

Python爬虫系列(四)(简单)Dota排行榜爬取,并存入Excel表格
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
在编写Python程序的时候,有很多库供我们选择,如urllib、requests,BeautifulSoup,lxml,正则表达式等等,使得我们在获取网页源代码或者选择元素的时候很方便,但是库多了,自己纠结症也犯了。。。额。自己今天爬的是对战平台的DOTA排行榜(ps:我在简书看到的一个评论,关于这个网站的,索性自己爬下了-_-),巩固下知识吧。
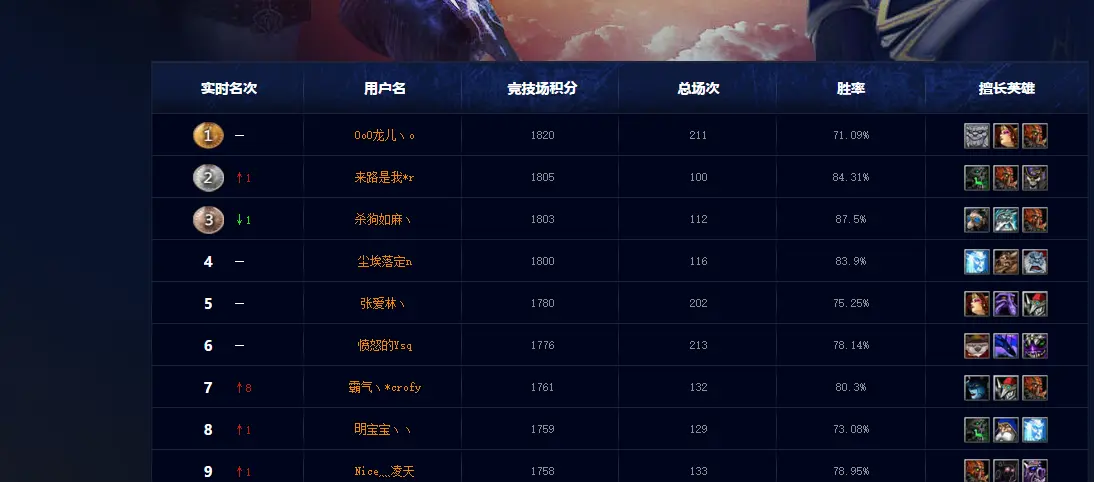
排行榜
1、分析网站
打开开发者工具,我们观察到排行榜的数据并没有在doc里
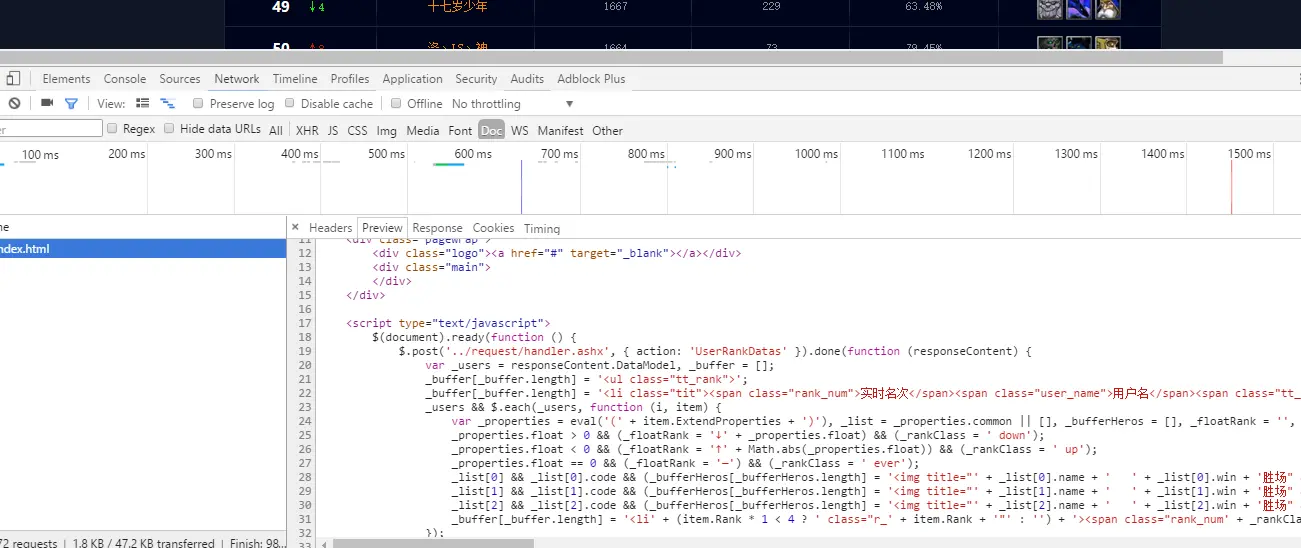
doc文档
在Javascript里我么可以看到下面代码:

ajax的post方法异步请求数据
在 XHR一栏里,我们找到所请求的数据
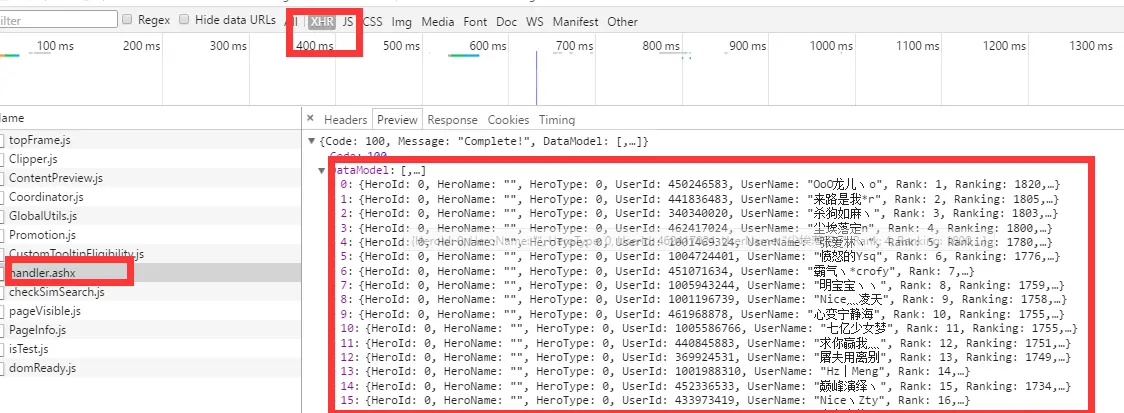
json存储的数据
请求字段为:

post请求字段
2、伪装浏览器,并将json数据存入excel里面
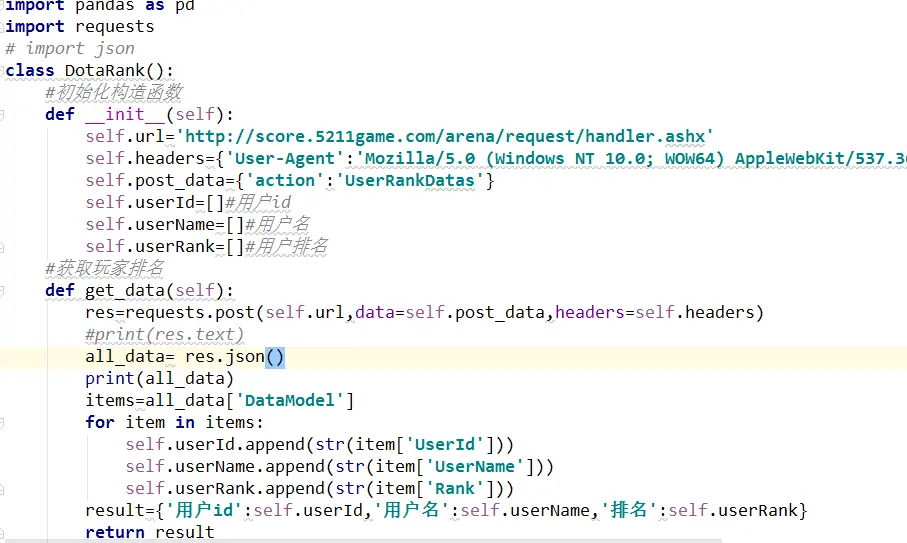
获取玩家信息
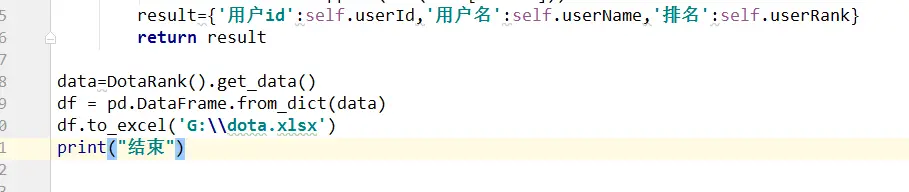
将数据保存到excel中
3、结果展示
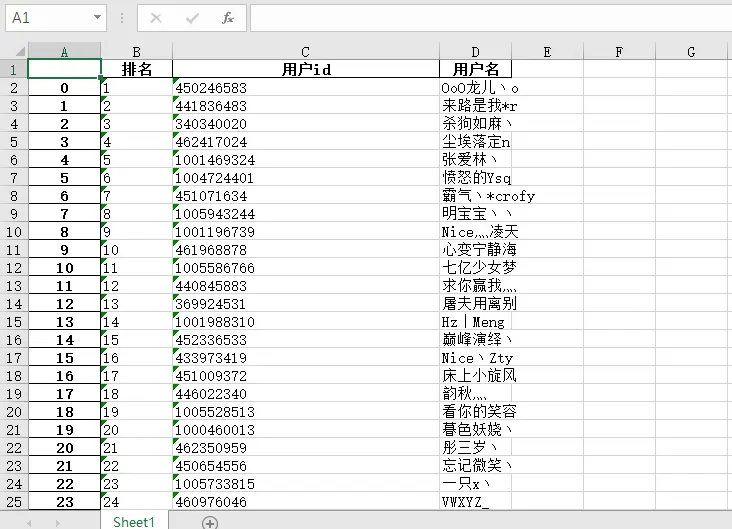
保存的数据
4、总结
在掌握一些基本的爬虫知识之后,自己想做一些爬虫进阶的实战项目,比如使用一些框架(scrapy、pyspider等)、还有使用代理池等等。还有很多知识要学习自己加油吧。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |