

大数据|Hadoop系统
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
📚Hadoop介绍
Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架它实现了Map/Reduce计算模型。
狭义上说Hadoop的核心组件有
- HDFS分布式文件系统解决海量数据存储
- MapReduce分布式运算编程框架解决海量数据计算
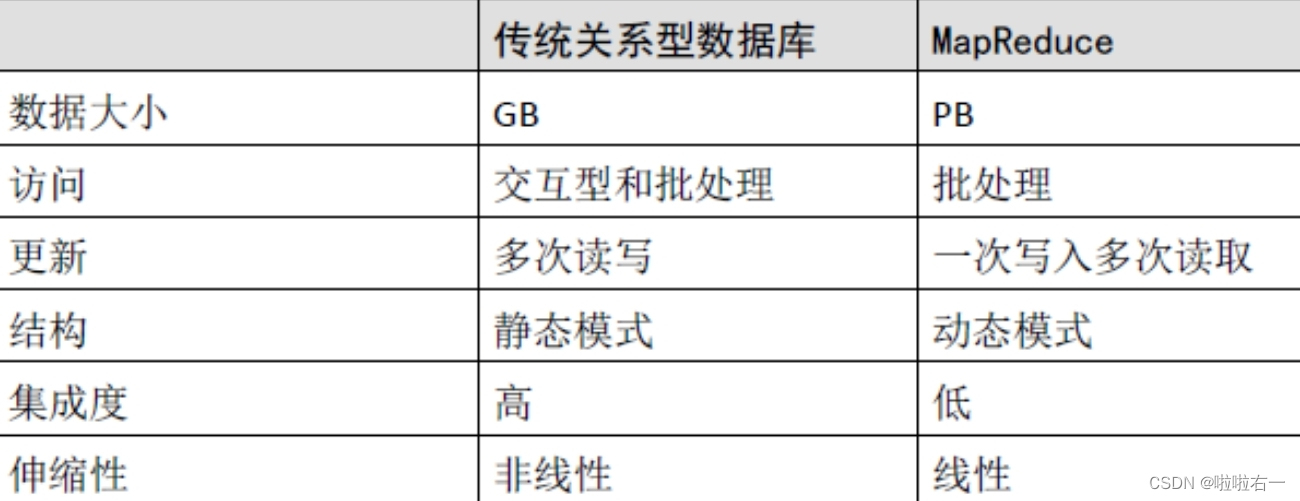
- YARN作业调度和集群资源管理的框架解决资源任务调度
📚Hadoop优点
- Hadoop是可靠的因为它假设计算元素和存储会失败因此它维护多个工作数据副本确保能够针对失败的节点重新分布处理。
- Hadoop是高效的因为它以并行的方式工作通过并行处理加快处理速度。
- Hadoop是可伸缩的它能够处理PB级数据即有扩容能力。
- Hadoop成本低依赖于廉价服务器因此它的成本比较低任何人都可以使用。
由于Hadoop优势突出基于Hadoop的应用已经遍地开花尤其是互联网领域。

📚Hadoop的体系结构
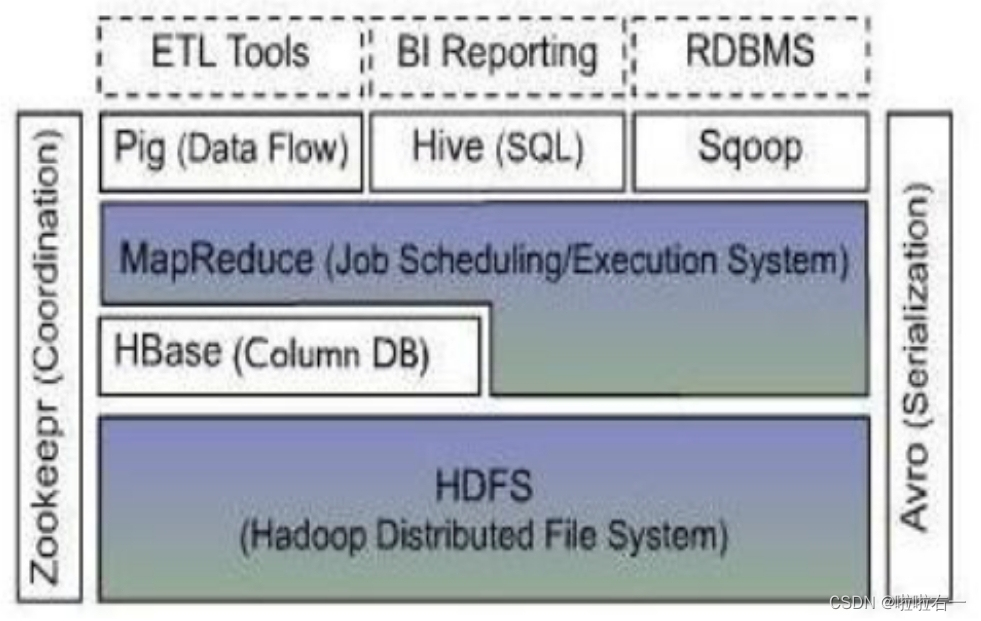
- HDFS是一种分布式文件系统运行于大型商用机集群HDFS提供了高可靠性的底层存储支持。
- HBase位于结构化存储层是一个分布式的列存储数据库。
- MapReduce是一种分布式数据处理模式和执行环境。
- Zookeeper是一个分布式的高可用性的协调服务提供分布式锁之类的基本服务。
- Hive是一个建立在Hadoop基础上的数据仓库用于管理存储于HDFS或HBase中的结构化/半结构化数据。
- Pig提供一种数据流语言程序员可以将复杂的数据分析任务实现为Pig操作上的数据流脚本这些脚本可自动转换为MapRduce任务链在Hadoop上执行从而简化工作难度。
- Sqoop是SQL-to-Hadoop的缩写为在RDBMS与Hadoop平台间进行快速批量数据交换。
🐰HDFS的体系结构
- 一个HDFS集群是由一个NameNode和若干个DataNode组成。
- NameNode作为主服务器管理文件系统的命名空间和客户端对文件的访问操作
- 集群中的DataNode管理存储的数据。
- HDFS支持用户以文件的形式存储数据文件被分为若干个数据块而且这若干个数据块存放在一组DataNode上。
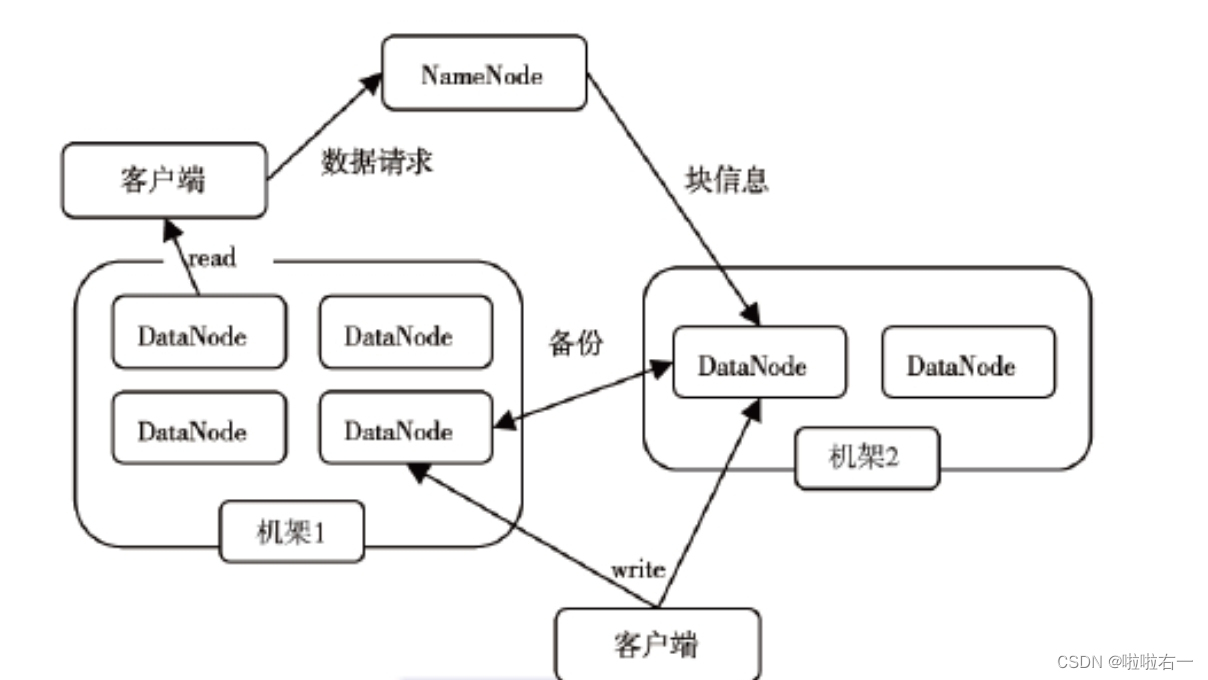
NameNode就是master它是一个主管管理者。管理HDFS的命名空间管理数据块(Block)映射信息配置副本策略处理客户端读写请求。
DataNode就是Slave它是劳累的打工人。NameNode下达命令DataNode执行实际操作。存储实际的数据块执行数据块的读写操作定时向NameNode汇报block信息。
🐰MapReduce的体系结构
- MapReduce是一种并行编程模式。基于它可以将任务分发到由上千台商用计算机组成的集群上并以一种高容错的方式并行处理大量的数据集实现Hadoop的并行任务处理功能。
- MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成的。
- 主节点负责调度构成一个作业的所有任务这些任务分布在不同的从节点上主节点监控它们的执行情况并且重新执行之前失败的任务。从节点仅负责由主节点指派的任务。
- 当一个Job被提交时JobTracker接受到提交作业和配置信息之后就会将配置信息等分发给从节点同时调度任务并监控TaskTracker的执行。
🌟MapReduce编程模型与Hadoop分布式开发息息相关下文会做详细介绍。
🐰HDFS和MapReduce的协同作用
- HDFS在集群上实现了分布式文件系统MapReduce在集群上实现了分布式计算和任务处理。
- HDFS在MapReduce任务处理中提供了文件操作和存储等支持MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作并收集结果。
- TaskTracker和DataNode需配对地设置在同一个物理的从节点服务器上JobTracker和NameNode可以设置在同一个物理主控节点服务器上也可以分开设置
HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心二者相互作用完成了Hadoop分布式集群的主要任务。
📚Hadoop与分布式开发
基于MapReduce的处理过程示例--文档词频统计WordCount
- 将大数据集分解为成百上千个小数据集每个或若干个数据集分别由集群中的一个节点进行处理并生成中间结果然后这些中间结果又由大量的节点合并形成最终结果。
- MapReduce框架下并行程序结构中需要用户完成的工作仅仅是根据任务编写Map和Reduce函数。


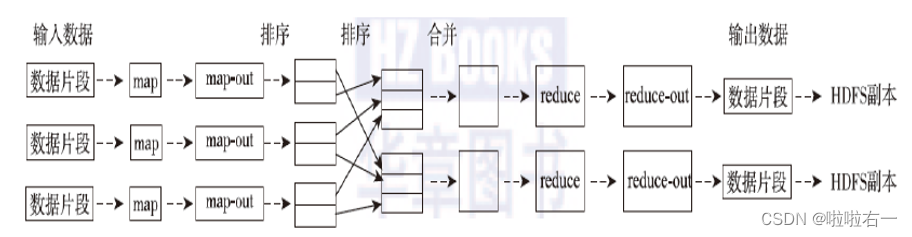
🐰MapReduce计算模型
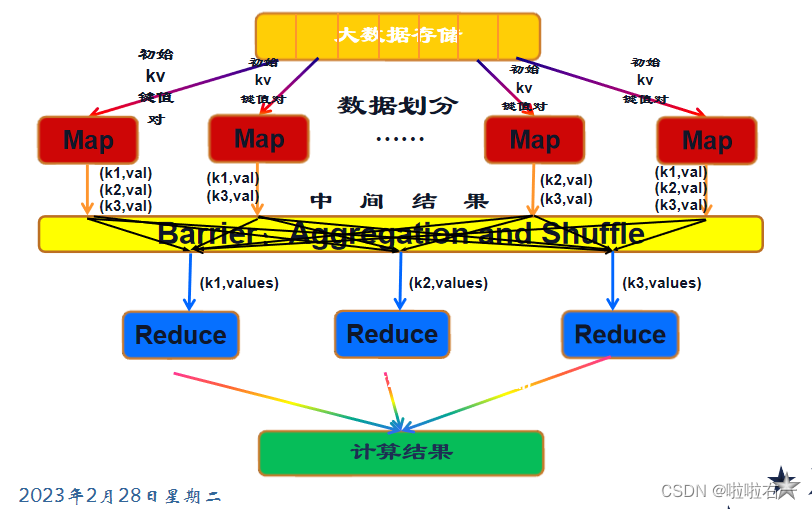
MapReduce编程模型的原理利用一个输入的key/value对集合来产生一个输出的key/value对集合。这个过程基于Map和Reduce这两个用户自定义函数实现。
- Map阶段是在单机上进行的针对一小块数据的计算过程简单来说就是按照给定的方法进行筛选分类。
- Shuffle阶段在map阶段的基础上进行数据移动为后续的reduce阶段做准备。简单说就是shuffle将同类型的数据进行合并。
- Reduce阶段对移动后的数据进行处理依然是在单机上处理一小份数据举个例子对Shuffle得到的合并后的数据进行count得到sum值。
关于Shuffle
- shuffle的意思就是洗牌它是MapReduce的核心也是被称为奇迹发生的地方。MapReduce玩的就是洗数据然后让数据出现在该出现的位置。
碎碎念
- Shuffle阶段所进行的洗牌可借助哈希表实现将对应的数据放到相应的“桶”里从而实现同类型的合并。
- MapReduce思想有种“分而冶之”的味道。Map负责“分”Reduce负责“合”。
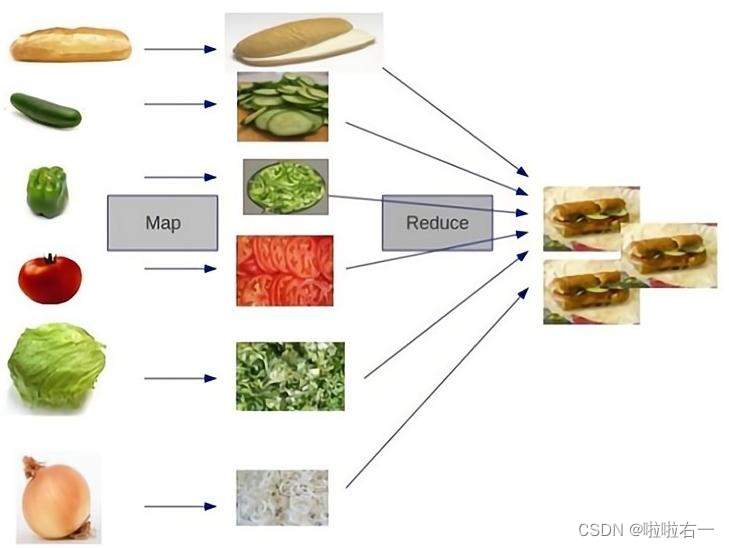
参考博客Lansonli【Hadoop专栏】
be happy——
