UniFormer: Unifying Convolution and Self-attention for Visual Recognition
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
paper链接: https://arxiv.org/abs/2201.09450
UniFormer: Unifying Convolution and Self-attention for Visual Recognition
一、引言
虽然CNN可以在小邻域内通过卷积有效地减少局部冗余但有限的感受野使其难以捕获全局依赖。另外VIT可以通过自注意力有效地捕获长期依赖关系而所有令牌之间的盲目相似性比较导致高冗余。为了解决这些问题本文提出了一种新的统一transFormer(UniFormer)它可以在一个简洁的transFormer格式中无缝地集成卷积和自注意的优点。与典型的transFormer块不同UniFormer块中的关系聚合器在浅层和深层分别配备了局部和全局令牌亲和性允许处理冗余和依赖以实现高效和有效的表示学习。UniFormer块堆叠成一个新的强大的骨干并将其用于从图像到视频领域从分类到密集预测的各种视觉任务。
本文以图像和视频领域中著名的vit(即DeiT和TimeSformer)为例进行可视化它们的注意力分布在浅层。如下图所示两种vit确实捕捉到了浅层的详细视觉特征而空间和时间注意是多余的。可以很容易地看到给定一个锚标记空间注意力主要集中在局部区域的标记上(主要是3×3)而从该图中的其他标记中学到的很少。同样时间注意力主要集中在相邻帧中的标记而忽略了远处帧中的其他标记。然而这种局部焦点是通过在空间和时间上对所有标记进行全局比较获得的。显然这种冗余注意方式带来了大量不必要的计算负担从而恶化了ViTs中的计算精度平衡。

在此基础上提出了一种新的统一transFormer(UniFormer)。它以简洁的transFormer格式灵活地统一了卷积和自注意可以同时解决局部冗余和全局依赖从而实现有效和高效的视觉识别。具体来说UniFormer模块由三个关键模块组成即动态位置嵌入(DPE)、多头关系聚合器(MHRA)和前馈网络(FFN)。关系聚合器的独特设计是UniFormer与以前的CNN和VIT的关键区别。在浅层中关系聚合器用一个小的可学习参数矩阵捕获局部令牌相关性它继承了卷积风格可以通过局部区域的上下文聚合在很大程度上减少计算冗余。
在深层关系聚合器通过令牌相似度比较学习全局令牌亲和力它继承了自注意风格可以自适应地从遥远的区域或框架构建远程依赖。通过逐步分层地堆叠局部和全局的UniFormer块可以灵活地整合它们的协作能力以促进表示学习。最后为视觉识别提供了一个通用而强大的主干并通过简单而精细的适应成功地解决了各种下游视觉任务。
二、实现细节
下图显示了简洁的统一transFormer(UniFormer)。为了简单描述以T帧的视频为例图像输入可以看作是一个单帧的视频。
因此红色突出显示的维度仅用于视频输入而对于图像输入所有维度都等于1。可以看到UniFormer是一个基本的transFormer格式。
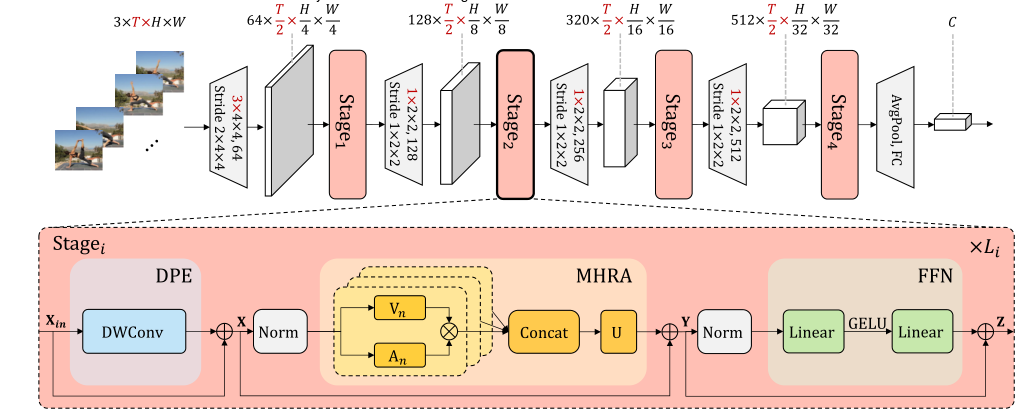
具体来说UniFormer块由三个关键模块组成:动态位置嵌入(DPE)、多头关系聚合器(MHRA)和前馈网络(FFN):
考虑输入令牌张量
X
i
n
∈
R
C
×
T
×
H
×
W
X_{in}∈R^{C×T ×H×W}
Xin∈RC×T×H×W(对于图像输入T = 1)首先引入DPE将位置信息动态地集成到所有令牌中(Eq. 1)。它对任意输入分辨率都很友好并且很好地利用了令牌顺序从而更好地进行视觉识别。然后使用MHRA通过关系学习利用其上下文标记来增强每个标记(Eq。
2).通过在表层和深层灵活设计令牌亲和力MHRA可以巧妙地统一卷积和自注意力减少局部冗余学习全局依赖。最后像传统的ViTs一样加入FFN它由两个线性层和一个非线性函数即GELU (Eq. 3)组成。通道数先按4的比例扩展然后恢复这样每个令牌都会单独增强。
如前所述传统的CNN和VIT侧重于解决局部冗余或全局依赖导致精度不理想或/和不必要的计算。为了克服这些困难引入了一种通用的关系聚合器(RA)它统一了卷积和用于标记关系学习的自注意。通过在浅层和深层分别设计局部和全局token亲和性实现了高效的表示学习。具体来说MHRA以多头风格利用令牌关系:
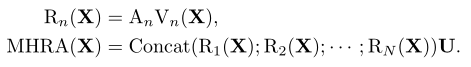
给定输入张量
X
∈
R
C
×
T
×
H
×
W
X∈R^{C×T ×H×W}
X∈RC×T×H×W(对于图像输入T = 1)首先将其重塑为一个长度为L=T ×H×W的符号序列
X
∈
R
L
×
C
X∈R^{L×C}
X∈RL×C。Rn(·)表示第N个头中的RA,
U
∈
R
C
×
C
U∈R^{C×C}
U∈RC×C是一个可学习的参数矩阵可以对N个头进行积分。每个RA由令牌上下文编码和令牌关联学习组成。应用线性变换将原始标记编码为上下文标记
V
n
(
X
)
∈
R
L
×
C
N
V_n(X)∈R^{L× \frac{C}{N}}
