

windows下实现对chatGLM-6B的微调
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1、前言
默认读者已成功部署chatGLM-6B,如果没有部署完毕请参阅下列文章同为笔者所写
https://blog.csdn.net/Asunazhang/article/details/130094252?spm=1001.2014.3001.5502
2、软件依赖
打开cmd切换至虚拟环境调用下列代码安装依赖。
pip install rouge_chinese nltk jieba datasets
3、使用方法
3.1 下载数据集
从
https://link.zhihu.com/?target=https%3A//cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/%3Fdl%3D1
下载处理好的 ADGEN 数据集将解压后的 AdvertiseGen 目录放到本目录下。如下图所示。
3.2 训练
windows下需要读者安装git 。如何安装请自行bing。记得把git写入环境变量。
如果跟我一样用的是虚拟环境请在虚拟环境下也安装一个git。
当git成功安装后你就可以在windows命令行执行.sh文件了。
那么在训练前打开chatGLM文件夹在进入ptuning文件夹右键train.sh打开方式选择记事本你会看到train.sh中含有下图所示的文件。
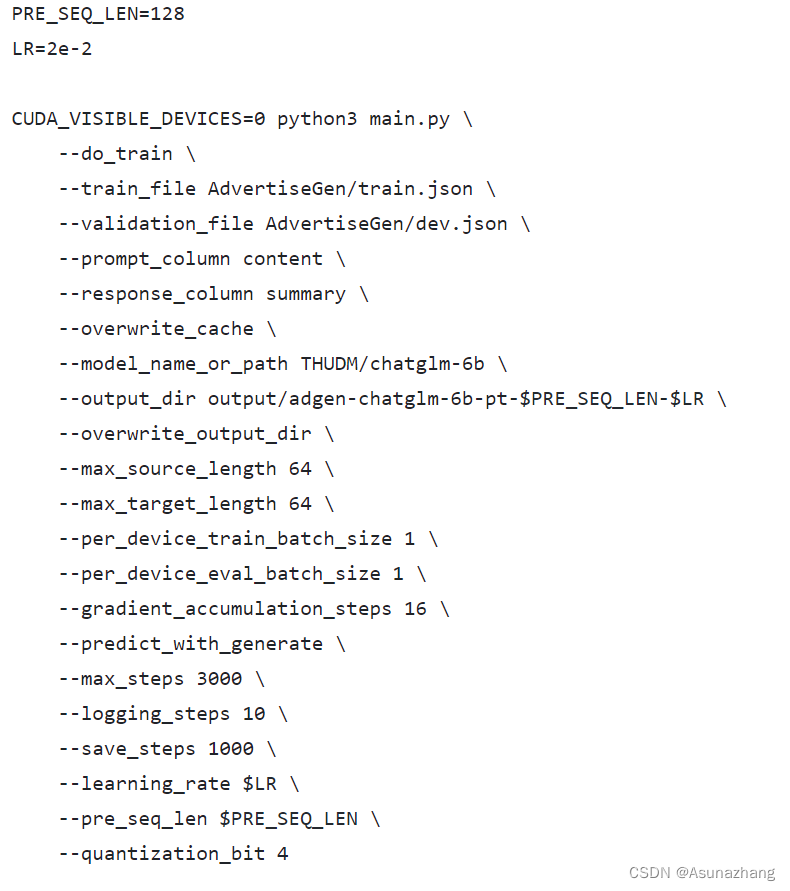
参数含义
PRE_SEQ_LEN 预序列长度
LR 学习率
do_train 是否进行训练
do_eval 是否进行预测
train_file 训练文件相对地址
validation_file 验证文件相对地址
prompt_column prompt 提示信息字段
response_column 响应信息字段
overwrite_cache 重写数据集缓存。
model_name_or_path 模型名称或模型地址
output_dir 训练好的模型保存的地址
per_device_train_batch_size 每个设备上的训练批次大小 在实际的训练过程中3090显卡可以把这个参数开到4。
之后修改train.sh中的文件。
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
还需要修改
--model_name_or_path ../model \
如果你的项目目录和我相同那么使用…/退出即可寻找到modelmodel里存放的是模型。如果此处报错那你也可选择默认路径但是要注意确保你的C盘有20G的余量下载模型。
此外如果你在执行bash操作时没有错误信息也没有执行代码直接跳转到下一次输入可以尝试将python3 main.py中的3去掉。
笔者就因为这个python3 找错找了5个小时。
当训练开始后如果你是默认Int4精度官方文档给出的代码需要跑4个小时3090ti如果是半精度那么需要11个小时。就笔者情况来看目前只有这两种方式可调。具体修改精度方式为打开train.sh如果你需要修改为半精度那么将最后一行注释掉即可。同时上文也提到在大于3090显卡上可以将per_device_train_batch_size参数开到4。
3.3 推理
同样需要修改文件。
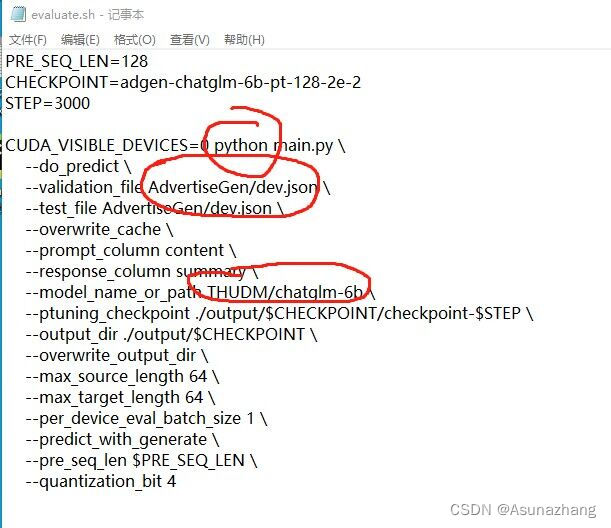
笔者需要修改python3 -->python
如果训练时选择默认Model_name_or_path那么不需要修改。如果修改model路径请选择和训练时相同的路径。
最后同样是–quantization_bit4 看个人情况修改。
之后在quantization_bit4 的情况下你大约需要推理1个小时。
4、验证
之后你就可以启动你的chatGLM。笔者在经过这一系列微调后最终实现的效果如下图

那么至此chatGLM_6B的官方文档微调已经实现。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |