

单链表面试题思路分享二
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
单链表面试题思路分享二
前言
我们紧接上文单链表面试题分享一来看看本章我要分享的题目,共四个题目,我还是把它在力扣或者牛客网的链接交给大家:1.合并两个有序链表力扣21题-----2.链表的分割牛客网cc149-----3.链表的回文结构力扣234题-----4.链表相交力扣160题,本次分享还是和之前一样,代码用c语言实现,我只分享我自己的思路和我认为容易想错的点(我曾经错过的点),如若我的代码有问题但是这个题刚好可以编译可以,请大家评论区提出.
1.合并两个有序链表
1.1 审题
我们首先看题:
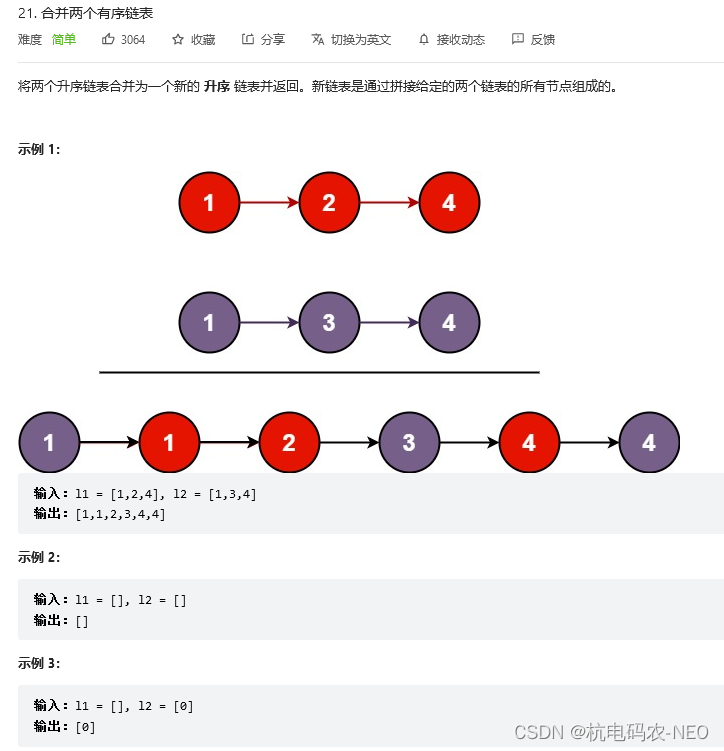
我们看见这道题的时候很容易和我们之前做的一道"合并两个有序数组"联系起来,但是问题是数组是可以通过下标来查找的,但是这个地方我们的链表只能"无脑"向后走,显然是不能用之前的结论的.***这里我们想到的就是用两个变量n1和n2,一个遍历list1,一个遍历list2,两个遍历同时走,我们可以再定义两个结构体指针head和tail,head是我们合并后数组的新头,tail用来不断往后走,这样我们就可以不用每次都遍历链表再插入.n1和n2谁指向的节点对应的值小就把谁放在tail上,然后值小的内个指针往后迭代,值大的保持不变.
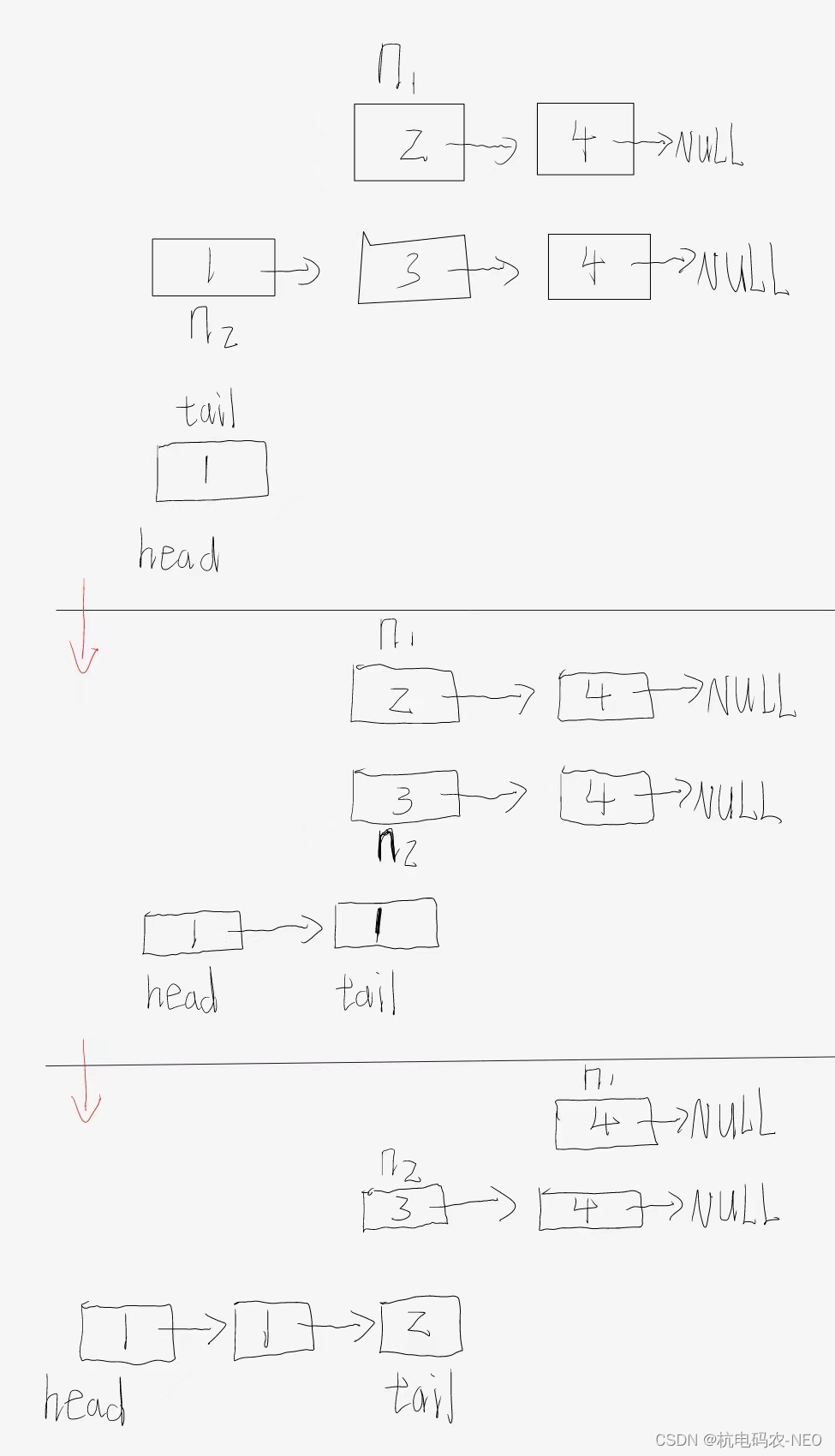 我们这样不断往后走直到n1或者n2其中一个为null,我们现在来实现一下代码
我们这样不断往后走直到n1或者n2其中一个为null,我们现在来实现一下代码
1.2 代码实现
#include<stdio.h>
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)//
{
struct ListNode* n1 = list1;
struct ListNode* n2 = list2;
struct ListNode* head = NULL;
struct ListNode* tail = NULL;//tail随时跟随新链表变动
while (n1 && n2)
{
if (n1->val >= n2->val)
{
if (head == NULL)//head最开始为NULL,要先赋值
{
head = n2;
tail = n2;
}
else
{
tail->next = n2;
tail = n2;//tail不断往前走,这样就可以不用每次都遍历链表找到尾再插入了
}
n2 = n2->next;
}
else if (n1->val < n2->val)
{
if (head == NULL)
{
head = n1;
tail = n1;
}
else
{
tail->next = n1;
tail = n1;
}
n1 = n1->next;
}
}
if (n2)//当n1或n2其中一个为空时就跳出来判断
{
tail->next = n2;//当n2首先为null时,我们就把list1后面所有的节点全部链接在tail后面
}
else if (n1)
{
tail->next = n1;//当n1首先为空时,我们把list2后面所有的节点全部链接在tail后面
}
return head;//最后返回我们新定义的头
}
1.3 代码优化
但是当我们提交代码后会发现它报错关于空指针解引用的问题,我们定义在出错的那一行,发现当我们原先的链表为空时,我们执行tail->next是对空指针解引用.所以我们来优化一下代码:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)//
{
if (list1 == NULL)//若这个地方不判断list是否为空指针,后面部分对tail解引用会报错为对空指针解引用
{
return list2;
}
if (list2 == NULL)
{
return list1;
}
struct ListNode* n1 = list1;
struct ListNode* n2 = list2;
struct ListNode* head = NULL;
struct ListNode* tail = NULL;//tail随时跟随新链表变动
while (n1 && n2)
{
if (n1->val >= n2->val)
{
if (head == NULL)//head最开始为NULL,要先赋值
{
head = n2;
tail = n2;
}
else
{
tail->next = n2;
tail = n2;//tail不断往前走,这样就可以不用每次都遍历链表找到尾再插入了
}
n2 = n2->next;
}
else if (n1->val < n2->val)
{
if (head == NULL)
{
head = n1;
tail = n1;
}
else
{
tail->next = n1;
tail = n1;
}
n1 = n1->next;
}
}
if (n2)//当n1或n2其中一个为空时就跳出来判断
{
tail->next = n2;
}
else if (n1)
{
tail->next = n1;
}
return head;
}
只需要在代码最前面判断一下list是不是为空就好了.
2. 链表的分割
2.1 审题
先看题:
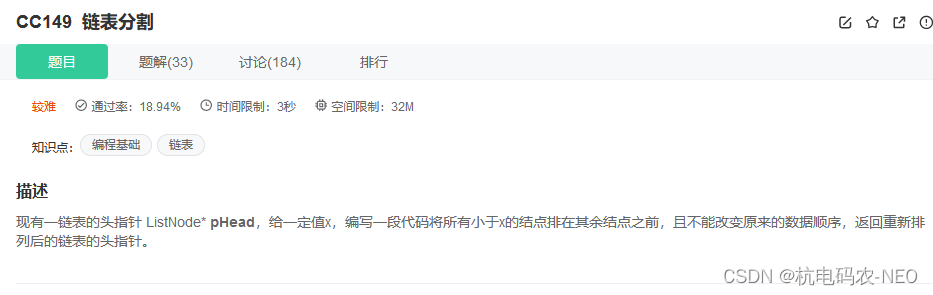
题目没有给用例,我们自己来假设一个.假如我们这个地方的链表给定为7->2->4->8->5->3.我们给一个X为4.那么我们将实现下图的功能:

我们的思路可能是先定义两个结构体指针n1和n2存放head的值,然后遍历链表,将节点指向的值小于X的链表放在b1当中,然后将节点指向的值小于X的节点放在n2当中,最后再将两个链表链接起来就可以了.但是当我们正在去实现代码的时候会发现,我们这样在原先链表上做这些操作很复杂,既要考虑节点的指向问题又要重新定义一个prev节点来记录前一个节点的位置.所以这种方法我们先放在一边看看有没有简单一点的方法.我们顺着刚才的思维再往下想,我们是不是可以重新定义两个结构体变量,为这个变量开辟一块和原先结构体占用空间大小一样的空间.然后我们不在原先的链表上操作而是在这两个新定义的"链表"中操作,这样就避免了在原先的链表上操作了. 在实现代码之前,我们有了之前几个题的经验会发现实现完代码总会有一些特殊的情况,比如头为空,或者对空指针解引用等等.这里我们创建两个变量的时候,我们再创建两个哨兵位来避免遇见这种问题. 这里如果有人不知道什么是哨兵位的话,我给大家一个链接快速了解哨兵位哨兵位作用和好处讲解
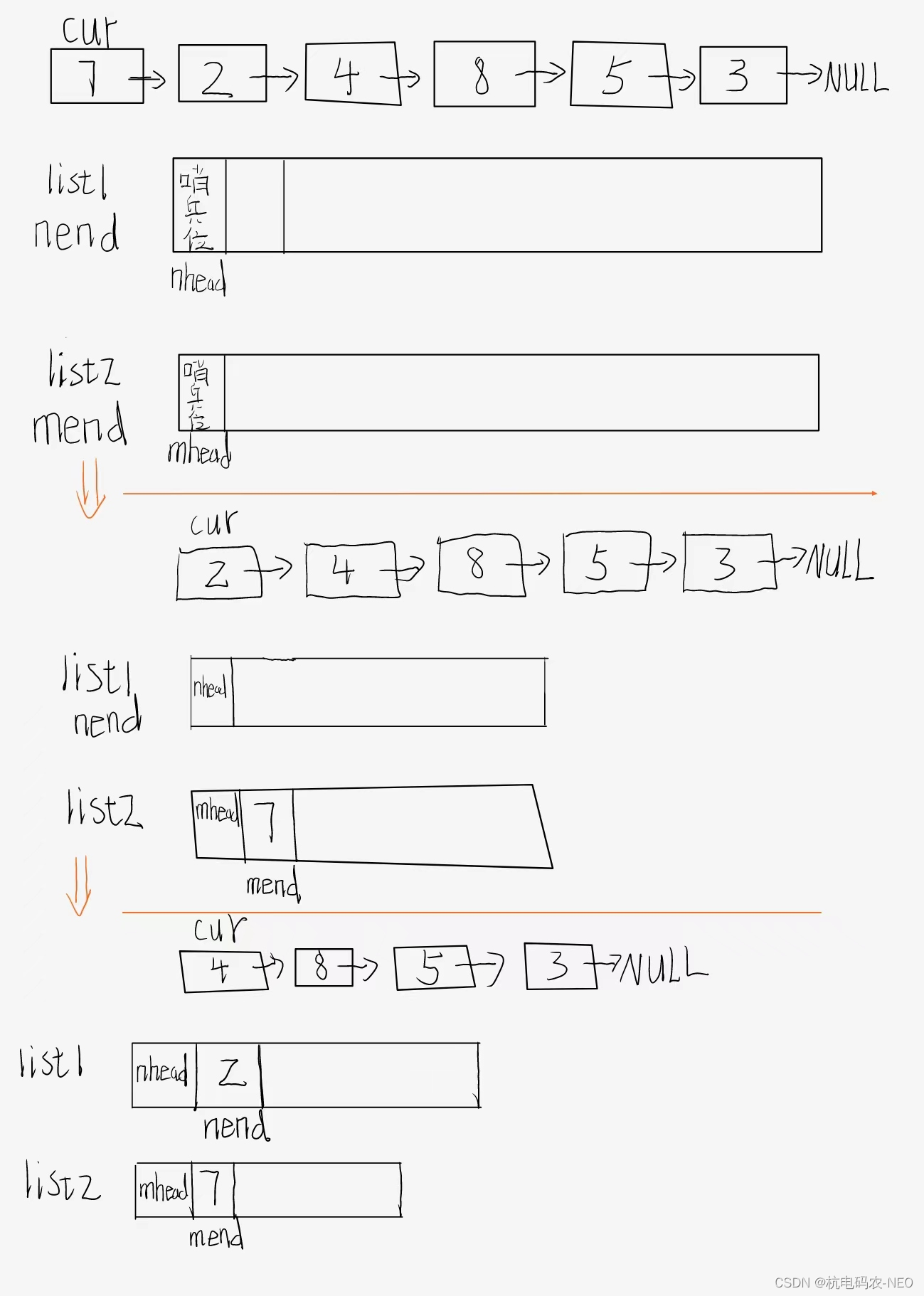
2.2 代码实现
ListNode* partition(ListNode* pHead, int x) {
ListNode* nhead, * nend, * mhead, * mend;
nhead = nend = (ListNode*)malloc(sizeof(ListNode)); //head和end指向同一个空间.
mhead = mend = (ListNode*)malloc(sizeof(ListNode));
mend->next = nend->next = NULL;//设置哨兵位方便尾插
ListNode* cur = pHead;
while (cur) {
if (cur->val >= x) {
mend->next = cur;
mend = cur;//mend要往后走
} else {
nend->next = cur;
nend = cur;//nend也要往后走
}
cur = cur->next;
}
nend->next = mhead->next;//将两个链表链接在一起
mend->next = NULL;//这里因为mend为新链表的最后一个节点,它可能指向nhead中的元素.
ListNode* newhead = nhead->next;
free(nhead);
free(mhead);
return newhead;
}
还有一点需要注意,上面这段代码中我最后把mend->next置为了NULL,这时因为我们有可能遇见下面这种情况,从而把我们的新链表变成了一个环:

3. 链表的回文结构
3.1 审题
先看题:
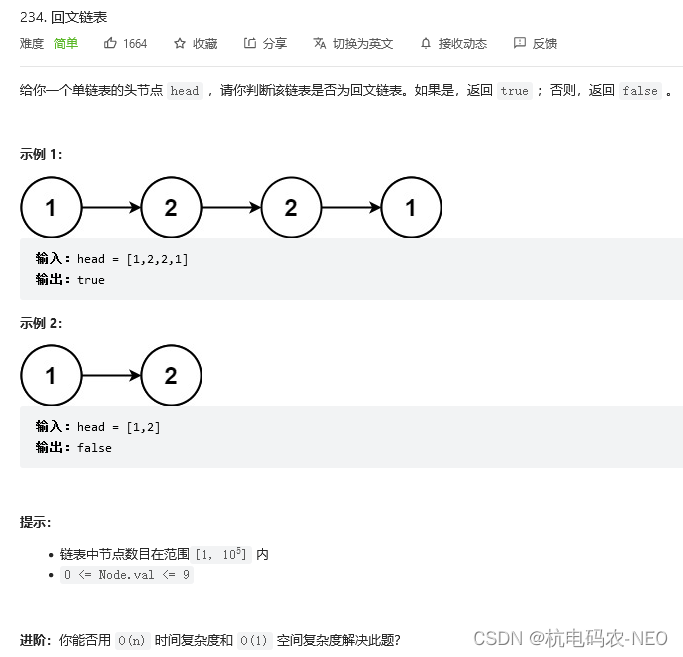
首先我们这里返回的是布尔类型true和false.这里题目值给出了我们的偶数个节点的情况,当我们写代码的时候还需要考虑奇数个节点.现在我们先来考虑偶数个节点的时候,如果链表为回文结构的话它是对称的,假如我们定义两个变量,一个变量放链表的前二分之一个节点,宁外一个链表放链表的后二分之一个节点再来判断这两个链表是否相同是不是能够完成任务,前二分之一个链表我们尾插原链表的节点,后二分之一个链表我们头插原链表的节点,这样我们就把两个链表变成一样的顺序了.这种方法按照逻辑是没有错的,但是我们说,这个题有没有优解,我们可以想到前一章我们讲过链表的中间节点和链表反转链表,我们仔细一想其实会发现这种头插尾插的形式还是比较麻烦的,我们可以利用前面的结论先找到链表的中间节点,再将中间节点后面的链表进行反转,这样也能得到我们想要的结果.
 我们一起遍历这两个链表,当其中一个链表为空时我们就停下来,这里我们先把偶数个节点的情况代码写出来,再去看奇数个:
我们一起遍历这两个链表,当其中一个链表为空时我们就停下来,这里我们先把偶数个节点的情况代码写出来,再去看奇数个:
之前我们用的找中间节点的办法是计数,我根据==感觉这样效率不高,所以这里我重新引入一种寻找中间节点的方法
3.2 代码实现
bool isPalindrome(struct ListNode* head)//先找到中间结点,再将中间结点以后的链表进行反转,利用前面链表题的结论
{
struct ListNode* n = head;
struct ListNode* m = head;
while (m && m->next)//找到中间的节点的新方法,这个地方循环完后中间节点为n,可以自己画图验证
{
n = n->next;
m = m->next->next;
}//n为中间结点
struct ListNode* cur = n;
struct ListNode* prev = NULL;
struct ListNode* next = n->next;
while (cur)//反转链表
{
cur->next = prev;
prev = cur;
cur = next;
if (next)
{
next = next->next;
}
}//prev为反转后的头
struct ListNode* phead = head;
while (phead && prev)//比较两个链表,当一个链表为NULL就停止
{
if (phead->val != prev->val)
{
return false;
}
else
{
phead = phead->next;
prev = prev->next;
}
}
return true;
}
我们判断偶数个的方法就已经实现出来了,再来思考奇数个节点应该怎么样判断:我们还是先找到中间的节点后反转再看看情况如何:
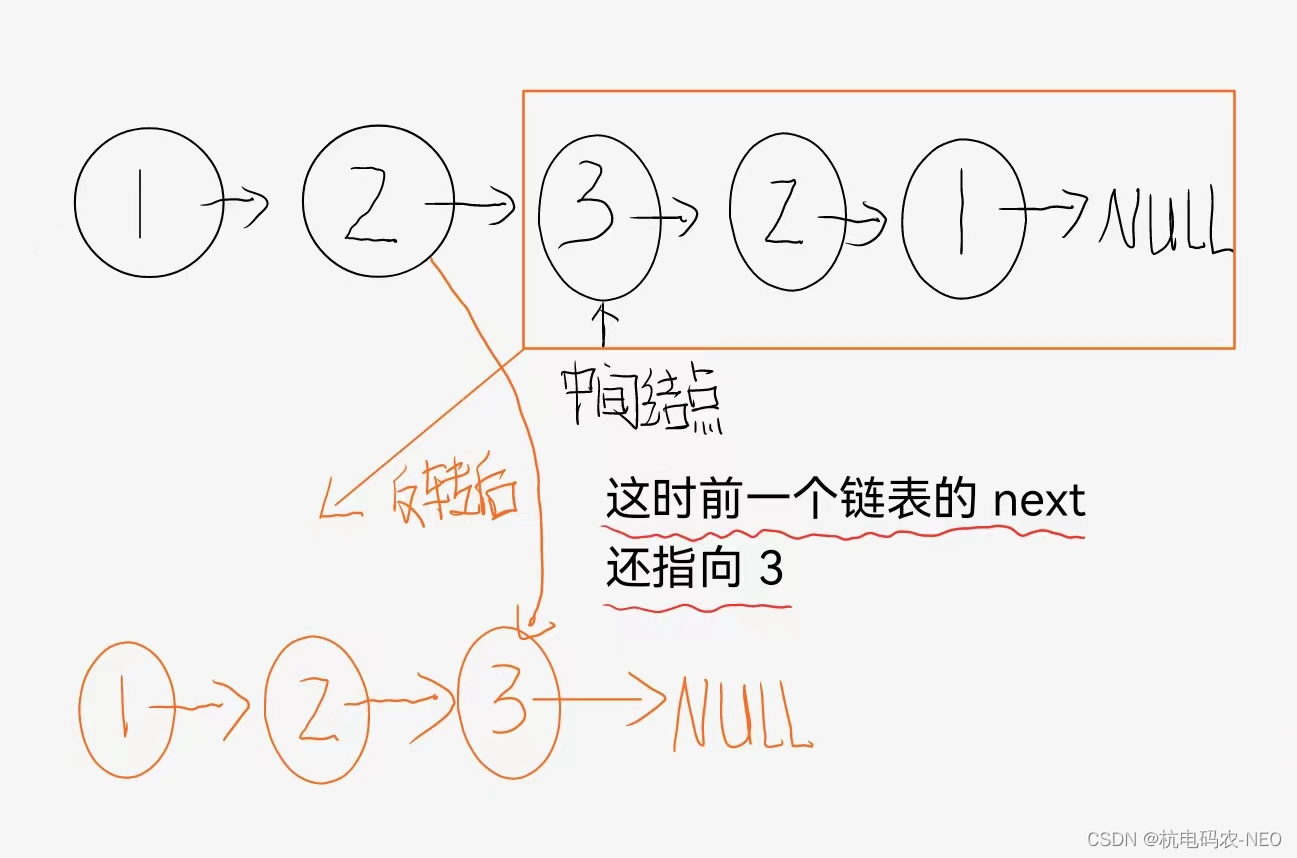
我们苦恼的点是比起上面的链表1,我们下面的链表2多了一个3,我们会认为在依次遍历我们的链表时会多出来一个节点,所以这种方法就不能采用,但是其实并不是这样,这个题很巧的地方在当我们的两个链表都走到2时,这时上面的链表1的next是指向链表2的节点3的,我们链表2的next也是指向节点3的,所以不会出现我们说的多出来一个节点的情况,所以我们对的偶数个节点的判断方法其实是适用于奇数个节点的 当我们做到这个地方的时候就很明了了,当我们以为一个方法是错误的时候不要把结论定死,先画图分析一下!
4. 链表相交
4.1 审题
我们先看题:
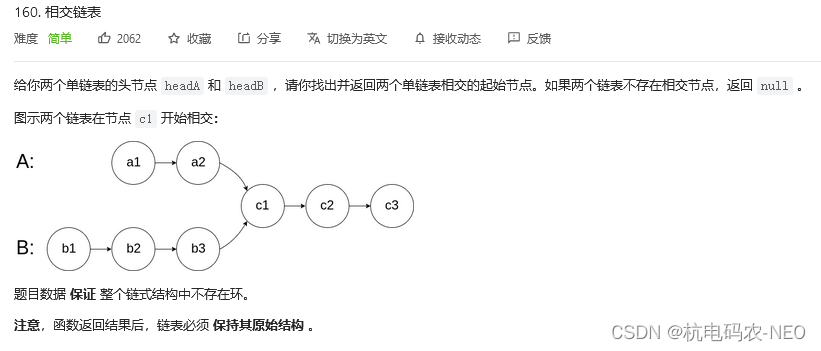
这是我第一次遇见两个链表指向同一个节点的问题,这里题目要我们干两件事,一是让我们判断这两个链表有没有公共节点,二是有公共节点返回相交的起始节点.这里我们把两个相交的链表分开来看要简洁明了一点:
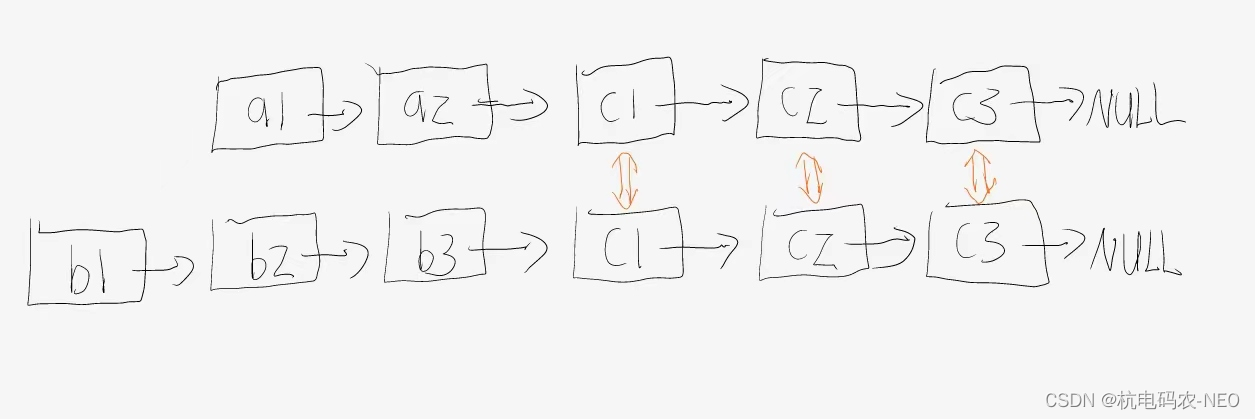 这里我们发现,如果两个链表有相交的节点,那么这两个链表的最后一个节点一定相同!注意这里的相同不是节点存储的数大小相同,这里是相同指的是两个结构体指针指向的是同一块空间,也就是同一个节点.所以我们的第一个问题就很好的解决了,我们只需要判断list1和list2最后一个节点相不相同就可以了.,我们还说,单链表指向的下一点只能有一个,所以我们不能说链表1和链表2在p点相交了,但是相交后面的节点可以不一样,比如像这样的X型结构是不存在的:
这里我们发现,如果两个链表有相交的节点,那么这两个链表的最后一个节点一定相同!注意这里的相同不是节点存储的数大小相同,这里是相同指的是两个结构体指针指向的是同一块空间,也就是同一个节点.所以我们的第一个问题就很好的解决了,我们只需要判断list1和list2最后一个节点相不相同就可以了.,我们还说,单链表指向的下一点只能有一个,所以我们不能说链表1和链表2在p点相交了,但是相交后面的节点可以不一样,比如像这样的X型结构是不存在的:
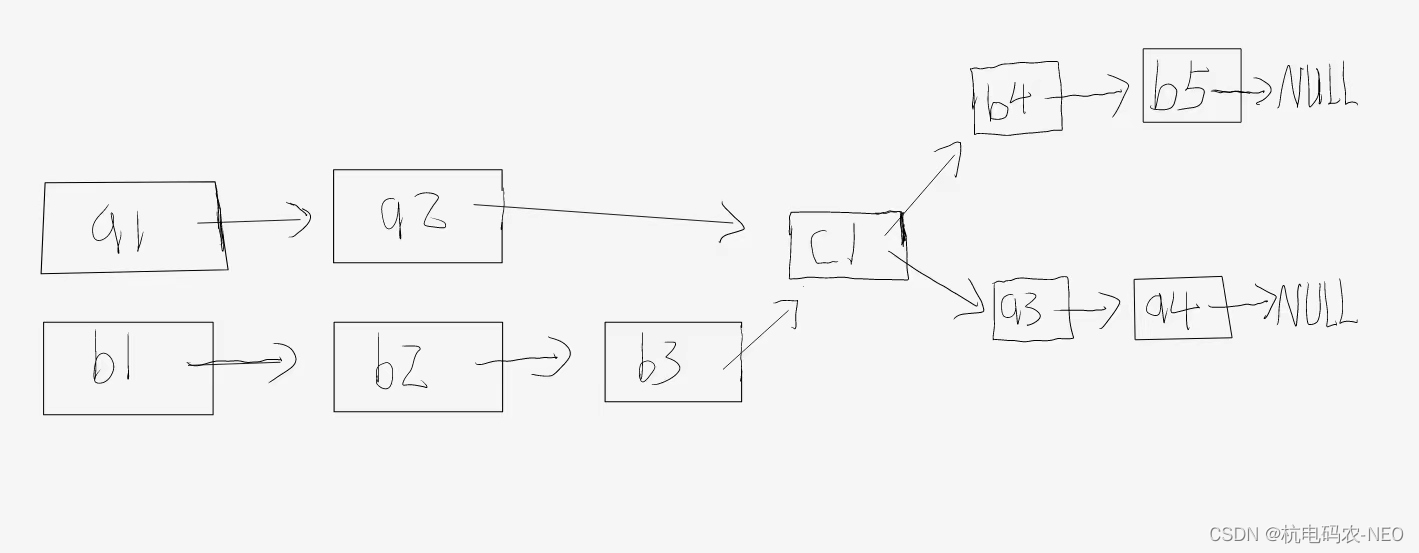
所以我们之前的判断可以说是没有问题的,思考到这里,我们会很容易想到一个方法来判断公共节点是否存在,那就是将链表1中的节点一一拿出来遍历链表2中的节点,如果相同就返回它,但是我们说这样做虽然可以做出来这道题,但是它的时间复杂度为O(N^2),而且思路比较平凡,没有创新型.所以我们宁僻稀径,我们想到要是这两个链表的长度一样就很好办了,假如两个链表节点数相同我们就可以从头直接一一对比链表1和链表2而不用遍历链表很多遍了.并且很巧的是我们之前判断它是否有相交节点的时候我们已经遍历过一遍两个链表了,这里我们在原来遍历的基础上加一个count1和count2来计数链表的节点数,两个链表相差多少个节点数我们就在节点数少的两个前面头插几个节点,将两个链表的结点数变成相同的.现在我们有大致的思路了就来实现一些代码.
4.2 代码实现
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB)
