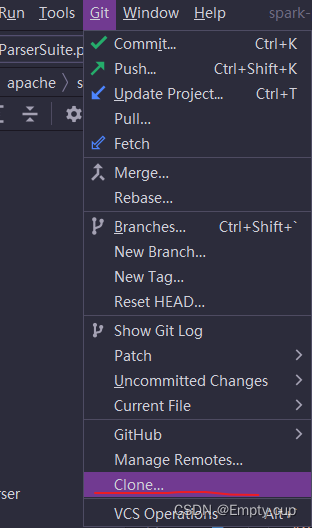
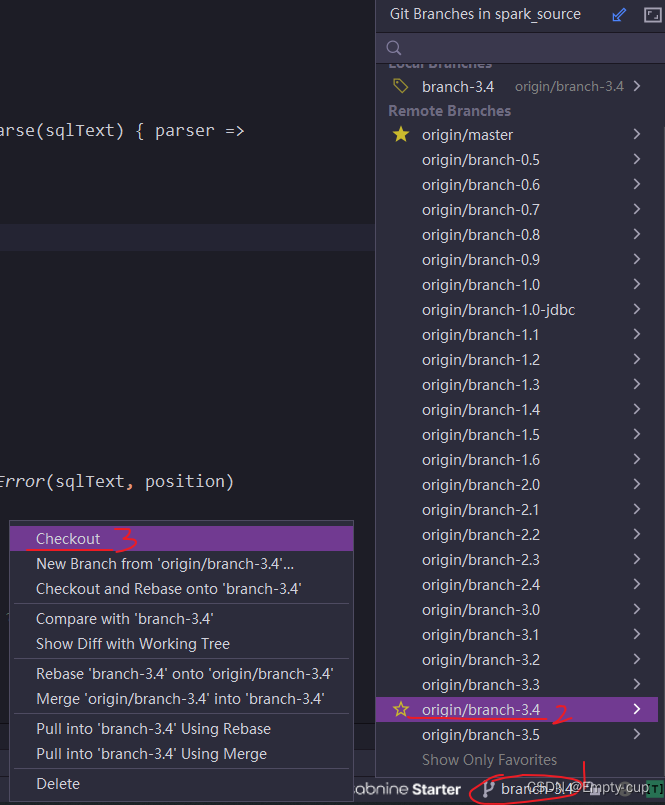
打开IDEA在Git下的Clone中输入 https://github.com/apache/spark克隆代码到本地CheckOut到目标版本Spark3.4
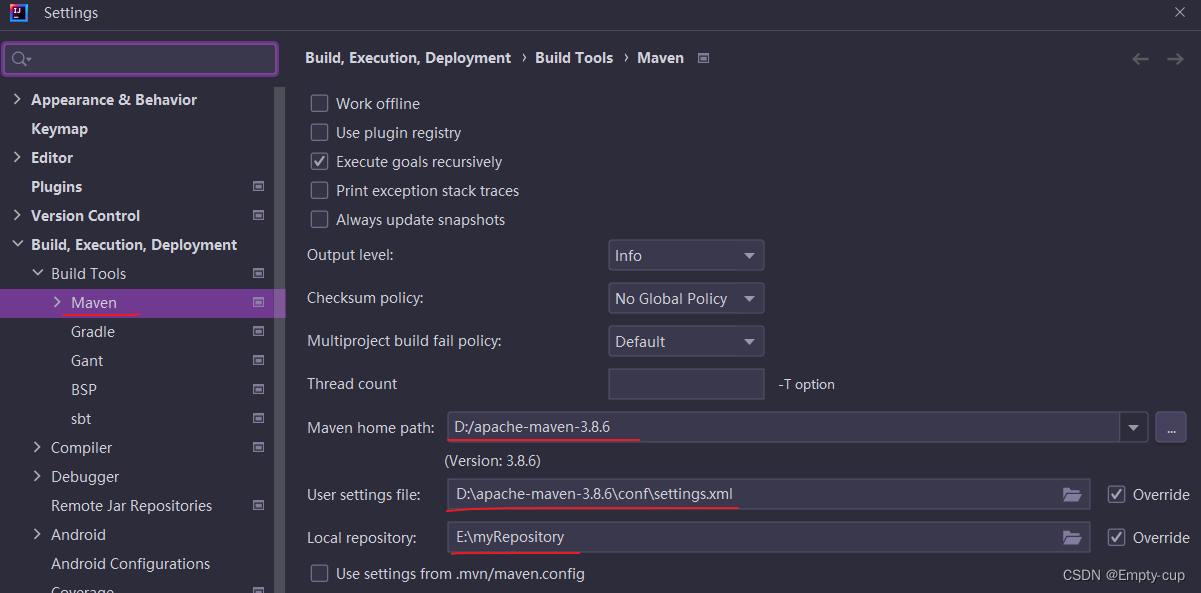
2. 安装maven。
版本按照pom文件指定的版本安装在IDEA中配置安装的路径。

3. 为IDEA安装 ANTLR 和 Scala 插件

4. 测试ANTLR的词法语法解析功能
在Spark源码项目中搜索 SqlBaseParser.g4 文件在 singleStatement 上右键找到“Test Rule singleStatement”在底部对话框中输入SQL语句观察解析出的抽象语法树。
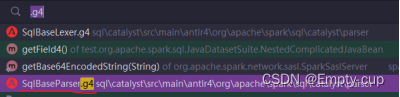
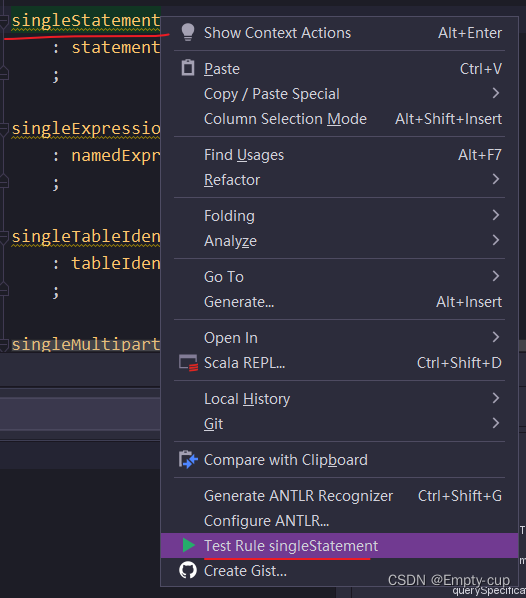

注意SQL语句一定要大写。
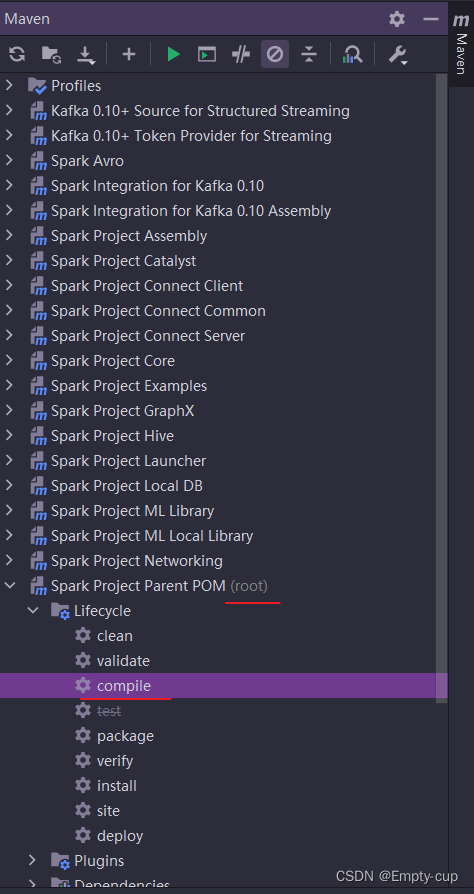
5. 编译源码
由于我们只做源码阅读不做打包所以只需要通过 compile 就行package貌似报错更多不容易打包成功但是 compile 相对容易。多次 compile 尝试直到 build success。
6. 运行测试类
在…/spark_branch3_4/sql/core/src/test/scala/org/apache/spark/sql目录下打开 SQLQuerySuite 文件在任意一个test模块上右键、运行观察是否正常输出。
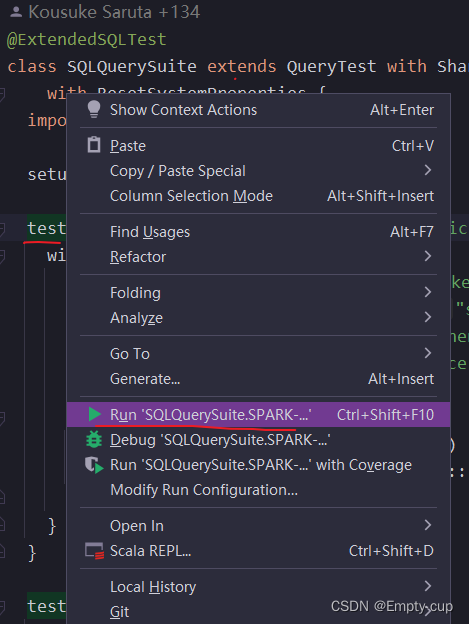
测试案例运行成功。至此代表源码阅读环境准备完毕。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |