

大数据-hadoop-MapReduce原理详解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
MapReduce[1]是Google提出的一个软件架构用于大规模数据集的并行运算。概念“Map映射”和“Reduce归约”及他们的主要思想都是从函数式编程语言借鉴的还有从矢量编程语言借来的特性。[注 1]
当前的软件实现是指定一个“Map”映射函数用来把一组键值对映射成一组新的键值对指定并发的“Reduce”归约函数用来保证所有映射的键值对中的每一个共享相同的键组。
映射和归约
简单来说一个映射函数就是对一些独立元素组成的概念上的列表例如一个测试成绩的列表的每一个元素进行指定的操作比如有人发现所有学生的成绩都被高估了一分他可以定义一个“减一”的映射函数用来修正这个错误。。事实上每个元素都是被独立操作的而原始列表没有被更改因为这里创建了一个新的列表来保存新的答案。这就是说Map操作是可以高度并行的这对高性能要求的应用以及并行计算领域的需求非常有用。
而归约操作指的是对一个列表的元素进行适当的合并继续看前面的例子如果有人想知道班级的平均分该怎么做他可以定义一个归约函数通过让列表中的奇数odd或偶数even元素跟自己的相邻的元素相加的方式把列表减半如此递归运算直到列表只剩下一个元素然后用这个元素除以人数就得到了平均分。虽然他不如映射函数那么并行但是因为归约总是有一个简单的答案大规模的运算相对独立所以归约函数在高度并行环境下也很有用。
分布和可靠性
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性每个节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保持沉默超过一个预设的时间间隔主节点类同Google档案系统中的主服务器记录下这个节点状态为死亡并把分配给这个节点的数据发到别的节点。每个操作使用命名文件的不可分割操作以确保不会发生并行线程间的冲突当文件被改名的时候系统可能会把他们复制到任务名以外的另一个名字上去。避免副作用。
归约操作工作方式很类似但是由于归约操作在并行能力较差主节点会尽量把归约操作调度在一个节点上或者离需要操作的数据尽可能近的节点上了这个特性可以满足Google的需求因为他们有足够的带宽他们的内部网络没有那么多的机器。
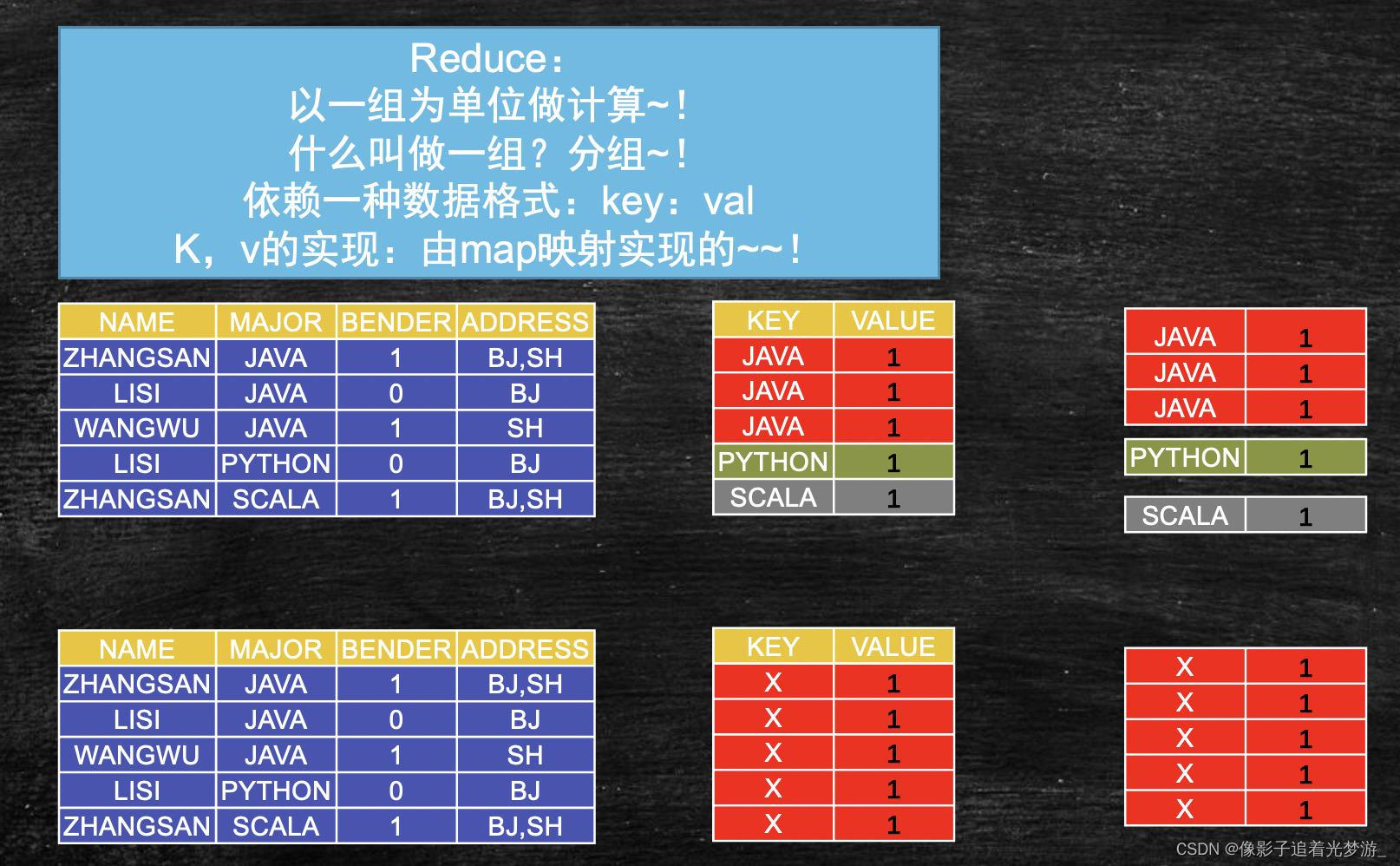
Map:以一条记录为单位做映射

reduce:以一组为单位做计算
为什么叫Map Reduce?
▪Map
–映射、变换、过滤
–1进N出
▪Reduce
–分解、缩小、归纳
–一组进N出
▪(KEY,VAL)
–键值对的键划分数据分组

Map Reduce框架

MR
数据已一条记录为单位经过map方法映射成KV相同的key为一组这一组数据调用一次reduce方法在方法内迭代计算着一组数据。
参考java 设计模式 --迭代器模式
经验数据集一般是用迭代计算的方式
block > split
1:1
N:1
1:N
split > map
1:1
map > reduce
N:1
N:N
1:1
1:N
group(key)>partition
1:1
N:1
N:N
1:N

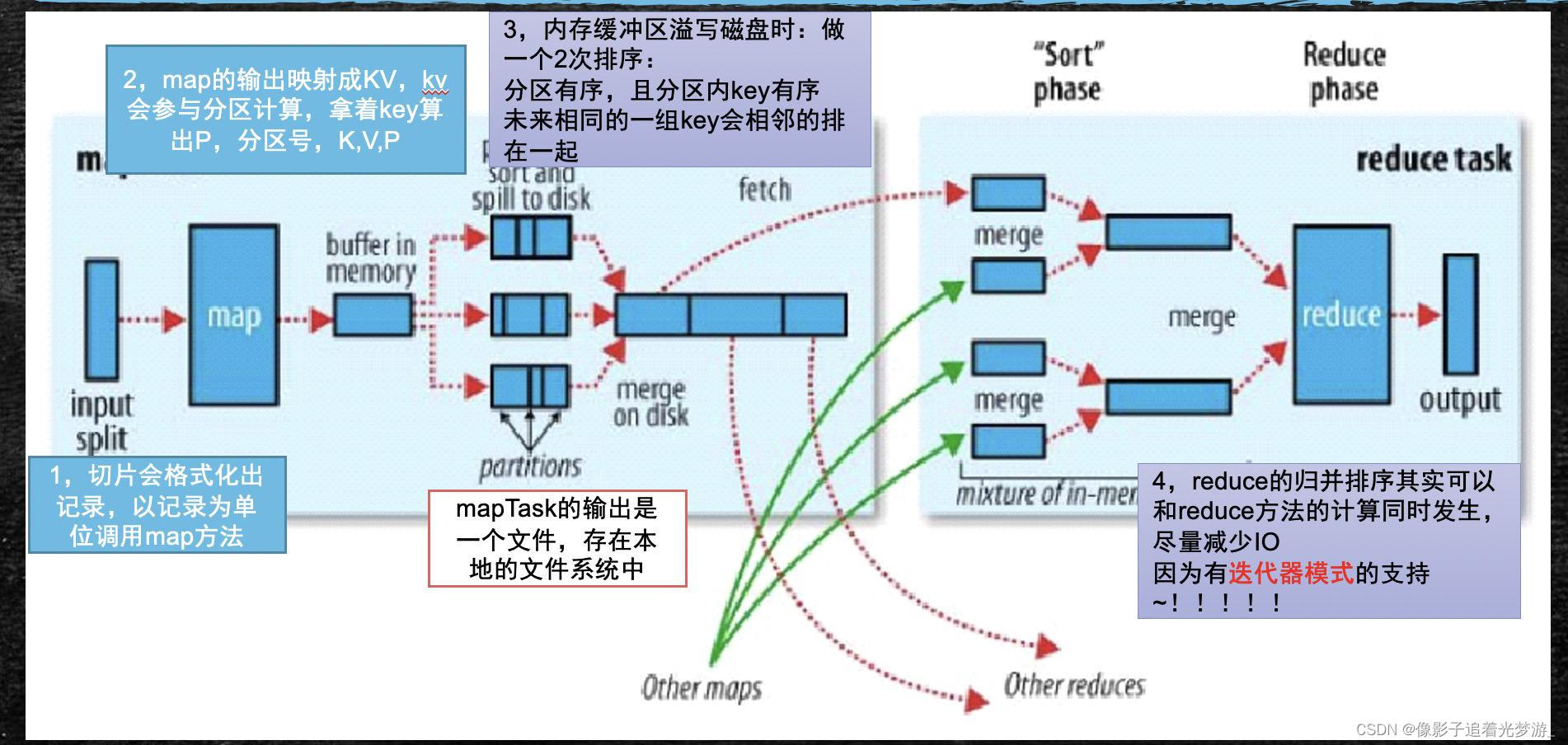
迭代器模式是批量计算中非常优美的实现形式~
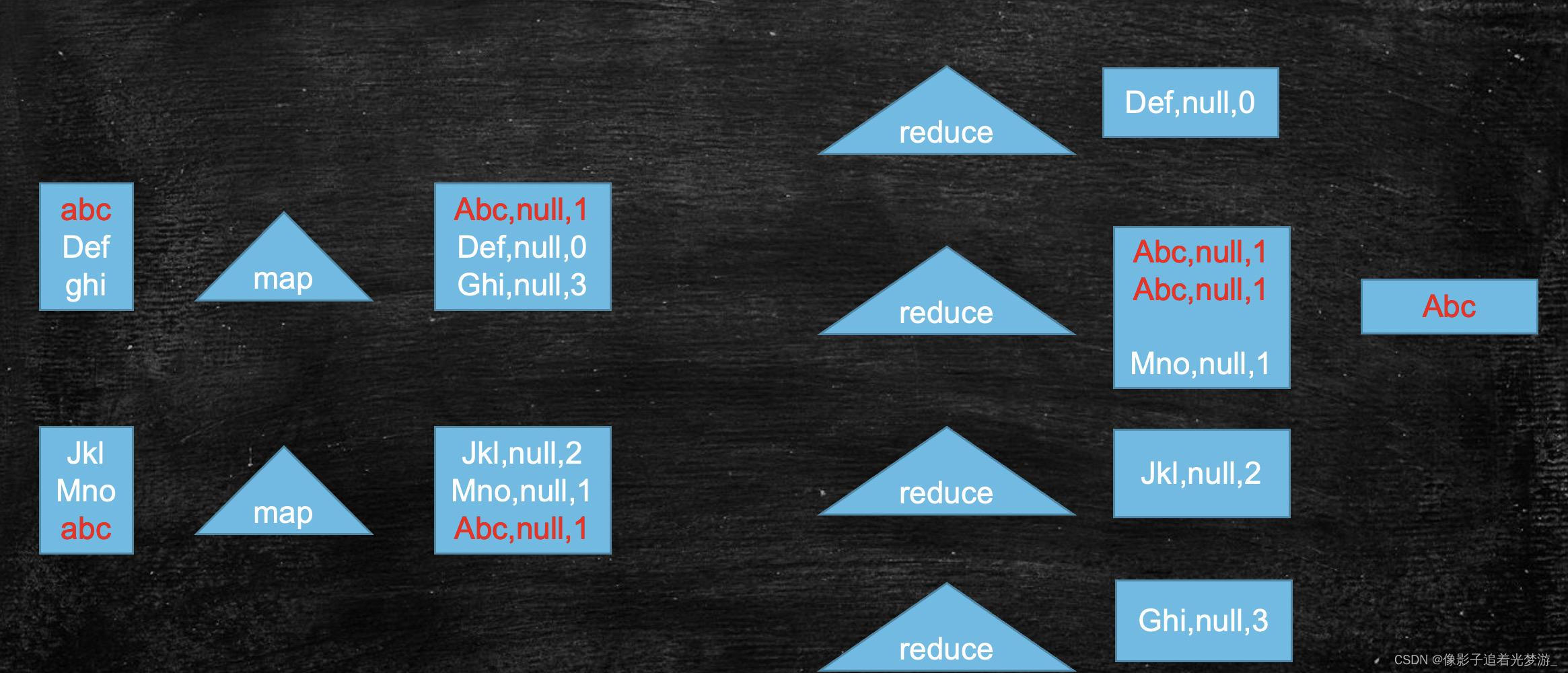
hello1,0 1是个数0代表分区
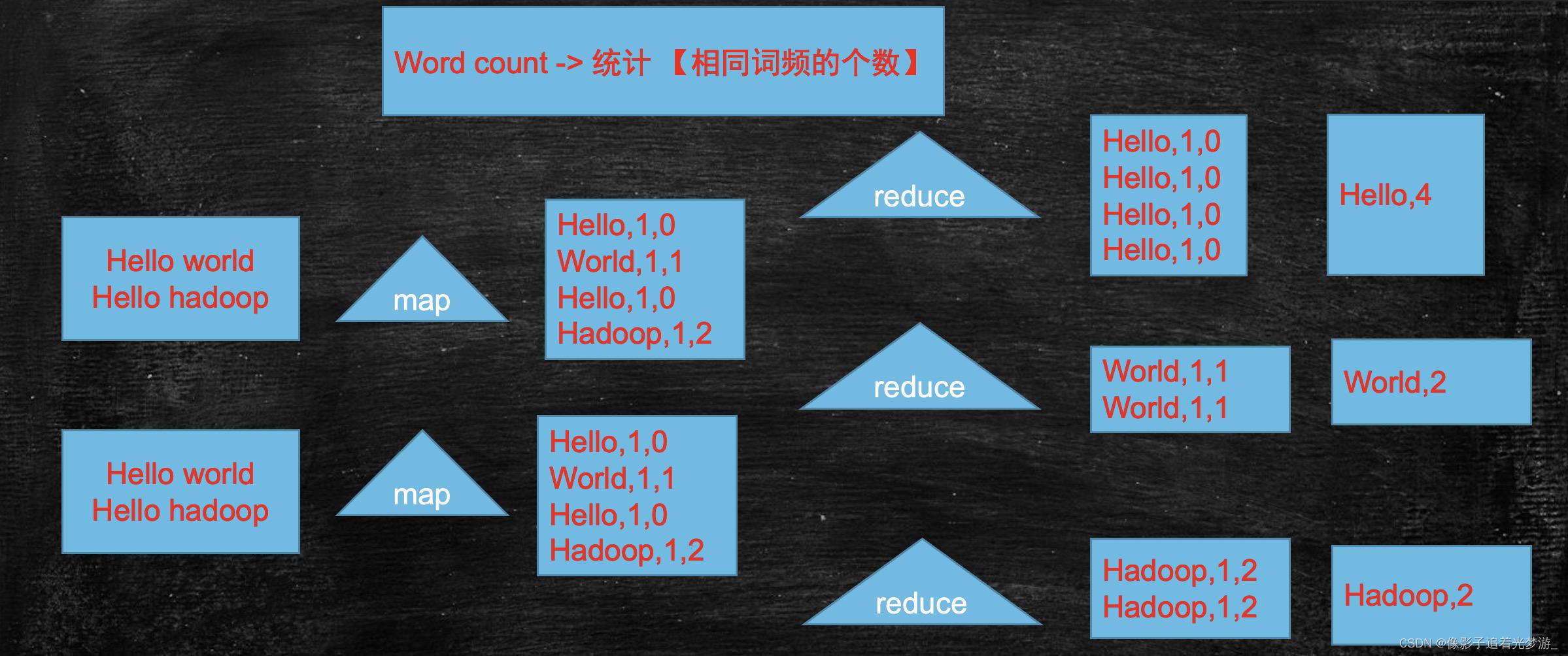
统计相同词频的个数