{
struct ListNode* n1 = headA;//定义n1和n2来计数
struct ListNode* n2 = headB;
struct ListNode* cur1 = headA;//定义cur1和cur2来遍历链表
struct ListNode* cur2 = headB;
int count1 = 0, count2 = 0;
while (n1)//计算第一个链表有多少个结点
{
n1 = n1->next;
count1++;
}
while (n2)//计算第二个链表有多少个结点
{
n2 = n2->next;
count2++;
}
if (count1 > count2)//当两个链表结点数不一样,就把结点数少的链表头插几个结点变成和宁外一个链表结点数相同
{
int count = count1 - count2;
while (count-- > 0)//这个过程在头插,list2头插
{
struct ListNode* newhead2 = (struct ListNode*)malloc(sizeof(struct ListNode));
newhead2->val = 0;//头插的val设置为0
newhead2->next = cur2;
cur2 = newhead2;
}
}
else if (count1 < count2)//也是头插,只不过是list1头插
{
int count = count2 - count1;
while (count-- > 0)
{
struct ListNode* newhead1 = (struct ListNode*)malloc(sizeof(struct ListNode));
newhead1->val = 0;
newhead1->next = cur1;
cur1 = newhead1;
}
}
while (cur1)//当链表的结点数相同后,我们就找每个链表对应结点的值相不相同,
// 如若相同就判断它们指向的结点是不是同一个
{
if (cur1->val == cur2->val)
{
if (cur1 == cur2)
{
return cur1;
}
}
cur1 = cur1->next;
cur2 = cur2->next;
}
return NULL;//如果没有返回cur1证明遍历了一整遍后都没有找到相交的节点.就返回null.
}
这个代码我们一提交就直接通过了,反应出我们的解题思路还是没有什么问题的,这个方法是小编自己做这个题时用的方法,但是这个题还有宁外一个解法
4.3 方法二的实现
我们说假如两个链表的长度是一样的我们就可以很好的解题了,这里我们引出宁一种方法,这种方法和方法一很相似,这里我们还是在原来遍历链表的基础上定义两个计数变量来记录链表1和链表2的节点个数,假如链表1比链表2多了n个节点:
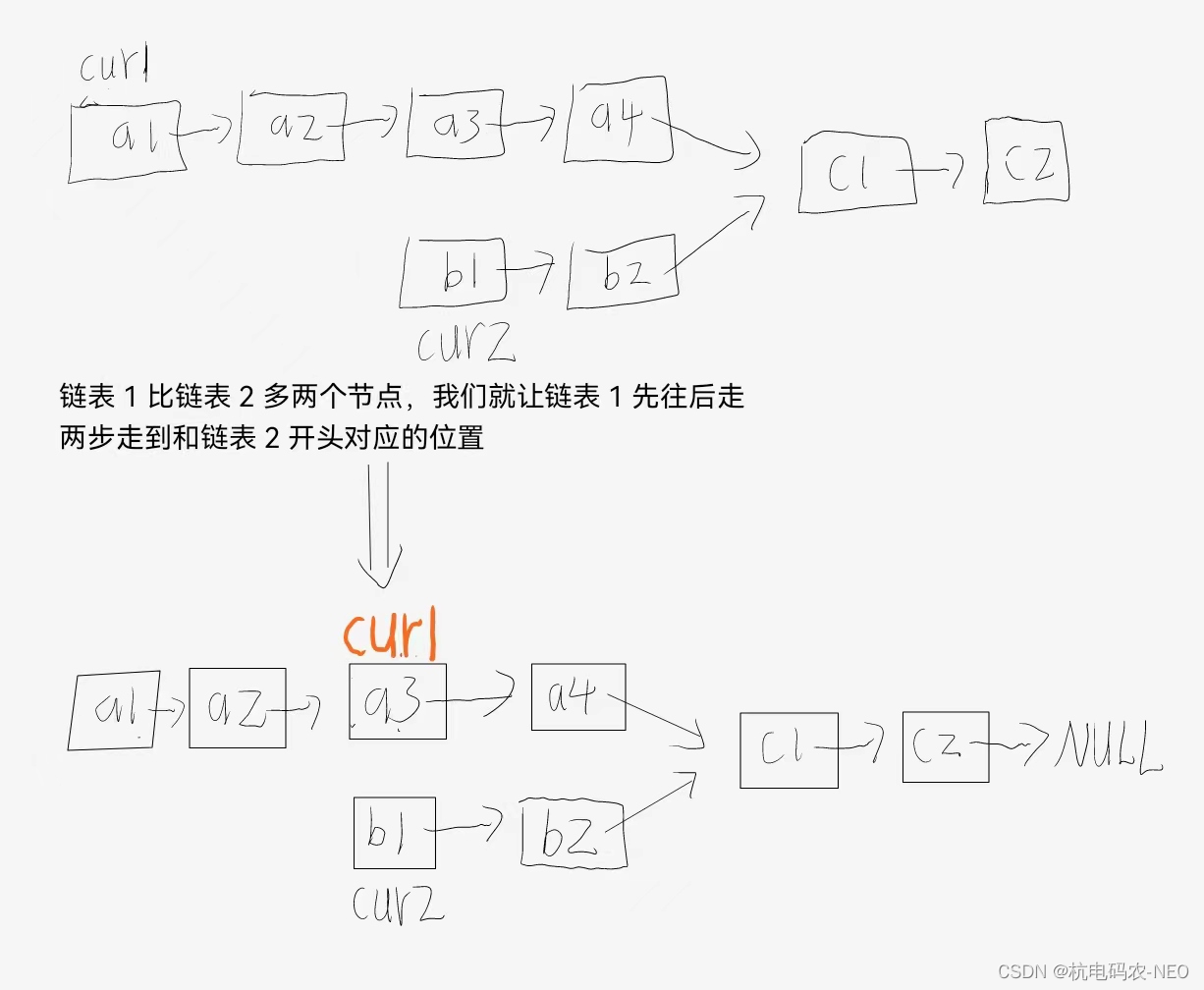
现在我们来实现这段代码:
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB)
{
struct ListNode* taila = headA;
struct ListNode* tailb = headB;
int lena = 1;
while (taila->next)
{
lena++;
taila = taila->next;
}
int lenb = 1;
while (tailb->next)
{
lenb++;
tailb = tailb->next;
}
//不相交
if (taila != tailb)
{
return NULL;
}
int gap = abs(lena - lenb);//abs为绝对值的意思
//长的先走差距步,再同时找交点
struct ListNode* longlist = headA;
struct ListNode* shortlist = headB;
if (lena < lenb)
{
shortlist = headA;
longlist = headB;
}
while (gap--)
{
longlist = longlist->next;
}
while (longlist != shortlist)
{
longlist = longlist->next;
shortlist = shortlist->next;
}
return longlist;
}
5. 总结
本篇文章的四个题的难度相较于前一篇文章的难度是有所提升的,甚至我们还用到了前一章解题的一些结论.我们第一次做这种链表OJ题可能找不到头绪,不知道改从何下手,我想说这是很正常的现象!小编做题时也是往往抠破头皮也想不到解题之道,但是这种时候千万不要去看解析,还是上次提到的方法,先审题,再画图,有一定思路框架后再尝试写代码,遇见报错不要怕,慢慢调试它,我们说一个优秀的程序员思考和修改代码的时间是远远超过写代码的时间的!最后重要的事情再说一遍:链表题画图真的很重要,可以说画图画的好,解题只需一两秒.
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |