

Guava Cache介绍-面试用
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
一、Guava Cache简介
1、简介
Guava Cache是本地缓存数据读写都在一个进程内相对于分布式缓存redis不需要网络传输的过程访问速度很快同时也受到 JVM 内存的制约无法在数据量较多的场景下使用。
基于以上特点本地缓存的主要应用场景为以下几种
- 对于访问速度有较大要求
- 存储的数据不经常变化
- 数据量不大占用内存较小
- 需要访问整个集合
- 能够容忍数据不是实时的
2、对比
二、Guava Cache使用
下面介绍如何使用
1、先引入jar
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0-jre</version>
</dependency>
案例1
1、创建Cache对象在使用中我们只需要操作loadingCache对象就可以了。
LoadingCache<String, String> loadingCache = CacheBuilder.newBuilder()
.initialCapacity(5)//内部哈希表的最小容量也就是cache的初始容量。
.concurrencyLevel(3)//并发等级也可以定义为同时操作缓存的线程数这个影响segment的数组长度原理是当前数组长度为1如果小于并发等级且素组长度乘以20小于最大缓存数也就是10000那么数组长度就+1依次循环
.maximumSize(10000)//cache的最大缓存数。应该是数组长度+链表上所有的元素的总数
.expireAfterWrite(20L, TimeUnit.SECONDS)//过期时间过期就会触发load方法
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) {
//缓存不存在会进到load方法该方法返回值就是最终要缓存的数据。
log.info("进入load缓存");
return "手机号";
}
});
2、通过缓存获取数据
//获取缓存如果数据不存在触发load方法。
loadingCache.get(key);
案例2使用reload功能
1、生成缓存对象
ListeningExecutorService executorService = MoreExecutors.listeningDecorator(Executors.newSingleThreadExecutor());
LoadingCache<String, String> loadingCache = CacheBuilder.newBuilder()
.initialCapacity(5)
.concurrencyLevel(3)
.maximumSize(10000)
.expireAfterWrite(20L, TimeUnit.SECONDS)//超这个时间触发的是load方法
.refreshAfterWrite(5L, TimeUnit.SECONDS) //刷新超过触发的是reload方法
//.expireAfterAccess(...): //当缓存项在指定的时间段内没有被读或写就会被回收。
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) {
//缓存不存在或者缓存超过expireAfterWrite设置的时间进到load方法
log.info("进入load缓存");
return "手机号";
}
@Override
public ListenableFuture<String> reload(String key, String oldValue) throws Exception {
//超过refreshAfterWrite时间但是没有超过expireAfterWrite时间进到reload方法
log.info("进入reload缓存");
//这里是异步执行任务
return executorService.submit(() -> {
Thread.sleep(1000L);
return "relad手机号";
});
}
});
1、expireAfterWrite、refreshAfterWrite可以同时一起使用当然不同组合应对不同场景。
2、需要说明当缓存时间当超过refreshAfterWrite的时间但是小于expireAfterWrite设置的时间请求进来执行的是reload方法当时间超过expireAfterWrite时间那么执行的是load方法。
2、使用缓存对象
String value = loadingCache.get(key); //获取缓存
loadingCache.invalidate(key); //删除具体某个key的缓存
loadingCache.invalidateAll(Arrays.asList("key1","key2","key3"));//删除多个
loadingCache.invalidateAll(); //删除所有
三、源码
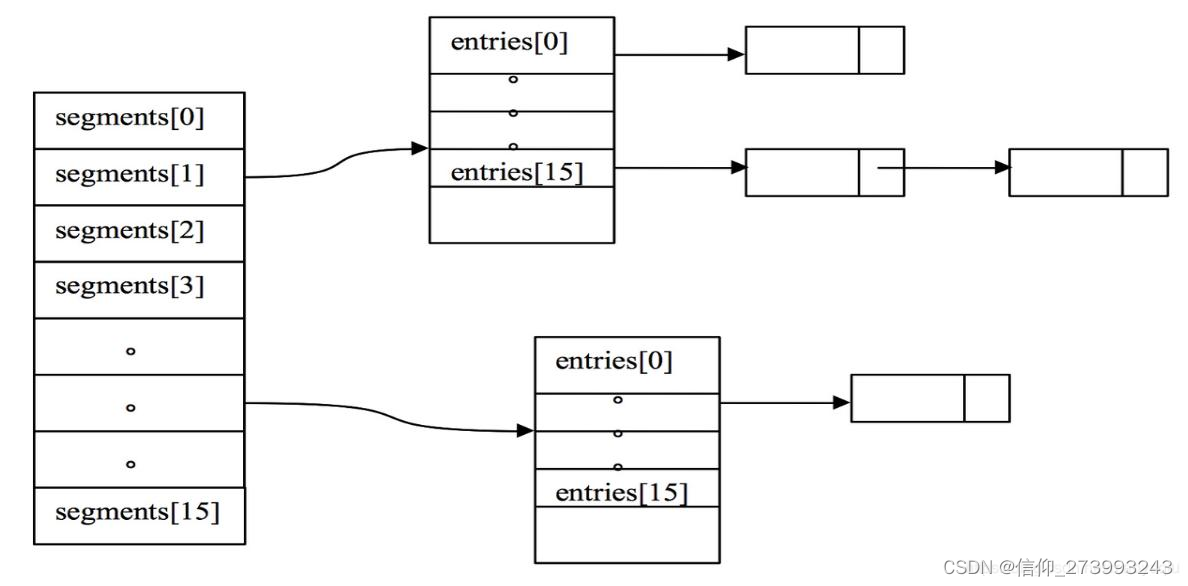
缓存对象底层是LocalLoadingCache类里面有个很重要的属性segments缓存数据都存在这个里面
//1、缓存对象
LocalLoadingCache{
//segments是一个数组每一个元素都是Segment类型
final Segment<K, V>[] segments;
}
//2、下面介绍下Segment这个类有哪些重要的属性
class Segment<K, V> extends ReentrantLock{ //继承了重入锁
//首先Segment里面有一个属性table这个table是AtomicReferenceArray类型
AtomicReferenceArray<ReferenceEntry<K, V>> table;
}
//3、下面看下AtomicReferenceArray到底有什么
AtomicReferenceArray{
//其实就是包裹了一个数组。每个元素都ReferenceEntry类型
private final Object[] array;
}
AtomicReferenceArray特别之处在于下
提供了可以原子读取、写入底层引用数组的操作并且还包含高级原子操作。比较特别的就是put操作就是我们在给该数组某个元素设置值的时候可以使用比较的方式来设置值。
例如AtomicReferenceArray.compareAndSet(2,10,20)
2下标位置10是新的值20是原来期望的值只有原来的值为20才会更新为10。
在回到上面AtomicReferenceArray里面的属性array里面每一个元素都是ReferenceEntry类型ReferenceEntry的实现类是StrongAccessWriteEntry
StrongAccessWriteEntry{
final K key;
//value存到了ValueReference对象里面只是ValueReference包装了一下,这个在并发的时候会用到。
volatile ValueReference<K, V> value;
final int hash;
final ReferenceEntry<K, V> next; //针对hash碰撞时拓展的链表。
}
结构图如下
四、下面介绍常用功能及其原理
1、获取数据
1、通过key生成hash根据hash从segments这个数组中得到具体下标该元素是Segment类型
2、从Segment里面的table里面获取也就是AtomicReferenceArray的array从里面获取数据此时拿到的是一个key所对应的StrongAccessWriteEntry对象。
3、StrongAccessWriteEntry里面会存下该hash碰撞所对应的其他key-value数据集合,StrongAccessWriteEntry对象保存了这个元素所对应的hashkey和valuenext还有过期时间如果过期了也会返回return, 如果没有过期会进行key对比只有一致才会返回。
4、获取的时候如果数据不存在就会调用下面的put方法。获取数据时是不使用lock()的。
2、put数据
在put前先lock()为什么可以使用锁因为继承了ReentrantLock
Segment<K, V> extends ReentrantLock {
.....
}
首先是通过Load方法拿到数据拿到后再通过storeLoadedValue方法来把结果写到缓存数据里面去在写入的时候也是用到了锁lock(); 所以这里就双重锁了。
先是通过hash结合算法得到下标在根据下标从AtomicReferenceArray数组中获取元素那么这个元素ReferenceEntry是一个有next的链表所以我们要遍历这个链表如果有key一致的我么就要把他覆盖掉。如果没有就使用set方法设置值。
3、删除数据
删除数据也是一样先lock();
拿到找到这个元素所在的位置然后删除掉
4、过期策略重点
过期配置主要包含着三个expireAfterWrite、refreshAfterWrite、expireAfterAccess下面分别介绍下这个三个作用
expireAfterWrite当缓存项在指定时间后就会被回收主动需要等待获取新值才会返回。
expireAfterAccess: 当缓存项在指定的时间段内没有被读或写就会被回收。
refreshAfterWrite当缓存项上一次更新操作之后的多久会被刷新。第一个请求进来执行load把数据加载到内存中同步过程指定的过期时间内比如10秒都是从cache里读取数据。过了10秒后没有请求进来不会移除key。再有请求过来才则执行reload在后台异步刷新的过程中如果当前是刷新状态访问到的是旧值。刷新过程中只有一个线程在执行刷新操作不会出现多个线程同时刷新同一个key的缓存。在吞吐量很低的情况下如很长一段时间内没有请求再次请求有可能会得到一个旧值这个旧值可能来自于很长时间之前这将会引发问题。可以使用expireAfterWrite和refreshAfterWrite搭配使用解决这个问题
//是否更新过期时间判断条件
void recordWrite(ReferenceEntry<K, V> entry, int weight, long now) {
// we are already under lock, so drain the recency queue immediately
drainRecencyQueue();
totalWeight += weight;
if (map.recordsAccess()) { //这个判断条件是expireAfterAccess>0
entry.setAccessTime(now); //设置过期时间
}
if (map.recordsWrite()) { //这个判断条件是expireAfterWrite>0
entry.setWriteTime(now); //设置过期时间
}
accessQueue.add(entry);
writeQueue.add(entry);
}
后续每次读的时候如果存在设置了expireAfterAccess就会每次把过期时间更新掉。
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
那么在获取数据的时候是如何判断是否执行reload的源码里面有明确的判断
V scheduleRefresh(ReferenceEntry<K, V> entry, K key, int hash, V oldValue, long now, CacheLoader<? super K, V> loader) {
if (map.refreshes() && (now - entry.getWriteTime() > map.refreshNanos)) {
V newValue = refresh(key, hash, loader, true);
}
}
//map.refreshes()主要是判断 refreshNanos > 0
//也就是代码中build的refreshAfterWrite(2L, TimeUnit.MINUTES)代码。设置了refreshNanos的时间。
场景1: 当前时间减去缓存到期时间结果大于过期时间才会执行refresh方法就会从reload里面获取数据。
场景2当然还有一种情况就是既设置了refreshAfterWrite又设置了expireAfterWrite这个情况是优先判断数据是否过期了如果并且过期时间超了那么就执行load方法如果没有超过过期时间超过了refresh的过期时间那么就执行reload方法代码如下
//判断是否过期
if (map.isExpired(entry, now)) {
return null;
}
//看下isExpired的逻辑
boolean isExpired(ReferenceEntry<K, V> entry, long now) {
//这里忽略
if (expiresAfterAccess() && (now - entry.getAccessTime() >= expireAfterAccessNanos)) {
return true;
}
//判断是否设置了expireAfterWriteNanos时间且当前时间减去过期时间是否超过expireAfterWriteNanos超过则说明数据已经过期了。
if (expiresAfterWrite() && (now - entry.getWriteTime() >= expireAfterWriteNanos)) {
return true;
}
return false;
}
2、解决缓存击穿
缓存击穿假如在缓存过期的那一瞬间有大量的并发请求过来。他们都会因缓存失效而去加载执行db操作可能会给db造成毁灭性打击。
解决方案: 采用expireAfterWrite+refreshAfterWrite 组合设置来防止缓存击穿expire则通过一个加锁的方式只允许一个线程去回源有效防止了缓存击穿但是可以从源代码看出在有效防止缓存击穿的同时会发现多线程的请求同样key的情况下一部分线程在waitforvalue而另一部分线程在reentantloack的阻塞中。
//当数据过期了先拿到数据的状态如果是正在执行load方法则其他线程就先等待
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
//关键在于valueReference对象他有2种两类不同类型代表不同状态。
1、一开始创建的时候valueReference是LoadingValueReference类型对象。这个在刚创建entity的时候会用到。也就是load方法被执行前LoadingValueReference固定是返回true
2、当load方法被加载完valueReference类型就变成StrongValueReference。load执行完后更新entity的类型。StrongValueReference的isLoading方法固定是false
3、当数据过期时
3、刷新时拿到的不一定是最新数据
因为如果因为过期执行刷新的方法也就是reload方法那么从缓存里面拿到的数据不一定是新数据可能是老数据为什么因为刷新时异步触发reload不像load同步这种源码如果reload的返回null那么会优先使用oldValue数据。
V scheduleRefresh(ReferenceEntry<K, V> entry, K key, int hash, V oldValue, long now, CacheLoader<? super K, V> loader) {
if (map.refreshes() && (now - entry.getWriteTime() > map.refreshNanos)) {
V newValue = refresh(key, hash, loader, true); //执行刷新的方法也就reload方法下面看下refresh做了什么操作
if (newValue != null) {
return newValue;
}
}
return oldValue;
}
refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
//通过异步去执行reload方法注意是异步此时没有完成那么直接返回null那么上面的scheduleRefresh方法直接返回的是oldValue也就是老数据。
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
}
}
return null;
}
所以缓存失效第一次数据不一定是最新的数据。可能是老的数据因为是异步执行reload方法不知道耗时会有多久所以主线程不会一直去等子线程完成。关注下主线程在子线程执行reload会等多久
4、总结
1、refreshAfterWrites是异步去刷新缓存的方法可能会使用过期的旧值快速响应。
2、expireAfterWrites缓存失效后线程需要同步等待加载结果可能会造成请求大量堆积的问题。
四、注意点
在重写load的时候如果数据是空要写成"",不能是null,因为在put的时候会判断返回的值如果是null就会抛出下面异常
@Override
public String load(String key) {
return ...
}
//当load返回为空时会抛出异常
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |