

spark为什么比hadoop快
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
网上一堆人根本对计算框架一知半解就出来糊弄人常见解答有:
spark是基于内存计算所以快。这跟废话似的mr计算的时候不也是基于内存?
mr shuffle落盘。这也是胡扯 spark shuffle不落盘?
实际上如果一个job只有一个map task和reduce task那么spark并不会比mr快很多。spark快的真正原因是当一个job具有多个stage时 我们将这个job表示为 [ m a p 1 , r e d u c e 1 , m a p 2 , r e d u c e 2 . . . r e d u c e n − 1 , m a p n . . . ] [map_1, reduce_1, map_2, reduce_2...reduce_{n-1}, map_n...] [map1,reduce1,map2,reduce2...reducen−1,mapn...]那么mr会在每一个 r e d u c e n − 1 reduce_{n-1} reducen−1和 m a p n map_n mapn之间进行一次落盘和一次文件读取而spark因为可以将窄依赖的算子合并为一个stage(得益于spark的DAG计算机制)所以在 r e d u c e n − 1 reduce_{n-1} reducen−1和 m a p n map_n mapn之间是不涉及落盘的直接基于内存计算。
举个小例子加深理解假设一个job涉及两个stage那么mr和spark的运行过程是这样的:
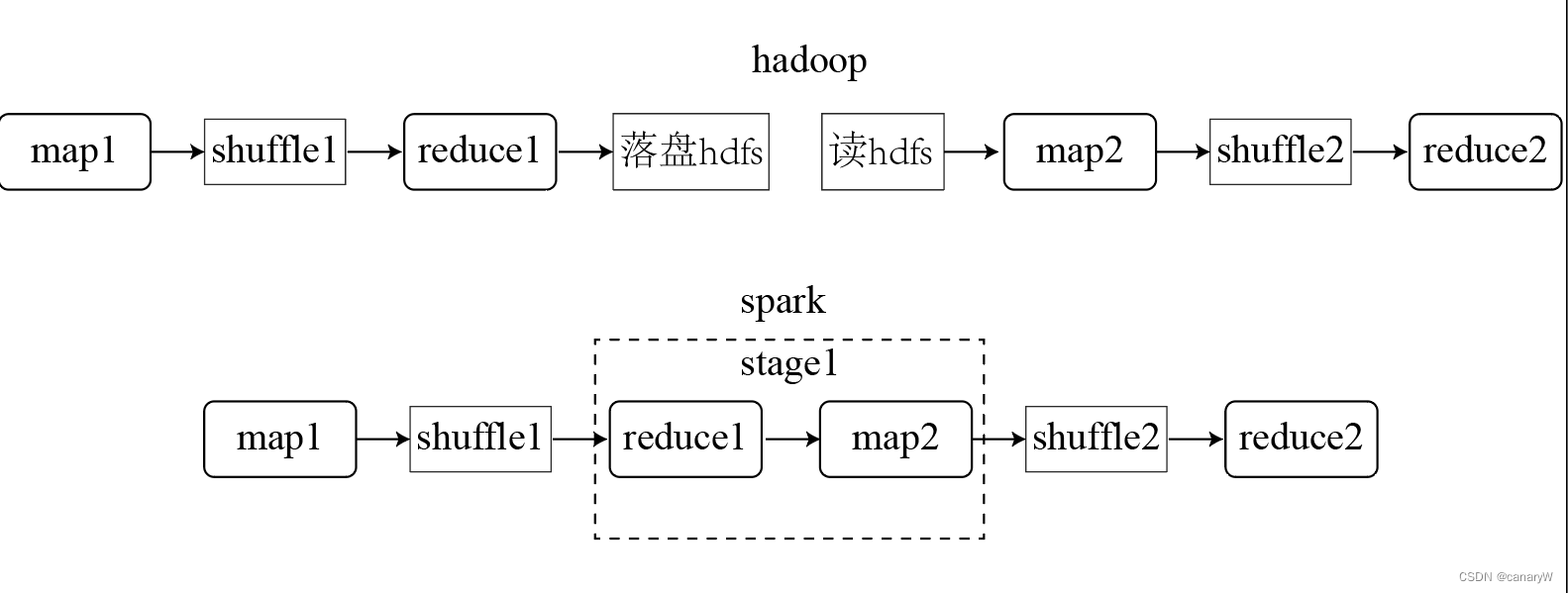
可以看到 spark相较于MR而言少了一次hdfs文件落盘和一次文件读取如果一个job有
n
n
n个stage比方说是机器学习算法那么spark可以节省
n
−
1
n-1
n−1次文件落盘、读取。因此速度会快很多。