Vn(X)∈RL×NC。
随后RA可以在令牌亲缘性
A
n
∈
R
L
×
L
A_n∈R^{L×L}
An∈RL×L的指导下总结上下文。
(一)、Local MHRA
尽管浅层的VIT比较了所有令牌之间的相似性但它们最终学习了局部表示。
这种冗余的自注意设计在浅层中带来了较大的计算成本。基于这一观察建议在一个小的邻域中学习令牌亲和力这恰好与卷积滤波器的设计有相似的见解。因此建议将局部亲和度表示为浅层中的可学习参数矩阵。
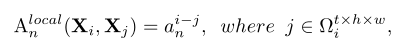
其中
a
n
∈
R
t
×
h
×
w
a_n∈R^{t×h×w}
an∈Rt×h×w是可学习参数
X
j
X_j
Xj指
Ω
i
t
×
h
×
w
Ω_i^{t×h×w}
Ωit×h×w中的任意相邻的令牌。(i−j)表示标记i和j之间的相对位置。请注意相邻标记之间的视觉内容在浅层中变化微妙因为标记的感受野很小。在这种情况下没有必要在这些层中使令牌关联成为动态的。因此使用一个可学习的参数矩阵来描述局部令牌相关性它仅仅依赖于令牌之间的相对位置。
与卷积块的比较局部MHRA可以被解释为MobileNet块通用扩展。首先方程4中的线性变换V(·)等价于逐点卷积(PWConv)其中每个头对应一个输出特征通道
V
n
(
X
)
V_n(X)
Vn(X)。
此外局部令牌关联可以实例化为在每个输出通道(或头部)
V
n
(
X
)
V_n(X)
Vn(X)上操作的参数矩阵因此关系聚合器
R
n
(
X
)
=
A
n
l
o
c
a
l
V
n
(
X
)
R_n(X) = A^{local}_n V_n(X)
Rn(X)=AnlocalVn(X)可以解释为深度卷积(DWConv)。最后线性矩阵U它连接并融合了所有的头部也可以被视为一个点卷积。因此这种局部MHRA可以在MobileNet块中以pwconv-dwconv - pwconv的方式重新表述。此外与MobileNet块不同的是局部UniFormer块被设计为通用的transformer格式即除了MHRA之外它还包含动态位置编码(dynamic position encoding, DPE)和前馈网络(forward network, FFN)。这种独特的集成可以有效地增强令牌表示这在之前的卷积块中没有探讨过。
(二)、全局MHR
在深层重要的是在更广泛的token空间中开发远程关系这自然与自注意力的设计有相似的见解。因此通过比较全局视图中所有令牌的内容相似度来设计令牌的亲和性:
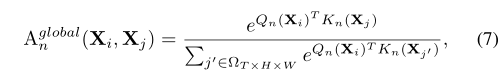
其中
X
j
X_j
Xj可以是全局中大小为T ×H×W(对于图像输入T = 1)的任何令牌而
Q
n
(
⋅
)
Q_n(·)
Qn(⋅)和
K
n
(
⋅
)
K_n(·)
Kn(⋅)是两个不同的线性变换。
与变压器块比较:全局MHRA Aglobaln (Eq. 7)可以实例化为一个时空自注意其中Qn(·)Kn(·)和Vn(·)在ViT中成为Query, Key和V value。因此它可以有效地学习长期依赖关系。
全局UniFormer块与以前的ViT块不同。首先大多数视频transformer在视频域中划分时空注意以减少令牌相似度比较中的点积计算。
但这种操作不可避免地恶化了符号之间的时空关系。相反全局联合编码时空符号关系生成更具鉴别性的视频表示便于识别。由于局部UniFormer块在很大程度上节省了浅层token比较的计算因此整个模型可以达到较好的计算精度平衡。其次UniFormer中采用动态位置嵌入(dynamic position embedding, DPE)代替了绝对位置嵌入。它采用卷积样式可以克服置换不变性并且对不同长度的可视标记友好。
(三)、动态位置嵌入
位置信息是描述视觉表征的重要线索。此前大多数vit通过绝对或相对位置嵌入对这些信息进行编码。但是绝对位置嵌入需要对不同的输入大小进行微调而相对位置嵌入由于自注意的修改效果不佳。
为了提高灵活性最近提出了卷积位置嵌入。特别是条件位置编码(CPE)可以通过卷积运算符隐式编码位置信息从而解锁Transformer以处理任意输入大小并提高识别性能。由于其即插即用的特性灵活地采用它作为在UniFormer中的动态位置嵌入(DPE):
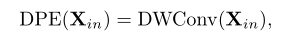
DWConv指的是零填充的深度卷积。选择这样的设计作为我DPE基于以下原因。首先深度卷积对任意输入形状都是友好的例如可以直接使用它的时空版本来编码视频中的3D位置信息。其次深度卷积是轻量级的这是计算精度平衡的重要因素。最后添加额外的零填充因为它可以帮助令牌通过逐步查询它们的邻居来了解它们的绝对位置。
三、框架设计

四、实验
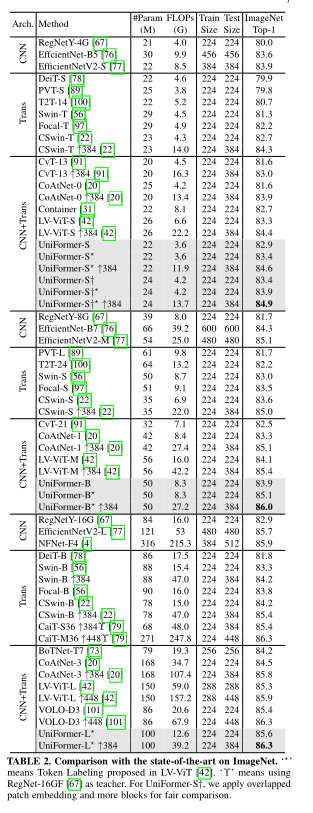
(一)、图像分类
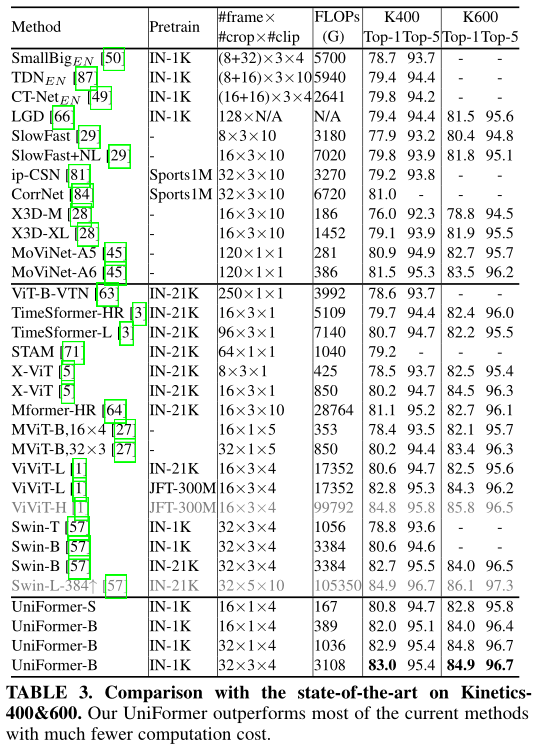
(二)、视频分类
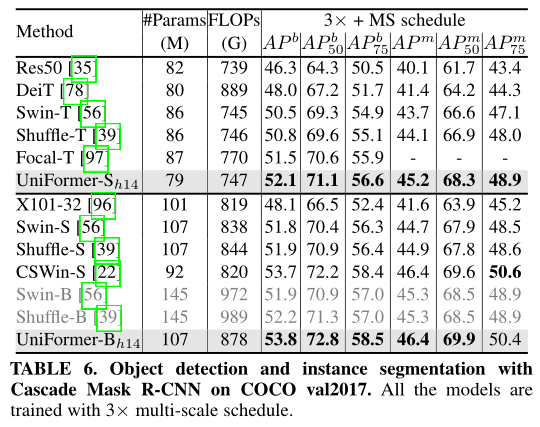
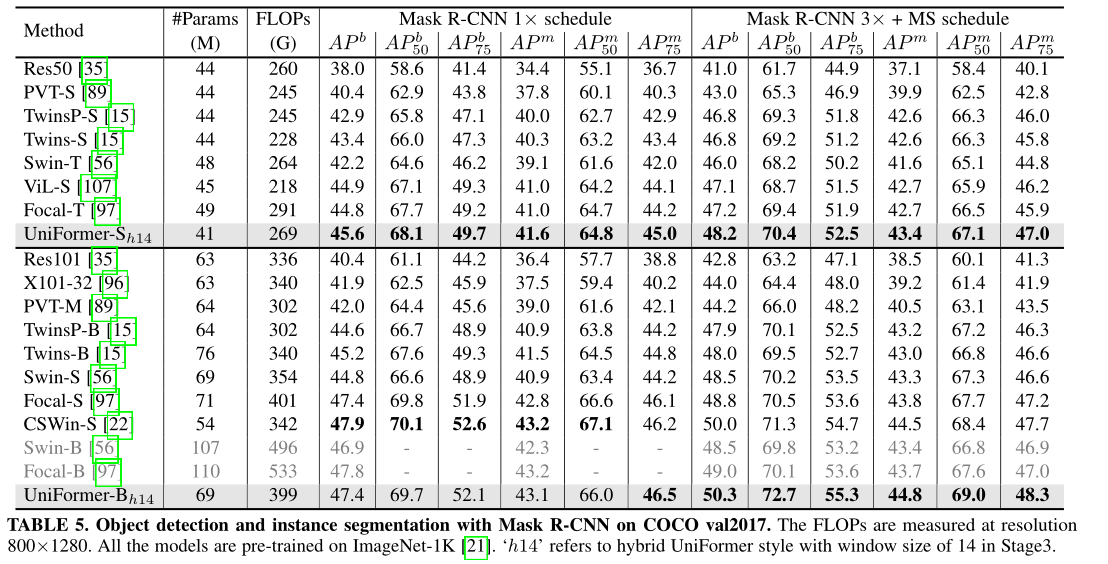
(三)、目标检测
(三)、语义分割