

Python【bs4模块】讲解
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
导入from bs4 import BeautifulSoup
#爬取某豆的电影榜单
import pprint
import requests
from bs4 import BeautifulSoup
class pachong:
#pass #这段代码的意思如果暂时没有想好在类中定义任何属性和方法你可以先写pass Python就会认为这段不会运行直接跳过不会报错。
def __init__(self):
self.url = 'https://movie.douban.com/top250'
# 'https://movie.douban.com/top250?start={start}'.format(start='')
self.startnum = []
for Turn_pages in range(0,51,25):#这段代码首先是从0到250遍历取值的间隔是25为什么我写的是251因为Python语法规定一般最右边的数值会减去1我们获取的页面数据就会0,25,50,.......
# print(Turn_pages)
self.startnum.append(Turn_pages) # 将从range中获取的数据添加到空列表startnum当中
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
def get_top(self):
for starts in self.startnum:
start = int(starts)
html = requests.get(self.url,params={'start':starts},headers=self.headers).text #text 的意思转换成认识文字格式
# print(html)
soup = BeautifulSoup(html,'lxml') # 不要用xx.parser 了它太老了可以用 lxml
name = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span ')
fp = open('.豆瓣Top250.txt', 'w', encoding='utf-8')
for time in name:
title = time.text
fp.write(title+'\n')
print(title)
print('over')
# pprint.pprint(title) #可以尝试打印这段代码
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
# content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
# name1 = soup.find_all('content > div > div.article > ol > li:nth-child(1)')
# pprint.pprint(time)
#这里的作用就像工厂的发动机点火操作一点火前面的机器开始运转起来了
if __name__ == "__main__":
#对象调用
call = pachong()
# print(call)
#对象调用自身的方法
call.get_top()教大家一个获取url的好方法
使用谷歌浏览器
点击你需要获取信息的页面
鼠标右击检查
进入下图界面后点击NetWork 现在啥都没有
刷新界面ctrl + r 键盘这次爬虫课程中是向下滑查看网页的翻页方式
切换页面点击第2页因为只有切换了页面抓包工具network才会抓到数据
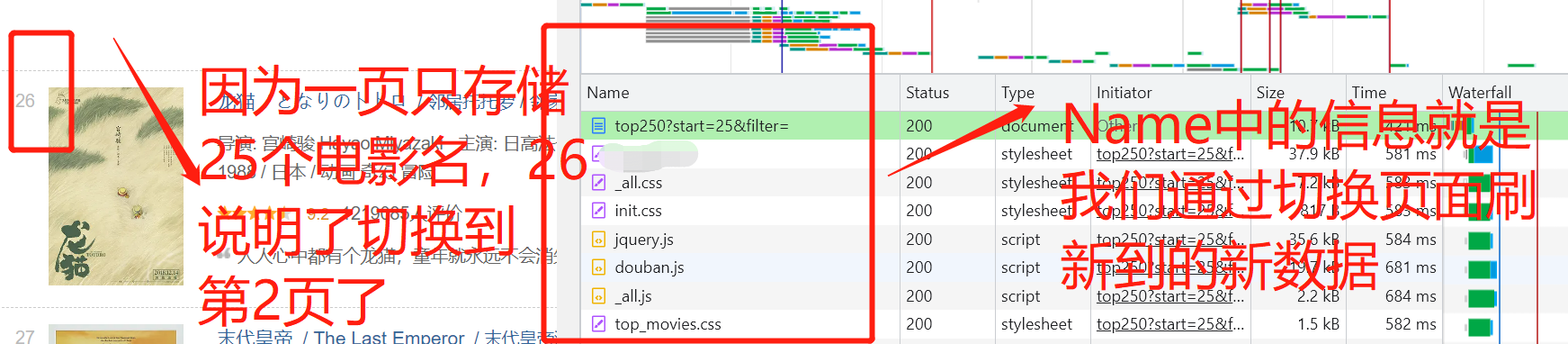
查找存放我们需要获取的关键信息的储存位置(在 Name 这一列中查找)
显然我们这次获取的信息在就在红色框框框起来的文件包中点击红色框框框起来的那段文字就会进入出现右边菜单栏的一些信息。
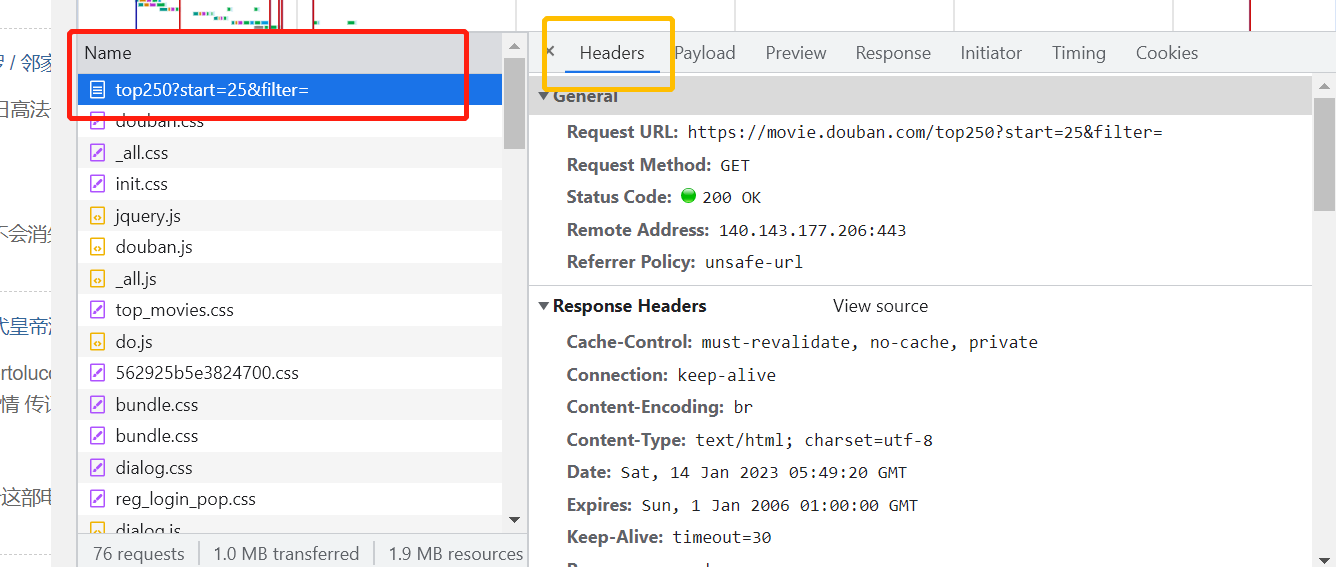
找到黄色框框中的Headers在Headers 的下面找到Rrequest URL 发送请求的url地址和 User-Agent:UA 伪装以那种浏览器的形式访问还有Request Method查看发起的post请求还是get请求
cooike有的网页爬取数据时也需要加上复制cookie的内容给其添加到headers当中

关于url的动态参数有的网页时静态大部分是动态静态就是网页地址不变动态就是有的参数会发生变化。
显然这次获取数据的参数strat是发生变化的
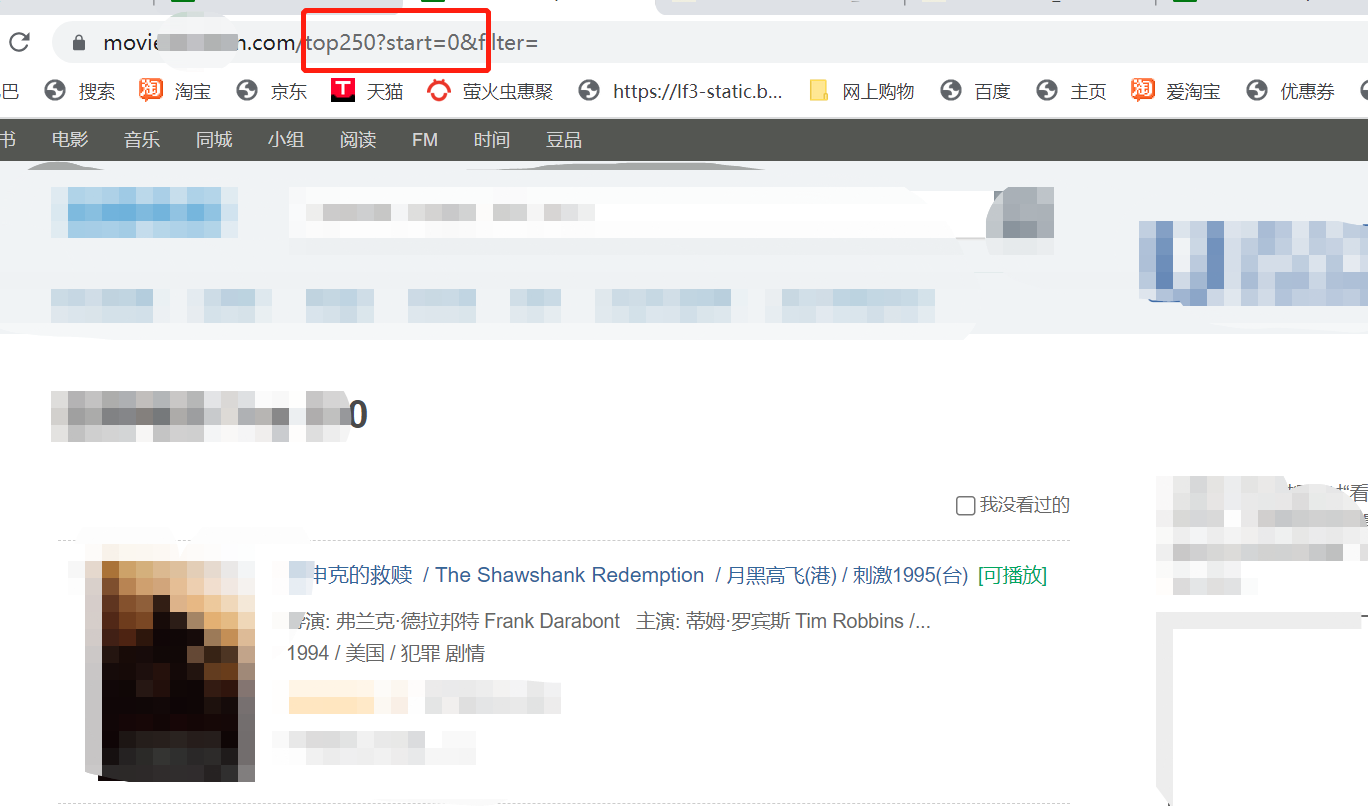
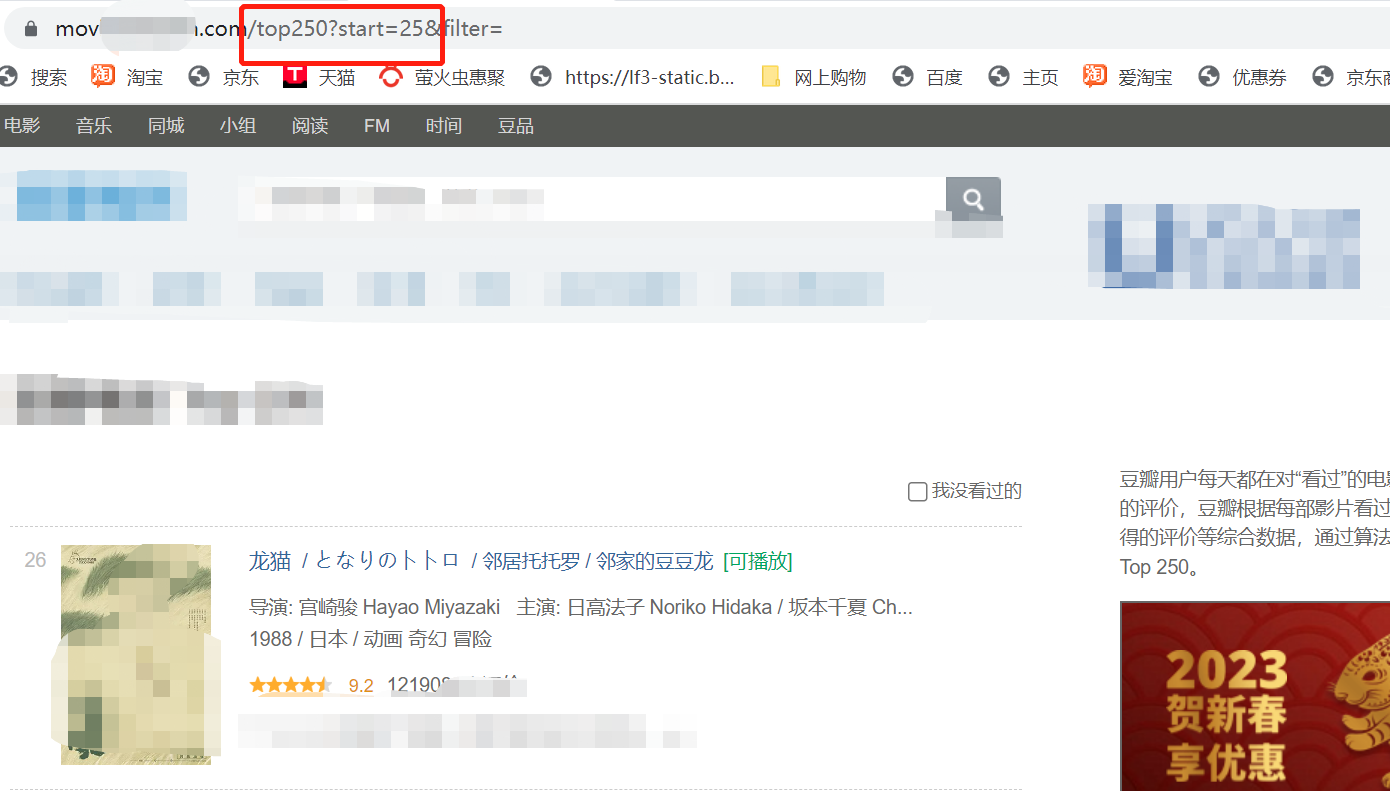
注意观察代码的规律start = 0 是第一页start = 25是第二页说明第三页就是start = 50
