

2022年第三届MathorCup高校数学建模挑战赛——大数据竞赛 赛道B 北京移动用户体验影响因素研究 问题二建模方案及代码实现详解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
2022年第三届MathorCup高校数学建模挑战赛——大数据竞赛 赛道B 北京移动用户体验影响因素研究 建模方案及代码实现

更新进展
2022年12月21日 12:20 发布问题一、二思路及问题一的python代码实现
2022年12月22日 15:00 发布问题二python实现的代码
更新完毕
相关链接
1 题目
移动通信技术飞速发展给人们带来了极大便利人们也越来越离不开移动通信技术带来的各种便捷。随着网络不断的建设网络覆盖越来越完善。各个移动运营商越来越重视客户的网络使用体验从而进一步提升网络服务质量。 客户满意度是客户对运营商产品服务的满意程度反映了客户期望与实际感知的产品服务之间的差异。特别是在信息透明、产品同质化的今天 客户满意度的表现成为各大运营商市场运营状况的重要体现。数字经济时代各大运营商需要运用数字经济的管理理念和技术手段建立客户体验生态的全方位系统性测评体系实现客户满意度评测的数字化转型让客户体验赋能商业决策让商业决策真正服务客户共同推动移动网络高质量可持续发展。 根据客户投诉对影响用户体验的问题逐点解决是传统提升客户满意度的方法。但是随着用户数量的大幅增加移动产品的种类越来越丰富 客户的需求越来越高传统的方法已经难以有效提升客户的满意度。本研究拟通过分析影响用户满意度的各种因素为决策提供依据从而实现更早、更全面提升用户满意度。 中国移动通信集团北京公司让客户根据自身在网络覆盖与信号强度、语音通话清晰度和语音通话稳定性三个方面的体验进行打分同时还让客户根据语音通话的整体体验进行语音通话整体满意度的打分并统计整理影响客户语音业务体验的因素希望以此来分析客户语音业务满意度的主要影响因素并提升客户语音业务满意度。同时对于上网数据业务中国移动北京公司让客户根据自身在网络覆盖与信号强度、手机上网速度、手机上网稳定性三个方面的体验进行打分同时还让客户根据手机上网的整体体验进行手机上网整体满意度的打分并统计整理影响客户上网体验的因素希望以此可以分析影响客户上网业务体验的主要因素并提升客户的上网体验。
初赛问题 基于以上背景请你们的团队根据附件给出的数据通过数据分析与建模的方法帮助中国移动北京公司解决以下问题
问题 1根据附件 1 和附件 2分别研究影响客户语音业务和上网业务满意度的主要因素并给出各因素对客户打分影响程度的量化分析和结果。附件 1、2 中各字段的解释说明见附件 5。
问题 2结合问题 1 的分析对于客户语音业务和上网业务分别建立客户打分基于相关影响因素的数学模型并据此对附件 3、4 中的客户打分
进行预测研究将预测结果分别填写在result.xlsx 的Sheet1“语音”和Sheet2“上网”两个工作表中并上传到竞赛平台说明你们预测的合理性。
附件
附件 1 语音业务用户满意度数据 附件 2 上网业务用户满意度数据 附件 3 语音业务用户满意度预测数据 附件 4 上网业务用户满意度预测数据附件 5 附件 1、2、3、4 的字段说明result.xlsx
2 思路分析
2.1 问题一
这是相关性分析问题分别对附件1和附件2计算所有因素与语音通话整体满意度和手机上网整体满意度的相关性。首先对数据集进行数据预处理和数据可视化分析具体的分析过程看以下 部分python代码实现。查看异常值去除异常值查看数据分布对分布进行抓换等处理。预处理完毕后采用的相关性分析方法有
- Pearson相关
Pearson相关用于评估两个连续变量之间的线性关联强度。这种统计方法本身不区分自变量和因变量但如果您根据研究背景已经对变量进行了区分我们仍可以采用该方法判断相关性。
- Spearman相关
Spearman相关又称Spearman秩相关用于检验至少有一个有序分类变量的关联强度和方向。
- Kendall’s tau-b相关系数
Kendall’s tau-b 相关系数是用于检验至少有一个有序分类变量关联强度和方向的非参数分析方法。该检验与Spearman相关的应用范围基本一致但更适用于存在多种关联的数据如列联表。
- 卡方检验
卡方检验常用于分析无序分类变量之间的相关性也可以用于分析二分类变量之间的关系。但是该检验只能分析相关的统计学意义不能反映关联强度。因此我们常联合Cramer’s V检验提示关联强度。
- Fisher精确检验
Fisher精确检验可以用于检验任何RC数据之间的相关关系但最常用于分析22数据即两个二分类变量之间的相关性。与卡方检验只能拟合近似分布不同的是Fisher精确检验可以分析精确分布更适合分析小样本数据。但是该检验与卡方检验一样只能分析相关的统计学意义不能反映关联强度。
2.2 问题二
这是一个多分类问题1-10的评分10分类问题。简单的机器学习问题。首先数据预处理包括缺失值处理、异常值处理、类别特征编码label 采用onehot编码或者数值编码。接下来是特征工程特征工程的方法有特征筛选、特征降维、特征交叉、特征标准化或归一化等等。接下来选择常用的机器学习分类模型
- 1.KNN
- 2.感知机
- 3.朴素贝叶斯法
- 4.决策树
- 5.逻辑斯谛回归模型*
- 6.SVM
- 7.AdaBoost
- 8.随机森林
- 9.XGB
- 10.LGB
XGB、LGB一般效果更好。此比赛时间充足可以多对比几种模型看实验效果。此外还可以采用神经网络分类模型耗时较长效果更佳。
3 问题二python代码实现
3.1 读取数据
import datetime
import numpy as np
import pandas as pd
import numpy as np
from tqdm import tqdm
tqdm.pandas()
file1 = pd.read_excel('./data/附件1语音业务用户满意度数据.xlsx')
clear_file1=file1[(file1['语音通话整体满意度']<=10) & (file1['语音通话整体满意度']>=1)]
label = clear_file1['语音通话整体满意度']
3.2 数据预处理
用户描述,用户描述.1,重定向次数,重定向驻留时长 ,是否关怀用户,是否去过营业厅列这些列缺失值太多直接删除。
clear_file1_1 = clear_file1.drop(columns=['语音通话整体满意度','用户描述','用户描述.1','重定向次数','重定向驻留时长','是否关怀用户','是否去过营业厅'])
clear_file1_1
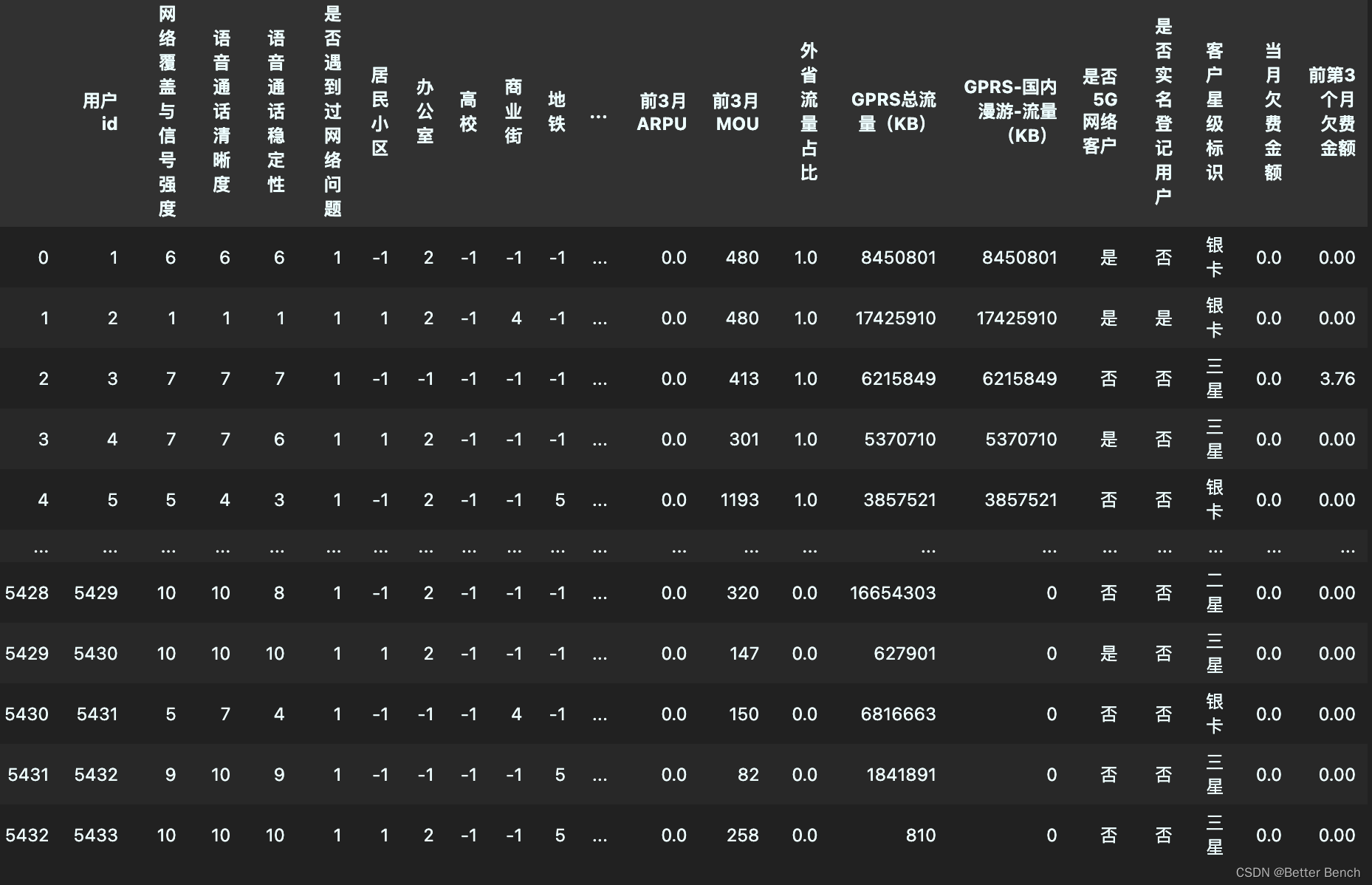
异常值填充,类别特征用众数填充数值特征用平均值填充
是否4G网络客户本地剔除物联网,终端品牌,终端品牌类型,外省流量占比,是否5G网络客户,是否实名登记用户,客户星级标识,当月欠费金额,前第3个月欠费金额
for s in ['是否4G网络客户本地剔除物联网','终端品牌','终端品牌类型','外省流量占比','是否5G网络客户','是否实名登记用户','客户星级标识','当月欠费金额','前第3个月欠费金额']:
if clear_file1_1[s].dtype==object:
fill_none = clear_file1_1[s].value_counts().index[0]
else:
fill_none = np.mean(clear_file1_1[s])
clear_file1_1[s] = clear_file1_1[s].fillna(fill_none)
clear_file1_1.isnull().any()

3.3 特征工程
3.3.1 特征交叉
统计类别特征和数值特征
cross_cat = []
cross_num = []
for s in clear_file1_1.columns:
if clear_file1_1[s].dtype==object or clear_file1_1[s].dtype==int:
cross_cat.append(s)
else:
cross_num.append(s)
cross_cat

将类别特征编码
clear_file1_2 = clear_file1_1.copy()
for s in clear_file1_2.columns:
if clear_file1_2[s].dtype==object:
class_mapping = {label:idx+1 for idx,label in enumerate(set(clear_file1_2[s]))}
clear_file1_2[s] = clear_file1_2[s].map(class_mapping)
定义交叉特征统计
def cross_cat_num(df, num_col, cat_col):
for f1 in tqdm(cat_col):
g = df.groupby(f1, as_index=False)
for f2 in tqdm(num_col):
。。。略
df = df.merge(feat, on=f1, how='left')
return(df)
data = cross_cat_num(clear_file1_2, cross_num, cross_cat) # 一阶交叉
data.shape
3.3.2 特征降维
步骤一根据与满意度打分的相关性筛选性相关性高的特征
tmp_train = data.copy()
tmp_train['语音通话整体满意度'] = label
col_list = tmp_train.columns.tolist()
mcorr = tmp_train[col_list].corr().abs()
tt = mcorr['语音通话整体满意度'] > 0.2
new_col = list(tt[tt == True].index)
new_col.remove('语音通话整体满意度')
clear_dataset_df1 = data[new_col].copy()
clear_dataset_df1['语音通话整体满意度'] = label
clear_dataset_df1.to_csv('data/clear_file1.csv',index=False)
len(new_col)
将清洗后的数据集存储起来
clear_dataset_df1 = data[new_col].copy()
clear_dataset_df1['label'] = label
clear_dataset_df1.to_csv('data/clear_file1.csv',index=False)
3.4 模型训练
划分训练集和测试集
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
df = pd.read_csv('data/clear_file1.csv')
Y = df['label']
X = df.drop(columns=['label'])
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=42)
scaler = StandardScaler()
train_X = scaler.fit_transform(X_train)
test_X = scaler.transform(X_test)
XGB分类模型
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.metrics import accuracy_score
import xgboost as xgb
from xgboost import plot_importance
from sklearn import metrics
import warnings
warnings.filterwarnings("ignore")
model = xgb.XGBClassifier(learning_rate=0.01,
n_estimators=10, # 树的个数-10棵树建立xgboost
max_depth=4, # 树的深度
min_child_weight = 1, # 叶子节点最小权重
gamma=0., # 惩罚项中叶子结点个数前的参数
subsample=1, # 所有样本建立决策树
colsample_btree=1, # 所有特征建立决策树
scale_pos_weight=1, # 解决样本个数不平衡的问题
random_state=27, # 随机数
slient = 0
)
model.fit(train_X,y_train)
y_pred = model.predict(test_X)
print("Accuracy : %.4g"%accuracy_score(y_test, y_pred))
输出Accuracy : 0.7724
预测附件3并存储为csv文件
test_df = pd.read_csv('data/clear_file3.csv')
y_pred = model.predict(test_df)
pd.DataFrame(y_pred).to_csv('result_1.csv',index=False)
同理对附件2和附件4进行处理附件4预测结果存储为result_2.csv最后合并两个csv为result.xlsx。
对附件2 的代码在下载内容中不再在文章中展示。
4 两问代码及图片下载
# https://www.betterbench.top/#/17/detail