

Flink CDC 原理
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
CDCChange Data Capture 变更数据捕获
目前CDC有两种实现方式一种是主动查询、一种是事件接收。
主动查询
相关开源产品有Sqoop、Kafka JDBC Source等。
用户通常会在数据原表中的某个字段中保存上次更新的时间戳或版本号等信息然后下游通过不断的查询和上次的记录做对比来确定数据是否有变动是否需要同步变化数据。
因为要以一定的间隔不断的查询源数据库所以随着间隔的减小和扫描数据量的增加对源数据库的压力会随之增加。
优点1不涉及数据库底层特性比较通用
缺点1如果原表中的字段无法用来区分新旧数据那么需要对原表进行改造从这一点看在某些场景下可能无法使用该方式。
缺点2实时性不高。
缺点3对业务数据库有压力。
缺点4源数据库数据更新频繁时可能存在数据丢失的风险。
事件接收
相关开源产品有Canal、Maxwell、Debezium等。
通过数据库本身的触发器Trigger或者日志例如Binary log、Transaction log、Write-ahead log等媒介将数据变化记录下来外部系统通过数据库底层的协议订阅并消费这些事件然后对数据库变动记录做重放从而实现数据同步。
优点1实时性高可以精确捕获数据变化。
优点2对源数据库不会产生额外压力。
缺点1需要独立安装部署插件或服务比Debezium 采集 MySql数据时。
缺点2需要将采集到的数据额外存储到Kafka等外部组件中对外提供稳定的实时数据流。
缺点3支持的数据库种类少。
Flink cdc 通过嵌入Debezium、Kafka的方式实现CDC降低了实现源数据库数据实时同步到Flink的操作难度。如下图红色虚线部分就是被简化的内容。
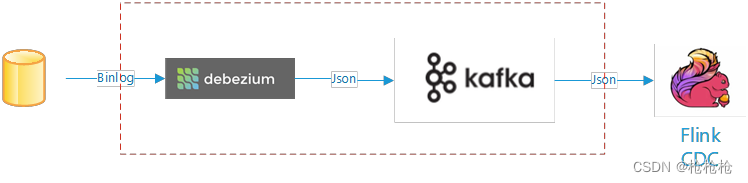
这里以flink-connector-postgresql-cdc依赖进行分析
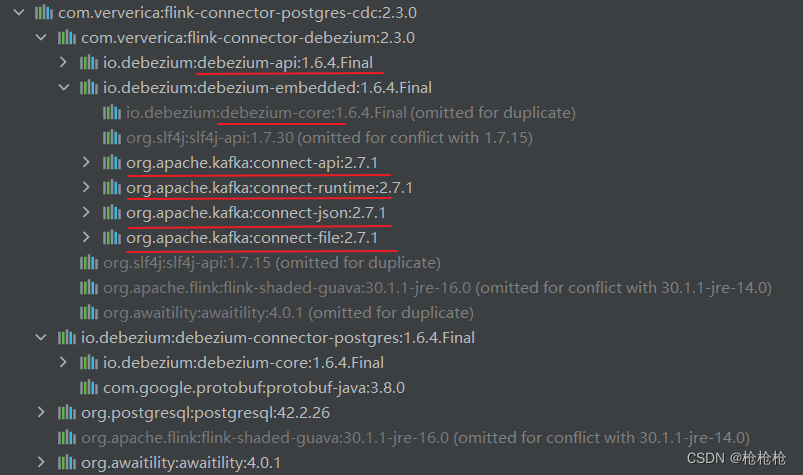
从中可以看到debezium和kafka的相关依赖。
随后再更新(ง •_•)ง
参考资料
https://www.jianshu.com/p/616d6c5f23a0
https://blog.csdn.net/qq_32727095/article/details/120361815