

Redis基本命令和常用数据类型-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
前言
Redis基本命令和常用数据类型String、List、Set、Hash、Zset、Geospatial、Hyperloglog。
一、Redis简介
RedisRemote Dictionary Server )即远程字典服务。
Redis 是一个开源BSD 许可内存数据结构存储用作数据库、缓存、消息代理和流引擎。Redis 提供数据结构例如字符串、哈希、列表、集、带有范围查询的排序集、位图、超日志日志、地理空间索引和流。 Redis 具有内置复制、Lua 脚本、LRU 逐出、事务和不同级别的磁盘持久性并通过 Redis Sentinel 和 Redis 集群的自动分区提供高可用性。
Redis是单线程的
官方表示Redis是基于内存操作CPU不是Redis性能瓶颈Redis的瓶颈是根据机器的内存和网络带宽既然可以使单线程就使用单线程了。Redis是C语言写的官方提供的数据为100000+QPS完全不比同样使用key-value的Memecache差
Redis为什么单线程还这么快
1、误区1高性能的服务器其一定是多线程的
2、误区2多线程会发生CPU上下文交换一定比单线程效率高
核心Redis是将所有的数据全部放在内存中的所有说使用单线程去操作是最高的多线程CPU上下文会切换耗时的操作对于内存系统来说如果没有上下文切换效就是最高的多次读写都在一个CPU上的在内存情况下这个就是最佳方案。
NoSQL
NoSQLNot Only SQL即不仅是SQL泛指非关系型数据库。
NoSQL 易扩展NoSQL 数据库种类繁多MongoDB、Redis 等共同的特点都是去掉关系数据库的关系型特性。
数据之间无关系这样就非常容易扩展无形之间也在架构的层面上带来了可扩展的能力。
大数据量下 NoSQL 数据库具有非常高的读写性能这得益于它的无关系性数据库的结构简单。
NoSQL 数据库的典型代表就是 Redis。
二、基本操作
1.赋值
set key value

2.取值
get key

3.切换数据库
- Redis 默认有 16 个数据库。
- 默认使用的是第 0 个数据库。
- 不同数据库存不同的值。
select
切换到数据库1

这个数据库0
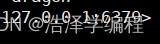
上面讲诉赋值操作我们在数据库0中已经赋值dragon在数据库1中是没有的

4.查看数据库所有键key
keys *

5.查看键值类型
type key
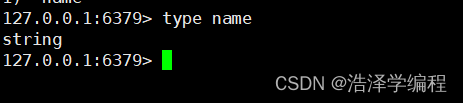
6.移动键值到其他数据库
move key 是数据库编号
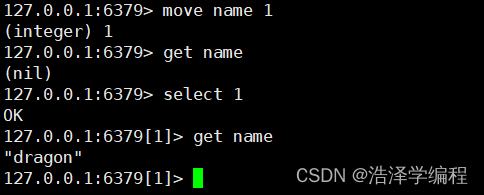
将数据库0中的name移到数据库1中
7.设置键值生存时间两种
expire key 时间
setex 键名称 生存时间 值
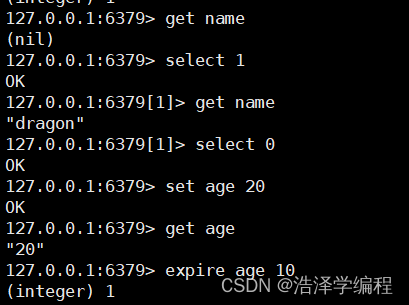

这里是设置10秒生存时间。
8.查看键值生存时间
ttl key
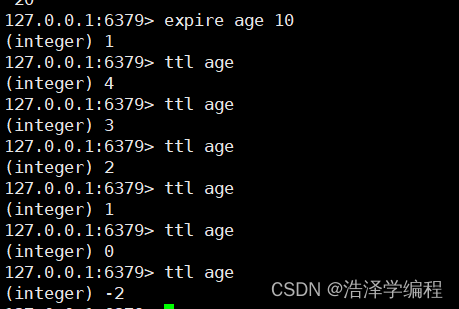
上面设置的生存时间用ttl查看-2说明已经过期。我输入命令查看的时候耽误了一些时间所以最开始是还剩4秒生存时间
9.查看当前数据库大小
dbsize
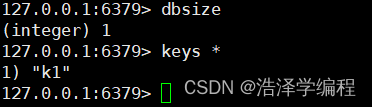
代码中就k1一个元素所以数据库大小为1
10.判断键是否存在
exists key
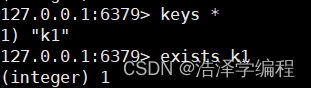
11.清空当前数据库
flushdb
12.清空所有数据库
flushall
三、常用数据类型
1.String字符串
1赋值
set key name
2取值
get key
3同时获取多个值
mset key1 key2…
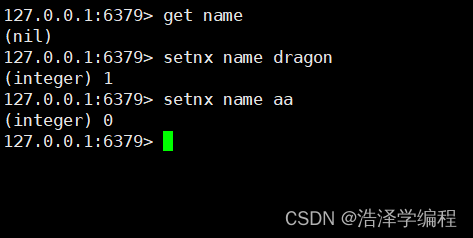
4不存在才赋值
setnx key value
5批量赋值
mset key1 value1 key2 value2…
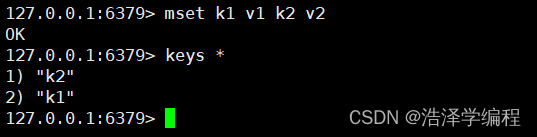
有一个赋值出错不会影响其他的赋值
6原子性批量赋值
msetnx k1 v1 k2 v2 k3 v3…
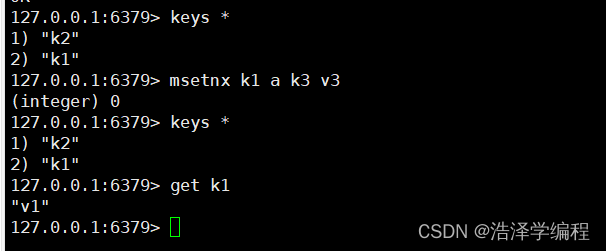
7追加字符串
如果当前字符串不存在则相当于set key
append key value
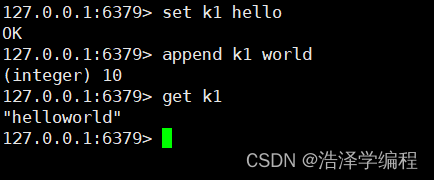

8获取字符串长度
strlen key
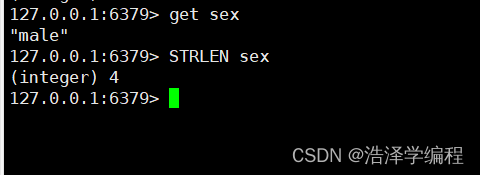
9获取指范围字符串
getrange key start end
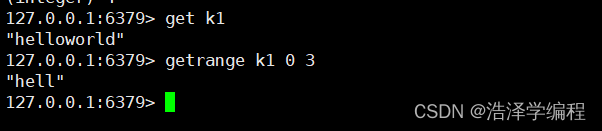 >
>
getrange key 0 -1相当于get key

10替换指定位置开始往后n位字符串
setrange key start value
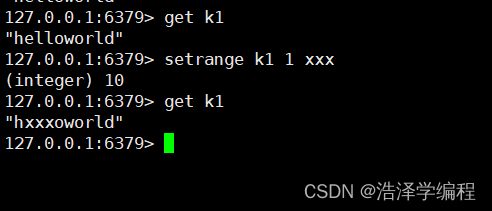
11设置对象
set 对象
两种


12先get后set
getset key value
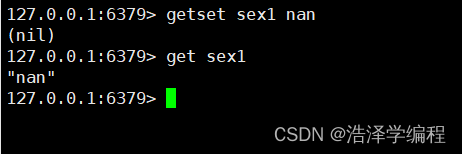
nil说明没有这个key所以直接赋值
13自增+1
incr key
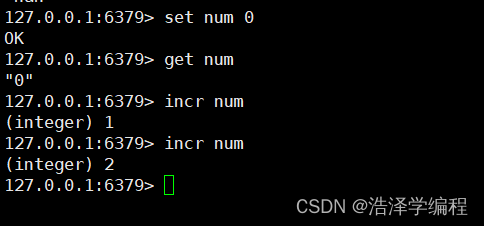
14指定步长增加
incrby key 数字
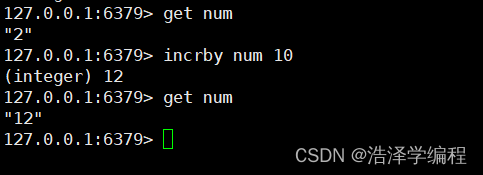
15递减和指定步长减少
decr
decrby
2.list
在Redis里面我们可以把lis玩成栈、队列、阻塞队列。
lis命令都是以 l 开。
list 实际是一个链表左右都可以插入值。
如果 key 不存在创建新的链表。
如果移除了所有元素空链表也代表不存在。
在两边插入或者改动值效率最高操作中间元素效率相对低一些。
应用场景消息排队
1插入
LPUSH 从左边插入一个或多个值
RPUSH 从右边插入一个或多个值
LINSERT 名称 before/after value1 vlaue2 在value1前插入value2
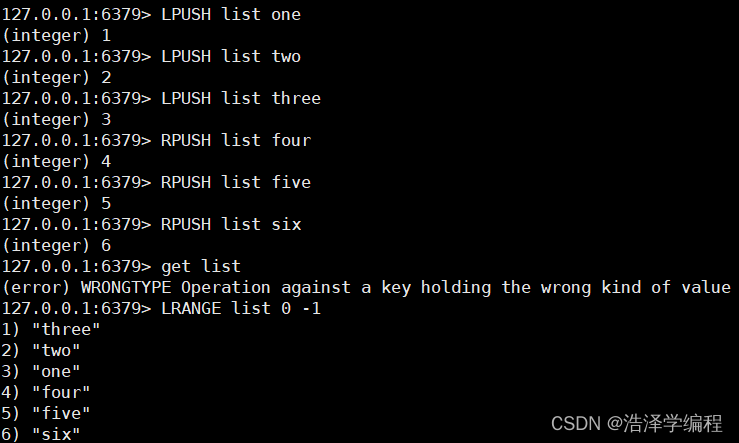
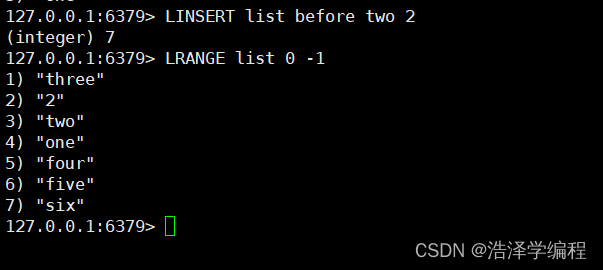
2指定下标赋值
Lset 名称 index value
如果列表不存在或者列表指定下标不存在赋值失败。
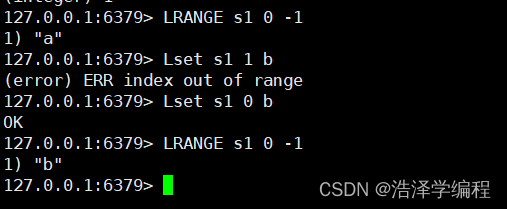
3查看列表
LRANGE 名称 begin end 查看区间数据 [begin,end]
begin = 0 end = -1是查看全部。
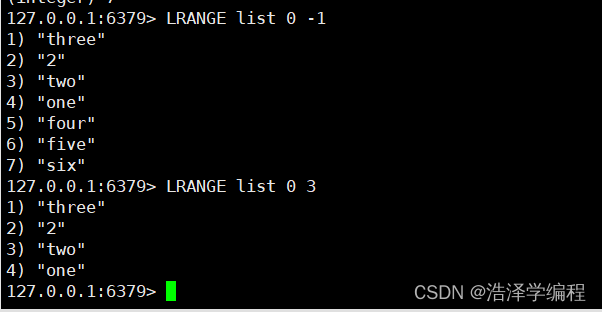
4下标获取值
lindex 名称 index

5返回列表长度
Llen 名称

6移除
Lpop 从左边移除
Rpop 从右边移除
Lrem 名称 数量 value //移除指定数量的value

7截取
Ltrim 名称 begin end
截取区内的元素
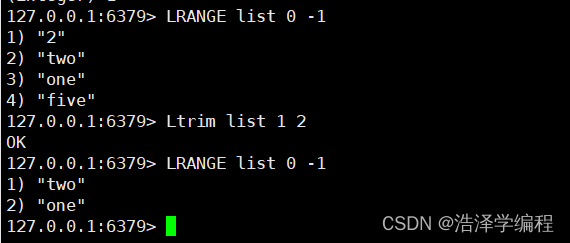
8移动
Rpoplpush 名称 另一个列表
移动列表的最后一个元素带新列表中

9列表是否存在
exists 名称

3.set
Set 中的值是不能重复的
命令都是以 s 开头
应用场景共同关注
1添加
Sadd 名称 value

2取值
Smembers
查看所有值

3随机获取元素
SRANDMEMBER 名称
随机获取集合中的元素
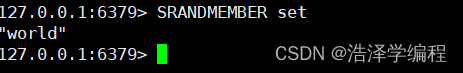
4随机删除
Spop 名称

5指定删除
Srem 名称 value
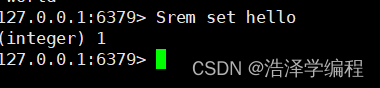
6元素是否存在
Sismember 名称 value

7元素个数
Scard 名称

8移动
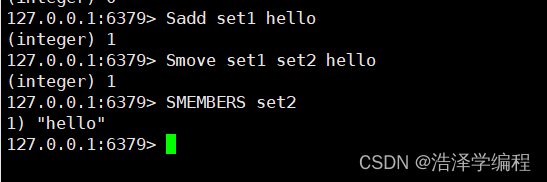
Smove set1 set2 hello
移动 set1 中的 hello 到 set2 中set2 不存在则创建set2集合并移动
9并集、交集、差集
SDIFF 名称1 名称2 //差集
SINTER 名称1 名称2 //交集
SUNION 名称1 名称2 //并集
4.Hash
哈希就是 key - map 的数据结构
应用场景对象存储
1赋值
hset 名称 key1 value1 key2 value2…

2获取
hmget 名称 key1 key2… //获取多个
hget 名称 key //获取一个
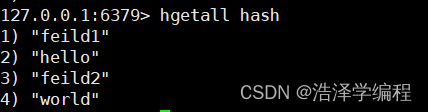
hgetall 名称 //获取全部
hkeys //获取全部key
hvals //获取全部value

3指定删除
hdel 名称 key
对应的value也会删除
4获取数量
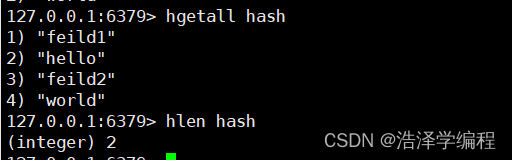
hlen 名称
key-value算一个长度
5字段是否存在
HEXISTS 名称 key
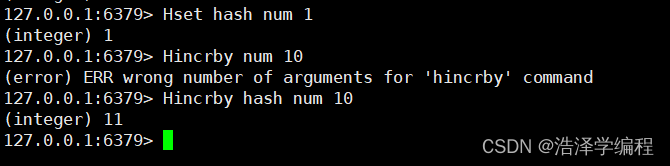
6 自增
Hincrby 名称 key 步长可以是负数
5.Zset
Zset 就是 Set 的有序集合
应用场景排行榜
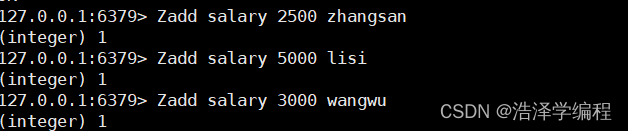
1赋值
Zadd 名称 数值 value…
2获取
Zrange 名称 begin end //下标
区间为0、-1为查询全部
注意观察数据已经按照数值排序了默认从大到小

3获取元素个数
Zcard 名称

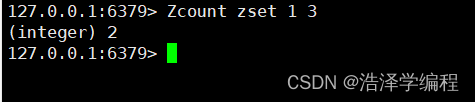
4统计指定区间元素数量
Zcount 名称 begin end //下标
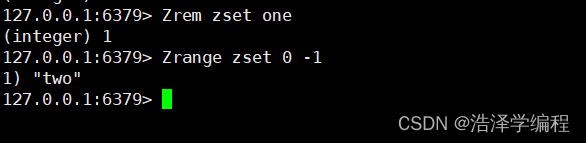
5删除
Zrem 名称 value
移除指定元素
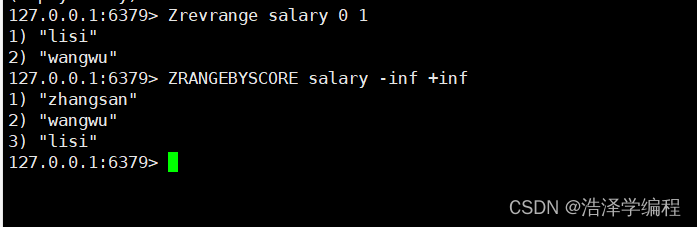
6排序获取
Zrevrange 名称 begin end //从小到大// 区间是下标
Zrangebyscore 名称 begin end //从大到小 // 区间是值数据key的范围并不是下标 // -inf代表负无穷 +inf 代表正无穷
Zrangebyscore 名称 begin end witscores //从大到小显示并附带key的数据

6.Geospatial地理位置
edis 的 GEO 特性在 3.2 版本中推出 这个功能可以将用户给定的地理位置信息储存起来。
通常用以实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
geo 的数据类型为 zset。
GEO 的数据结构总共有六个常用命令geoadd、geopos、geodist、georadius、georadiusbymember、gethash
有效经度从-180度到180度
有效纬度从-85.05112878到85.05112878
当坐标位置超过上诉范围会报错。
一般我们会直接下载城市数据直接通过Java导入。
1添加地理位置
geoadd key 经度 维度 member
将给定的空间元素纬度、经度、名字添加到指定的键里面。
geoadd 命令以标准的xy格式接受参数所以用户必须先输入经度然后再输入纬度。
geoadd 能够记录的坐标是有限的非常接近两极的区域无法被索引。


2获取经纬度
一定是一个坐标值
geopos key member

3获取两个位置距离
geodist key member1 member2
是直线距离默认是米
单位
- km千米
- m米
- mi英里
- ft英尺


4半径内元素查询
georadius key 经度 纬度 半径
乱码报错

解决办法在连接时
redis-cli --raw增加–raw参数强制输出中文。
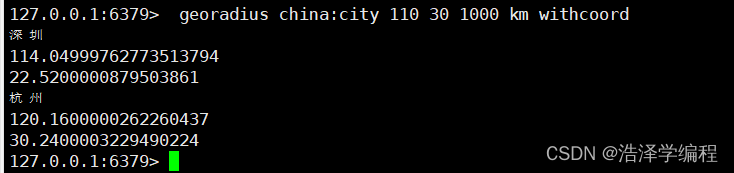
在 china:city 中寻找坐标 100 30 半径为 1000km 的城市

georadius key 经度 纬度 半径 withdist
返回位置名称和距中心直线距离

georadius key 经度 纬度 半径 withcoord
返回位置名称和经纬度
count 数字 // 限定寻找个数

5指定范围内元素
georadiusbymember key member 数字 单位
北京10000km内的城市

6经纬度字符串
geohash
将二维经纬度转换为一维字符串字符串越长表示位置更精确两个字符串越相似表示距离越近。

7删除
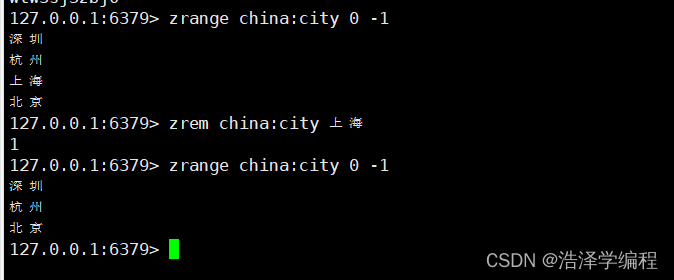
GEO 没有提供删除成员的命令但是因为 GEO 的底层实现是 zset所以可以借用 zrem 命令实现对地理位置信息的删除。
zrem
zrange
7.Hyperloglog基数统计
Redis 在 2.8.9 版本添加了 HyperLogLog 结构用来做基数统计的算法
其优点是在输入元素的数量或者体积非常非常大时计算基数所需的空间总是固定的并且是很小的。
每个 HyperLogLog 键只需要花费 12 KB 内存就可以计算接近 2 ^ 64 个不同元素的基数。
HyperLogLog 是一种算法它提供了不精确的去重计数方案
比如数据集 {1, 3, 5, 7, 5, 7, 8} 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}基数不重复元素为 5。
比如统计网页的浏览用户数量一天内同一个用户多次访问只算一次。
传统的解决方案是使用 Set 来保存用户 id然后统计 Set 中的元素数量。
这种方案只能承载少量用户一旦用户数量大起来就需要消耗大量的空间。
而且目的是统计用户数量而不是保存用户这是个吃力不讨好的方案。
使用 HyperLogLog 最多需要 12k 就可以统计大量的用户数。
尽管它大概有 0.81% 的错误率但对于统计用户数量这种不需要很精确的数据是可以忽略不计的。
1添加
PFadd


2获取基数值
PFCOUNT


3并集合并
pfmerge
mykey和mykey2取并集得到并集mykey3

有重复部分所以合并后15个。
8.Bitmap位图
Redis 从 2.2 版本增加了 Bitmap位图
如果使用普通的 key / value存储则要记录 365 条记录如果用户量很大需要的空间也会很大。
Redis 提供了 Bitmap 位图这种数据结构Bitmap 就是通过操作二进制位来进行记录即为 0 和 1。
如果要记录 365 天的打卡情况使用 Bitmap 表示的形式大概如下0101000111000111……
这样 365 天相当于 365 bit又 1 字节 = 8 bit , 所以相当于使用 46 个字节即可。
BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态其中的 key 就是对应元素本身。
实际上底层也是通过对字符串的操作来实现的。
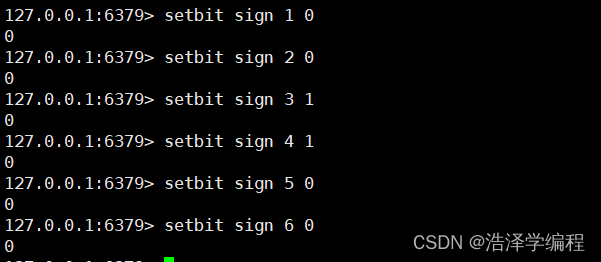
1添加
setbit
2取值
getbit

3统计
bitcount
只有2个值为1

总结
以上就是Redis讲解。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |