

Hadoop、Hive安装-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、 工具
Linux系统Centos版本7.0及以上
JDKjdk1.8
Hadoop3.1.3
Hive3.1.2
虚拟机VMware
mysql5.7.11
工具下载地址: https://pan.baidu.com/s/1JYtUVf2aYl5–i7xO6LOAQ
提取码: xavd
提示以下是本篇文章正文内容下面案例可供参考
二、JDK安装
下载jdk-8u181-linux-x64.tar.gz包将此包上传至/opt 目录下。
cd /opt
解压安装包 tar zxvf jdk-8u181-linux-x64.tar.gz
删除安装包 rm -f jdk-8u181-linux-x64.tar.gz
使用root权限编辑profile文件设置环境变量
vi/etc/profile
export JAVA_HOME= /usr/java/jdk1.8.0_181
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
让修改的文件生效
source /etc/profile
三、安装mysql
下载mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz包将此包上传至/opt目录下并改名mysql。
cd /opt
tar -xzvf mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.7.11-linux-glibc2.5-x86_64 mysql
先查询是否存在用户组
groups mysql
创建用户组和用户名
groupadd mysql && useradd -r -g mysql mysql
授予文件数据目录权限
chown mysql:mysql -R /opt/mysql/data
修改/etc/my.cnf配置文件,没有得到话就创建
vi /etc/my.cnf
[mysqld]
port = 3306
user=mysql
basedir=/opt/mysql/
datadir=/opt/mysql/data
socket=/tmp/mysql.sock
symbolic-links=0
[mysqld_safe]
log-error=/opt/mysql/data/mysql.log
pid-file=/opt/mysql/data/mysql.pid
[client]
port=3306
default-character-set=utf8
初始化mysql服务
cd /opt/mysql/bin
执行命令然后会有一个默认密码有的人这里会报错是因为没有安装libaio这里就先安装一遍
yum install libaio -y
./mysqld --defaults-file=/etc/my.cnf --user=mysql --initialize

启动mysql
cp /opt/mysql/support-files/mysql.server /etc/init.d/mysql
service mysql start
进入目录
cd /opt/mysql/bin
登录,输入刚才的临时密码就可以了直接复制粘贴
./mysql -u root -p
修改密码我设置的密码是root在最后面根据自己需要进行设置
alter user 'root'@'localhost' identified with mysql_native_password BY 'root';
刷新使操作生效
flush privileges;
更改数据库连接权限
use mysql;
update user set host='%' where user = 'root';
flush privileges;
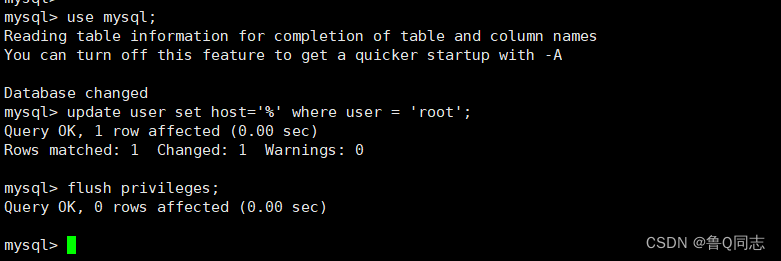
退出
exit
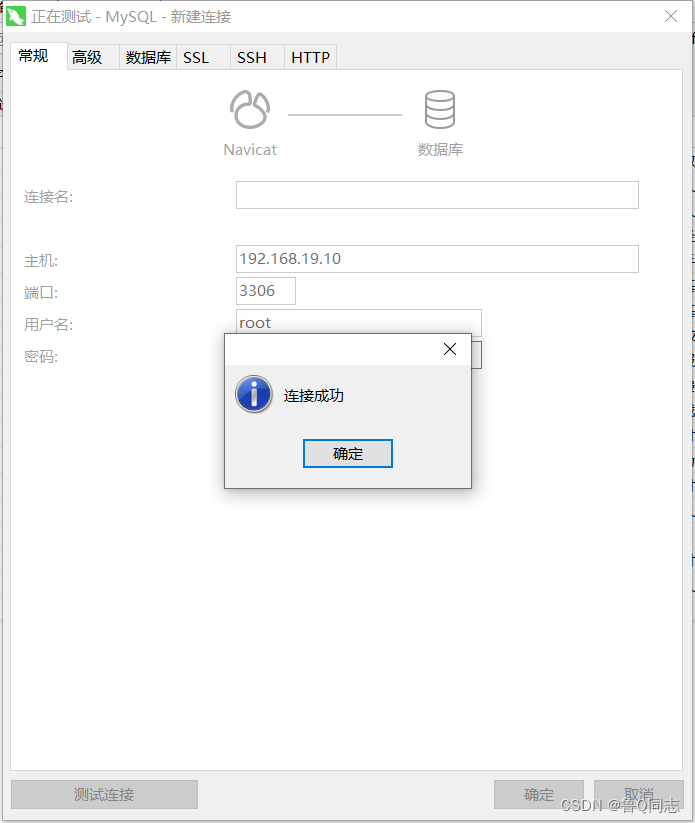
测试
我虚拟机的ip为192.168.19.10

有的人会连接不成功是因为发防火墙没有放开端口这里有两种方法关闭防火墙或者开放端口
关闭防火墙
systemctl stop firewalld
开放端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
开放完端口后需要重启防火墙才能生效
firewall-cmd --reload
设置开机自启
添加到服务列表
chkconfig --add mysql
查看列表
chkconfig --list
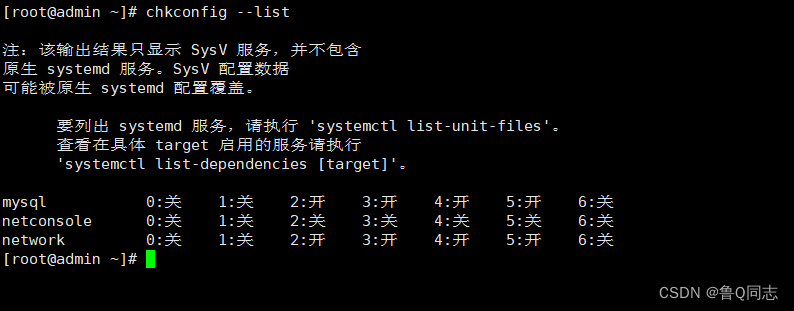
一般2345都是开或者on的如果不是执行命令
chkconfig --level 2345 mysql on
添加系统路径
vi /etc/profile
export PATH=/opt/mysql/bin:$PATH
source /etc/profile
四、hadoop安装
安装步骤和jdk的完全一样存在/opt 然后把下载解压的hadoop放到该文件夹下面。最主要的也还是配置文件如果配置文件里面的路径正确那就可以。配置代码如下
vi/etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
安装完之后可以在终端输入hadoop version命令查看

Hadoop分布式配置
终端输入mkdir /opt/hadoop-3.1.3/tmp创建tmp文件夹
终端输入mkdir /opt/hadoop-3.1.3/data/namenode创建namenode文件夹
终端输入mkdir /opt/hadoop-3.1.3/data/datanode创建datanode文件夹
在终端输入cd /opt/hadoop-3.1.3/etc/hadoop/ 注意自己的路径后面需要修改的文件都在这个目录下面这里先进入该目录
进入/opt/hadoop-3.1.3/etc/hadoop
cd /opt/hadoop-3.1.3/etc/hadoop
配置core-site.xml输入vi core-site.xml 打开文件后添加
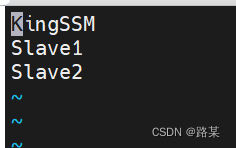
全分布式中我使用三台虚拟机KingSSM是我的主机名还有两台分别是Slave1和Slave2
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://kingssm:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.3/tmp</value>
</property>
</configuration>
配置hdfs-site.xml输入vi hdfs-site.xml 打开文件后添加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-3.1.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-3.1.3/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
配置mapred.site.xml输入vi mapred-site.xml 打开文件后添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>kingssm:9001</value>
</property>
</configuration>
配置yarn-site.xml输入yarn-site.xml打开文件后添加
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>kingssm</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
配置hadoop-env.sh输入vi hadoop-env.sh 打开文件后添加
export JAVA_HOME=/opt/jdk1.8.0_181
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:/opt/hadoop-3.1.3/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/opt/hadoop-3.1.3/pids
配置yarn-env.sh输入vi yarn-env.sh 打开文件后添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置workers输入vi workers 打开文件后添加这里换成你的主机名和IP地址KingSSM是当前正在操作的虚拟机主机名其他两个是等下要克隆的两台虚拟机的主机名IP地址要在虚拟机中修改
在终端输入cd /opt/hadoop-3.1.3/sbin/ 进入新的目录
配置start-dfs.sh输入vi start-dfs.sh打开文件后添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置stop-dfs.sh输入vi stop-dfs.sh打开文件后添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
修改主机名
# 查看主机名称
hostname
# 修改主机名
hostnamectl --static set-hostname kingssm
设置静态IP
终端输入ip route查看网关

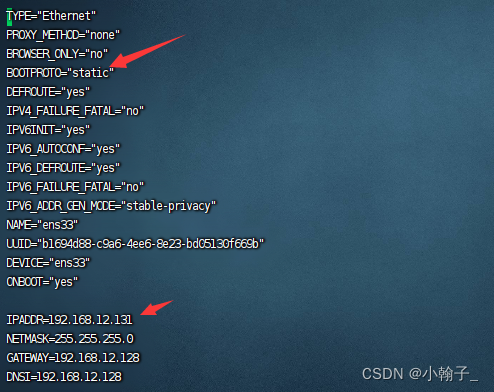
输入vi /etc/sysconfig/network-scripts/ifcfg-ens33修改文件修改或添加下面的内容IP地址自己选择但是注意要和网关对应如网关是192.168.12.128那IP地址前面就得是192.168.12后面那部分自己随意NDS1和网关一样子网掩码是255.255.255.0
添加虚拟机之间的映射
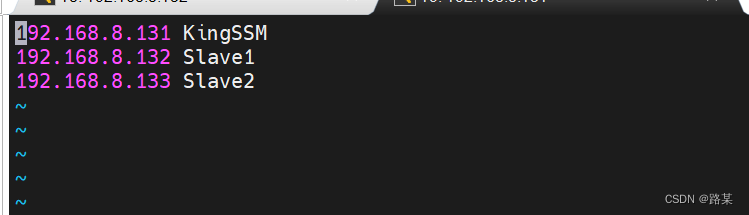
终端输入vi /etc/hosts添加
SSH免密登录
首先运行
ssh localhost
正常情况下是免密登录的如果你还要输入密码的话那就是你ssh没有配置好。这里要说一下的是ssh7.0之后就关闭了dsa的密码验证方式如果你的秘钥是通过dsa生成的话需要改用rsa来生成秘钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再次运行
ssh localhost
如果不需要输入密码说明ssh配置好了。接下来运行
ssh-keygen -t rsa 然后一直回车
等可以再次输入时输入下面命令将公钥发布出去
ssh-copy-id kingssm
ssh-copy-id slave1
ssh-copy-id slave2
五、克隆虚拟机启动集群
把当前正在使用的kingssm虚拟机关闭然后克隆两台虚拟机。
点击虚拟机------>右键------>管理------>克隆------>完全克隆
等克隆完之后三台虚拟机都打开然后对克隆出来的两台分别设置主机名slave1和slave2并修改IP地址
启动集群
三台虚拟机都需要先格式化
打开终端以root身份操作三台都要输入hadoop namenode -format进行格式化
格式化完成后在kingssm中启动集群输入start-all.sh启动集群如果关闭输入stop-all.sh
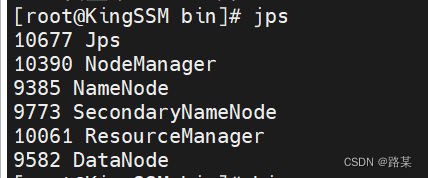
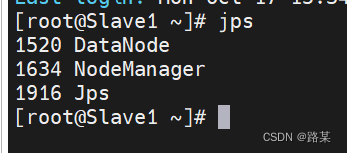
启动完后输入jps查看启动状态kingssm和slave应该有以下信息
访问网页查看结果kingssm:9870
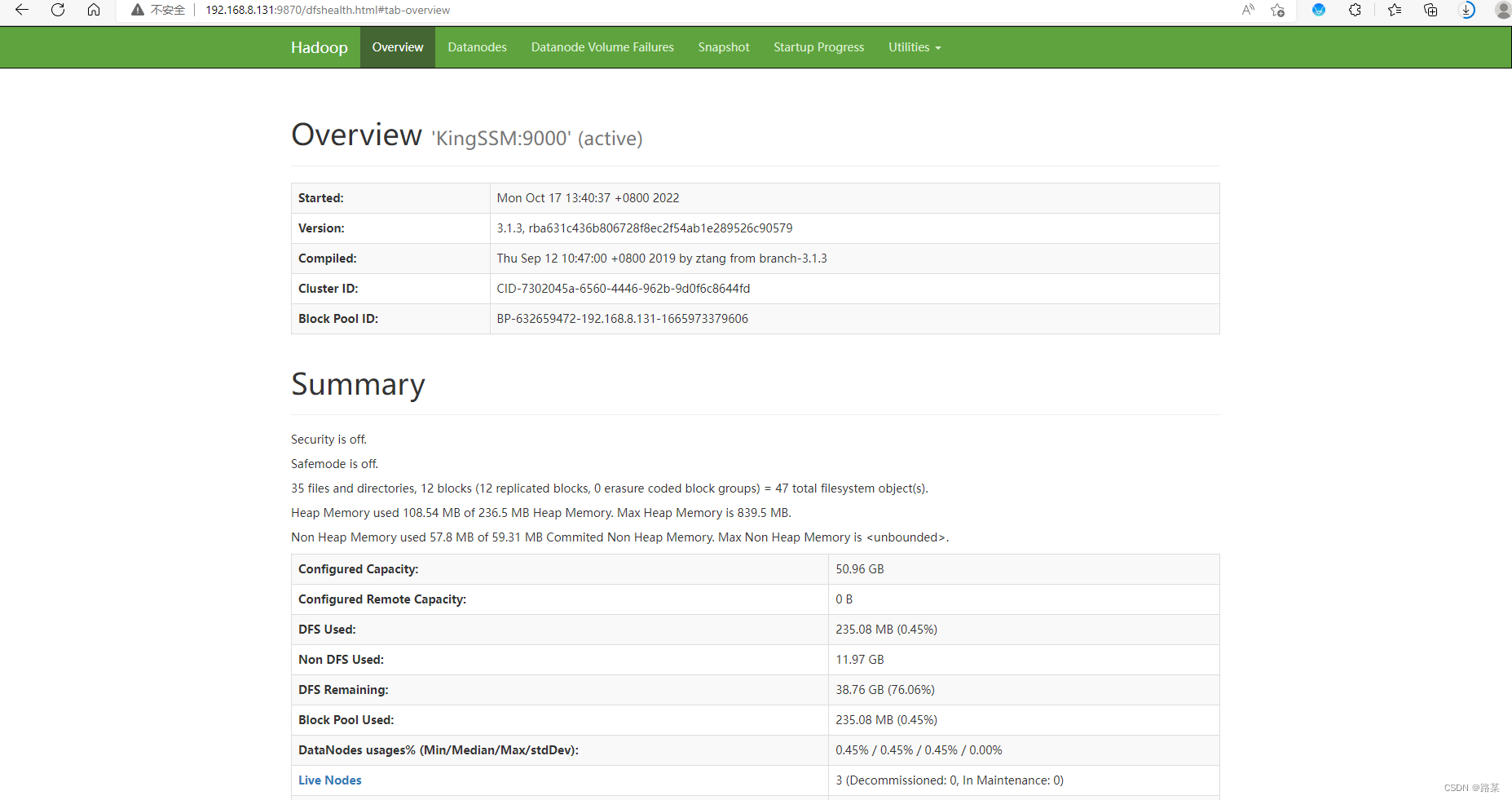
访问网页查看结果kingssm:8088

六、hive安装
修改hadoop的 core-site.xml中, 添加以下内容:
修改hadoop 配置文件 /opt/hadoop-3.1.3/core-site.xml,加入如下配置项:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
软件包下载 apache-hive-3.1.2-bin.tar.gz上传/usr目录下并解压重命名hive
cd /opt
tar -xzvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin
修改 hive的环境配置文件: hive-env.sh
cd /export/server/hive-3.1.2/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
修改一下内容:
# 配置hadoop的家目录
HADOOP_HOME=/opt/hadoop-3.1.3/
# 配置hive的配置文件的路径
export HIVE_CONF_DIR=/opt/hive/conf/
# 配置hive的lib目录
export HIVE_AUX_JARS_PATH=/opt/hive/lib/
创建配置文件
cd /opt/conf/
vi hive-site.xml
将以下内容复制配置文件中
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://kingssm:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 远程模式部署metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://kingssm:9083</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>kingssm</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
vi /etc/profile
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
连接MySQL, 用户名root, 密码root
mysql -uroot -proot
创建hive元数据, 需要和hive-site.xml中配置的一致sql
创建数据库, 数据库名为: metastore
create database metastore;
show databases;
初始化元数据库
schematool -initSchema -dbType mysql -verbose
看到schemaTool completed 表示初始化成功
验证安装
hive
退出
quit;
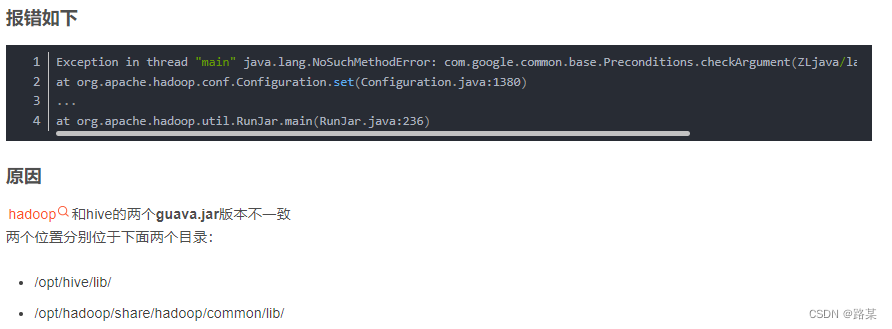
如遇以下错误及解决方法

hadoo的slf4j和hive两个slf4j冲突
删除 /opt/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar

hadoop和hive的两个guava.jar版本不一致
将高版本的替换到底版本的
创建HDFS的hive相关的目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
启动 hive的服务: metastore
先启动metastore服务项:
前台启动:
cd /opt/hive/bin
hive --service metastore
注意: 前台启动后, 会一直占用前台界面, 无法进行操作
好处: 一般先通过前台启动, 观察metastore服务是否启动良好
前台退出: ctrl + c
后台启动:
当前台启动没有任何问题的时候, 可以将其退出, 然后通过后台启动, 挂载后台服务即可
cd /opt/hive/bin
nohup hive --service metastore &
启动后, 通过 jps查看, 是否出现一个runjar 如果出现 说明没有问题(建议搁一分钟左右, 进行二次校验)
注意: 如果失败了, 通过前台启动, 观察启动日志, 看一下是什么问题, 尝试解决
后台如何退出:
通过 jps 查看进程id 然后采用 kill -9
启动hive的服务: hiveserver2服务
接着启动hiveserver2服务项:
前台启动:
cd /opt/hive/bin
hive --service hiveserver2
注意: 前台启动后, 会一直占用前台界面, 无法进行操作
好处: 一般先通过前台启动, 观察hiveserver2服务是否启动良好
前台退出: ctrl + c
后台启动:
当前台启动没有任何问题的时候, 可以将其退出, 然后通过后台启动, 挂载后台服务即可
cd /opt/hive/bin
nohup hive --service hiveserver2 &
启动后, 通过 jps查看, 是否出现一个runjar 如果出现 说明没有问题(建议搁一分钟左右, 进行二次校验)
注意: 如果失败了, 通过前台启动, 观察启动日志, 看一下是什么问题, 尝试解决
后台如何退出:
通过 jps 查看进程id 然后采用 kill -9
基于beeline的连接方式
cd /opt/hive/bin
beeline --进入beeline客户端
连接hive:
!connect jdbc:hive2://kingssm:10000
接着输入用户名: root
最后输入密码: 无所谓(一般写的都是虚拟机的登录密码)
可能出现问题
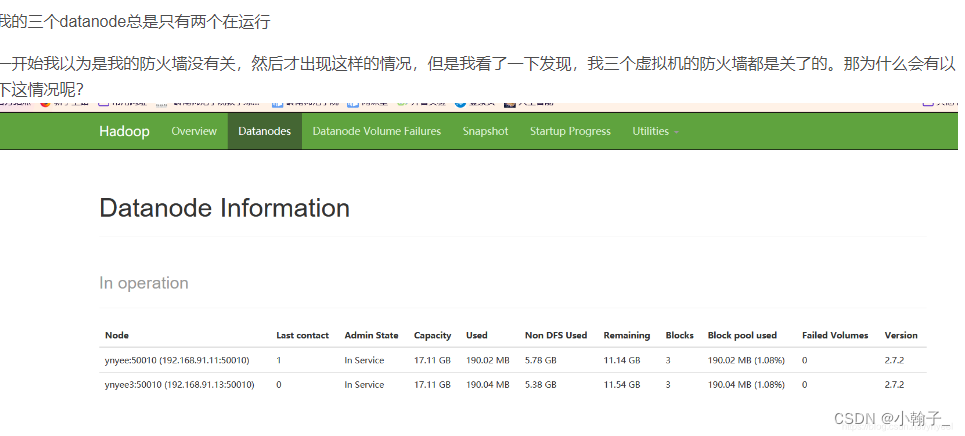
到我们hadoop下的/opt/hadoop-3.1.3/data/datanode/current下去修改VERSION文件把datanodeUuid改成两个不同的id就可以了随便改都可以~
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |