

深入探究HDFS:高可靠、高可扩展、高吞吐量的分布式文件系统【上进小菜猪大数据系列】
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
上进小菜猪沈工大软件工程专业爱好敲代码持续输出干货。
引言
在当今数据时代数据的存储和处理已经成为了各行各业的一个关键问题。尤其是在大数据领域海量数据的存储和处理已经成为了一个不可避免的问题。为了应对这个问题分布式文件系统应运而生。Hadoop分布式文件系统Hadoop Distributed File System简称HDFS就是其中一个开源的分布式文件系统。本文将介绍HDFS的概念、架构、数据读写流程并给出相关代码实例。
一、HDFS的概念
HDFS是Apache Hadoop的一个核心模块是一个开源的分布式文件系统它可以在集群中存储和管理大型数据集。HDFS被设计用来运行在廉价的硬件上它提供了高可靠性和高可用性能够自动处理故障具有自我修复的能力。
HDFS的核心理念是将大型数据集划分成小的块通常是128 MB并在集群中的多个节点之间进行分布式存储。每个块都会被复制到多个节点上以提高数据的可靠性和可用性。HDFS还提供了高效的数据读写接口可以支持各种不同类型的应用程序对数据的读写操作。
二、HDFS的架构
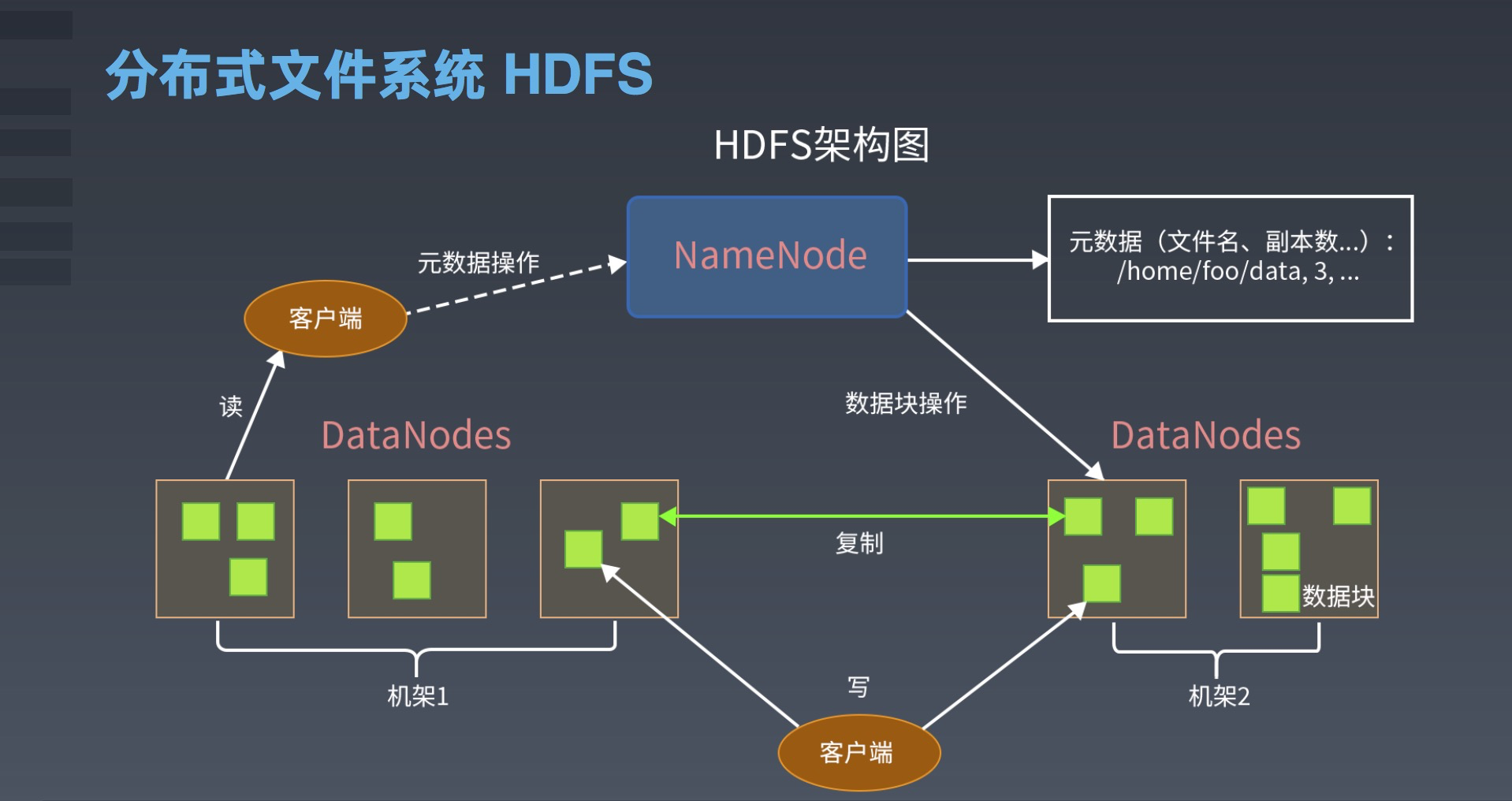
HDFS的架构包括NameNode、DataNode和客户端三个组件。
1.NameNode
NameNode是HDFS的核心组件它是集群中的中心节点用于管理文件系统的命名空间和客户端访问文件的元数据。NameNode维护了整个文件系统的命名空间和文件的层次结构它还维护了每个文件的块列表、块所在的DataNode列表以及每个块的副本数量。当客户端请求访问文件时它首先向NameNode发送请求NameNode根据元数据信息返回给客户端请求的数据块的位置信息。
2.DataNode
DataNode是HDFS的工作节点它负责存储实际的数据块并提供数据读写服务。当客户端需要读取或写入数据块时它会与DataNode通信DataNode返回请求的数据块并执行相应的读写操作。
3.客户端
客户端是使用HDFS的应用程序它通过HDFS提供的API来访问HDFS中存储的数据。客户端向NameNode发送文件系统的元数据请求并与DataNode进行数据交互。HDFS提供了Java和其他编程语言的API使得开发者可以方便地使用HDFS的功能。
三、HDFS的数据读写流程
HDFS的数据读写流程包括文件写入和文件读取两个过程
1.文件写入
在HDFS中文件的写入过程可以分为以下几个步骤
1客户端向NameNode发送文件写入请求。
2NameNode检查请求的文件是否存在如果不存在则创建新的文件并返回文件的元数据信息给客户端。如果文件已经存在则返回文件的元数据信息给客户端。
3客户端根据元数据信息将文件分割成一个个数据块并将每个数据块复制到多个DataNode上。
4客户端向NameNode发送数据块信息包括块的编号和块所在的DataNode列表。
5NameNode将块的信息存储在内存中并返回给客户端写入成功的信息。
6客户端开始向DataNode写入数据块如果一个DataNode写入失败则重新选择另一个DataNode进行数据复制。
7当所有数据块都写入完成后客户端向NameNode发送完成写入请求NameNode更新文件的元数据信息并返回写入完成的信息给客户端。
2.文件读取
在HDFS中文件的读取过程可以分为以下几个步骤
1客户端向NameNode发送文件读取请求。
2NameNode根据文件的元数据信息返回数据块的位置信息。
3客户端根据块的位置信息向DataNode请求读取数据块。
4DataNode返回数据块的内容给客户端。
5如果需要读取多个数据块则客户端继续向相应的DataNode请求读取数据块。
3.HDFS的优势
HDFS具有以下优势
1可靠性HDFS采用了数据复制机制每个数据块都会复制到多个DataNode上即使某个DataNode出现故障也不会影响文件的完整性和可用性。
2高可扩展性HDFS的设计理念就是高可扩展性通过添加更多的DataNode可以轻松地扩展文件系统的容量和性能。
3高吞吐量HDFS的设计目标是针对大数据量的处理因此具有高吞吐量的特性能够快速地读写大文件。
4适用于批处理HDFS适用于大规模的批处理任务例如MapReduce等。
4.HDFS的缺点
HDFS也有以下几个缺点
1不适合小文件存储由于HDFS采用了数据块的方式存储文件每个数据块的大小通常为64MB或128MB因此如果存储小文件会浪费大量的存储空间。
2不适合实时读写由于HDFS的设计目标是针对大数据量的处理因此不适合实时读写操作。
3复制带来的负载和成本HDFS采用了数据复制机制每个数据块都会复制到多个DataNode上这会增加系统的负载和成本。
5.HDFS的应用
HDFS已经被广泛地应用于大数据处理、数据分析等领域例如
1HadoopHadoop是一个分布式计算平台基于MapReduce和HDFS实现了大规模数据处理。
2SparkSpark是一个快速、通用、可扩展的大数据处理引擎可以与HDFS集成实现大规模数据处理。
3HBaseHBase是一个面向列存储的NoSQL数据库也是基于HDFS实现的。
4HiveHive是一个基于Hadoop的数据仓库可以将结构化数据映射为HDFS上的文件系统。
6.HDFS的代码实例
以下是一个简单的Java程序用于向HDFS中写入一个文件
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFSWriter {
public static void main(String[] args) throws Exception {
String localFilePath = "/home/user/data.txt";
String hdfsFilePath = "/user/hadoop/data.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
InputStream in = new FileInputStream(localFilePath);
fs.copyFromLocalFile(new Path(localFilePath), new Path(hdfsFilePath));
IOUtils.closeStream(in);
}
}
该程序首先需要指定要写入的本地文件路径和HDFS文件路径然后创建一个Configuration对象和FileSystem对象以便与HDFS进行交互。接下来使用copyFromLocalFile()方法将本地文件复制到HDFS中并使用closeStream()方法关闭输入流。
以下是一个简单的Java程序用于从HDFS中读取一个文件
import java.io.OutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFSReader {
public static void main(String[] args) throws Exception {
String localFilePath = "/home/user/data.txt";
String hdfsFilePath = "/user/hadoop/data.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
OutputStream out = new FileOutputStream(localFilePath);
IOUtils.copyBytes(fs.open(new Path(hdfsFilePath)), out, conf);
IOUtils.closeStream(out);
}
}
该程序首先需要指定要读取的本地文件路径和HDFS文件路径然后创建一个Configuration对象和FileSystem对象以便与HDFS进行交互。接下来使用open()方法打开HDFS中的文件使用copyBytes()方法将文件的内容复制到本地文件中并使用closeStream()方法关闭输出流。
四.总结
HDFS是一个高可靠、高可扩展、高吞吐量的分布式文件系统适用于大规模的数据处理和批处理任务。它的设计理念就是针对大数据量的处理因此不适合小文件存储和实时读写操作。HDFS已经被广泛地应用于大数据处理、数据分析等领域例如Hadoop、Spark、HBase、Hive等。通过上述的代码实例可以初步了解HDFS的基本操作方式。
当然HDFS还有很多其他的高级特性例如快照、权限控制、Federation等这些特性在大规模集群中是非常有用的。如果您想要深入了解HDFS可以继续学习Hadoop生态系统中的其他组件例如YARN、MapReduce、Hive、Pig、Spark等。
在实际应用中为了更好地管理和操作HDFS还需要使用一些工具。例如Hadoop自带的命令行工具hadoop fs可以方便地操作HDFS中的文件和目录例如创建目录、上传文件、下载文件等。此外还有一些第三方的图形界面工具例如Apache Ambari、Cloudera Manager、Hue等可以更加直观地管理HDFS集群。
总之HDFS是一个非常重要的分布式文件系统是Hadoop生态系统的核心组件之一。了解和掌握HDFS的基本概念和操作方式对于从事大数据处理和数据分析的工程师来说是非常必要的。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |