

Intel oneAPI笔记(3)--jupyter官方文档(SYCL Program Structure)学习笔记-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
前言
本文是对jupyterlab中oneAPI_Essentials/02_SYCL_Program_Structure文档的学习记录包含对Device Selector、Data Parallel Kernel、Host Accessor、Buffer Destruction、的介绍最后还有一个小关于向量Vector加法的实例
设备Device
设备类包含用于查询设备信息的成员函数这对于创建多个设备的SYCL程序很有用成员函数get_info可以获取包括以下的信息
名称供应商版本号本地和全局工作编号宽度内置类型时钟频率缓存宽度和大小在线或离线等

设备选择器Device Selector
这个类允许在运行时根据用户提供的启发式方法选择特定设备来执行内核。下面的代码示例显示了标准设备选择器的使用

运行结果

队列Queue
队列类提交要由SYCL运行时执行的命令组。队列是一种将工作提交给设备的机制。一个队列映射到一个设备多个队列可以映射到同一个设备

内核Kernel
内核对象不是由用户显式构造的而是在调用parallel_for等内核调度函数时构造的用于在设备上执行代码的方法和数据

Scope
Application scope和command group scope
执行在主机上的代码在这个scope中可以使用c++全部代码
Kernel scope
执行在设备Device上的代码这个scope中可以无法使用部分c++的功能
Parallel Kernels
并行内核允许一个操作的多个实例并行执行。这对于offload的基本for循环的并行执行非常有用因为for循环中的每个迭代都是完全独立的并且按任意顺序执行。并行内核是用parallel_for函数表示的。c++应用程序中的一个简单的'for'循环编写如下

用下面这种方法可以offload到一个加速器accelerator中

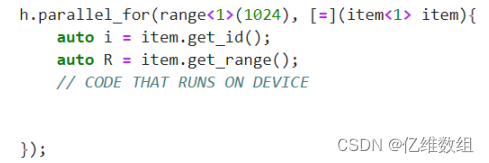
基本并行内核的功能主要包含range、id和item类。Range类用于描述并行执行的迭代空间id类用于在并行执行中索引内核的单个实例

上述的i可以换成item这样的话可以通过相关函数不仅得到原来的索引值i还可以在这个循环内部得到range
Nd Range Kernels
基本并行内核是并行for循环的简单方法但不允许在硬件级别进行性能优化。ND-Range内核是表达并行性的另一种方式它通过提供对本地内存的访问和将执行映射到硬件上的计算单元来实现低级性能调优。整个迭代空间被分成称成很多工作组工作组中的工作项被安排在硬件上的单个计算单元上
nd_range内核的功能通过nd_range和nd_item类公开。Nd_range类表示使用全局执行范围和每个工作组的本地执行范围的分组执行范围。Nd_item类表示内核函数的单个实例并允许查询工作组范围和索引

比如上面这个例子第一个range<1>1024表示全局执行范围是1024个工作单元第二个range<1>(64)表示每个工作组的本地执行范围是64也就是一个工作组有64个单元也照应了图上的4*4*4区域
Buffer Model
缓冲区在跨设备和主机的SYCL应用程序中封装数据。访问器是访问缓冲区数据的机器
SYCL的代码开头内容
![]()
SYCL程序是标准的c++。该程序在主机上调用并将计算offload到加速器上。程序员使用SYCL的队列、缓冲区、设备和内核抽象来指示应该卸载哪些部分的计算和数据
SYCL程序的第一步我们创建一个队列。我们通过将任务提交到队列将计算量转移到设备上。程序员可以通过选择器选择CPU、GPU、FPGA等器件。这个程序在这里使用默认的q这意味着SYCL运行时通过使用默认选择器来选择运行时可用的最有能力的设备。但下面是一个简单的SYCL程序
设备和主机可以共享物理内存也可以拥有不同的内存。当内存不同时offload计算需要在主机和设备之间复制数据。SYCL不要求程序员管理数据副本。通过创建缓冲区和访问器SYCL确保数据对主机和设备可用而无需程序员的任何努力。SYCL还允许程序员在需要实现最佳性能时显式控制数据移动
在SYCL程序中我们定义了一个内核就是device 运行的那部分代码。对于像这样的简单程序索引空间直接映射到数组的元素。内核被封装在一个c++ lambda函数中。lambda函数在索引空间中以坐标数组的形式传递一个点。对于这个简单的程序索引空间坐标与数组索引相同。下面程序中的parallel_for将lambda应用到索引空间。索引空间在parallel_for的第一个参数中定义为从0到N-1的一维范围

对访问器Accessor的隐式依赖
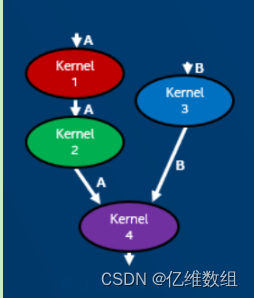
访问器在SYCL图中创建对内核执行排序的数据依赖关系如果两个内核使用相同的缓冲区第二个内核需要等待第一个内核完成以避免竞争条件比如下面这个图必须在kernel1运行完之后缓冲区A才能空闲然后才能继续运行kernel2
样例
%%writefile lab/buffer_sample.cpp
//==============================================================
// Copyright © Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include <sycl/sycl.hpp>
constexpr int num=16;
using namespace sycl;
int main() {
auto R = range<1>{ num };
//Create Buffers A and B
buffer<int> A{ R }, B{ R };
//Create a device queue
queue Q;
//Submit Kernel 1
Q.submit([&](handler& h) {
//Accessor for buffer A
accessor out(A,h,write_only);
h.parallel_for(R, [=](auto idx) {
out[idx] = idx[0]; }); });
//Submit Kernel 2
Q.submit([&](handler& h) {
//This task will wait till the first queue is complete
accessor out(A,h,write_only);
h.parallel_for(R, [=](auto idx) {
out[idx] += idx[0]; }); });
//Submit Kernel 3
Q.submit([&](handler& h) {
//Accessor for Buffer B
accessor out(B,h,write_only);
h.parallel_for(R, [=](auto idx) {
out[idx] = idx[0]; }); });
//Submit task 4
Q.submit([&](handler& h) {
//This task will wait till kernel 2 and 3 are complete
accessor in (A,h,read_only);
accessor inout(B,h);
h.parallel_for(R, [=](auto idx) {
inout[idx] *= in[idx]; }); });
// And the following is back to device code
host_accessor result(B,read_only);
for (int i=0; i<num; ++i)
std::cout << result[i] << "\n";
return 0;
}运行结果

结果解释并行运行kerne11和kernel3在缓冲区A和B中分别写入0--15这16个数然后运行kernel2让缓冲区A中的数翻二倍最后运行kernel4让缓冲区A中的0--30这16个数和缓冲区B中的0--15这16个数相乘最后输出
Host Accessor
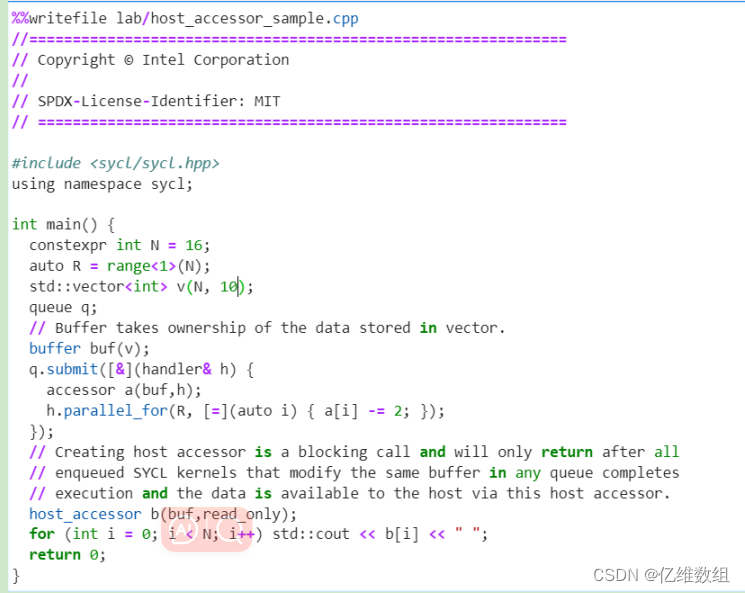
主机访问器是使用主机缓冲区访问目标的访问器。它是在命令组的作用域之外创建的它们用于通过构造主机访问器对象将数据同步回主机。缓冲区销毁是将数据同步回主机的另一种方法
缓冲区获取存储在vector中的数据的所有权。创建主机访问器是一个阻塞调用只有在所有队列中修改同一缓冲区的SYCL内核完成执行并且主机可以通过该主机访问器访问数据之后才会返回
运行结果

下面介绍主机和设备数据同步的另一种方法缓冲区销毁
Buffer Destruction
在下面的示例中缓冲区创建发生在单独的函数作用域中。当执行超出此函数作用域时调用缓冲区析构函数从而放弃数据的所有权并将数据复制回主机内存

运行结果
![]()
Custom Device Selector
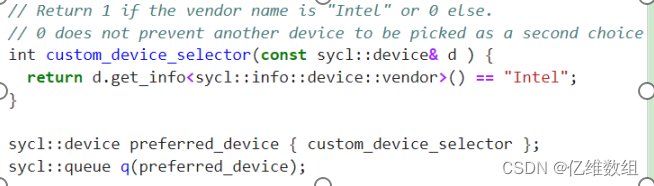
自定义设备选择器使用您自己的逻辑评分机制自定义设备选择器
特定供应商名称的自定义设备选择器
具有GPU和特定设备名称的自定义设备选择器

基于设备的优先级的自定义设备选择器

下面是基于上种情况的案例
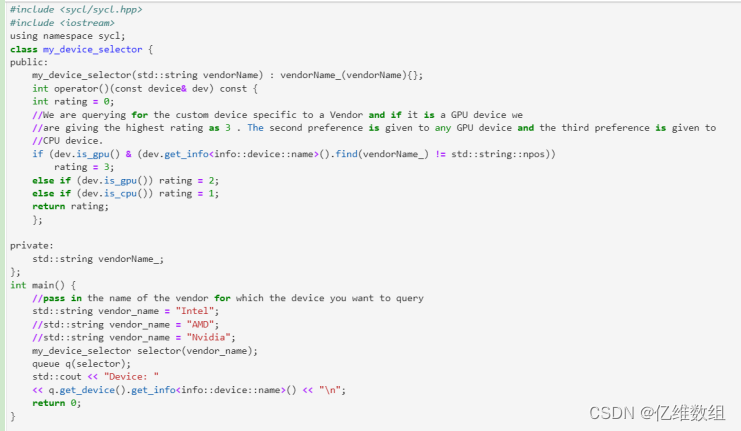
运行结果

Lab Exercise: Vector Add
下面是官方文档中向量相加这个练习
下面是我已经补全的代码
#include <sycl/sycl.hpp>
using namespace sycl;
int main() {
const int N = 256;
//# Initialize a vector and print values
std::vector<int> vector1(N, 10);
std::cout<<"\nInput Vector1: ";
for (int i = 0; i < N; i++) std::cout << vector1[i] << " ";
//# STEP 1 : Create second vector, initialize to 20 and print values
//# YOUR CODE GOES HERE
std::vector<int> vector2(N, 20);
std::cout<<"\nInput Vector2: ";
for (int i = 0; i < N; i++) std::cout << vector2[i] << " ";
//# Create Buffer
buffer vector1_buffer(vector1);
//# STEP 2 : Create buffer for second vector
//# YOUR CODE GOES HERE
buffer vector2_buffer(vector2);
//# Submit task to add vector
queue q;
q.submit([&](handler &h) {
//# Create accessor for vector1_buffer
accessor vector1_accessor (vector1_buffer,h);
//# STEP 3 - add second accessor for second buffer
//# YOUR CODE GOES HERE
accessor vector2_accessor (vector2_buffer,h);
h.parallel_for(range<1>(N), [=](id<1> index) {
//# STEP 4 : Modify the code below to add the second vector to first one
vector1_accessor[index] += vector2_accessor[index];
});
});
//# Create a host accessor to copy data from device to host
host_accessor h_a(vector1_buffer,read_only);
//# Print Output values
std::cout<<"\nOutput Values: ";
for (int i = 0; i < N; i++) std::cout<< vector1[i] << " ";
std::cout<<"\n";
return 0;
}运行结果
