

kubernetes 污点(Taint)和容忍度(Toleration)研究
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.文档
官方文档https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/taint-and-toleration/
2.知识点
2.1.什么污点和容忍度?
污点(Taint) 是应用在节点之上的,从这个名字就可以看出来,是为了排斥pod 所存在的。
容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
2.2.污点和容忍度的作用?
Taint(污点)和 Toleration(容忍)可以作用于node和 pod 上,其目的是优化pod在集群间的调度,这跟节点亲和性类似,只不过它们作用的方式相反,具有taint的node和pod是互斥关系,而具有节点亲和性关系的node和pod是相吸的。另外还有可以给node节点设置label,通过给pod设置nodeSelector将pod调度到具有匹配标签的节点上。
Taint 和 toleration 相互配合,可以用来避免pod被分配到不合适的节点上。每个节点上都可以应用一个或多个taint,这表示对于那些不能容忍这些taint的 pod,是不会被该节点接受的。如果将toleration应用于pod上,则表示这些pod可以(但不要求)被调度到具有相应taint的节点上。
2.3.给节点设置/移除污点
给节点node1增加一个污点,它的键名是key1,键值是value1,效果是NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到node1这个节点。
kubectl taint nodes node1 key1=value1:NoSchedule
若要移除上述命令所添加的污点,你可以执行:
kubectl taint nodes node1 key1=value1:NoSchedule-
2.4.查看节点污点
sudo kubectl describe node master.cluster.k8s
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl describe node master.cluster.k8s
Name: master.cluster.k8s
Roles: control-plane
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=master.cluster.k8s
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node.kubernetes.io/exclude-from-external-load-balancers=
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"3e:ff:5f:de:af:30"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 10.0.22.121
kubeadm.alpha.kubernetes.io/cri-socket: unix:///var/run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 08 Jul 2022 08:55:07 +0000
Taints: key1=value1:NoSchedule
node-role.kubernetes.io/master:NoSchedule2.5.在pod 中定义容忍度
可以在 PodSpec 中定义 Pod 的容忍度。 下面两个容忍度均与上面例子中使用kubectl taint命令创建的污点相匹配, 因此如果一个 Pod 拥有其中的任何一个容忍度都能够被分配到node1:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"实例
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"operator 的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
如果 operator 是 Exists (此时容忍度不能指定 value)
如果 operator 是 Equal ,则它们的 value 应该相等
如果 operator 不指定,则默认为Equal
注意:
如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key 、value 和 effect 都匹配,即这个容忍度能容忍任意 taint。
如果 effect 为空,则可以与所有键名 key1 的效果相匹配。
effect 的参数含义
NoSchedule 新的不能容忍的pod不能再调度过来,但是之前运行在node节点中的Pod不受影响
NoExecute 新的不能容忍的pod不能调度过来,老的pod也会被驱逐
PreferNoScheduler 表示尽量不调度到污点节点中去
2.6.多个污点的匹配原则
可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点,特别是以下情况:
如果未被过滤的污点中存在至少一个 effect 值为 NoSchedule 的污点, 则 Kubernetes 不会将 Pod 分配到该节点。
如果未被过滤的污点中不存在 effect 值为 NoSchedule 的污点, 但是存在 effect 值为 PreferNoSchedule 的污点, 则 Kubernetes 会 尝试 不将 Pod 分配到该节点。
如果未被过滤的污点中存在至少一个 effect 值为 NoExecute 的污点, 则 Kubernetes 不会将 Pod 分配到该节点(如果 Pod 还未在节点上运行), 或者将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
例如,假设您给一个节点添加了如下污点
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
假定有一个 Pod,它有两个容忍度:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"上述 Pod 不会被分配到 node1 节点,因为其没有容忍度和第三个污点相匹配。
但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行, 那么它还可以继续运行在该节点上,因为第三个污点是三个污点中唯一不能被这个 Pod 容忍的。
2.7.设置NoExcute 的驱逐时间
通常情况下,如果给一个节点添加了一个 effect 值为NoExecute的污点, 则任何不能忍受这个污点的 Pod 都会马上被驱逐, 任何可以忍受这个污点的 Pod 都不会被驱逐。
但是,如果 Pod 存在一个 effect 值为NoExecute的容忍度指定了可选属性tolerationSeconds的值,则表示在给节点添加了上述污点之后, Pod 还能继续在节点上运行的时间。
例如
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600这表示如果这个 Pod 正在运行,同时一个匹配的污点被添加到其所在的节点, 那么 Pod 还将继续在节点上运行 3600 秒,然后被驱逐。 如果在此之前上述污点被删除了,则 Pod 不会被驱逐。
2.8.基于污点的驱逐
这是在每个 Pod 中配置的在节点出现问题时的驱逐行为。
前文提到过污点的 effect 值 NoExecute会影响已经在节点上运行的 Pod
如果 Pod 不能忍受 effect 值为 NoExecute 的污点,那么 Pod 将马上被驱逐
如果 Pod 能够忍受 effect 值为 NoExecute 的污点,但是在容忍度定义中没有指定 tolerationSeconds,则 Pod 还会一直在这个节点上运行。
如果 Pod 能够忍受 effect 值为 NoExecute 的污点,而且指定了 tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。
当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括:
node.kubernetes.io/not-ready:节点未准备好。这相当于节点状态 Ready 的值为 "False"。
node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状态 Ready 的值为 "Unknown"。
node.kubernetes.io/memory-pressure:节点存在内存压力。
node.kubernetes.io/disk-pressure:节点存在磁盘压力。
node.kubernetes.io/pid-pressure: 节点的 PID 压力。
node.kubernetes.io/network-unavailable:节点网络不可用。
node.kubernetes.io/unschedulable: 节点不可调度。
node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个 "外部" 云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
在节点被驱逐时,节点控制器或者 kubelet 会添加带有NoExecute效应的相关污点。 如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。
实例
一个使用了很多本地状态的应用程序在网络断开时,仍然希望停留在当前节点上运行一段较长的时间, 愿意等待网络恢复以避免被驱逐。在这种情况下,Pod 的容忍度可能是下面这样的:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000说明:
Kubernetes 会自动给 Pod 添加一个 key 为 node.kubernetes.io/not-ready 的容忍度 并配置 tolerationSeconds=300,除非用户提供的 Pod 配置中已经已存在了 key 为 node.kubernetes.io/not-ready 的容忍度。
同样,Kubernetes 会给 Pod 添加一个 key 为 node.kubernetes.io/unreachable 的容忍度 并配置 tolerationSeconds=300,除非用户提供的 Pod 配置中已经已存在了 key 为 node.kubernetes.io/unreachable 的容忍度。
这种自动添加的容忍度意味着在其中一种问题被检测到时 Pod 默认能够继续停留在当前节点运行 5 分钟。
注意:DaemonSet 中的 Pod 被创建时, 针对以下污点自动添加的 NoExecute 的容忍度将不会指定 tolerationSeconds:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
这保证了出现上述问题时 DaemonSet 中的 Pod 永远不会被驱逐。
3.实例
目前有2节点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
master.cluster.k8s Ready control-plane 208d v1.24.2
server Ready <none> 204d v1.24.2以zookeeper部署作为实例:https://kubernetes.io/zh-cn/docs/tutorials/stateful-application/zookeeper/
3.1.节点master1个污点未被容忍
3.1.1.污点配置
master节点master.cluster.k8s设置key1=value1不可执行的污点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl taint nodes master.cluster.k8s key1=value1:NoSchedule
node/master.cluster.k8s taintedmaster节点污点:
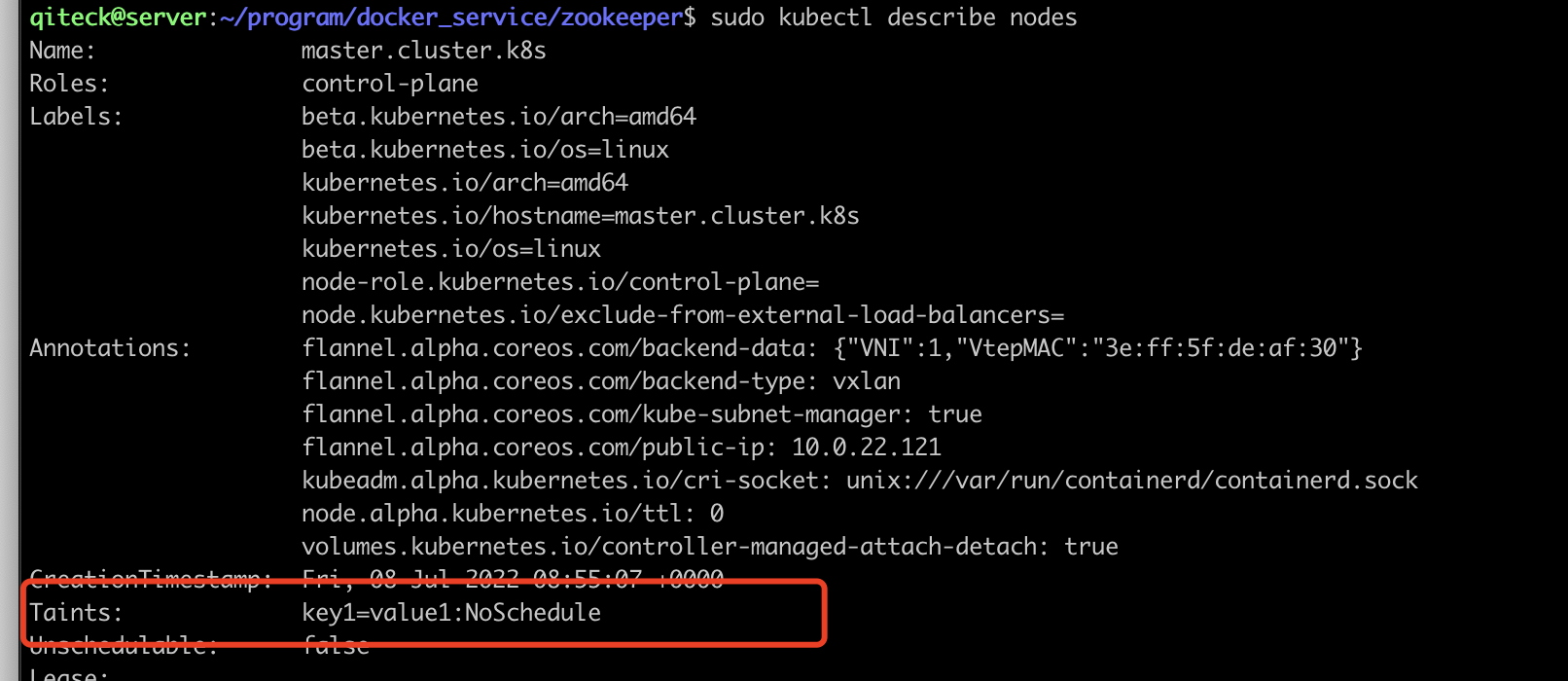
server节点污点:
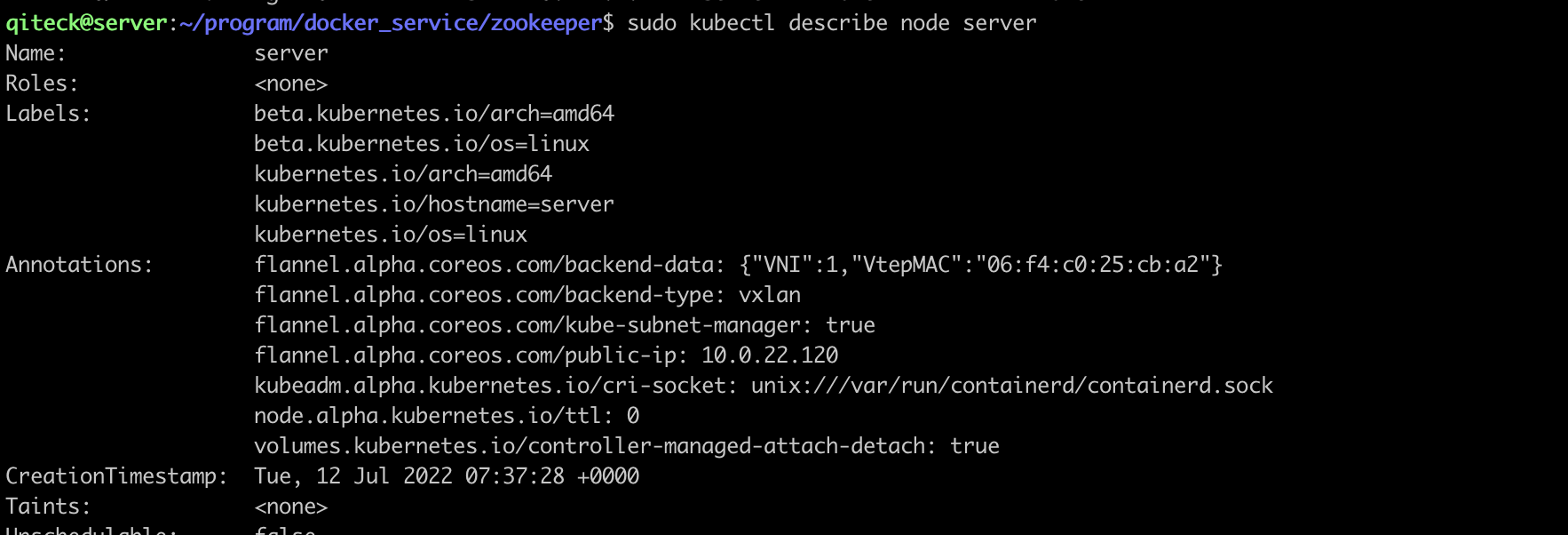
3.1.2.zookeeper配置
不设置容忍
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
namespace: kafka
labels:
app: kafka
spec:
ports:
- port: 9092
name: server
clusterIP: None
selector:
app: kafka
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: kafka-pdb
namespace: kafka
spec:
selector:
matchLabels:
app: kafka
minAvailable: 2
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
namespace: kafka
spec:
selector:
matchLabels:
app: kafka
serviceName: kafka-svc
replicas: 3
template:
metadata:
labels:
app: kafka
spec:
terminationGracePeriodSeconds: 300
securityContext:
runAsUser: 1000
fsGroup: 1000
containers:
- name: kafka
imagePullPolicy: Always
image: duruo850/kafka:v3.3.2
resources:
requests:
memory: "100Mi"
cpu: 100m
ports:
- containerPort: 9092
name: server
command:
- sh
- -c
- "exec kafka-server-start.sh /opt/kafka/config/server.properties --override broker.id=${HOSTNAME##*-} \
--override listeners=PLAINTEXT://:9092 \
--override zookeeper.connect=zk-0.zk-hs.kafka.svc.cluster.local:2181,zk-1.zk-hs.kafka.svc.cluster.local:2181,zk-2.zk-hs.kafka.svc.cluster.local:2181 \
--override log.dir=/var/lib/kafka \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=false \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
#--override inter.broker.protocol.version=o.11.0.3 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157E308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=CreateTime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=4 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000 "
env:
- name: KAFKA_HEAP_OPTS
value: "-Xmx512M -Xms512M"
- name: KAFKA_OPTS
value: "-Dlogging.level=INFO"
volumeMounts:
- name: datadir
mountPath: /var/lib/kafka
readinessProbe:
tcpSocket:
port: 9092
timeoutSeconds: 1
initialDelaySeconds: 5
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: kafka
resources:
requests:
storage: 300Mi3.1.3.部署
sudo kubectl apply -f zookeeper_not_toleration.yaml
3.1.4.效果
master有1污点:
key1:value1:NoSchedule
被容忍了0个污点:
由于key1污点1在,所以master无法部署,只能在server节点部署

3.2.节点master1个污点被容忍
3.2.1.污点配置
master节点master.cluster.k8s设置key1=value1不可执行的污点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl taint nodes master.cluster.k8s key1=value1:NoSchedule
node/master.cluster.k8s taintedmaster节点污点:
server节点污点:
3.2.2.zookeeper配置
设置容忍key1value1
apiVersion: v1
kind: Service
metadata:
name: zk-hs
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
name: zk-cs
labels:
app: zk
spec:
ports:
- port: 2181
name: client
selector:
app: zk
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
selector:
matchLabels:
app: zk
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: zk
spec:
securityContext:
runAsUser: 1000
fsGroup: 1000
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
containers:
- name: kubernetes-zookeeper
imagePullPolicy: Always
image: "registry.k8s.io/kubernetes-zookeeper:1.0-3.4.10"
resources:
requests:
memory: "200Mi"
cpu: "0.1"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: zookeeper
resources:
requests:
storage: 200Mi3.2.3.部署
sudo kubectl apply -f zookeeper_toleration_key1valu1.yaml
3.2.4.效果
master有1污点:
key1:value1:NoSchedule
被容忍了1个污点:
key1:value1:NoSchedule
由于污点1被容忍,所以master可以部署

3.3. 节点master2个污点1个被容忍
3.3.1.污点配置
master节点master.cluster.k8s设置key1=value1不可执行的污点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl taint nodes master.cluster.k8s key1=value1:NoSchedule
node/master.cluster.k8s taintedmaster节点master.cluster.k8s设置key2=value2不可执行的污点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl taint nodes master.cluster.k8s key2=value2:NoSchedule
node/master.cluster.k8s taintedmaster节点污点:
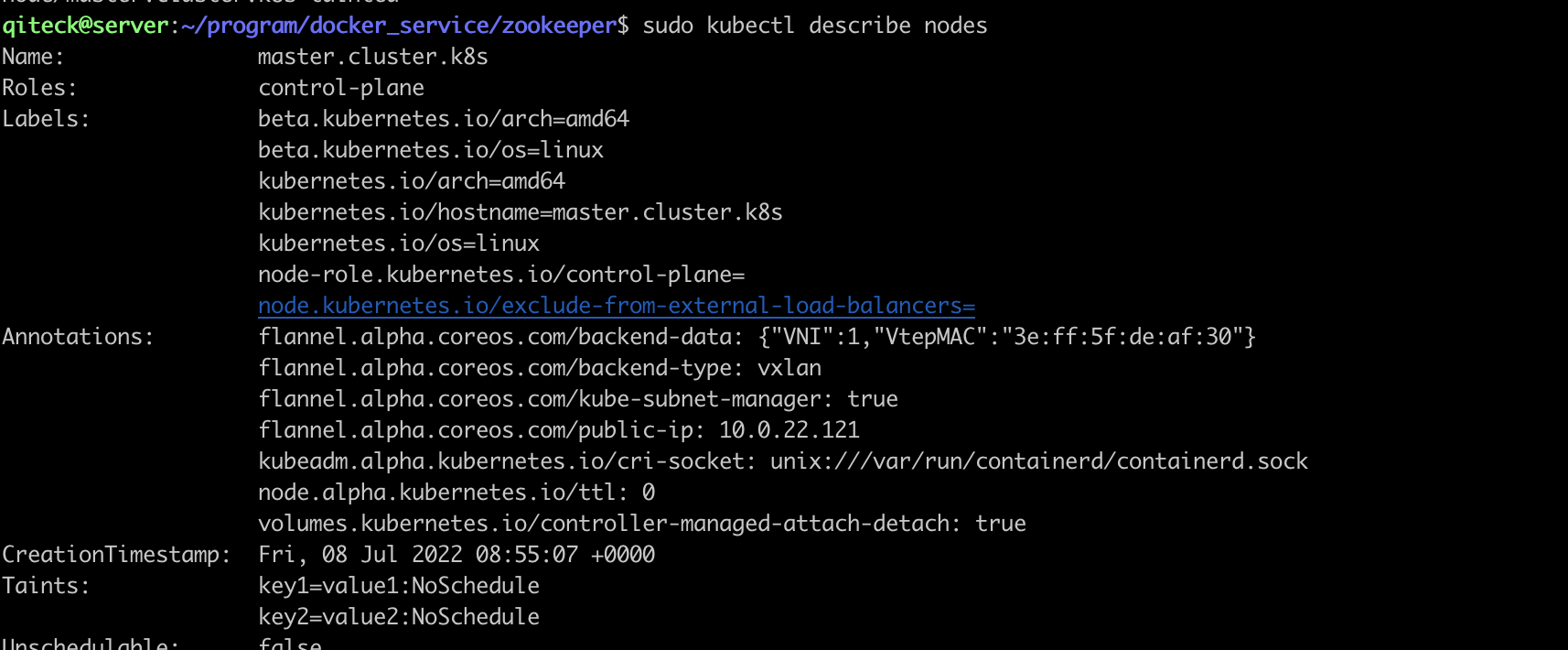
server节点污点:
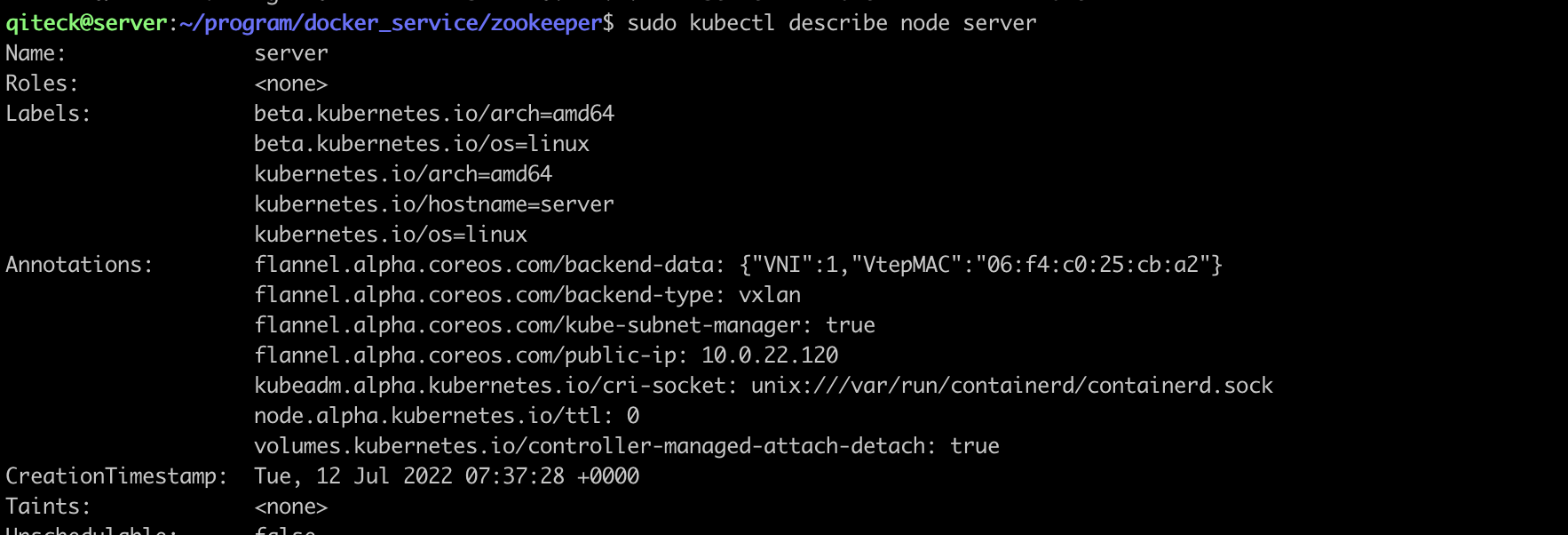
3.3.2. zookeeper配置
设置容忍key1value1
apiVersion: v1
kind: Service
metadata:
name: zk-hs
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
name: zk-cs
labels:
app: zk
spec:
ports:
- port: 2181
name: client
selector:
app: zk
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
selector:
matchLabels:
app: zk
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: zk
spec:
securityContext:
runAsUser: 1000
fsGroup: 1000
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
containers:
- name: kubernetes-zookeeper
imagePullPolicy: Always
image: "registry.k8s.io/kubernetes-zookeeper:1.0-3.4.10"
resources:
requests:
memory: "200Mi"
cpu: "0.1"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: zookeeper
resources:
requests:
storage: 200Mi3.3.3.部署
sudo kubectl apply -f zookeeper_toleration_key1valu1.yaml
3.3.4.效果
master有2污点:
key1:value1:NoSchedule
key2:value2:NoSchedule
被容忍了1个污点:
key1:value1:NoSchedule
由于key2污点还在,所以master无法部署,只能在server节点部署

3.4. 节点master2个污点2个被容忍
3.4.1.污点配置
master节点master.cluster.k8s设置key1=value1不可执行的污点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl taint nodes master.cluster.k8s key1=value1:NoSchedule
node/master.cluster.k8s taintedmaster节点master.cluster.k8s设置key2=value2不可执行的污点:
qiteck@server:~/program/docker_service/zookeeper$ sudo kubectl taint nodes master.cluster.k8s key2=value2:NoSchedule
node/master.cluster.k8s taintedmaster节点污点:
server节点污点:
3.4.2. zookeeper配置
设置容忍key1value1key2value2
apiVersion: v1
kind: Service
metadata:
name: zk-hs
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
name: zk-cs
labels:
app: zk
spec:
ports:
- port: 2181
name: client
selector:
app: zk
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
selector:
matchLabels:
app: zk
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: zk
spec:
securityContext:
runAsUser: 1000
fsGroup: 1000
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key2"
operator: "Equal"
value: "value2"
effect: "NoSchedule"
containers:
- name: kubernetes-zookeeper
imagePullPolicy: Always
image: "registry.k8s.io/kubernetes-zookeeper:1.0-3.4.10"
resources:
requests:
memory: "200Mi"
cpu: "0.1"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: zookeeper
resources:
requests:
storage: 200Mi3.4.3.部署
sudo kubectl apply -f zookeeper_toleration_key1valu1key2value2.yaml
3.4.4.效果
master有2污点:
key1:value1:NoSchedule
key2:value2:NoSchedule
被容忍了2个污点:
key1:value1:NoSchedule
key2:value2:NoSchedule
由于master污点都被容忍了,所以master可以部署:

| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |