

Bugku题目——抄错的字符
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
描述:
老师让小明抄写一段话,结果粗心的小明把部分数字抄成了字母,还因为强迫症把所有字母都换成大写。你能帮小明恢复并解开答案吗:QWIHBLGZZXJSXZNVBZW
根据提示,需要恢复原来的字符串才行。首先是数字转数字的:
1 : l(小写L)、I(大写i)
2 : Z/z
5 : S/s
8 : B
9 : g
0 : O/o大概就是以上的情况,然后就是大小写的转换。分析完毕后发现这并不是什么明文,有点像Base64。简单尝试一下发现可行。写exp如下:
from base64 import b64decode
from string import printable
#字母数字对应表
Numlist = {'i': '1', 'l': '1', 'z': '2', 's': '5', 'g': '9', 'o': '0'}
#分割字符串
def cut(obj, sec):
return [obj[i:i + sec] for i in range(0, len(obj), sec)]
#使用递归将字符串还原回所有可能的结果
def decode(str):
res = []
if len(str) > 1:
relist = decode(str[1:])
Rlist = decode(str[0])
for i in Rlist:
for j in relist:
res.append(i + j)
else:
res.append(str[0].lower())
res.append(str[0].upper())
if str[0].lower() in Numlist:
res.append(Numlist[str[0].lower()])
return res
#判断base解码后是否是正常的字符
def isbase(str):
res = b64decode(str)
for i in res:
if i not in printable.encode():
return False
return True
if __name__ == '__main__':
enstr = 'QWIHBLGZZXJSXZNVBZW'
#base64可以切片分别解码,减少运算数量
enlist = cut(enstr, 4)
flag = []
for i in enlist:
delist = decode(i)
f = []
for base in delist:
base += '=' * (4 - len(base)) #填充=
if isbase(base):
print(base, end=',')
f.append(b64decode(base).decode())
flag.append(f)
print()
print()
for i in flag:
print(i)运行结果如下:
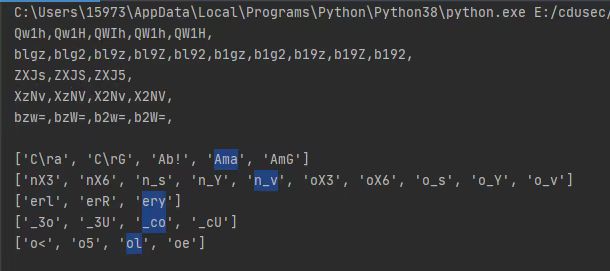
根据题目作者名字(Aman)和正确单词拼写,构成正确的flag
Aman_very_cool
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |