

MobileViT、MobileViTv2、MobileViTv3学习笔记(自用)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1、MobileViT一种用于移动设备的轻量级通用视觉转换器
论文地址https://arxiv.org/abs/2110.02178
MobileVitV1是苹果公司2021年发表的一篇轻量型主干网络它是CNN与Transfomrer的混合架构模型这样的架构模型也是现在很多研究者们青睐的架构之一。自Vision Transformer出现之后人们发现Transfomrer也可以应用在计算机视觉领域并且效果还是非常不错的。但是基于Transformer的网络模型存在着问题就是该结构的网络模型需要大量的数据才能得到不错的效果如果使用少量数据进行训练那么会掉点很明显。出现这种现象的原因就是Transformer并没有像CNN那样具有空间归纳偏置的特征。因为空间归纳偏置允许CNN在不同的视觉任务中学习较少参数的表示。那么什么是空间归纳偏置呢

Transformer相对于CNN的缺点
空间归纳偏置是对目标函数的一种必要性假设大概意思就是像人一样带着某种偏见去看待事物归纳 (Induction) 指从一些例子中寻找共性、泛化形成一个较通用的规则的过程。偏置 (Bias) 则是指对模型的偏好。从现实生活中观察到的现象中归纳出一定的规则(heuristics)然后对模型做一定的约束从而可以起到“模型选择”的作用即从假设空间中选择出更符合现实规则的模型。
CNN的归纳偏置一般来说有两种
localityCNN是以滑动窗口的形式一点一点地在图片上进行卷积的所以假设图片上相邻的区域会有相邻的特征靠得越近的东西相关性越强translation equivariance平移等变性或平移同变性写成公式就是f(g(x))=g(f(x))不论是先做 g 这个函数还是先做 f 这个函数最后的结果是不变的其中f代表卷积操作g代表平移操作。因为在卷积神经网络中卷积核就相当于是一个模板不论图片中同样的物体移动到哪里只要是同样的输入进来然后遇到同样的卷积核那么输出永远是一样的- 一旦神经网络有了这两个归纳偏置之后他就拥有了很多的先验信息所以只需要相对较少的数据就可以学习一个相对比较好的模型。但是对于transformer来说它没有这些先验信息所以它对视觉的感知全部需要从这些数据中自己学习。
Transformer就是只有刚开始将图片切成patch的时候和加位置编码的时候用到了除此之外就再也没有用任何针对视觉问题的归纳偏置了而且位置编码也是随机初始化的1-D信息。所以在中小数据集上ViT不如CNN是可以理解的。
该图来源于【机器学习】浅谈 归纳偏置 (Inductive Bias)_何处闻韶的博客-CSDN博客_归纳偏置
虽然Transformer没有像CNN那样具有空间归纳偏置平移不变性(translation equivariance )和局部像素之间的相关性(locality)必须要大量数据来进行学习数据中的某种特性从而导致无法很好的应用在这样的边缘设备或者说一般的设备也很难跑的动。但是CNN也有缺点就是CNN在空间上获取的信息是局部的因此一定程度上会制约着CNN网络结构的性能相反Transformer的自注意力机制能够获取全局信息。


为此在本文中作者就结合两者的优势为移动视觉任务构建一个轻量级、低延迟的网络。从而提出MobileViT一种用于移动设备的轻量级通用视觉转换器。它结合了CNN(例如空间归纳偏差和对数据增强不太敏感)和ViTs(例如输入自适应加权和全局处理)的优点。在MS-COCO对象检测任务中在相同数量的参数下MobileViT的准确性比MobileNetv3高5.7%。移动视觉任务需要轻量级、低延迟和满足设备资源约束的精确模型并且是通用的但是本文中的方式并不满足延迟低的要求其中的原因就是因为多头注意力机制的原因。
注意浮点操作(FLOPs)不足以满足移动设备上的低延迟因为FLOPs忽略了几个重要的推理相关因素如内存访问、并行度和平台特征(Ma et al, 2018)。
下图是本文提供的一般的Vision Transformer的结构首先将C,H,W的图片进行Patch处理成N个向量然后经过线性层进行降低向量维度再经过位置编码然后再经过N个Transformer块在通过class token来进行分类。

标准的Vision Transformer
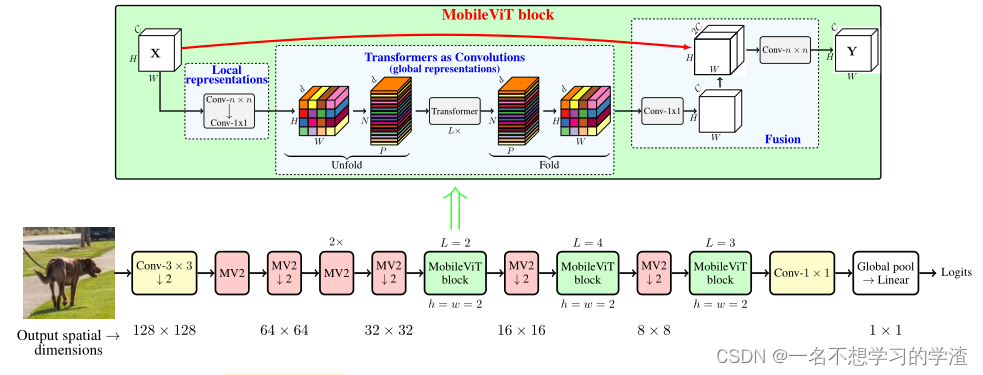
MobileViT结构。这里MobileViT块中的convn × n表示一个标准的n × n卷积MV2指的是MobileNetv2块。执行下采样的块用↓2标记。
本文的网络结构如上所示我们可以看出该网络结构就是通过MV2模块和MobileViT 模块所组成其中MV2块就是MobileNetv2的block它是一种倒残差结构即特征图的维度是先升后降据相关论文中描述说更高的维度经过激活函数后它损失的信息就会少一些。

MobileNetv2的block
MobileViT 模块相比较就有些复杂如下图所示这也是这篇论文的重点首先将特征图通过一个卷积核大小为nxn代码中是3x3的卷积层进行局部的特征建模然后通过一个卷积核大小为1x1的卷积层调整通道数。接着通过Unfold -> Transformer -> Fold结构进行全局的特征建模然后再通过一个卷积核大小为1x1的卷积层将通道数调整回原始大小。接着通过shortcut捷径分支在V2版本中将该捷径分支取消了与原始输入特征图进行Concat拼接沿通道channel方向拼接最后再通过一个卷积核大小为nxn代码中是3x3的卷积层做特征融合得到输出。
由于语言组织能力所以文本参考原文链接https://blog.csdn.net/qq_37541097/article/details/126715733

由于为了减少参数量Unfold -> Transformer -> Fold在本次的自注意力机制中只选择了位置相同的像素点进行点积操作。这样做的原因大概就是因为和所有的像素点都进行自注意力操作会带来信息冗余毕竟不是所有的像素都是有用的。具体的做法如下图所示。

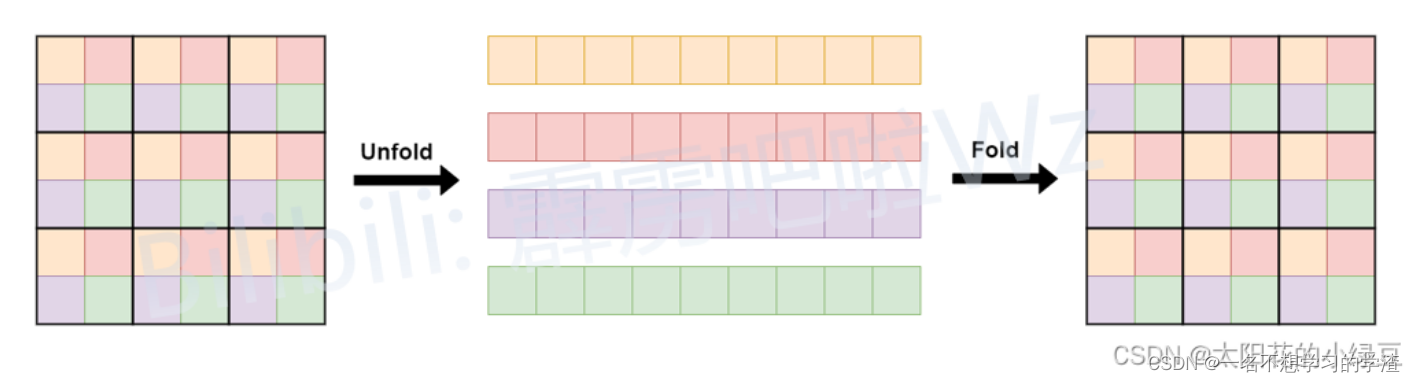
该图像来源于MobileViT模型简介_太阳花的小绿豆的博客-CSDN博客_mobile模型
这里作者给出了关于MobileViT 模块为什么能够成功的原因。标准卷积可以被看作是三个连续操作的堆栈:(1)展开(2)矩阵乘法(学习局部表示)(3)折叠。MobileViT块类似于卷积因为它也利用了相同的构建块。MobileViT块用更深层次的全局处理(变压器层的堆栈)取代了卷积中的局部处理(矩阵乘法)。因此MobileViT具有类似卷积的特性(例如空间偏差)。因此MobileViT块可以被看作是卷积的变压器。通过该模块也具有全局处理能力这也是模型轻量化的原因不需要太多的参数进行学习。
后面作者针对不同的任务对不同patch size进行的实验感兴趣的话可以自行了解。
2、MobileViTv2移动视觉变压器的可分离自我注意
论文地址https://arxiv.org/abs/2206.02680

MobileViTv1与卷积的相关指标对比
MobileViT可以在多种移动视觉任务中实现最先进的性能包括分类和检测。虽然这些模型的参数较少但与基于卷积神经网络的模型相比它们具有较高的延迟如上图所示。 MobileViT的主要效率瓶颈是Transformer 的多头自注意(MHA)它需要O(k2)相对于token的数量的时间复杂度。此外MHA需要昂贵的操作(例如批处理矩阵乘法)来计算自注意影响资源受限设备的延迟。从而提出了一种具有线性复杂度的可分离自我注意方法其中复杂度为O(k)。MobileViTv2在ImageNet数据集上的准确率达到75.6%在移动设备上运行速度比MobileViT快3.2倍的情况下其性能比MobileViT高出约1%
注意对于图像数据而言其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例将输入图片(224x224)按照16x16大小的Patch进行划分划分后会得到 (224/16)^2=196 个Patches。接着通过线性映射将每个Patch映射到一维向量中以ViT-B/16为例每ge Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量后面都直接称为token。[16, 16, 3] -> [768]。
如下图我们可以看出 MobileViTv2在局部表示中将一般的卷积变成了深度可分离卷积操作降低计算量并且也取消了残差结构以及特征融合部分在论文中说这样会使最终结果会好一些。从结构上来看就知道计算量肯定减少了。个人觉得这能涨一个点还是非常厉害的说明设计的非常好。

可分离自注意力方法的主要思想是计算关于潜在token L 的上下文分数。然后这些分数用于重新加权输入token并生成一个上下文向量该向量编码全局信息。因为自注意力是针对潜在token计算的所以所提出的方法可以将Transformer中自注意力的复杂度降低 k 倍。所提出的方法的一个简单而有效的特征是它使用逐元素操作例如求和和乘法来实现使其成为资源受限设备的不错选择。因此将所提出的注意力方法称为可分离自注意力因为它允许我们通过用两个单独的线性计算替换二次 MHA 来编码全局信息。改进的模型 MobileViTv2 是通过在 MobileViT 中将 MHA 替换为可分离的自注意力来获得的。

3、MobileViTv3移动友好的视觉转换器简单有效地融合了本地全局和输入功能
论文地址https://arxiv.org/abs/2209.15159
虽然主要的mobilevitv1块有助于实现具有竞争力的最先进的结果但mobilevitv1块中的融合块创建了扩展挑战并具有复杂的学习任务。我们提出对融合块进行简单有效的修改以创建mobilevitv3块解决了伸缩问题简化了学习任务。
MobileViTv2体系结构删除了融合块并使用了线性复杂度的Transformer得到了比MobileViTv1更好的性能。将本文提出的融合块添加到MobileViTv2中以创建MobileViTv3-0.5,0.75和1.0模型。与MobileViTv2相比这些新模型在ImageNet-1k、ADE20K、COCO和PascalVOC2012数据集上提供了更好的精度。
使用了简单有效的方法来融合输入、局部(CNN)和全局(ViT)特征来提升模型的精度。
 在本论文中提出了对现有MobileViTv1块体系结构的四个设计更改。
在本论文中提出了对现有MobileViTv1块体系结构的四个设计更改。
1、 融合块中用1x1卷积层替换3x3卷积层。这一块有点不理解个人感觉就是为了降低计算量毕竟1x1卷积核可以通过控制卷积核数量实现降维或升维。优势就在于 1x1卷积核 会使用更少的权重参数数量。在输入尺寸不发生改变的情况下而增加了非线性所以会增加整个网络的表达能力。
在融合模块中替换3×3卷积层存在两个主要动机。首先融合部分独立于特征图中其他位置的局部和全局特征以简化融合模块的学习任务。从概念上讲3×3卷积层融合了输入特征、全局特征以及其他位置的输入和全局特征这是一项复杂的任务。融合模块的目标可以简化因为它可以融合输入和全局特征而不依赖于特征图中的其他位置。因此作者在融合中使用1×1卷积层而不是3×3卷积层。
其次将3×3卷积层替换为1×1卷积层是消除MobileViTv1架构扩展中的主要限制之一。通过改变网络宽度并保持深度恒定将MobileViT-v1从XXS扩展到S。更改MobileViTv1 Block的宽度输入和输出通道数会导致参数和FLOP的数量大幅增加。例如如果输入和输出通道在MobileViTv1 Block中加倍2×则融合模块内3×3卷积层的输入通道数增加4×输出通道数增加2×因为输入到3×3卷积层的是输入和全局表示块特征的串联。这导致MobileViTv1 Block的参数和FLOP大幅增加。使用1×1卷积层可避免在缩放时参数和FLOP的大幅增加。
2、本地和局部特征融合。在融合层来自本地和全局表示块的特征被连接到我们提出的MobileViTv3块中而不是输入和全局表示特征。这是因为与输入特征相比局部表示特征与全局表示特征更密切相关。局部表示块的输出通道略高于输入特征的通道。这导致输入特征映射到融合块的1x1卷积层的数量增加但由于3x3卷积层改为1x1卷积层参数和flop的总数明显少于基线MobileViTv1块
3、融合输入。在论文中说ResNet和DenseNet等模型中的残余连接已证明有助于优化体系结构中的更深层次。并且增加了这个残差结构后消融实验证明能够增加0.6个点。如下图所示。

4、在融合模块中将一般卷积变成了深度可分离卷积。这一部分的改进从消融研究结果中可以看出这一变化对Top-1 ImageNet-1K的精度增益影响不大从上图最后一行看出掉了0.3个点但是能够提供了良好的参数和精度权衡。
通过上面的几点可以更好的对MobileViT块进行扩展带来的优势也是非常巨大的如下图所示在参数量控制在6M以下达到的效果也是非常惊人的Top-1的精确度都快接近80%了。

对于代码自己也在看后面会继续更新为自己加油吧