

MongoDB 聚合操作注意事项
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

MongoDB, 虽然一直是被称为NO SQL ,文档数据库,可最近这两年MONGODB 没闲着,MONGODB 作为大数据分析的数据存储空间使用的现在大有人在。
聚合作为MONGODB对于传统数据库 GROUP BY ,甚至窗口函数的在MONGODB的体现,是比较常用的。 数据量小的情况下,性能不是问题,而如果数据量大的情况下,一般使用MONGODB 的聚合操作是有技巧和注意的。
首先的从聚合的初级原理说起,MONGODB 的聚合是分阶段的,大致可以简单的分离出,数据的提取,和数据计算。
下面的图中,就是在聚合操作中可能会遇到的坑,在做一个简单的聚合中,(数据量5000万,为了浮现问题,所以直接做聚合,而且做得值是随机值,所以你懂得) ,在操作中直接报错,这个报错信息是由于在操作聚合时,pipleline stage (具体看你的操作,这里是group stage,的使用已经超过MONGODB 的限制 100MB) ,所以在数据量较大的情况下,并且没有进行数据额过滤,或者数据过滤(这里叫$match)后,还是数据量巨大的情况下,我们应该在做聚合的时候,添加一个参数,这个参数是在 MONGODB 3.4 支持的。
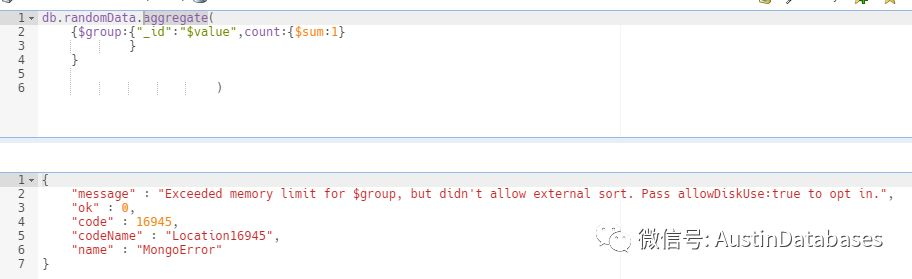
具体语句是
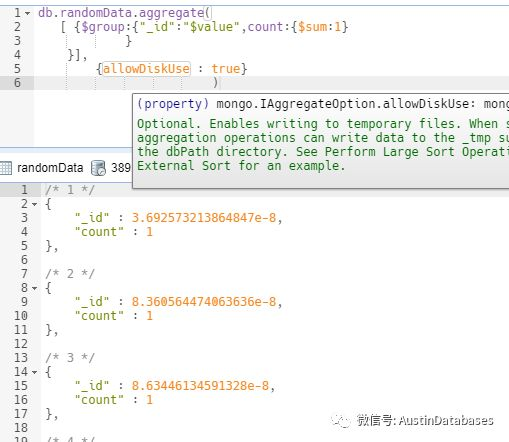
样的情况下,就可以利用物理磁盘的环境来突破做聚合的限制。
那一般来说做聚合中需要注意什么总结有以下几点(非完整,目前没有使用到一些操作,这些操作不在总结范围内)
1,不再聚合范围的数据要进行$match 提前过滤
2,显示的字段要进行控制,与聚合无关的字段,应该提前$project
3, 如果聚合中包含排序,则排序要在$match之下
4,当有多个$match操作时,尽量进行合并。
5, 对于 $match操作的 或 $sort 操作,在数据量大的情况下应该建立索引
6 如果操作中包含$sort $limit的操作,应该将$limit 的操作后置
另根据当前的情况,大部分聚合可以优化的命令在 MONGODB 3.4 及以上的版本。所以如果大数据量做聚合的运算,还是升级到 3.4 及以上的版本为好。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |