

浅谈Redis基本数据类型底层编码(含C源码)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
- 一、String
- 1、int
- 2、embstr
- 3、raw
- 4、bitmap
- 5、hyperloglog
- 二、List
- 1、ziplist
- 2、quicklist
- 三、Hash
- 1、ziplist
- 2、hashtable
- 3、string和hash的使用取舍
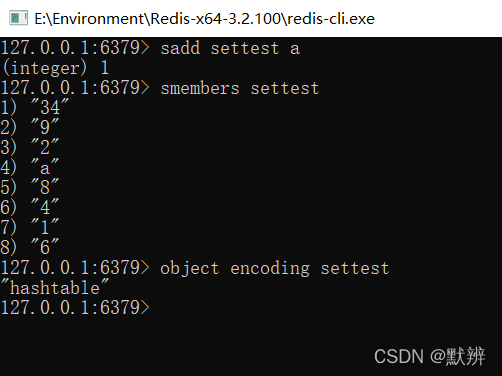
- 四、Set
- 1、intset
- 2、hashtable
- 五、ZSet
- 1、ziplist
- 2、skiplist
- 3、zadd源码流程
- 4、geospatial
写在前面,在阅读本文前需要简单了解Redis底层的数据结构(C语言中相关变量的定义),否则不建议阅读本文。想简答了解Redis底层数据结构的可以参考我之前的博客:浅谈Redis底层数据结构(sdshdr-redisObject)
了解了Redis底层数据结构,你就能知道C语言层面中redisObject的含义其type就对应string、list、hash、set、zset这五种基本数据类型,与之对应的分别是每种基本数据类型的encoding底层编码。如下图,string类型的底层编码可以是int、embstr、raw。本文的主要内容也就是讲解这些底层编码。Redis为什么这么快,与这些底层编码有直接的关系。
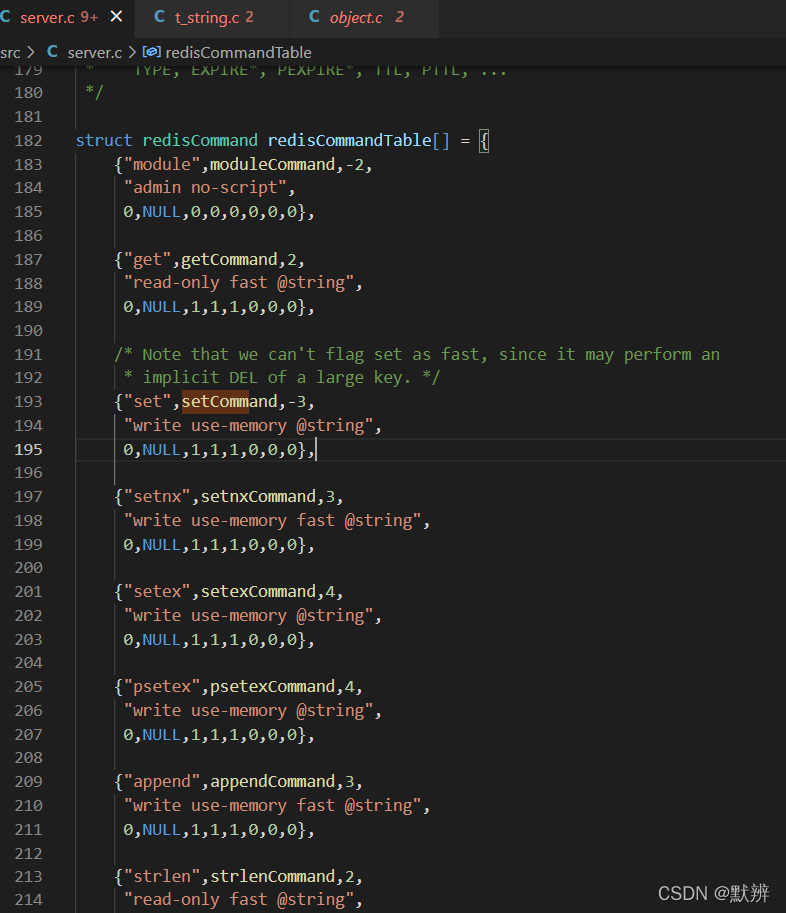
server.c里的redisCommand结构体包含了所有的客户端命令,所有的命令都可以以该结构体为起点进行调试
一、String
Redis提供的String类型,其底层有三种不同的编码格式,对应的是redisObject对象的encoding变量的取值变化。
1、int
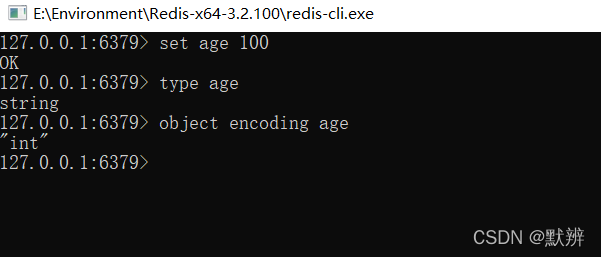
当我们的age值为int类型的时候,其对应的底层编码是一个int类型。
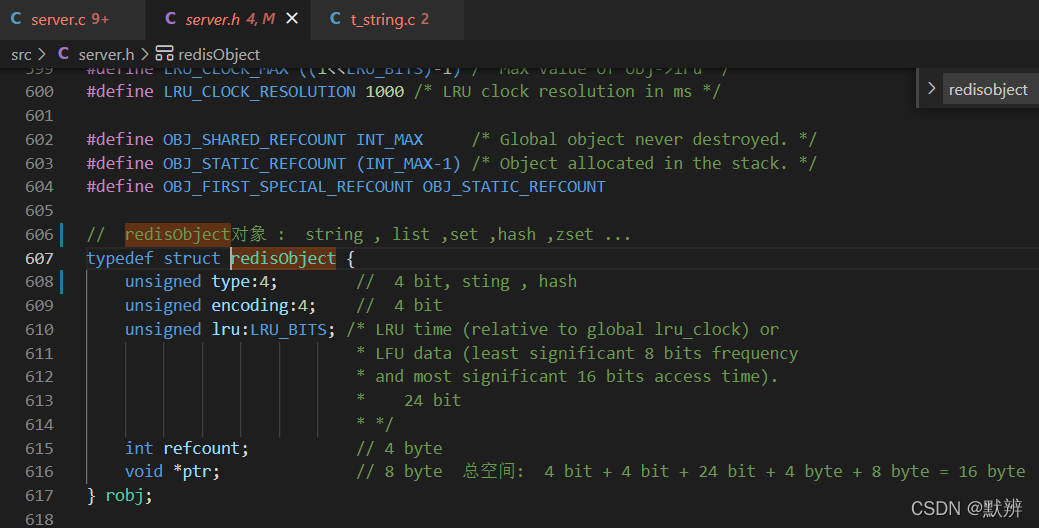
让我们又回到redisObject这个位置。通过观察我们发现,type4个二进制位,encoding4个二进制位,lru24个二进制位,refcount是int类型占用4个字节,*ptr是一个指针在64位机器上占用8个字节。
此时,(4B+4B+24B)/8 + 4byte + 8byte = 16byte,即redisObject占用16个字节,当然这个总大小并不是此处的重点。此处重点位*ptr这个指针,该指针的作用是用于指向我们的真实的value数据存放的地址。
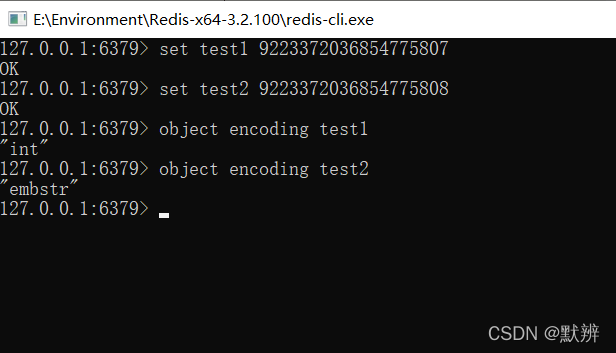
巧在,64位机器下面,长整型也占用8个字节,即表示该指针表示的值刚好能够存放所有的数字值。那么为什么不直接使用该指针来表示具体的数字呢?reids就是这么做的。以至于我们使用object encoding 查看对应的底层编码时,使用的是int。long最大值为,9223372036854775807。
测试值,当数字超过最大值9223372036854775807的时候,String类型的底层编码就变成了embstr
对应的底层源码逻辑为
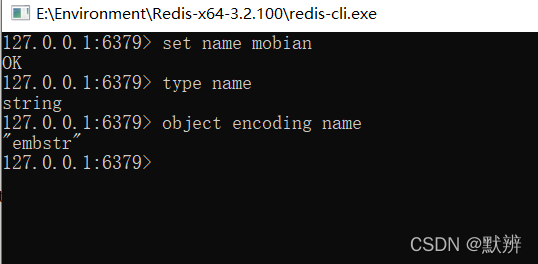
2、embstr
跳过第一个int的return,进入第二个return。此时字符串的底层编码是embstr
我们都知道操作系统加载数据是没办法要多少加多少的,它的最小加载单位为一个缓存行。这在我之前的博客有进行过讲解,有兴趣的小伙伴可以参考:浅谈volatile与计算机缓存一致性协议(MESI)之间的联系。64位计算机,一次加载的最小单位就是64个字节,即64byte。
此处又要提及另一个结构体dictEntry,该变量可以理解为一个key-value的集合体,这在开头提到的博客中有进行过讲解。我们一次get操作,必然是会拿到整个dictEntry,此时该实体就包含两部分,即key和value。
key就是我们所说的sdshdr结构体,len+alloc+flags+buf = 4byte。buf也占用一个二进制位是因为它会在末尾自动补齐一个\0,用来兼容C语言的函数库。
value,前文算过占用16byte
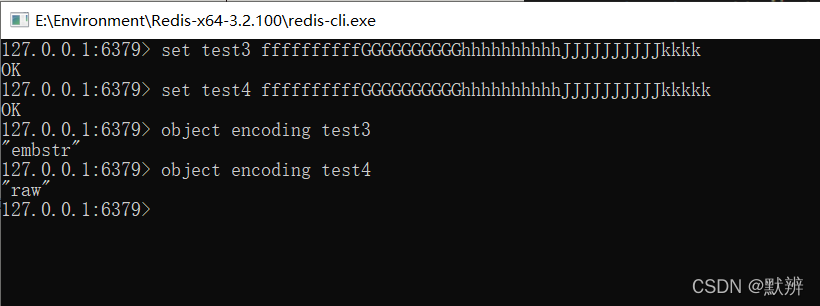
64byte - 16byte - 4byte = 44byte,即留给字符串用来存放的位置还有44byte
测试超过44位的长度变化
对应源码说明
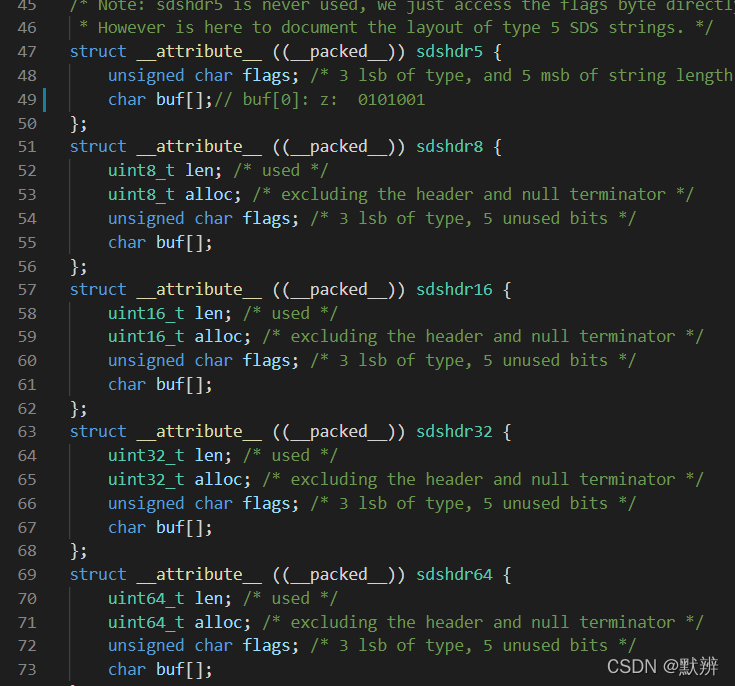
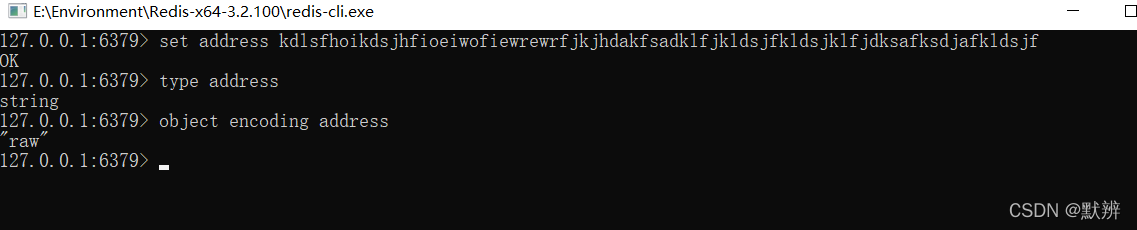
3、raw
其他情况,使用raw存储,使用*ptr指向对应的内容的地址
4、bitmap
我们使用type可以查看bitmap类型
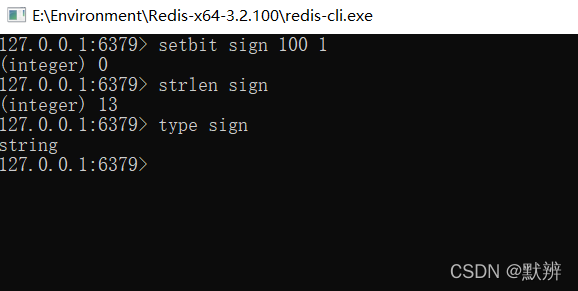
通过上面的测试,我们可以发现Redis中的bitmap是使用string类型来修饰的,并且使用一个int类型的数字来描述string字符串的长度,我们都知道int类型,int类型大小为4byte,也就是32个二进制位,即最大能表示2^32。
上图的sign 100 1,表示的含义为在string的底层含义为,在string的底层偏移量的第100的位置的bit位设置为1,既然是底层偏移量那么我们也就很容易明白偏移量只能是int数字。
所以我们可以得出,bitmap的长度是使用int来描述,所以string类型的最大长度为init的最大值,即 2^32B / ( 2^3 * 2^10 * 2^10) = 2 ^9M = 512M,bitmap能表示的最大值为512M。即如果我们想要使用bitmap,则会一次性开辟521M的空间,这是十分浪费空间的。
5、hyperloglog
其底层也是使用string,不过对于它的原理我还没看明白。
推荐参考文章:Redis源码中hyperloglog结构的实现原理是什么?
二、List
Redis中的List是一个有序(按加入的时序排序)的数据结构,采用quicklist(双端链表) 和 ziplist 作为List的底层实现。可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率
Redis中的list可以理解为Java中arraylist和linklist的一个集合体,既汲取了arraylist 紧凑的数据(不使用链表节点而浪费空间),又汲取了linklist含有节点而带来增删的高效(不会因为要所有数据生成一个全新数组而降低效率)
1、ziplist
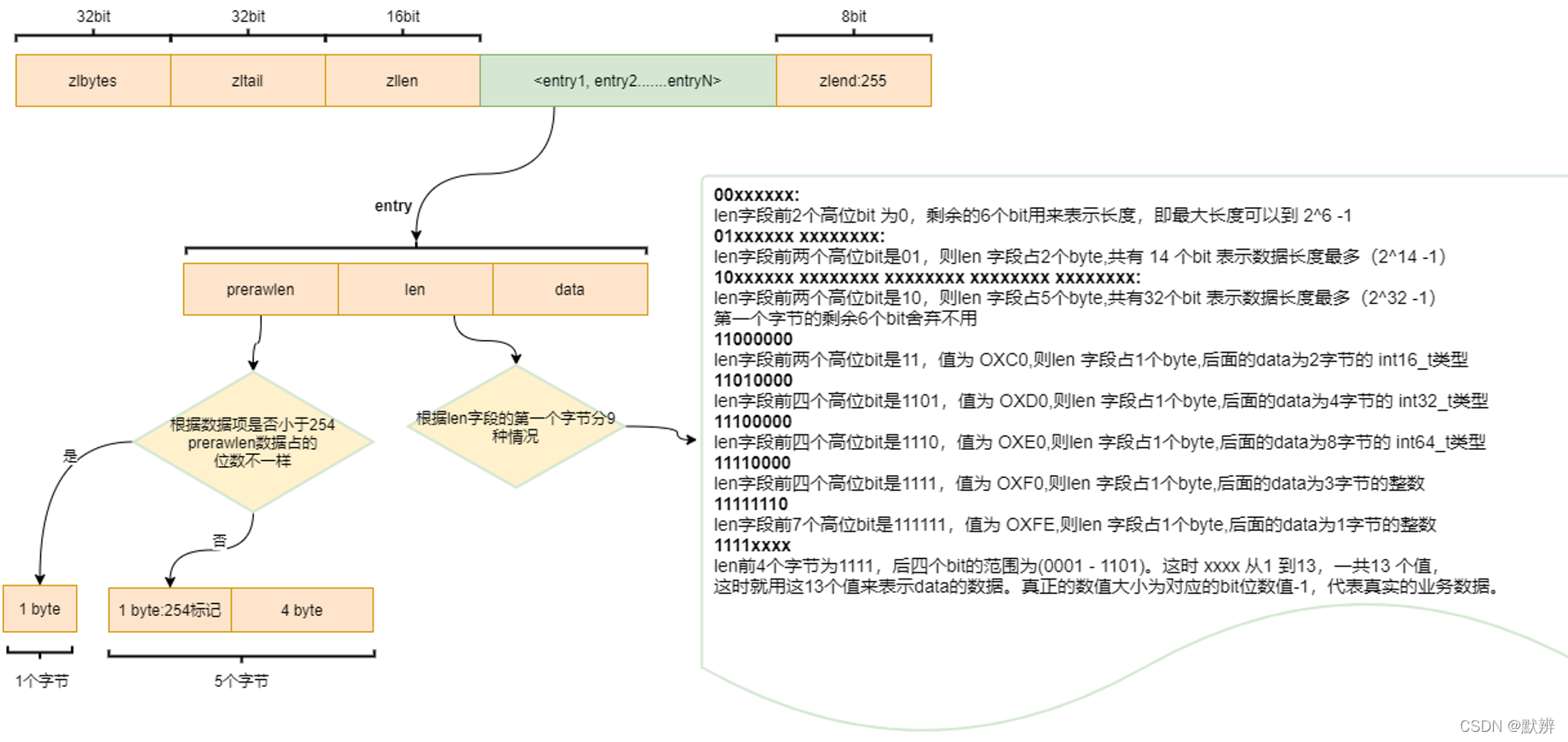
ziplist可以理解为一个Java中的缩小版arraylist,arraylist中的每一个节点变成ziplist中的一个entry。在此基础上,将所有的entry(整个list中数据的一部分)看作一个整体,并为其增加其他相应的描述,如ziplist的长度、最后一个元素的偏移位置、entry的个数…
相关变量描述如下:
1、zlbytes:表示当前ziplist的长度
2、zltail:表示ziplist最后一个节点的偏移量,在反向遍历ziplist或者pop尾部节点的时候有用
3、zllen:表示当前ziplist中元素个数,即entry数量
4、zlend:表示ziplist结尾,值恒为1111 1111
5、entry:
- prevlengh:记录上一个节点的长度,为了方便反向遍历ziplist
- len:当前节点长度
- data:当前节点的值,可以是数字或字符串
2、quicklist
下图为Redis中list的整体结构。
其中quicklist的作用仅仅是将众多的ziplist串联起来,将每一个ziplist视为一个quicklistNode,quicklist中还包含node的头节点、node的尾节点、node的数量、list的长度等信息
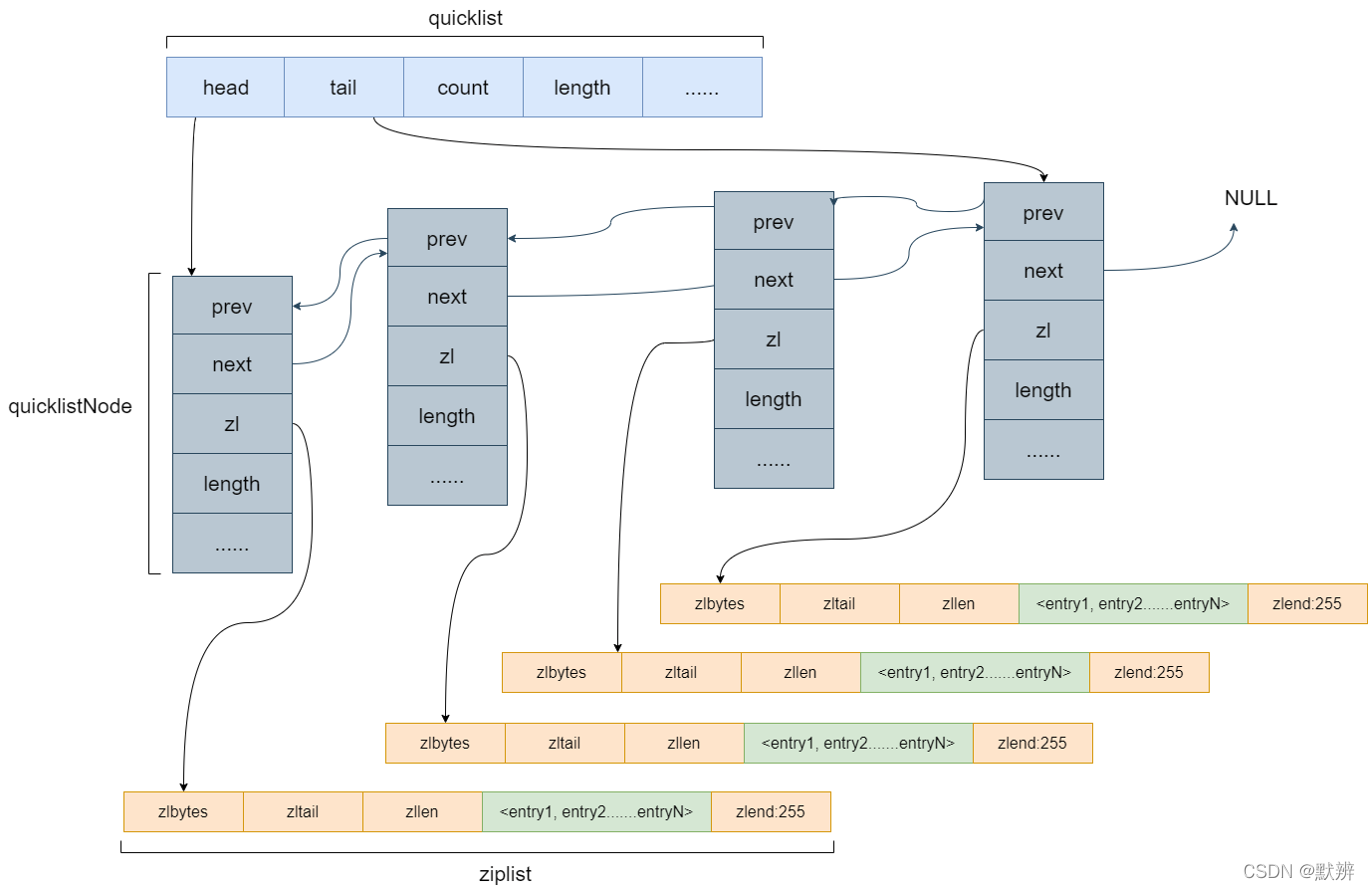
即最终出现的现象就是,当数据到达一定的大小后,就会新生成一个quicklistNode节点,这样的好处是,即包含了类似数组的效果(单个node节点内数据查询效率高,且节省空间),又包含了类似链表的效果(多个node之间互不干扰,增删成本低)。
当然我们还可以对list进行相关的优化
1、设置单个节点数据存储的大小:list-max-ziplist-size -2,单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中

2、设置node节点内部数据的压缩:list-compress-depth:0代表所有节点,都不进行压缩;1代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩;2,3,4 … 以此类推

三、Hash
Hash 数据结构底层实现为一个字典( dict ),也是RedisBb用来存储K-V的数据结构,当数据量比较小,或者单个元素比较小时,底层用ziplist存储,数据量超过一定的阈值就会使用hashtable进行存储。
hash底层结构如下图:

entry节点中data对应的数据为:
- entry1:entry2 = name :mobian
- entry3:entry4 = age:23
- entry5:entry6 = hobby:girl
1、ziplist
当hash存储的数据较小时,其底层使用的是ziplist进行存储,参考list中对ziplist结构的讲解,ziplist内部的entry节点是连续的内存空间,所以此时的hash是有序的
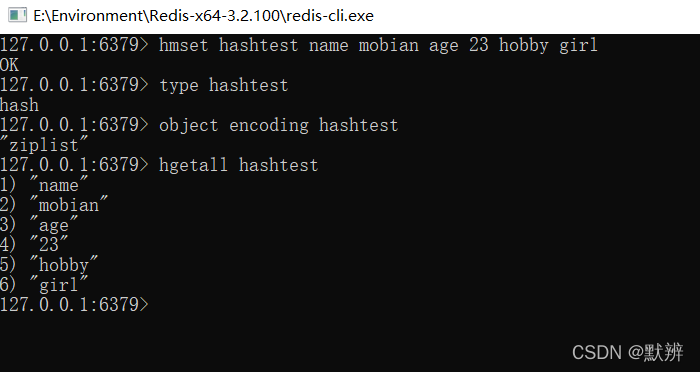
2、hashtable
当我们添加一个较大的数据yyy…后,此时hash数据类型的底层编码变成了hashtable,并且对应的数据也变成了无序。这个很好理解,因为hash值是无序的,自然我们之前使用ziplist存放的有序的数据也就被打乱了。
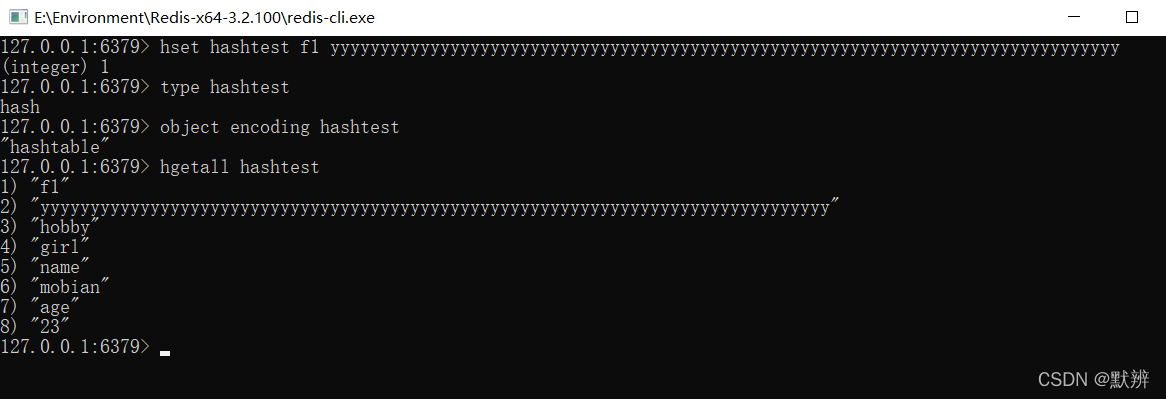
使用hash这种基本数据类型时,数据大小和元素数量阈值可以通过如下参数设置
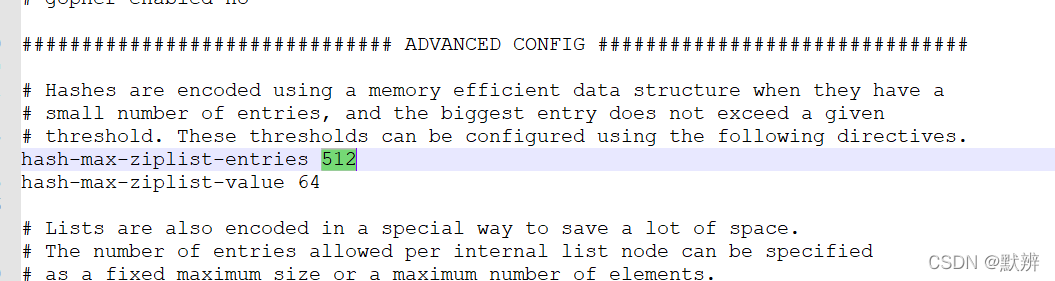
3、string和hash的使用取舍
Redis中所有的数据最终都是封装为一个redisObj对象,并且这些对象是以散列表的形式进行存放。如果使用string类型去替代hash类型进行数据的存放,hash中众多的entry很快就会让这个散列表的key产生冲突,以至于引发扩容,影响效率;如果使用hash结构,就只会占用一个key,而对应的value才是具体hash的内部键值对。
当然我们也应该明白,使用string的优势在于string类型api丰富,如可以设置对应key的过期时间,对应放在hash中的key-value是无法设置过期时间的。
四、Set
Set 为无序的,自动去重的集合数据类型,Set 数据结构底层实现为一个value 为 null 的字典( dict ),当数据可以用整形表示时,Set集合将被编码为intset数据结构。其底层结构参考hash的结构图
两个条件任意满足时,Set将用hashtable存储数据:
- 元素个数大于 set-max-intset-entries 512 (配置文件中可以设置)
- 元素无法用整形表示
对应的转换规则可以参考hash结构
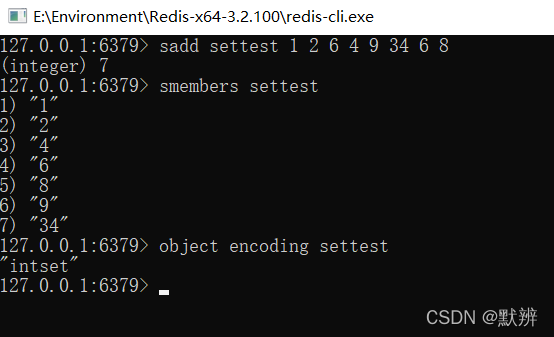
1、intset
数据能够使用整形表示,自动去重且按照顺序进行排列
整数集合是一个有序的,存储整型数据的结构。整型集合在Redis中可以保存int16_t,int32_t,int64_t类型的整型数据,并且可以保证集合中不会出现重复数据。如下图
2、hashtable
与hash相同,int类型无法满足数据存放时,数据的底层编码会修改为hashtable,以至于数据变得无序
五、ZSet
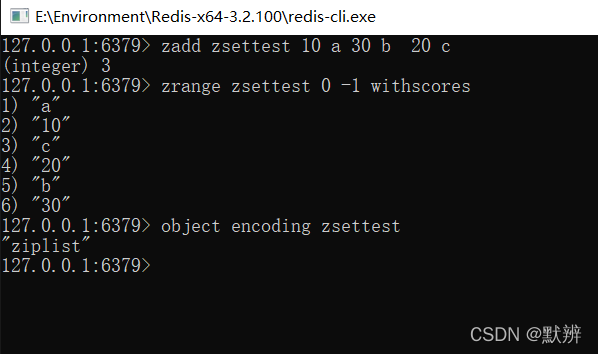
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist),当数据比较少时,用ziplist编码结构存储。
当数据满足下列条件时,底层编码格式会由ziplist转化为skiplist,对应的参数同样也是维护在配置文件中
1、ziplist
此时数据较小,zset底层使用ziplist进行编码
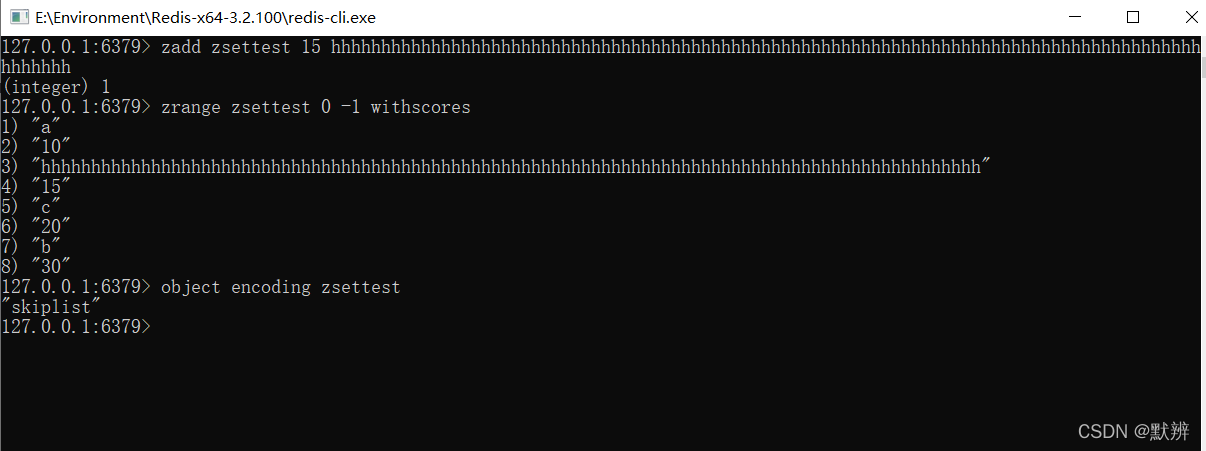
2、skiplist
当我们的member元素(分数score可以重复,成员member不能重复)大小超过64byte底层编码格式将由ziplist转变为skiplist。即配置文件中zset-max-ziplist-value 指代的大小是member的大小
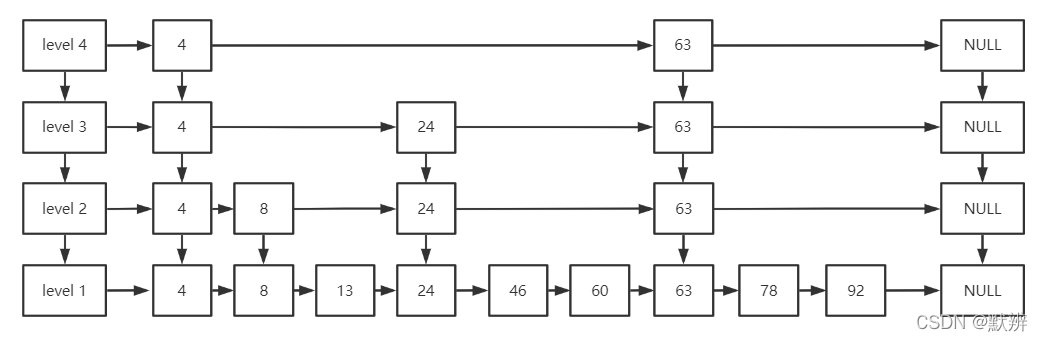
Redis中的skiplist是基于跳表的基础上改变而来。下图为skiplist跳表的基本结构,其基本结构大致为:
- 含有一个整体的索引层级,类比二叉树中的树的高度
- 每一列都是相同且重复的数据
- 其查找特点,有点类似于二分查找的结构。如一个45数字,他在第四层会判断出在4-63之间,第三层会判断出在24-63之间,第二层无法判断,第一层会判断出在24-46之间。
Redis中zset底层的skiplist在原本的skiplist的基础上,使用一个节点将跳表第一层的数据串联起来。在该节点中包含了所有的节点个数、索引的层数、头节点、为节点,即如下的结构体。具体的代码在后面源码步骤中会再次提及。
3、zadd源码流程
客户端执行zadd zsettest score member命令后
1、server.c文件中的zaddCommand命令开始,它会直接调用到t_zset.c的zaddGenericCommand函数
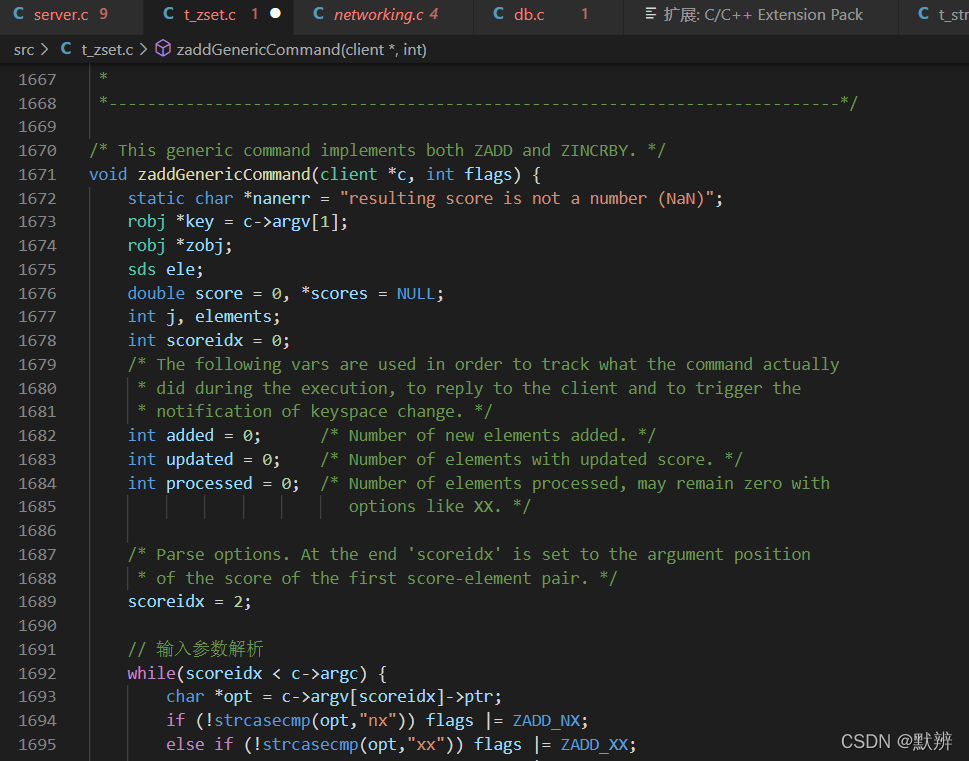
2、判断当前的key是否存在,不存在则创建对应的节点
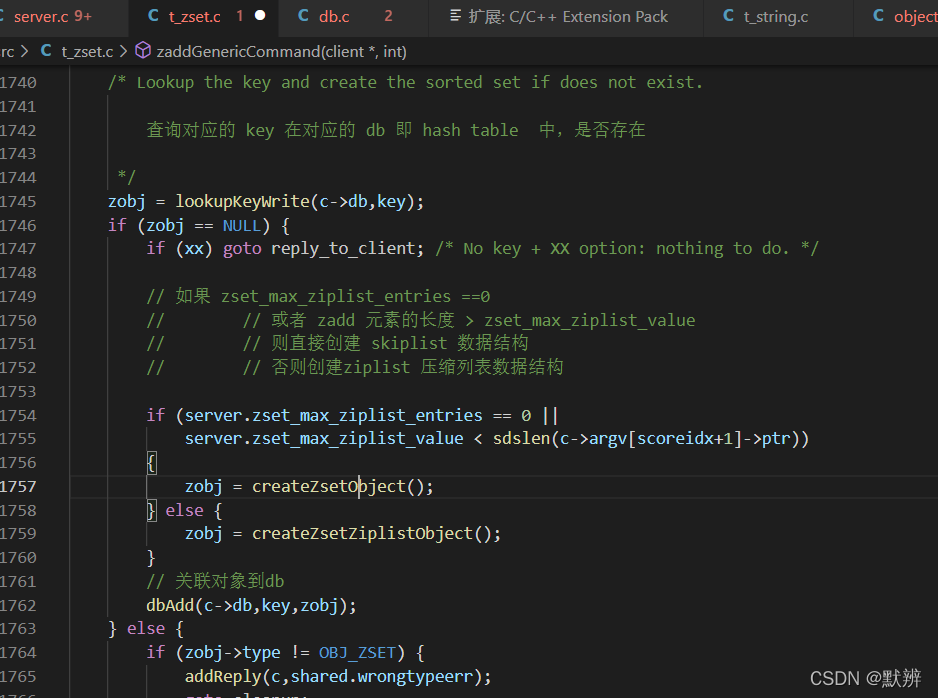
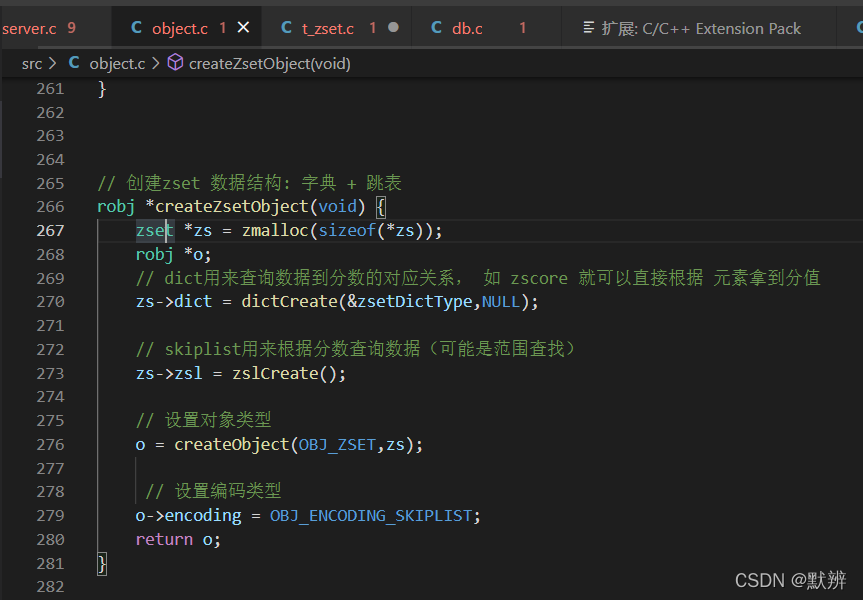
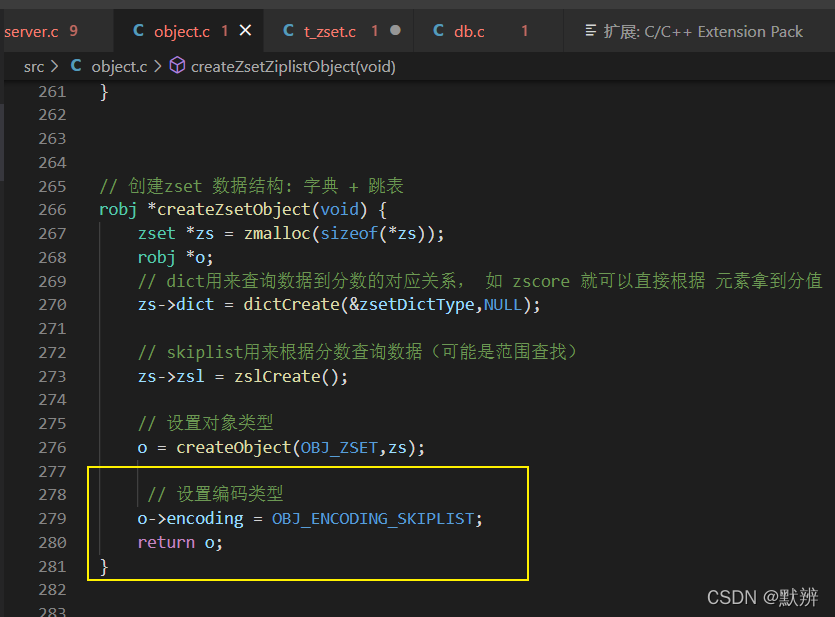
补充创建节点createZsetObject函数相关细节:
1)初始化zset结构体(内部包含dict和zskiplist结构,dict就是整个数据结构,其内部包含两个dictEntry,dictEntry就是我们一个key-value节点集合体)
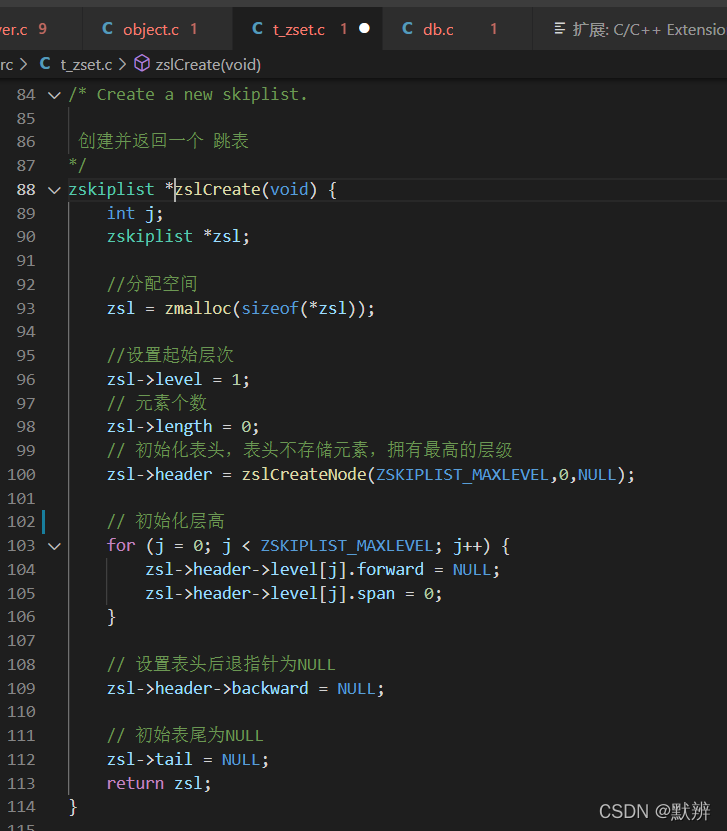
2)初始化skiplist内部结构
3)创建节点对象,即创建redisObject对象,完成相关参数的定义
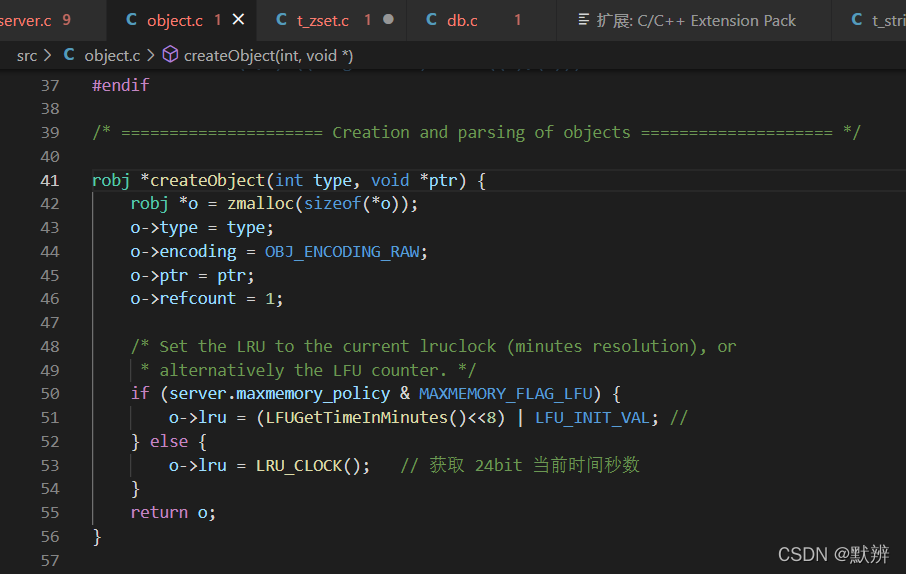
3)设置redisObj的编码格式
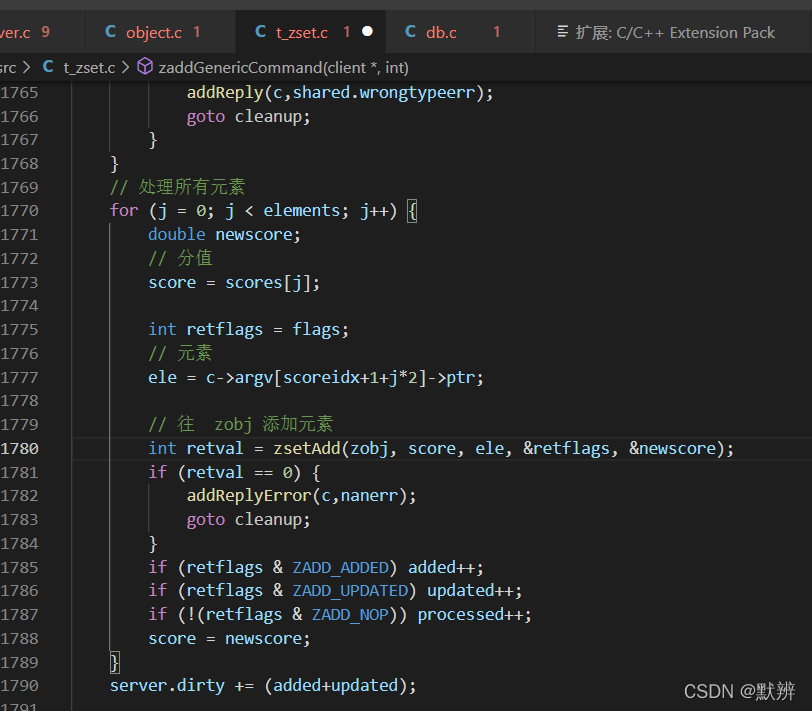
3、向zset中添加创建出来的redisObj,即调用zsetAdd函数
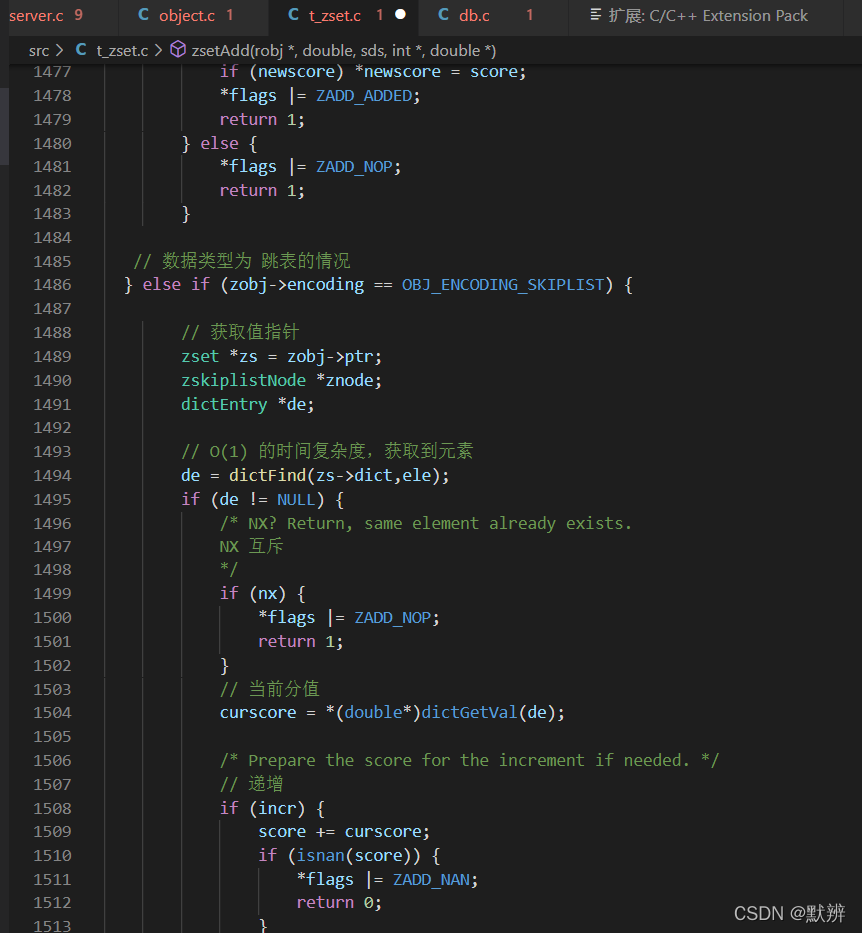
4、在zsetAdd函数内部会判断,会根据zset的编码格式,进入不同的判断。下图为skiplist类型时的逻辑
4、geospatial
geospatial底层是由zset基本数据结构实现
更细节的讲解可以参考别人的文章,我觉得很不错:Geohash算法原理及实现、Geohash原理
GeoHash是一种地理位置编码方法。 由Gustavo Niemeyer 和 G.M. Morton于2008年发明,它将地理位置编码为一串简短的字母和数字。它是一种分层的空间数据结构,将空间细分为网格形状的桶,这是所谓的z顺序曲线的众多应用之一,通常是空间填充曲线。
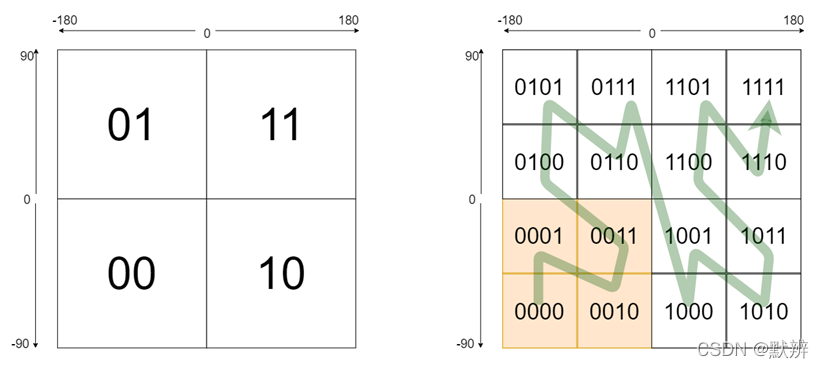
经度范围是东经180到西经180,纬度范围是南纬90到北纬90,我们设定西经为负,南纬为负,所以地球上的经度范围就是[-180, 180],纬度范围就是[-90,90]。如果以本初子午线、赤道为界,地球可以分成4个部分。
如果纬度范围[-90°, 0°)用二进制0代表,(0°, 90°]用二进制1代表,经度范围[-180°, 0°)用二进制0代表,(0°, 180°]用二进制1代表,那么地球可以分成如下4个部分。以此类推,每一块区域再次4等分
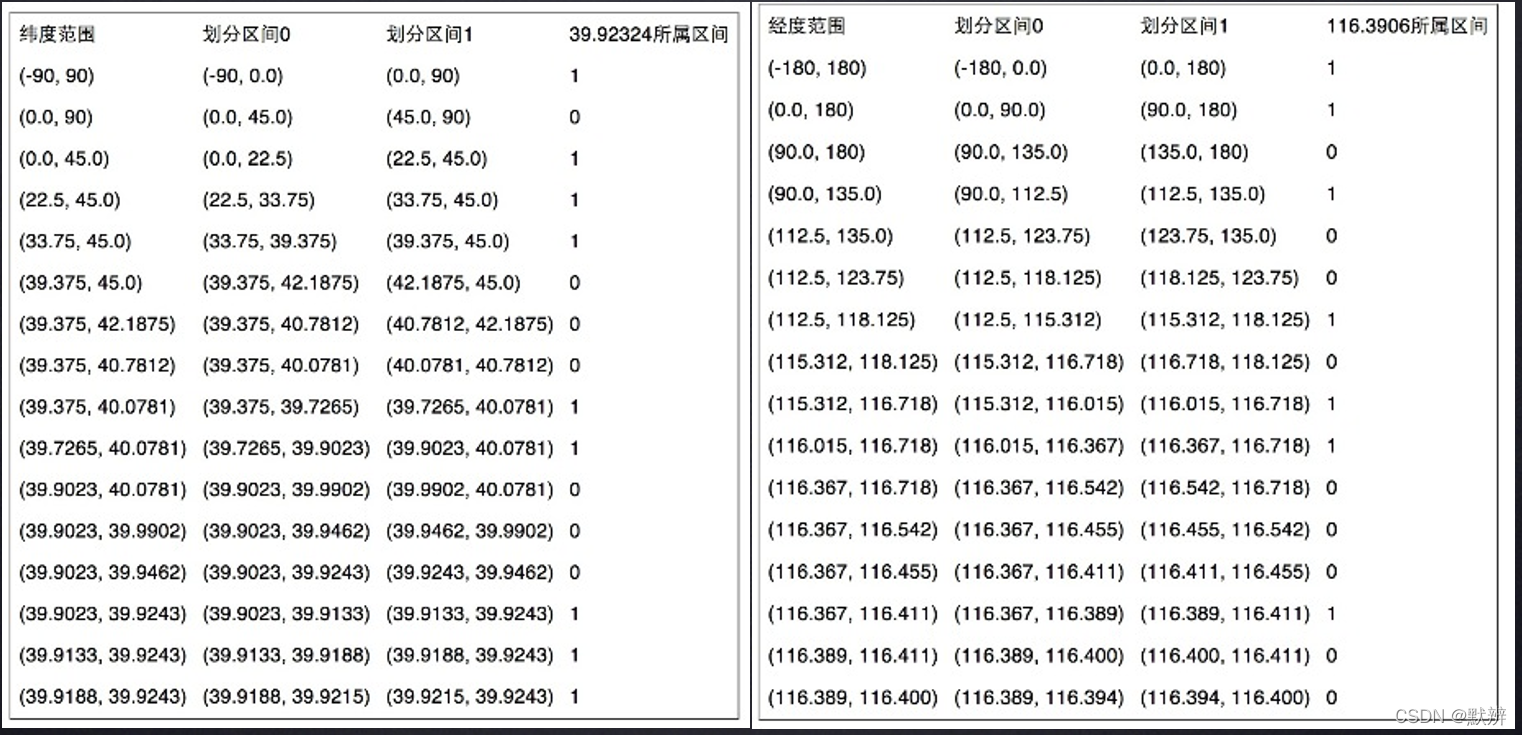
1、以东经116.3906,南纬39.92324为例,下图为将坐标按照单一维度进行定位的图示,结合两张图,即一个横坐标,一个纵坐标配合起来看,最终对应的位置对应的二进制为:11100 11101 00100 01111 00000 01101 01011 00001
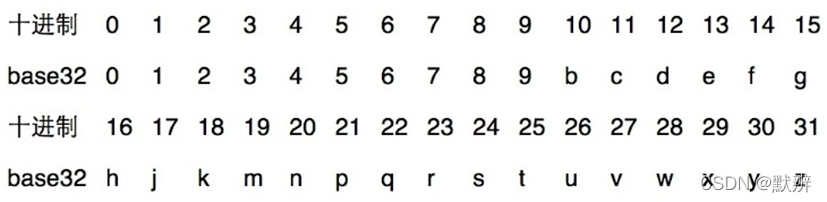
2、最后使用用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,首先将11100 11101 00100 01111 00000 01101 01011 00001按照五位一组,转成十进制 28,29,4,15,0,13,11,1,十进制再转化为对应的base32的编码,即wx4g0ec1。
3、wx4g0ec1。然后将两个不同地点的经纬度转换的base32字符串进行比较,算出两者之间的距离
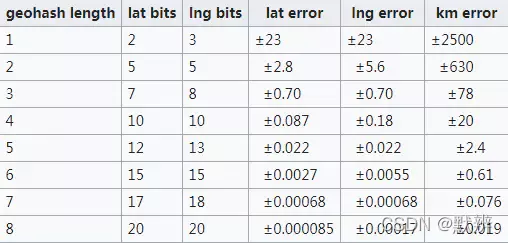
优点:GeoHash利用Z阶曲线进行编码,Z阶曲线可以将二维所有点都转换成一阶曲线。地理位置坐标点通过编码转化成一维值,利用 有序数据结构如B树、SkipList等,均可进行范围搜索。因此利用GeoHash算法查找邻近点比较快
缺点:Z 阶曲线有一个比较严重的问题,虽然有局部保序性,但是它也有突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |