

Linux基本功系列之sort命令实战
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

文章目录
前言
大家好又见面了我是沐风晓月本文是专栏【linux基本功-基础命令实战】的第43篇文章。
专栏地址[linux基本功-基础命令专栏] 此专栏是沐风晓月对Linux常用命令的汇总希望能够加深自己的印象以及帮助到其他的小伙伴😉😉。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
🏠个人主页我是沐风晓月
🧑个人简介大家好我是沐风晓月双一流院校计算机专业😉😉
💕 座右铭 先努力成长自己再帮助更多的人 一起加油进步🍺🍺🍺
💕欢迎大家这里是CSDN我总结知识的地方喜欢的话请三连有问题请私信😘
一. sort命令介绍
sort命令是一个排序命令可以对文件进行排序然后将排序结果标准输出。
sort将文件的每一行作为一个单位相互比较比较原则是从首字符向后依次按ASCII码值进行比较最后将他们按升序输出。
二. 语法格式及常用选项
依据惯例我们还是先查看帮助使用 sort --help
[root@mufenggrow ~]# sort --help
用法sort [选项]... [文件]...
或sort [选项]... --files0-from=F
Write sorted concatenation of all FILE(s) to standard output.
Mandatory arguments to long options are mandatory for short options too.
排序选项
-b, --ignore-leading-blanks 忽略前导的空白区域
-d, --dictionary-order 只考虑空白区域和字母字符
-f, --ignore-case 忽略字母大小写
-g, --general-numeric-sort compare according to general numerical value
-i, --ignore-nonprinting consider only printable characters
-M, --month-sort compare (unknown) < 'JAN' < ... < 'DEC'
-h, --human-numeric-sort 使用易读性数字(例如 2K 1G)
-n, --numeric-sort 根据字符串数值比较
-R, --random-sort 根据随机hash 排序
--random-source=文件 从指定文件中获得随机字节
-r, --reverse 逆序输出排序结果
--sort=WORD 按照WORD 指定的格式排序
一般数字-g高可读性-h月份-M数字-n
随机-R版本-V
-V, --version-sort 在文本内进行自然版本排序
其他选项
--batch-size=NMERGE 一次最多合并NMERGE 个输入;如果输入更多则使用临时文件
-c, --check, --check=diagnose-first 检查输入是否已排序若已有序则不进行操作
-C, --check=quiet, --check=silent 类似-c但不报告第一个无序行
--compress-program=程序 使用指定程序压缩临时文件;使用该程序的-d 参数解压缩文件
--debug 为用于排序的行添加注释并将有可能有问题的用法输出到标准错误输出
--files0-from=文件 从指定文件读取以NUL 终止的名称如果该文件被
指定为"-"则从标准输入读文件名
-k, --key=KEYDEF sort via a key; KEYDEF gives location and type
-m, --merge merge already sorted files; do not sort
-o, --output=文件 将结果写入到文件而非标准输出
-s, --stable 禁用last-resort 比较以稳定比较算法
-S, --buffer-size=大小 指定主内存缓存大小
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-T, --temporary-directory=目录 使用指定目录而非$TMPDIR 或/tmp 作为
临时目录可用多个选项指定多个目录
--parallel=N 将同时运行的排序数改变为N
-u, --unique 配合-c严格校验排序;不配合-c则只输出一次排序结果
-z, --zero-terminated 以0 字节而非新行作为行尾标志
--help 显示此帮助信息并退出
--version 显示版本信息并退出
为了更直观一些我们把常用的参数用表格来展示
| 参数 | 描述 |
|---|---|
| GNU 参数说明 | |
| -c | 检查文件是否按照顺序进行排序 |
| -d | 排序时处理英文字母数字及空格字母外忽略其他字符 |
| -f | 排序将小写字母视为大写字母 |
| -M | 将前面的3个字母依照月份缩写进行排序 |
| -r | 以相反的顺序进行排序 |
| -n | 依照数值的大小进行排序- |
| -o | 排序后存入指定的文件 |
| -t | 指定一个用来区分键位置字符 |
| -k | 后面跟数字指定按第几列进行排 |
有了具体的参数之后我们再来看实战案例
三. 参考案例
3.1 按照文本默认排序
此时无需加任何参数sort将文件/文本的每一行作为一个单位相互比较.
比较原则是从首字符向后依次按ASCII码值进行比较最后将他们按升序输出。
[root@mufenggrow ~]# sort /etc/passwd |head -5
abrt:x:173:173::/etc/abrt:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:993:988::/var/lib/chrony:/sbin/nologin
从上面的代码可以看到 按照首字符的ASCII码排序
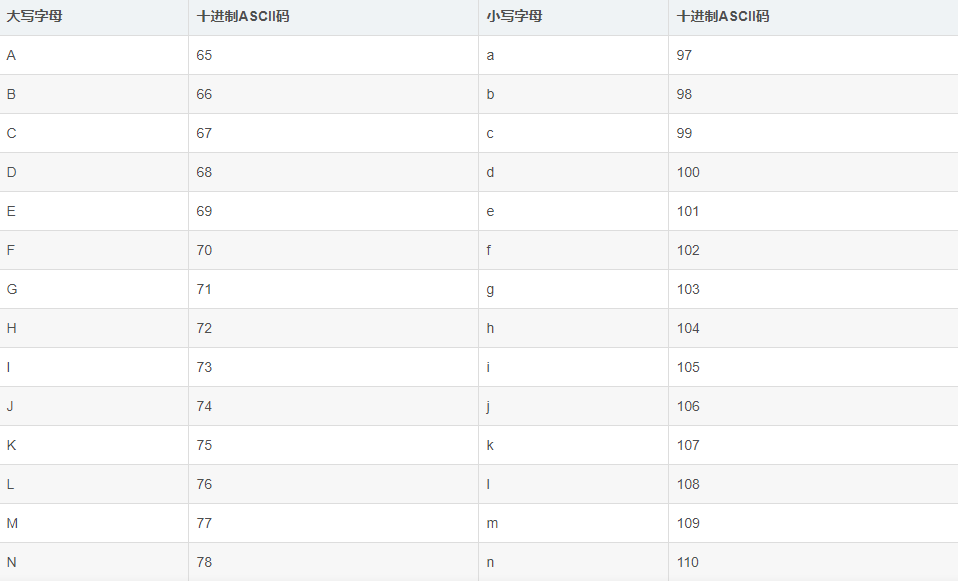
这里要理解什么是ASCII码
在计算机中所有的数据在存储和运算时都要使用二进制表示。而ASCII是基于拉丁字母的一套电脑编码系统主要用于显示现代英语和其他西欧语言它是现今最通用的单字节编码系统。
英文字母对应的ACSII码如下
3.2 忽略相同的行
-u参数主要用来忽略相同的行
## 可以看到有相同的行
[root@mufeng-06 ~]# cat a.txt
tiger
deer
lion
elphant
monkey
bear
dog
pig
pig
## 使用-u参数后
[root@mufeng06 ~]# sort -u a.txt 删除重复的行但是空行不会被删除
bear
deer
dog
elphant
lion
monkey
pig
tiger
使用-u参数后相同的行就没有了。
我们之前写过一个脚本统计在线的IP数有多少个代码如下
先写一个测试脚本
[root@mufenggrow ~]# cat ping1.sh
#!/bin/bash
str="192.168.1."
for num in {1..10}
do
ip=${str}${num}
ping -c1 -w1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo $ip >>/root/online.txt
fi
done
# 统计在线IP的个数
online=`cat /root/online.txt|wc -l `
echo "在线ip总数为 $online"
执行上面的脚本查看效果
[root@mufenggrow ~]# ./ping1.sh
在线ip总数为 12
我们发现执行的结果为12个IP这个结果是否准确? 我们查看文件内容
[root@mufenggrow ~]# cat online.txt
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
通过查看文件我们发现文件的内容为中有很多重复的IP这时候我们就可以使用sort -u 参数
[root@mufenggrow ~]# sort -u online.txt |wc -l
4
使用这个命令之后是不是就感觉IP少了很多去掉了重复的结果就对了。
3.3 按数字大小进行排序
此处使用-n 参数
当你使用sort命令对数字进行排序但是又不用-n参数的时候就会发现是乱序的
[root@mufenggrow ~]# cat a.txt
1
2
333
111
110
112
223
229
91
54
[root@mufenggrow ~]# sort a.txt
1
110
111
112
2
223
229
333
54
91
是不是从排序里感觉112 反而不如2大了?
加上-n参数才是正常的我们来看下代码
[root@mufenggrow ~]# sort -n a.txt
1
2
54
91
110
111
112
223
229
333
如果向对数字进行倒序排列需要加-r 参数 当然这里要对数字排序所以-n还是少不了的。
[root@mufenggrow ~]# sort -nr a.txt
333
229
223
112
111
110
91
54
2
1
3.4 检查文件是否已经按照顺序排序
-c参数可以检查文件是否按照顺序排序
[root@mufenggrow ~]# sort -c a.txt
sorta.txt:4无序 111
可以看到无序表示没有按照顺序排序这里需要主要当我们对一个文件排序后虽然会再屏幕上显示但并不会修改源文件。
3.5 将第3列按照数字大小进行排序
这里用到以下几个参数
-n是按照数字大小排序
-r是以相反顺序
-k是指定需要排序的栏位
-t指定栏位分隔符为冒号
我们对/etc/passwd 以冒号为分隔符把第三列进行大小排序
[root@mufenggrow ~]# sort -t: -nk 3 /etc/passwd |head -5
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
如果我们要将上面的排序变成从大到小排列
[root@mufenggrow ~]# sort -t: -nrk 3 /etc/passwd |head -5
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
laoxin:x:1000:1000:laoxin:/home/laoxin:/bin/bash
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
colord:x:998:997:User for colord:/var/lib/colord:/sbin/nologin
libstoragemgmt:x:997:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
注意
-t后面可以跟分隔符如果分割符为 比如容易操作但如果分隔符为空格的时候需要确认空格是否是规则的比如有的是多个空格有的是一个空格就很难达到预期的效果
root@mufenggrow ~]# sort -t " " -k 3 b.txt
9 9 1 0
1 2 3 4
2 2 4 5
5 6 7 8
[root@mufenggrow ~]# cat c.txt
1 2 33 44
2 2 3 4
7 9 11 4
3 4 6 7
[root@mufenggrow ~]# sort -t " " -k 4 c.txt
1 2 33 44
2 2 3 4
3 4 6 7
7 9 11 4
最后一个的排序按照第四列就没成功所以还是那句话如果空格比较杂乱的时候不建议使用空格进行排序如果非要用空格可以先做预处理。
3.6 将排序结果输出到文件
-o参数可以将结果输出到文件比如我们把3.5的排序输出到a.txt中
root@mufenggrow ~]# sort -t: -nrk 3 /etc/passwd -o a.txt
四. 探讨 -k的高级用法
案例一 使用-u 参数去重的时候希望参照第一个域进行去重
我们知道-u参数是去重但是必须两行完全重复才可以而有时候我们根据一部分来去重。
如果我们只用-u去重
[root@mufenggrow ~]# sort -u d.txt
lisi: 34
mufeng: 100
mufeng:60
mufeng:99
wangwu: 66
zhangsan: 59
可以看到有三个mufeng
结合 -k试一下
[root@mufenggrow ~]# sort -t: -u -k 1,1 d.txt
lisi: 34
mufeng: 100
wangwu: 66
zhangsan: 59
[root@mufenggrow ~]#
可以看到mufeng下面的两个mufeng被去掉了。
这里的 -k 1,1 我们写作 -k start,end , 如果start 第一个域的第一个字符~end 最后一个域的最后一个字符如果完全相同仅保留第一次出现的行后面出现的相同行都会被消除。
总结
sort命令在日常工作中应用的比较广泛一定要认真学习记熟记牢常用参数。
💕💕💕 好啦这就是今天要分享给大家的全部内容了我们下期再见✨ ✨ ✨
🍻🍻🍻如果你喜欢的话就不要吝惜你的一键三连了~

