

SparkSQL-第一章:SparkSQL快速入门
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家来学习今天的内容!
一、什么是SparkSQL
SparkSQL 是Spark的一个模块, 用于处理海量结构化数据
限定: 结构化数据处理
二、为什么学习SparkSQL
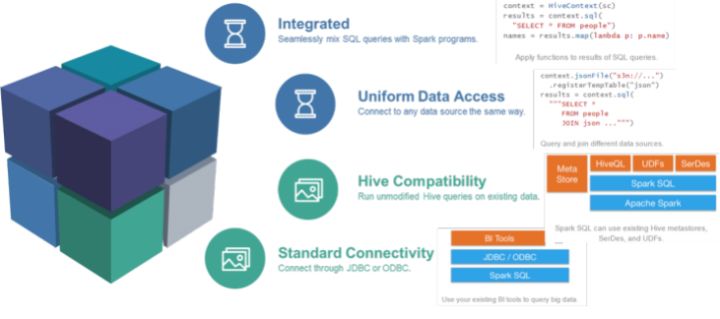
SparkSQL是非常成熟的 海量结构化数据处理框架.
学习SparkSQL主要在2个点:
SparkSQL本身十分优秀, 支持SQL语言\性能强\可以自动优化\API简单\兼容HIVE等等
企业大面积在使用SparkSQL处理业务数据
- 离线开发
- 数仓搭建
- 科学计算
- 数据分析
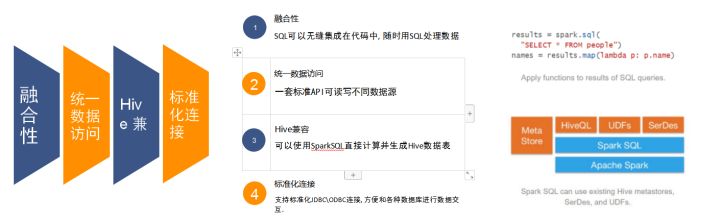
三、SparkSQL的特点
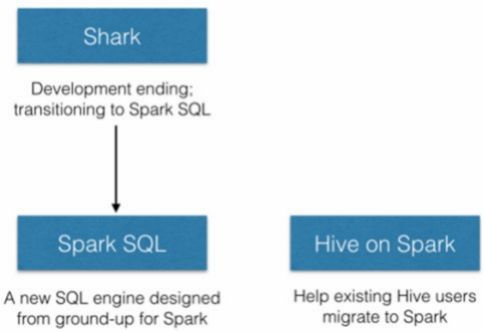
四、SparkSQL发展历史 - 前身 Shark框架
在许多年前(2012\2013左右)Hive逐步火热起来, 大片抢占分布式SQL计算市场;
Spark作为通用计算框架, 也不可能放弃这一细分领域。于是, Spark官方模仿Hive推出了Shark框架(Spark 0.9版本);
Shark框架是几乎100%模仿Hive, 内部的配置项\优化项等都是直接模仿而来,不同的在于将执行引擎由MapReduce更换为了Spark;
因为Shark框架太模仿Hive, Hive是针对MR优化, 很多地方和SparkCore(RDD)水土不服, 最终被放弃
Spark官方下决心开发一个自己的分布式SQL引擎 也就是诞生了现在的SparkSQL
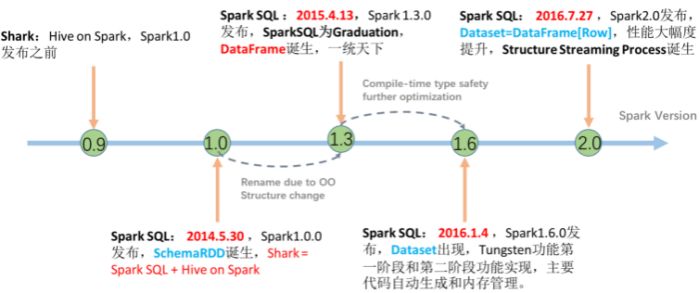
● 2014年 1.0正式发布
● 2015年 1.3 发布DataFrame数据结构, 沿用至今
● 2016年 1.6 发布Dataset数据结构(带泛型的DataFrame), 适用于支持泛型的语言(Java\Scala)
● 2016年 2.0 统一了Dataset 和 DataFrame, 以后只有Dataset了, Python用的DataFrame就是 没有泛型的Dataset
● 2019年 3.0 发布, 性能大幅度提升, SparkSQL变化不大
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |