

tcp丢包的排查
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
丢包的排查
参考资料1、https://blog.csdn.net/maimang1001/article/details/121786580
2、https://blog.csdn.net/m0_67645544/article/details/124574099
1、 网卡丢包
a) ifconfig
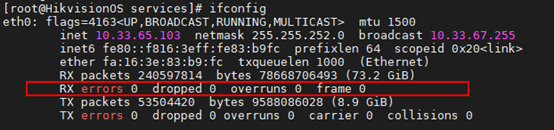
b) 查看网卡丢包统计(虚拟机看不到网卡信息)ethtool –S eth0

网卡(NIC)读取到数据帧后写入网卡内部的数据缓冲区(Ring Buffer),再生成中断触发内核从Ring Buffer中读取数据如果该数据缓冲区不够用新来的包就会被丢弃上述两图中就会有显示。
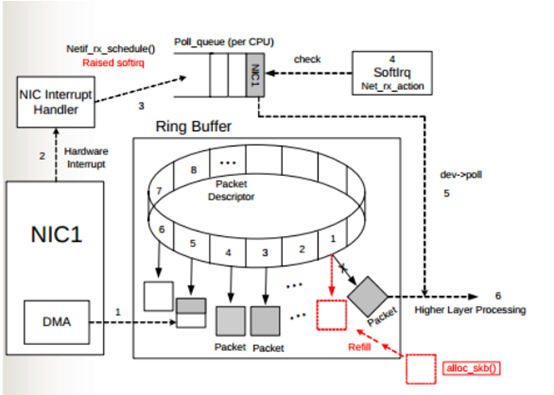
查看eth0网卡Ring Buffer最大值和当前设置
ethtool –g eth0
修改Ring Buffer大小
ethtool –G eth0 rx 4096 tx 4096
2、 netdev_max_backlog溢出
netdev_max_backlog 是内核从NIC(网卡)收到包后交由协议栈处理之前的缓冲队列。每个CPU核都有一个backlog队列当这个队列不够用溢出时数据包将被丢弃。
cat /proc/net/softnet_stat 查看是否发生了netdev_max_backlog溢出其中 每一行代表每一个CPU核的状态统计
第一列代表中断处理程序收到的包总数
第二列即代表由于 netdev_max_backlog 队列溢出而被丢弃的包总数
netdev_max_backlog 的默认值是 1000修改大小方法为
/etc/sysctl.conf里加上net.core.netdev_max_backlog=2000
再执行sysctl –p
3、 路由丢包
netsata –s|grep route 查看路由丢包
ip r 命令查看ip对应路由表
rp_filter反向路由过滤丢包反向路由过滤机制是Linux通过反向路由查询检查收到的数据包源IP是否可路由Loose mode、是否最佳路由Strict mode如果没有通过验证则丢弃数据包设计的目的是防范IP地址欺骗攻击。
rp_filter 提供三种模式供配置
0 - 不验证
1 - RFC3704定义的严格模式对每个收到的数据包查询反向路由如果数据包入口和反向路由出口不一致则不通过
2 - RFC3704定义的松散模式对每个收到的数据包查询反向路由如果任何接口都不可达则不通过
可通过修改/proc/sys/net/ipv4/conf/eth0/rp_filter值配置此项
4、 防火墙拦截
检查是否是防火墙引起的丢包 可以停掉iptables和firewalld, 查看命令systemctl status iptables.service / systemctl status firewalld.service
停止命令 systemctl stop iptables.service / systemctl stop firewalld.service
5、连接跟踪表溢出
kernel 用 ip_conntrack 模块来记录 iptables 网络包的状态并把每条记录保存到 table 里这个 table 在内存里可以通过 /proc/net/ip_conntrack 查看当前已经记录的总数如果网络状况繁忙比如高连接高并发连接等会导致逐步占用这个 table 可用空间一般这个 table 很大不容易占满并且可以自己清理table 的记录会一直呆在 table 里占用空间直到源 IP 发一个 RST 包但是如果出现被攻击、错误的网络配置、有问题的路由/路由器、有问题的网卡等情况的时候就会导致源 IP 发的这个 RST 包收不到这样就积累在 table 里越积累越多直到占满。无论哪种情况导致table变满满了以后就会丢包出现外部无法连接服务器的情况。内核会报如下错误信息kernel: ip_conntrack: table full, dropping packet
查看当前连接跟踪数 :
cat /proc/sys/net/netfilter/nf_conntrack_max
修改如下值
net.netfilter.nf_conntrack_max = 262144 #可以增大跟踪的条数
net.netfilter.nf_conntrack_tcp_timeout_established = 432000 #减小跟踪有效时间
6、 tcp连接跟踪安全检查
丢包原因由于连接没有断开但服务端或者client之前出现过发包异常等情况报文没有经过连接跟踪模块更新窗口计数没有更新合法的 window 范围导致后续报文安全检查被丢包协议栈用 nf_conntrack_tcp_be_liberal 来控制这个选项默认是1-不开启
- 1关闭只有不在tcp窗口内的rst包被标志为无效
- 0开启; 所有不在tcp窗口中的包都被标志为无效
7、 系统网络内存不足
系统内存不足创建新分片队列失败netstat -s |grep reassembles查看是否丢包
增大系统网络内存修改项
net.core.rmem_default
net.core.rmem_max
net.core.wmem_default
8、 TIME_WAIT过多
服务端在高并发的情况 主动关闭连接 会出现大量的socket处于timewait状态timewait数目超过tcp_max_tw_buckets(默认是65536)值后新来的连接直接进入close状态。
解决方法
a、tw_reusetw_recycle 必须在客户端和服务端 timestamps 开启时才管用默认打开
b、tw_reuse 只对客户端起作用开启后客户端在1s内回收
c、tw_recycle 对客户端和服务器同时起作用开启后在 3.5*RTO 内回收RTO 200ms~ 120s具体时间视网络状况。内网状况比 tw_reuse 稍快公网尤其移动网络大多要比 tw_reuse 慢优点就是能够回收服务端的 TIME_WAIT 数量在服务端如果网络路径会经过NAT节点不要启用 net.ipv4.tcp_tw_recycle会导致时间戳混乱引起其他丢包问题
d、调整 tcp_max_tw_buckets 大小
9、时间戳异常
服务端开启快速回收机制后 net.ipv4.tcp_tw_recycle为1(前提tcp_timestamps为1)NAT环境里的多个客户端连接服务端时 因为时间戳校验导致会导致SYN包被丢弃。通过命令netstat –s|grep rejects查看确认丢包。
tcp_timestamps开启后linux内核会开启 PAWS 机制。PAWS是为了防止TCP序列号绕回会维护最近一次收到数据包的时间戳Recent TSval如果接下来的数据包时间戳小于这个即不是递增的时间戳就会直接丢弃这个数据包。这种情况下是用「IP + 端口」四元组区分连接。
而开启timewait快速回收后PAWS检查是针对IP做区分这样同一个NAT环境里的不同客户端连接都会被检查同一时间戳
10、tcp全连接队列长度不够
tcp连接linux内核维护一个半队列和一个全连接队列
半连接队列中存放等待完成3次握手的连接这些连接的状态为Syn_RECV 该队列长度为max(64,/proc/sys/net/ipv4/tcp_max_syn_backlog)
全连接队列存放完成3次握手等待accpet的连接此时的状态已经是ESTABLISHED这个队列的长度min(backlog, somaxconn)backlog 的值则应该是由 int listen(int sockfd, int backlog) 中的第二个参数指定somaxconn由net.core.somaxconn决定
可以通过命令netstat –s|grep listen 查看是否丢包