

Pytorch从零开始实战07-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Pytorch从零开始实战——咖啡豆识别
本系列来源于365天深度学习训练营
原作者K同学
文章目录
环境准备
本文基于Jupyter notebook使用Python3.8Pytorch2.0.1+cu118torchvision0.15.2需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是手写VGG并且测试多GPU。
第一步导入常用包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
创建设备对象并且查看GPU数量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count()
数据集
本次使用的数据集是咖啡豆图片它分为四个类别Dark、Green、Light、Medium一共有1200张图片不同的类别存放在不同的文件夹中文件夹名是类别名。
使用pathlib查看类别
import pathlib
data_dir = './data/beans'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['Dark', 'Green', 'Medium', 'Light']
使用transforms对数据集进行统一处理并且根据文件夹名映射对应标签
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
total_data = datasets.ImageFolder("./data/beans/", transform=train_transforms)
total_data.class_to_idx # {'Dark': 0, 'Green': 1, 'Light': 2, 'Medium': 3}
随机查看5张图片
def plotsample(data):
fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图
for i in range(5):
num = random.randint(0, len(data) - 1) #首先选取随机数随机选取五次
#抽取数据中对应的图像对象make_grid函数可将任意格式的图像的通道数升为3而不改变图像原始的数据
#而展示图像用的imshow函数最常见的输入格式也是3通道
npimg = torchvision.utils.make_grid(data[num][0]).numpy()
nplabel = data[num][1] #提取标签
#将图像由(3, weight, height)转化为(weight, height, 3)并放入imshow函数中读取
axs[i].imshow(np.transpose(npimg, (1, 2, 0)))
axs[i].set_title(nplabel) #给每个子图加上标签
axs[i].axis("off") #消除每个子图的坐标轴
plotsample(total_data)

根据8比2划分数据集和测试集并且利用DataLoader划分批次和随机打乱
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size,
shuffle=True,
)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size,
shuffle=True,
)
len(train_dl.dataset), len(test_dl.dataset) # (960, 240)
模型选择
本次实验使用VGG16模型如下
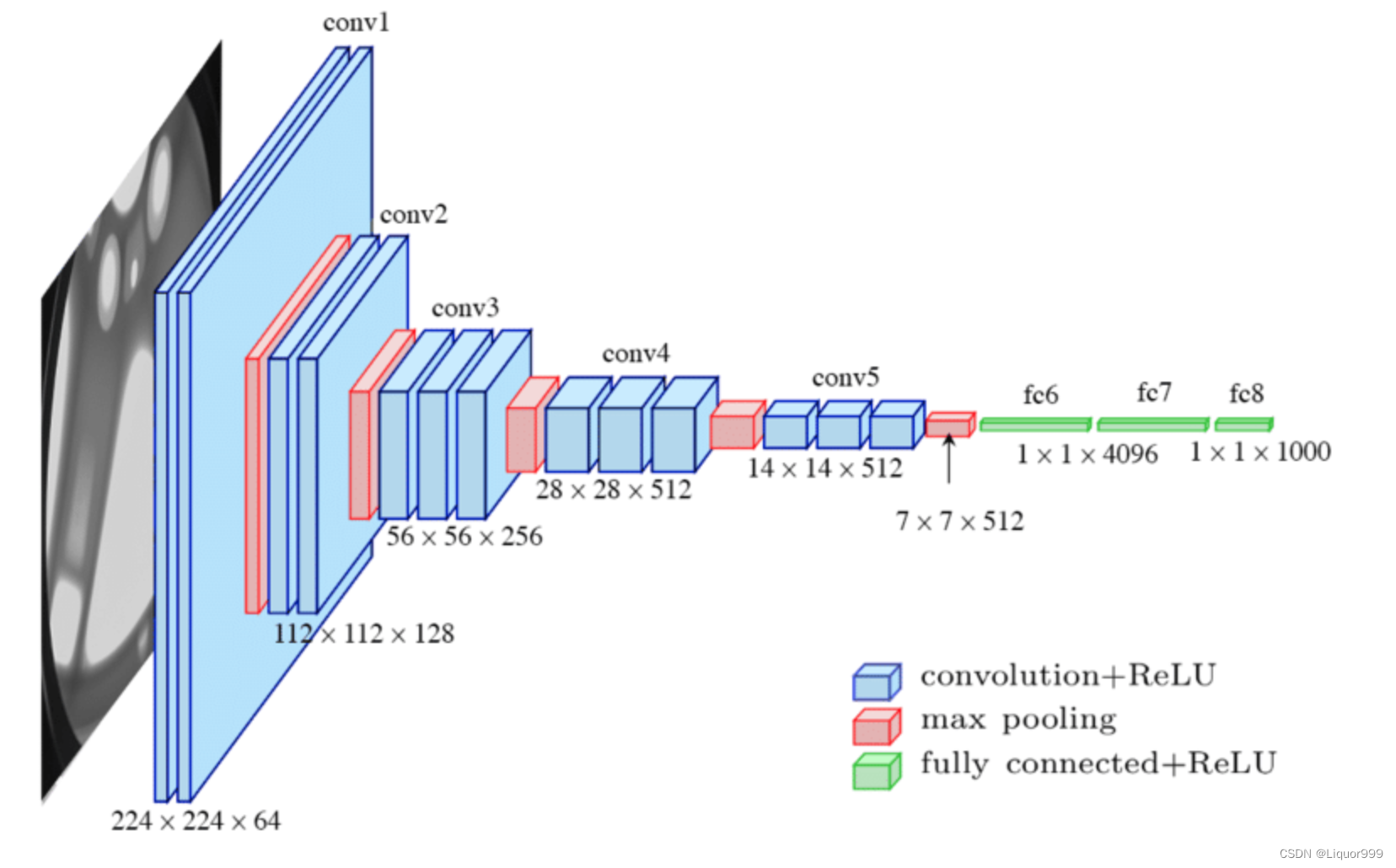
class Model(nn.Module):
def __init__(self):
super().__init__()
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Linear(7 * 7 * 512, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, len(classNames))
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = x.view(-1, 7 * 7 * 512)
x = self.fc(x)
return x
使用summary查看模型结构并且将模型转成多GPU并行运算的模型
from torchsummary import summary
# 将模型转移到GPU中
model = Model()
model = model.to(device)
if torch.cuda.device_count() > 1: # 检查电脑是否有多块GPU
print(f"Let's use {torch.cuda.device_count()} GPUs!")
model = nn.DataParallel(model) # 将模型对象转变为多GPU并行运算的模型
summary(model, input_size=(3, 224, 224))

训练
定义训练函数
def train(dataloader, model, loss_fn, opt):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_acc, train_loss = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
opt.zero_grad()
loss.backward()
opt.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_acc, test_loss = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss += loss.item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
定义损失函数、优化算法、学习率本次使用的是Adam优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.0001
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
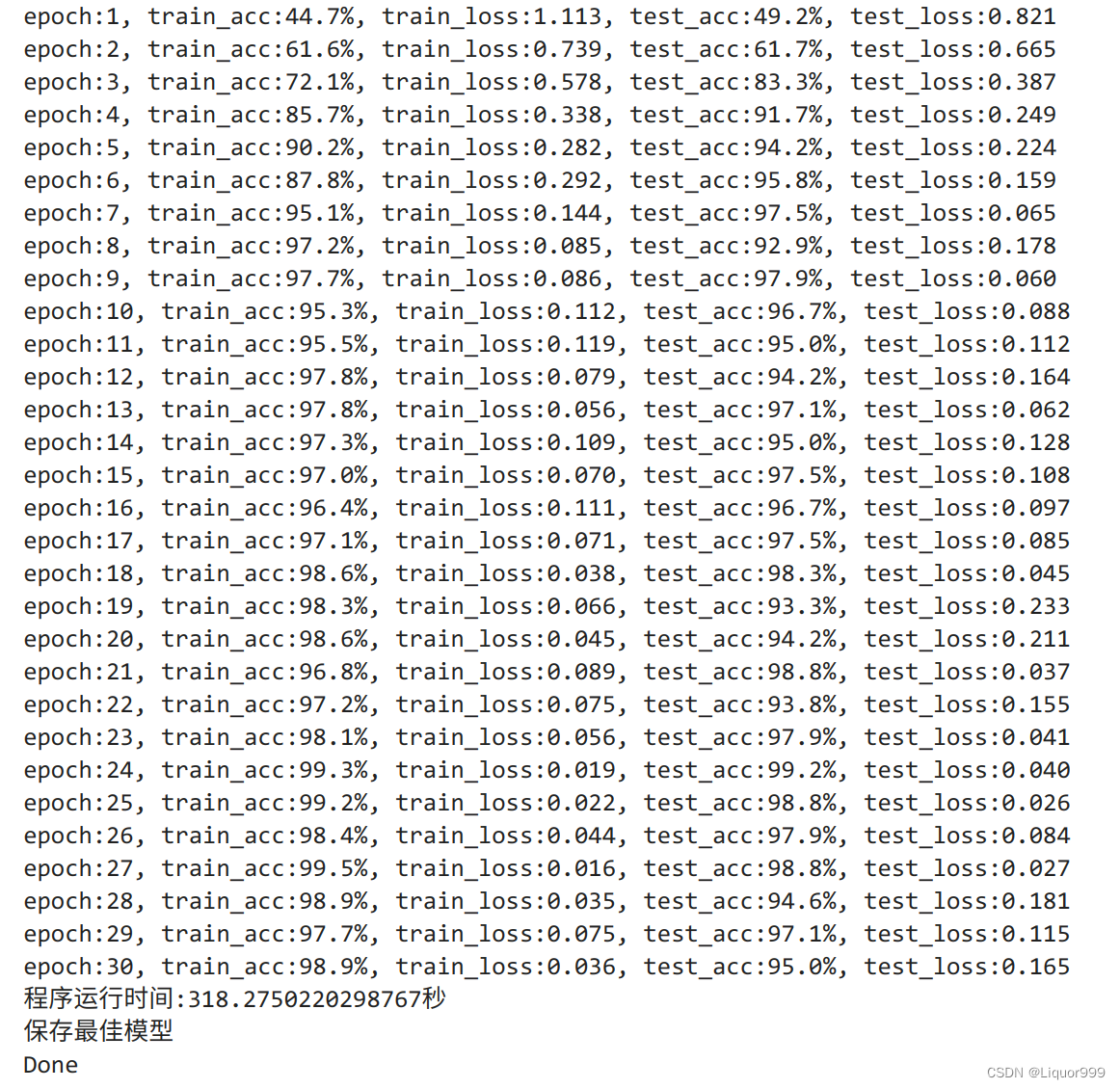
开始训练准确率还是非常高的
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []
T1 = time.time()
best_acc = 0
best_model = 0
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval() # 确保模型不会进行训练操作
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"
% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
T2 = time.time()
print('程序运行时间:%s秒' % (T2 - T1))
PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:
torch.save(best_model.state_dict(), PATH)
print('保存最佳模型')
print("Done")
模型可视化
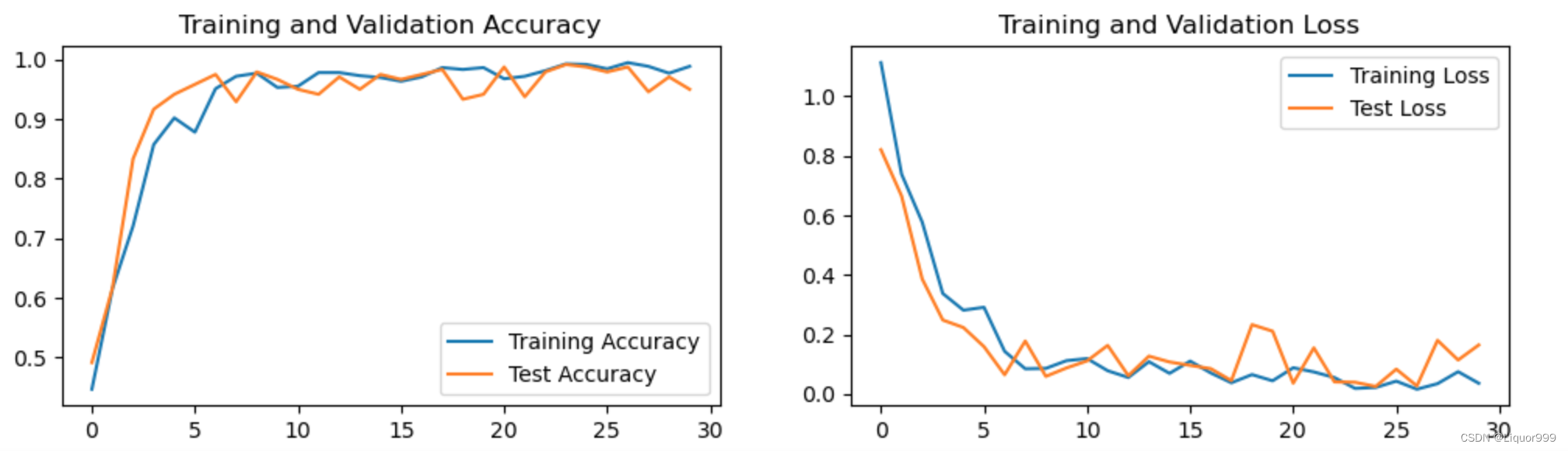
使用matplotlib可视化训练、测试过程
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义模型预测函数
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_,pred = torch.max(output,1)
pred_class = classes[pred]
print(f'预测结果是{pred_class}')
开始单张图片预测
predict_one_image(image_path='./data/beans/Dark/dark (1).png',
model=model,
transform=train_transforms,
classes=classes) # 预测结果是Dark
查看最优的模型的准确率和损失
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.9916666666666667, 0.0399394309388299)
其他问题
本次实验又使用了单GPU进行训练
# 单GPU
from torchsummary import summary
# 将模型转移到GPU中
model = Model()
model = model.to(device)
结果如下

总结
本次实验主要手写了经典网络架构VGG16并且使用两张GPU和一张GPU进行实验但惊奇的发现一张GPU运行时间是164秒两张GPU运行时间是318秒明明算力提高了反而训练时间更加慢了经过资料的查询大概原因是数据量很小GPU之间传递数据占用时间相对大于加速运算时间所以训练时间反而变长了。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |