

04.hadoop上课笔记之java编程和hbase
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.win查看服务
netstat -an #linux也有
#R数学建模语言 SCALAR
2.java连接注意事项,代码要设置用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
3.伪分布式的好处(不用管分布式细节,直接连接一台机器…,适合用于学习)
4.官方文档 查看类(static | new)
hadoop.org —>java API
5.单点故障:一个节点出错全部不可用
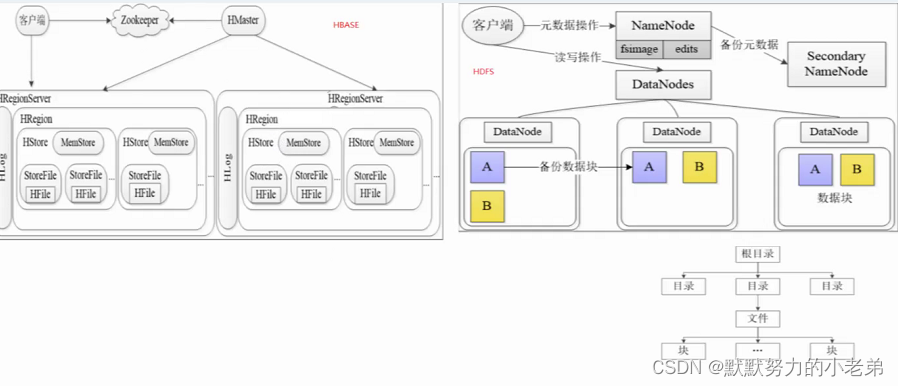
6.HBase hadoop database(像nosql的数据库,用列和表,分布式的数据库)
与hdfs的关系:HDFS是Hbase运行的底层文件系统
- RegionServer理解为数据节点存储数据的。
- region 向客户端提供数据和管理
- master 负载均衡和管理region(失效把数据移动到别处) 失效了 zookeeper也可以访问
- zookeeper 帮助master高可用 帮master监控regionserver 选master 找数据
#其他知识 #信息检索课(怎么查信息)
图hbase #元数据的表名
hbase:meta
7.安装hbase
- 解压
- 改配置文件
- 启动hadoop
- start.sh
8.habse应用场景
1.搜索条件简单,数据量大
2.不强调表之间的关系
3.列存储(直接在列查,不全表扫描,mysql需要索引才可以) 还可以列压缩
如: select age时直接查age列,而不是每个行扫描完扫描列是否满足条件
age 22 23 24
name jamse aa bb
myql事务 A原子性 atomicity C(consistency)一致性 I独立性(isolation) D (durability)持久性
mysql where 1=1是关于关系代数的理论, 1=1代表匹配的结果 要不要显示
9.hbash添加语句(不需要多表连接)
#查看hbase信息 http://192.168.202.103:16010/
create "tableName","columnName","columnName"
#查看帮助,必须要""
help "create"
#看结构
desc "tableName"
#hbase http://192.168.202.103:16030/rs-status
#插入一个数据必须需要id 列族:更小字段
put 'student_xxx','0001','stuinfo:name','tom'
#select
scan 'student_xxx'
#update
put 'student_xxx','0001','stuinfo:name','tomy'
#id可以不写字段
put 'student_xxx','07112001','info:name','Benie',3 #修改版本
#修改列的版本,改一个列对象的版本
alter 'student_xxx',{NAME=>'stuinfo',VERSIONS=>5}
#增加一个列
alter 'student_xxx','grades'
#删除列
alter 'student_xxx','delete'=>'grades'
#删除写错的数据 表 id 列:字段(没有写id字段,hbase会自动生成一个),所 #以可以省字段名
delete 'student_xxx','07112002','info:name'
#hbase不会自己添加版本,1个版本可能有多个数据,
#得到版本为3的
get 'student_xxx','0001',{COLUMN=>'stuinfo:name',VERSIONS=>3}
get 'student_xxx','0001'
#先禁用后删除table
disable xxx
drop xxx
#查看表是否存在
exists xxx
#查看列字段的数据
scan 'student_xxx',{COLUMNS=>'info:name'}
#查看多个字段的数据,不用id
scan 'student_xxx',{COLUMNS=>['info:name','relationship:father']}
#指定id数据区间,不包含最后一行
scan 'student_xxx',{STARTROW=>'07112001',ENDROW=>'07112002'}
#限制条数
scan 'student_xxx',{LIMIT=>2}
#删除版本为3 的
delete 'student_xxx','07112001','info:name',3
#删除整行
deleteall 'student_xxx','07112003'
#删除整表
truncate 'student_xxx'
#mysql数据导入hbase
#语法少了错了没有提示 list 或ctrl+c退出 #数据的属性在列中 VERSION所有列可以保存的版本数,TTL 是秒数
到期删除(密码,验证码)
#IN_MEMORY是否加载到内存
10.理论(毕业设计)
- region(按行键[id]划分,最初有1个,一般1g)(读列速度快,因为放在不同机器)
1. 是hbase负载均衡(分开处理资源)的最小单元
2. 一个region对应多个store(存列,和行的键)包含memstore(先写入内存)和filestore(内存写入磁盘)
flush ‘columns’ #需要写这个才能写入磁盘,如果不写默认需要1个小时才能写入- 写入相同文件只多一个文件,可以记录历史记录,存在内存为了排序,放入磁盘
#Hlog(wals)避免内存数据丢失,在写入内存之前备份,只有1个,不能大于1000个region,
#查看日志文件 /usr/local/hbase/hbase-tmp/logs/xxxregion-server
11.hbase集群 复制到别人的机器
scp
#会报错,需要改配置文件,连接java,要改host配置文件
12.Hbase的特点
① 半结构化或非结构化数据(变化的数据)
② 记录非常稀疏(没有表结构,null不占空间)
③ 多版本数据(可能要用以前写入的数据)
④ 超大数据量(自动水平切分)
12.Hbase特点(没有多表连接,直接是一个表,因为用列存储)
大一个表可以有数十亿行上百万列;
无模式每行都有一个可排序的主键和任意多的列列可以根据需要动态的增加同一张表中不同的行可以有截然不同的列;
面向列面向列(族)的存储和权限控制列(族)独立检索;
稀疏空(null)列并不占用存储空间
数据多版本每个单元中的数据可以有多个版本默认情况下版本号自动分配是单元格插入时的时间戳;
数据类型单一Hbase中的数据都是字符串没有类型 !!!
10.HBase和hdfs区别
- hbase只有字符串类型
- hbase一张表,传统要考虑多表关系
- 存储模式Hbase是基于列存储的,每列由每个文件存储
- 数据维护Hbase的更新实际上是插入了新的数据传统数据库只是替换和修改
- 可伸缩性Hbase
- 事务Hbase只可以实现单行的事务性,传统数据库是可以实现跨行的事务性。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |