

Unet网络解析
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1 Unet网络概述
论文名称U-Net: Convolutional Networks for Biomedical Image Segmentation
发表会议及时间 MICCA ( 国际医学图像计算和 计算机辅 助干预会 议 ) 2 0 1 5
Unet提出的初衷是为了解决医学图像分割的问题。
Unet网络非常的简单前半部分就是特征提取后半部分是上采样。在一些文献中把这种结构叫做编码器-解码器结构由于网络的整体结构是一个大些的英文字母U所以叫做U-net。其实可以将图像->高语义feature map的过程看成编码器高语义->像素级别的分类score map的过程看作解码器
Encoder左半部分由两个3x3的卷积层RELU再加上一个2x2的maxpooling层组成一个下采样的模块
Decoder右半部分由一个上采样的卷积层反卷积层特征拼接concat两个3x3的卷积层非线性ReLU层
在当时Unet相比更早提出的FCN网络使用拼接来作为特征图的融合方式。
FCN是通过特征图对应像素值的相加来融合特征的
U-net通过通道数的拼接这样可以形成更厚的特征当然这样会更佳消耗显存
2 Unet与FCN网络的区别
U-Net和FCN非常的相似U-Net比FCN稍晚提出来但都发表在2015年和FCN相比U-Net的第一个特点是完全对称也就是左边和右边是很类似的而FCN的decoder相对简单。第二个区别就是skip connectionFCN用的是加操作summationU-Net用的是叠操作concatenation。这些都是细节重点是它们的结构用了一个比较经典的思路也就是编码和解码encoder-decoder)结构。其实可以将图像->高语义feature map的过程看成编码器高语义->像素级别的分类score map的过程看作解码器
此外, 由于UNet也和FCN一样, 是全卷积形式, 没有全连接层(即没有固定图的尺寸),所以容易适应很多输入尺寸大小,但并不是所有的尺寸都可以,需要根据网络结构决定
3 为什么Unet在医疗图像分割种表现好
医疗影像语义较为简单、结构固定。因此语义信息相比自动驾驶等较为单一因此并不需要去筛选过滤无用的信息。医疗影像的所有特征都很重要因此低级特征和高级语义特征都很重要所以U型结构的skip connection结构特征拼接更好派上用场
医学影像的数据较少获取难度大数据量可能只有几百甚至不到100因此如果使用大型的网络例如DeepLabv3+等模型很容易过拟合。大型网络的优点是更强的图像表述能力而较为简单、数量少的医学影像并没有那么多的内容需要表述因此也有人发现在小数量级中分割的SOTA模型与轻量的Unet并没有优势
医学影像往往是多模态的。比方说ISLES脑梗竞赛中官方提供了CBFMTTCBV等多中模态的数据这一点听不懂也无妨。因此医学影像任务中往往需要自己设计网络去提取不同的模态特征因此轻量结构简单的Unet可以有更大的操作空间。
因此大多数医疗影像语义分割任务都会首先用Unet作为baseline
4 Unet网络结构
Unet网络是建立在FCN网络基础上的它的网络架构如下图所示总体来说与FCN思路非常类似。这里需要注意的是U-Net的输入大小是572x572但是输出却是388x388按理说它们应该相等因为图像分割相当于逐像素进行分类所以要求输入图像和输出图像大小一致但是为什么这里的输入尺寸要比输出尺寸大呢那是因为下图这个结构图是当年论文作者绘制的该作者对输入图像的边缘进行了镜像填充通过镜像填充将边界区域进行扩大这样可以给模型提供更多信息来完成模型的分割。
按照论文中的解释镜像填充的原因是因为图像 的边界的外面是空白的没有其它有效像素而我们预测图像中的像素类别时往往需要参考它的周围像素作为上下文信息这样才能保持分割的准确性为了预测边界像素论文对边界区域进行镜像来补全边界周围缺失的内容然后进行预测。这种策略叫做"overlap-tile"
这里的输入是单通道的原因是因为输入图片是灰度图而输出是两通道是因为这里是对像素进行二分类前景和背景所以输出通道是2
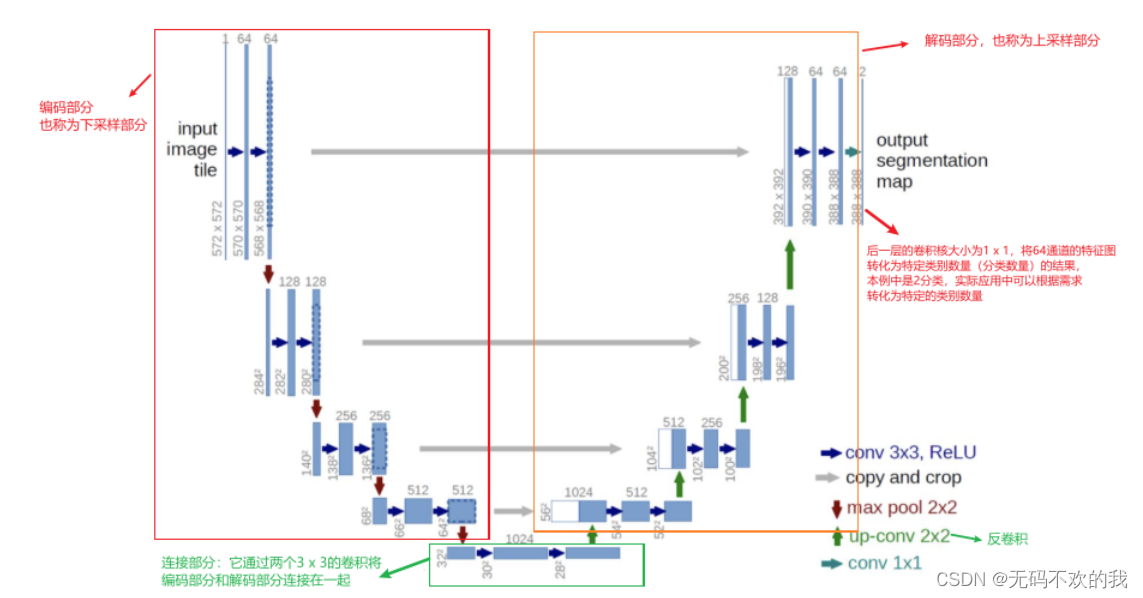
整个网络由编码部分左 和 解码部分右组成类似于一个大大的U字母具体介绍如下
1、编码部分是典型的卷积网络架构
它主要的作用是进行特征提取
架构中含有着一种重复结构每次重复中都有2个 3 x 3卷积层、非线性ReLU层和一个 2 x 2 max pooling层stride为2。图中的蓝箭头、红箭头没画ReLu
每一次下采样后我们都把特征通道的数量加倍
2、解码部分也使用了类似的模式
它主要的作用是进行上采样 (上采样可以让包含高级抽象特征的低分辨率图片在保留高级抽象特征的同时变为高分辨率)
架构中包含有一种重复结构每次重复都有一个上采样的卷积层反卷积层特征拼接concat两个3x3的卷积层非线性ReLU层
每一步都首先使用反卷积(up-convolution)每次使用反卷积都将特征通道数量减半特征图大小加倍。图中绿箭头
反卷积过后将反卷积的结果与编码部分中对应步骤的特征图拼接起来(concat)也就是将深层特征与浅层特征进行融合使得信息变得更丰富。白/蓝块
编码部分中的特征图尺寸稍大将其修剪过后进行拼接这里是将两个特征图的尺寸调整一致后按通道数进行拼接。左边深蓝虚线部分就是要裁剪的部分它对应右边的白色长方块部分
对拼接后的map再进行2次3 x 3的卷积。右侧蓝箭头
最后一层的卷积核大小为1 x 1将64通道的特征图转化为特定类别数量分类数量的结果。图中青色箭头
5 代码复现
下面使用pytorch框架对论文中的unet进行复现
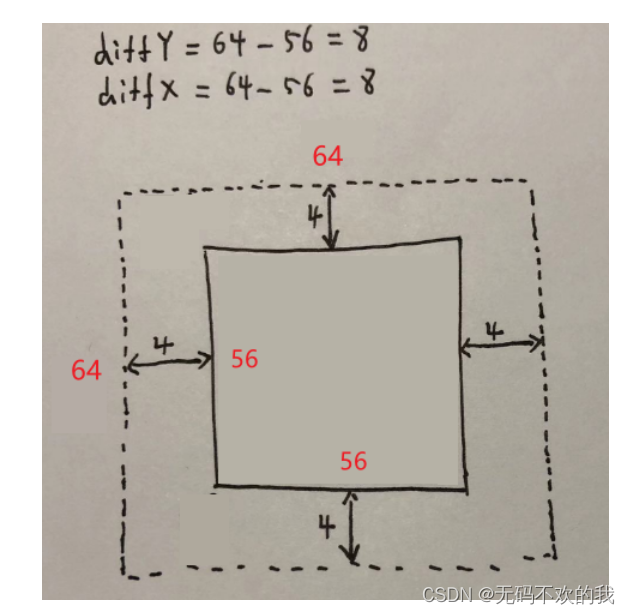
#编码器(论文中称之为收缩路径)的基本单元 def contracting_block(in_channels, out_channels): block = torch.nn.Sequential( #这里的卷积操作没有使用padding,所以每次卷积后图像的尺寸都会减少2个像素大小 nn.Conv2d(kernel_size=(3,3), in_channels=in_channels, out_channels=out_channels), nn.ReLU(), nn.BatchNorm2d(out_channels), nn.Conv2d(kernel_size=(3,3), in_channels=out_channels, out_channels=out_channels), nn.ReLU(), nn.BatchNorm2d(out_channels) ) return block #解码器论文中称之为扩张路径的基本单元 class expansive_block(nn.Module): def __init__(self, in_channels, mid_channels, out_channels): super(expansive_block, self).__init__() #每进行一次反卷积通道数减半尺寸扩大2倍 self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=(3,3), stride=2, padding=1, output_padding=1) self.block = nn.Sequential( # 这里的卷积操作没有使用padding,所以每次卷积后图像的尺寸都会减少2个像素大小 nn.Conv2d(kernel_size=(3,3), in_channels=in_channels, out_channels=mid_channels), nn.ReLU(), nn.BatchNorm2d(mid_channels), nn.Conv2d(kernel_size=(3,3), in_channels=mid_channels, out_channels=out_channels), nn.ReLU(), nn.BatchNorm2d(out_channels) ) def forward(self, e, d): d = self.up(d) #concat #e是来自编码器部分的特征图d是来自解码器部分的特征图它们的形状都是[B,C,H,W] diffY = e.size()[2]-d.size()[2] diffX = e.size()[3]-d.size()[3] #裁剪时先计算e与d在高和宽方向的差距diffY和diffX然后对e高方向进行裁剪具体方法是两边分别裁剪diffY的一半 #最后对e宽方向进行裁剪具体方法是两边分别裁剪diffX的一半 #具体的裁剪过程见下图一 e = e[:,:, diffY//2:e.size()[2]-diffY//2, diffX//2:e.size()[3]-diffX//2] cat = torch.cat([e, d], dim=1)#在特征通道上进行拼接 out = self.block(cat) return out #最后的输出卷积层 def final_block(in_channels, out_channels): block = nn.Sequential( nn.Conv2d(kernel_size=(1,1), in_channels=in_channels, out_channels=out_channels), nn.ReLU(), nn.BatchNorm2d(out_channels), ) return block class UNet(nn.Module): def __init__(self, in_channel, out_channel): super(UNet, self).__init__() #编码器 (Encode) self.conv_encode1 = contracting_block(in_channels=in_channel, out_channels=64) self.conv_pool1 = nn.MaxPool2d(kernel_size=2, stride=2) self.conv_encode2 = contracting_block(in_channels=64, out_channels=128) self.conv_pool2 = nn.MaxPool2d(kernel_size=2, stride=2) self.conv_encode3 = contracting_block(in_channels=128, out_channels=256) self.conv_pool3 = nn.MaxPool2d(kernel_size=2, stride=2) self.conv_encode4 = contracting_block(in_channels=256, out_channels=512) self.conv_pool4 = nn.MaxPool2d(kernel_size=2, stride=2) #编码器与解码器之间的过渡部分(Bottleneck) self.bottleneck = nn.Sequential( nn.Conv2d(kernel_size=(3,3), in_channels=512, out_channels=1024), nn.ReLU(), nn.BatchNorm2d(1024), nn.Conv2d(kernel_size=(3,3), in_channels=1024, out_channels=1024), nn.ReLU(), nn.BatchNorm2d(1024) ) # 解码器(Decode) self.conv_decode4 = expansive_block(1024, 512, 512) self.conv_decode3 = expansive_block(512, 256, 256) self.conv_decode2 = expansive_block(256, 128, 128) self.conv_decode1 = expansive_block(128, 64, 64) self.final_layer = final_block(64, out_channel) def forward(self, x): # Encode encode_block1 = self.conv_encode1(x) encode_pool1 = self.conv_pool1(encode_block1) encode_block2 = self.conv_encode2(encode_pool1) encode_pool2 = self.conv_pool2(encode_block2) encode_block3 = self.conv_encode3(encode_pool2) encode_pool3 = self.conv_pool3(encode_block3) encode_block4 = self.conv_encode4(encode_pool3) encode_pool4 = self.conv_pool4(encode_block4) # Bottleneck bottleneck = self.bottleneck(encode_pool4) # Decode decode_block4 = self.conv_decode4(encode_block4, bottleneck) decode_block3 = self.conv_decode3(encode_block3, decode_block4) decode_block2 = self.conv_decode2(encode_block2, decode_block3) decode_block1 = self.conv_decode1(encode_block1, decode_block2) final_layer = self.final_layer(decode_block1) return final_layer
模型测试
image = torch.rand((1, 3, 572, 572)) unet = UNet(in_channel=3, out_channel=2) mask = unet(image) print(mask.shape) #输出结果 torch.Size([1, 2, 388, 388])
图一图像裁剪过程演示
这里演示的是将64x64的特征图裁剪为56x56大小的过程
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |