

【Java IO流】字符集使用详解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
上一节关于字节流的文章中在使用字节流读取本地文件中的数据时文件中只存放了英文而并没有存放中文数据。我们还提到了不建议使用字节流读取纯文本文件的数据否则会出现乱码的情况那么为什么会出现这样的情况呢相信探讨完今天的内容你会有新的理解。
在计算机中任何数据都是以二进制的形式存储的一位二进制数称为一个比特位一个字节由 8 位二进制数组成存放 2 的 8 次方个数据字节是计算机中最小的存储单元。
而英文存放数据只需要一个字节即可为什么呢这就需要我们学习字符集的知识字符集也叫作编码表例如 ASCII 字符集把一些常用的字符编写为一个表每个字符对应了一个整数值ASCII 表中一共 128 个数据其中英文就全部包括在其中所以说存放英文数据至于要一个字节即可。
目前的文字编码标准主要有 ASCII、GB2312、GBK、Unicode 等。ASCII 编码是最简单的西文编码方案。GB2312、GBK、GB18030 是汉字字符编码方案的国家标准。Unicode 是全球字符编码的国际标准 。
ASCII
计算机以二进制的形式存储数据例如 abc 这样的字符和 1,2,3 这样的数字以及 + -* 等这样的符号都是使用二进制在计算机中存储的但是具体哪个二进制数字代表了哪个字符没有统一的标准此时就需要规定一个标准于是产生了 ASCII 字符集。ASCII 字符集由美国相关组织规定其中共有 128 个数据。
详细的信息可以查看 ASCII 码表常用的字符有 48 到 57 是十个阿拉伯数字65 到 90 是 26 个大写英文字母97 到 122 是小写英文字母。
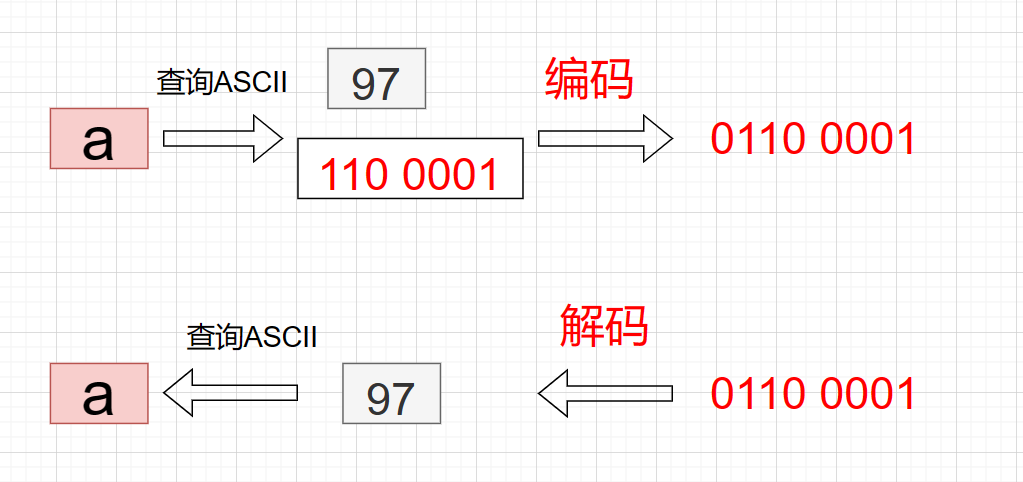
在字符集中查询到的数据不会直接存储到计算机中这里涉及到编码和解码的概念编码就是把字符集中查询到的数据按照一定的规则进行计算变成真实的存储在计算机硬盘中的二进制数据的过程解码就是把实际存储在计算机中的二进制数据按照一定的规则进行计算变成字符集中的数值的过程。ASCII字符集编码就是直接在前面补 0 解码时直接转换为十进制。
下面表示的是计算机的存储规则
ASCII 表中只包含了一些欧洲国家常用的字符并没有包含汉字。我们国家在1980年发布了 GB2312国标字符集其中包含了常用图形字符和简体中文台湾地区发布了繁体中文字符集 BIG5 为了统一标准2000年我国发布了 GBK 字符集包含了常用的中日韩文字等。随着计算机的发展又出现了 Unicode 字符集他将世界每个语言的字符集定义了一个唯一的编码。
我们使用的简体中文版 Windows 系统默认使用 GBK 字符集不同的 Windows 使用不同版本的字符集统一称为 ANSI 。
GBK
我们主要学习英文和汉字是如何使用字符集在计算机中存储数据的。
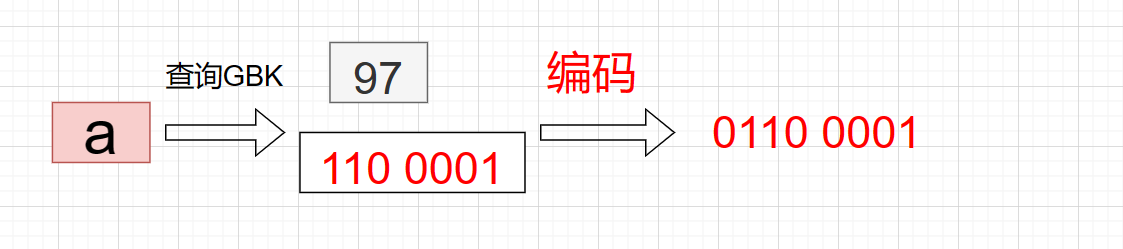
在 GBK 中英问同样使用一个字节存储因为它完全兼容 ASCII 字符集在存储时编码规则与 ASCII 相同
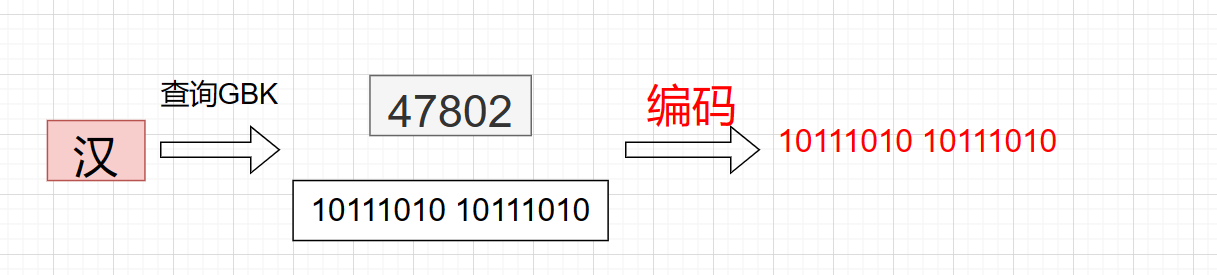
在 GBK 字符集中汉字使用两个字节存储因为一个字节最多存储 256 个数据显然是不够的。GBK字符集中左边 8 位称为高位字节右边 8 为称为低位字节高位字节转为十进制必须是一个负数且高位字节第一个二进制数一定是 1 这样做是为了区分汉字和英文在读取数据时当出现 1 时计算机会认为读取到了汉字此时会把两个字符的数据解码为一个汉字。
Unicode
不同的国家使用不同的字符集显然是不利于软件的发展的为了统一规则出现了 Unicode 字符集。Unicode 字符集由世界各地的软件开发商电脑制造商等组成的统一码联盟制定的。
同样的Unicode 完全兼容 ASCII 字符集但是其编码规则有所不同。例如 UTF-16使用 2-4 个字节UTF-32固定使用 4 个字节UTF-8等其中 UTF-8 是我们实际开发中常用的编码方式其使用 1 到 4 个字节的可变字符编码。
在 UTF-8 字符编码规则中ASCII字符集中的字符使用 1 个字节存储中日韩文字等使用 3 个字节存储其具以下的规则

例如 “汉” 字在 Unicode 字符集中是 47802转化为二进制是1011101010111010其进行 UTF-8 编码以后是
11101011 1010101010 10111010
为什么会出现乱码
在 Java 中程序出现乱码可能是下面的问题导致的
- 读取数据时未读完整个汉字
- 编码方式和解码方式不统一
我们知道使用字节流读取数据时默认一次只能读取一个字节的数据而 UTF-8 编码方式中使用三个字节存储一个汉字此时就可能出现没有读完整个汉字的情况于是就出现了乱码。
编码方式和解码方式不同时也会出现乱码。例如存储一个汉字时使用 UTF-8 的方式编计算机会使用 3 个字节存储该数据如果此时使用 GBK 的方式解码就会出现乱码的情况。
所以为了避免出现乱码我们不能使用字节流读取文本文件并且要保证编码和解码的方式统一。回到前言中的问题现在我们已经不难理解。
Java 中使用以下的方法进行编码和解码
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
/*
编码和解码的使用
*/
String s="Java你好";
byte[] bytes = s.getBytes();
System.out.println(Arrays.toString(bytes));
String s2=new String(bytes);
System.out.println(s2);
}
}
此时Java 使用 IDE 默认的编码方式进行编码我们还可以使用 getBytes() 方法的重载方法指定编码方式使用指定编码方式编码时可能会出现异常抛出即可。如果编码和解码的方式不统一会出现乱码。
示例
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
String s="Java你好";
byte[] bytes = s.getBytes("GBK");
System.out.println(Arrays.toString(bytes));
String s2=new String(bytes);
System.out.println(s2);
}
}
我们指定了字符串使用 GBK 的方式编码当使用默认的 UTF-8 再次解码时控制台出现乱码。