

MySQL 排序,分组,Limit的优化策略-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
3.2 减少ORDER BYGROUP BYDISTINCT
1. MySQL 中的两种排序方式
在MySQL中主要支持两种排序方式分别是 FileSort 和 Index。
Index索引排序就是我们给排序的字段添加了索引因为索引本身就是有序的所以我们在根据排序的时候就非常省时间了不需要进行重排序直接取出数据即可效率很高。
FileSort文件排序在查询到数据之后因为没有设置索引所以CPU就需要在内存中进行排序排好序之后再将数据进行返回而且数据量如果较大排序花费时间也会变长并且如果数据量非常大内存中装不下还需要多次IO操作先读取一部分数据排序再读取一部分数据排序效率较低。
2. 排序优化策略
2.1 对排序字段添加索引
从上面两种排序方式不难看出Index 索引排序明显是要比 FileSort 内存排序效率要高的因此我们最好能够在排序字段上添加索引这样在查询的时候就取出来的就是有序数据省去了排序时间
如下所示我查询 employees 员工表并通过 salary 薪水字段排序此时还没有给 salary 字段设置索引查询到107条数据花费 0.024秒
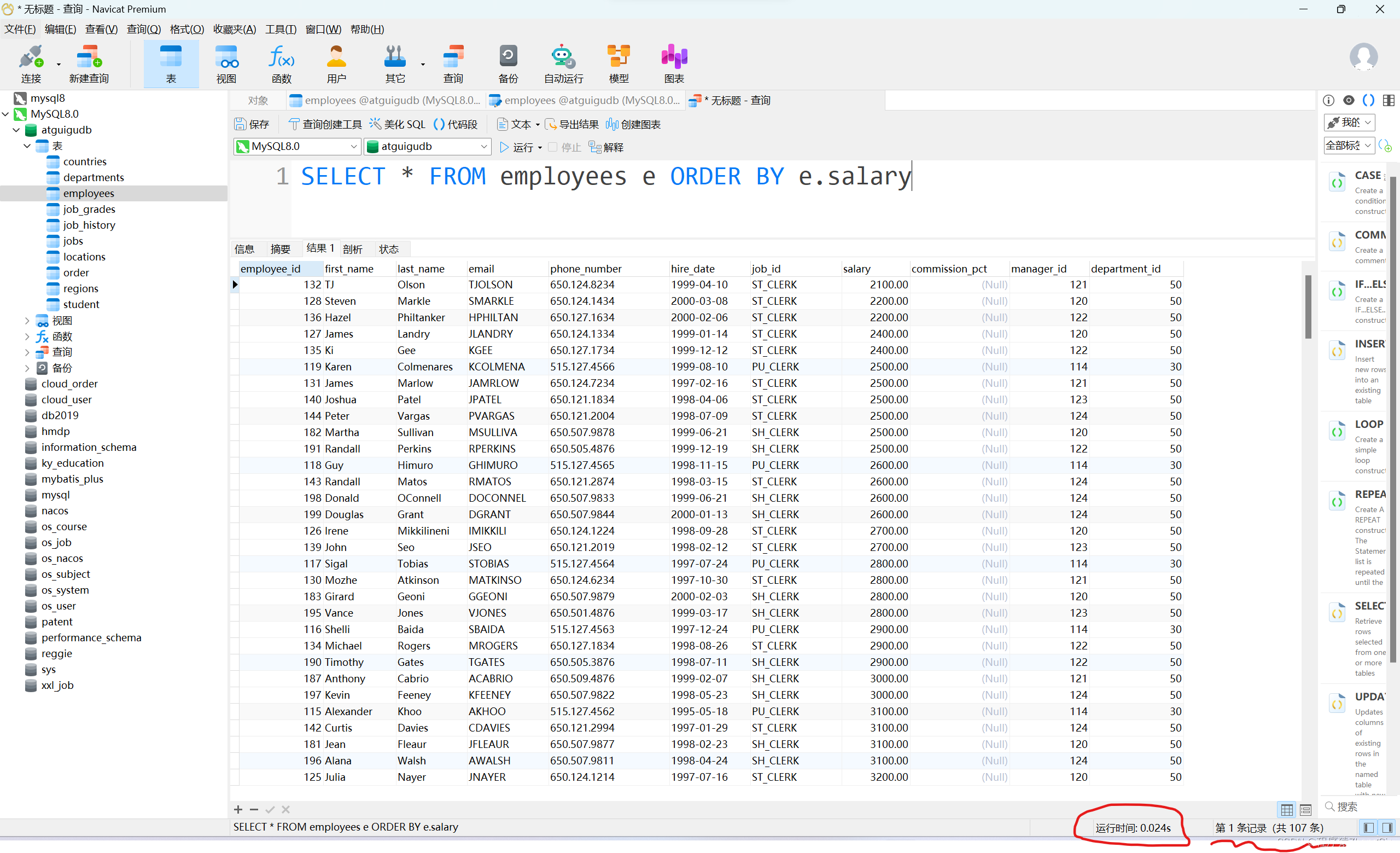
我现在给 salary 薪水字段设置一个普通索引然后再去做一遍查询
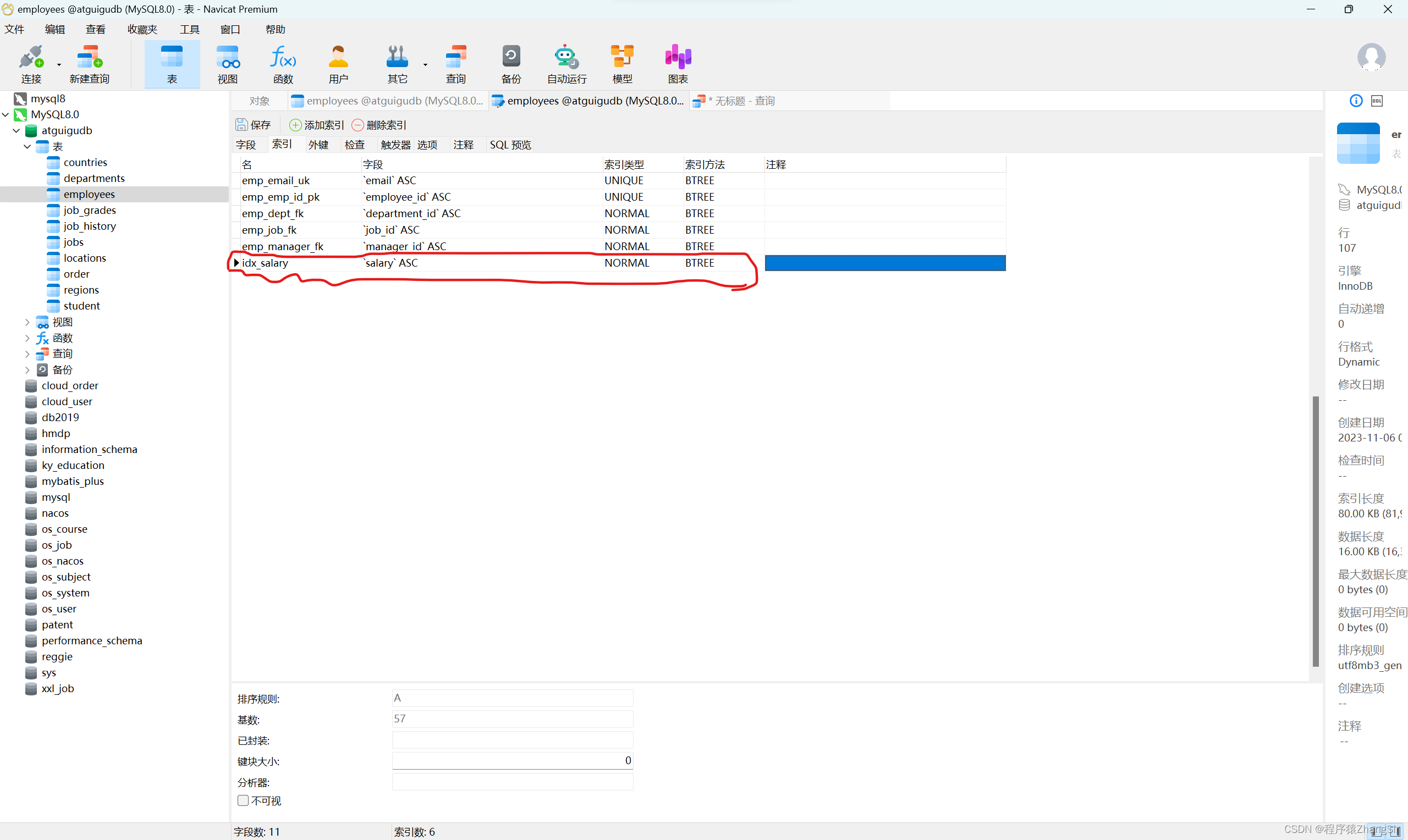
可以看到再添加过索引之后让然查询到了107条数据时间缩短为0.017秒可能同学们觉得没有什么差别这只是因为数据量小的原因只有一百多条记录如果有上千条上万条数据花费的时间一下子就拉开距离了。

2.2 可以和WHERT字段创建联合索引
在SQL语句中排序通常也会出现WHERE过滤字段在这种情况下我们可以考虑给WHERE过滤字段和ORDER BY排序字段建立一个联合索引。如果二者是同一个字段那就更完美了就给这个字段建立独立索引如果是两个字段建立联合索引但要注意WHERE过滤如果是范围查找会导致联合索引中后续索引失效那么即便设置了排序字段索引也是用不上的。在设置联合索引时一定要注意满足最左前缀原则保证索引能够生效。
如下此时 department_id 和 salary 字段都有索引但是没有联合索引所以查询的时候只会用到 department_id 这个字段的索引
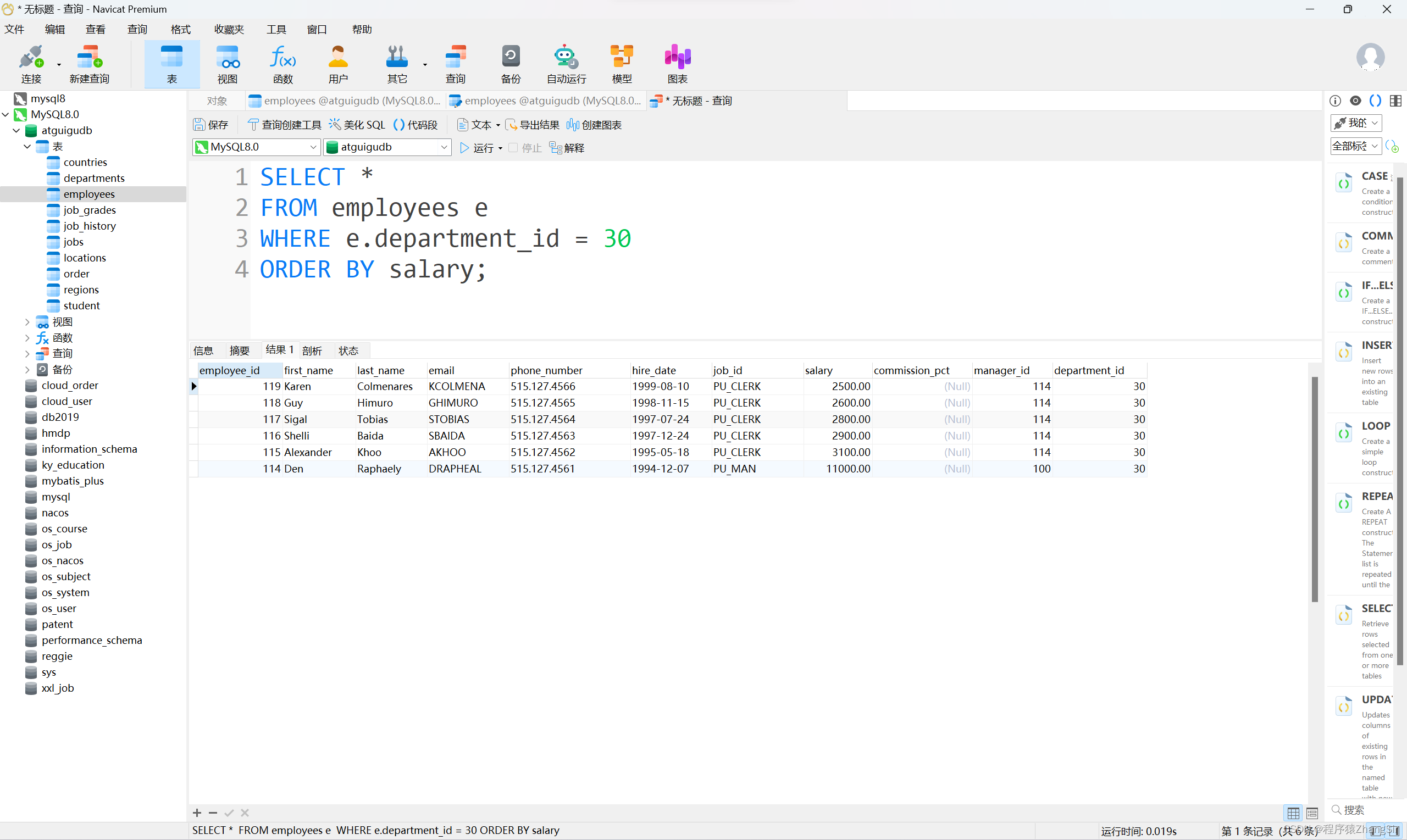
此时我给 department_id 和 salary 建立联合索引再次查询
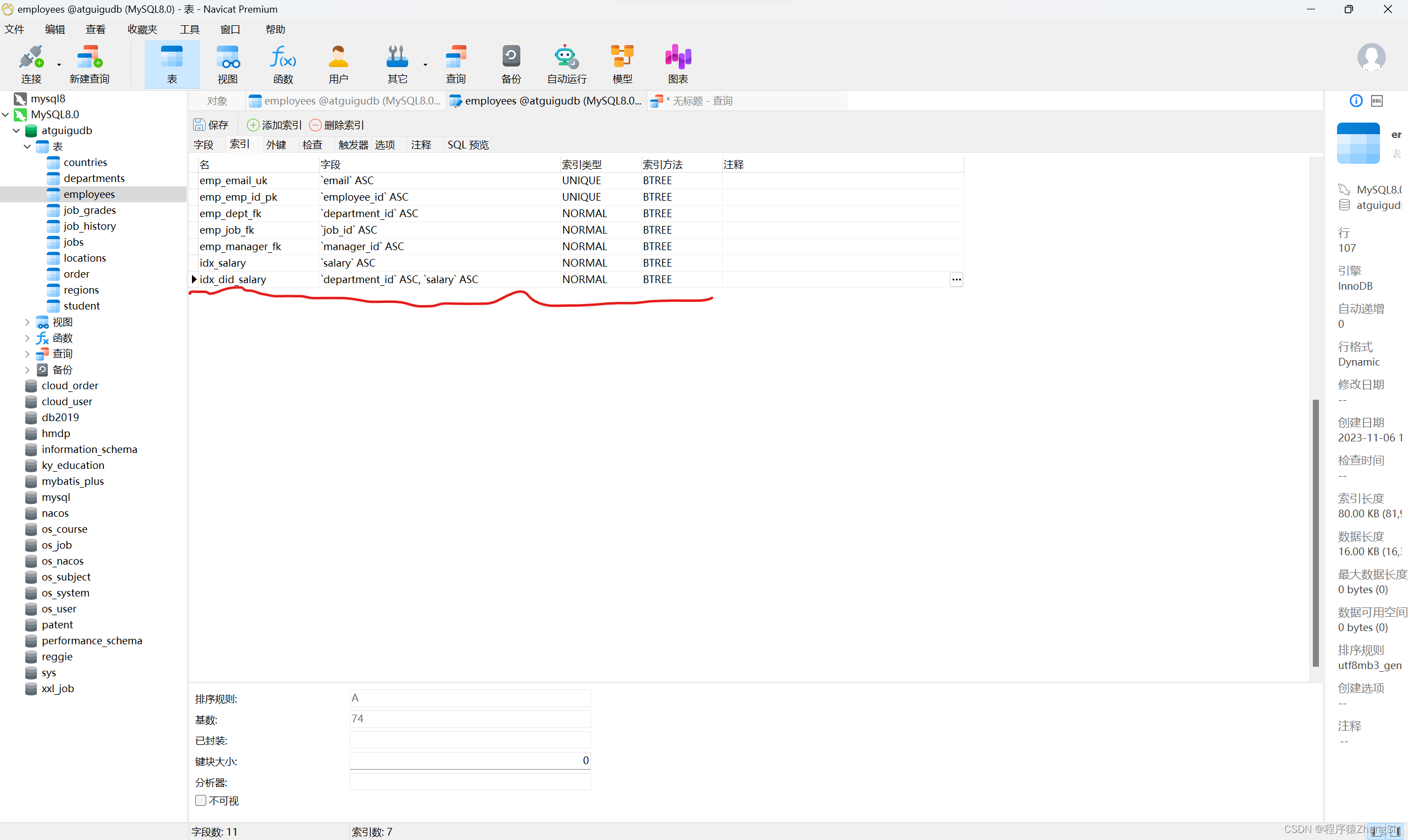
查询得到相同的结果使用联合索引时间0.017秒比单独使用 department_id索引快了 0.02秒
2.3 优化 FilerSort 排序方式
有些时候我们无法避免的会出现 FileSort 内存排序其实内存排序有两种方式分别是双路排序和单路排序。
双路排序扫描两次磁盘数据库会先将需要排序的字段IO加载到内存中进行排序经过排序之后再根据排好序的字段再次IO将完整数据查询出来
单路排序数据库会一次性将全部数据加载到内存然后进行排序并且在IO的时候是顺序IO读取读取过后再排序比双路排序要好。因为双路排序在第二次IO读取数据的时候是根据排好序的顺序读取数据的是随机IO明显没有顺序IO要快。但如果数据量较大就对内存要求较高但现在内存技术发展迅速内存已经不值钱了所以通常建议采用单路排序。
3. 分组优化策略
3.1 能WHERE不HAVING
HAVING也是一个过滤关键字它后面可以使用聚合函数再次过滤但是建议能在WHERE后面写的过滤条件就不要写在HAVING后面WHERE过滤之后剩下的少量数据无论是排序还是分组都只会花费很少的时间所以能WHERE过滤的数据就不要用HAVING。
3.2 减少ORDER BYGROUP BYDISTINCT
对于数据库而言排序分组去重这些操作都是比较繁琐耗费资源的如果将所有操作全部放在数据库中非常容易出现慢查询因此我们可以考虑将这些操作放在程序端去做数据库查询到数据之后使用程序代码进行排序分组去重
3.3 遵照最左前缀法则
GROUP BY使用索引的规则几乎与ORDER BY一样尽量遵循索引最左前缀原则
4. Limit 优化策略
有些极端情况如下我取第十万条记录之后的十条记录这种情况下数据库就会把所有的数据全部加载到内存中分页排序之后只取第一万条记录之后的十条记录做了大量的无用功。
SELECT * FROM employees ORDER BY employee_id LIMIT 10000,10;那么我们就可以对上面的SQL做修改直接使用WHERE过滤前一万条数据从第10001条记录开始取。提高效率但实际上这种情况很少发生如果真的有有这种需求建议直接将10000作为WHERE的一个过滤条件
SELECT * FROM employees WHERE employee_id > 10000 LIMIT 10000,10;