6. 描述性统计函数:summary 、Fivenum、describe、describeBy、stat.desc、 Aggregate、summaryBy
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
b站课程视频链接
https://www.bilibili.com/video/BV19x411X7C6?p=1
腾讯课堂(最新但是要花钱我花99😢😢元买了感觉讲的没问题就是知识点结构有点乱有点废话
https://ke.qq.com/course/3707827#term_id=103855009
本笔记前面的笔记参照b站视频【后面的画图】参考了付费视频
笔记顺序做了些调整【个人感觉逻辑顺畅】并删掉一些不重要的内容以及补充了个人理解
系列笔记目录【持续更新】https://blog.csdn.net/weixin_42214698/category_11393896.html
文章目录
1. summary( ) 、Fivenum( )
首先是summary()函数运行一次该函数就可以对数据进行详细的统计。
> myvars <- mtcars[c("mpg", "hp", "wt", "am")]
>
> 使用summary()函数计算变量的数据结果包括最小值下四分位数中四分位数数值型变量的均值上四分位数 和 最大值
> summary(myvars)
mpg hp wt am
Min. :10.40 Min. : 52.0 Min. :1.513 Min. :0.0000
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581 1st Qu.:0.0000
Median :19.20 Median :123.0 Median :3.325 Median :0.0000
Mean :20.09 Mean :146.7 Mean :3.217 Mean :0.4062
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610 3rd Qu.:1.0000
Max. :33.90 Max. :335.0 Max. :5.424 Max. :1.0000
>Fivenum()函数和summary()函数类似但可以返回5个基本的统计量包括最小值四分位数、中位数、上四位数、最大值
> fivenum(myvars$hp)
[1] 52 96 123 180 335
>
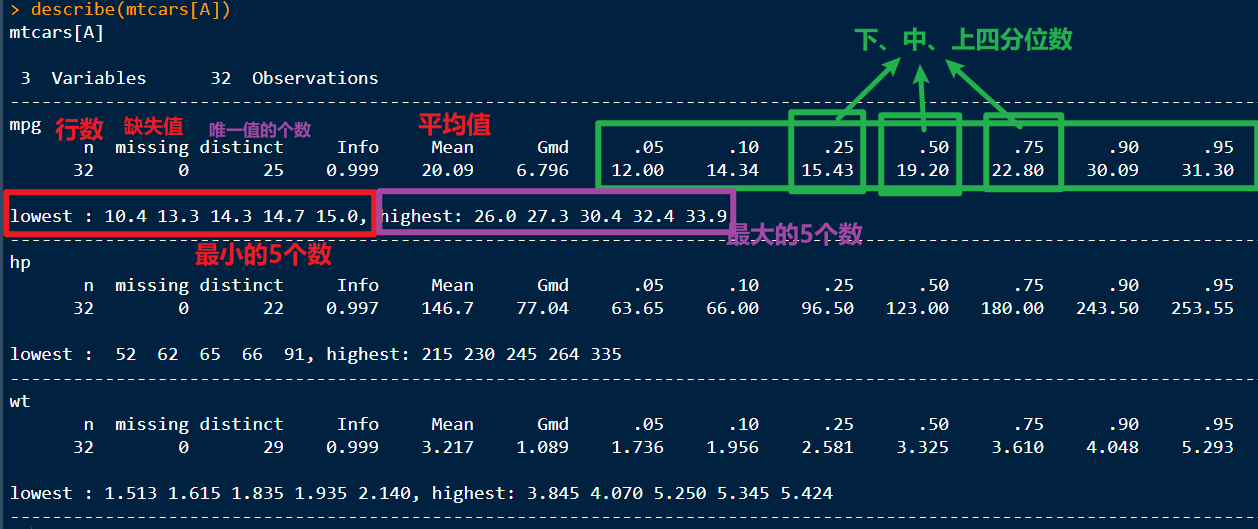
2. Hmisc包中的describe( )
Hmisc包中的describe()函数也可以计算统计量可以返回变量和观测的数量、缺失值和唯一值的数目、以及平均值、分位数、已经五个最大的值和五个最小的值
install.packages("Hmisc")
library(Hmisc)
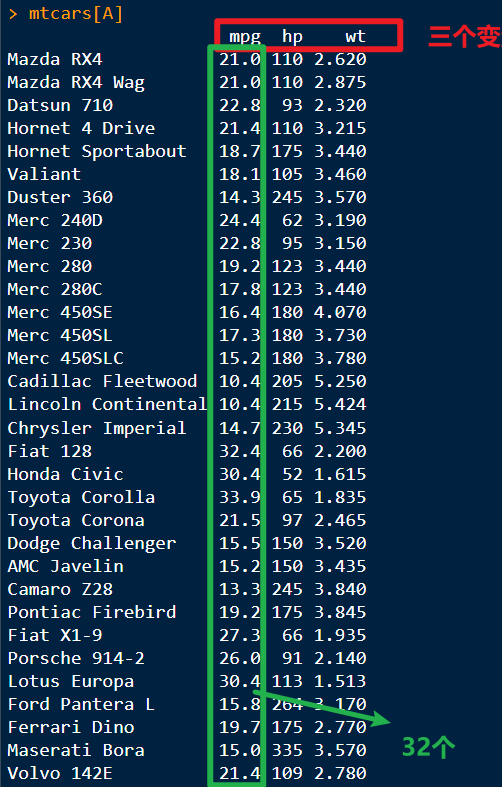
A <- c("mpg", "hp", "wt")
mtcars[A]
describe(mtcars[A])
3. pastecs包中有一个stat.desc()
格式为
stat.desc(x , basic = TRUE , desc =TRUE , norm=FALSE , p=0.95)
x一个数据框或时间序列it
basic=TRUE默认值则计算全部值、空值、缺失值的数量以及最小值、最大值、值域还有总和io
desc=TRUE默认值则计算中位数、平均数、平均数的标准误、平均数置信度为95%的置信区间、方差、标准差以及变异系数ast
norm=TRUE非默认
返回正态分布统计量包括偏度和峰度以及她们的统计显著程度和Shapiro-Wilk正态检验结果function
pp值来计算平均数的置信区间默认置信度为0.95
例子
>install.packages("pastecs")
>library(pastecs)
>A <- c("mpg", "hp", "wt")
> stat.desc(mtcars[A])
mpg hp wt
nbr.val 32.0000000 32.0000000 32.0000000
nbr.null 0.0000000 0.0000000 0.0000000
nbr.na 0.0000000 0.0000000 0.0000000
min 10.4000000 52.0000000 1.5130000
max 33.9000000 335.0000000 5.4240000
range 23.5000000 283.0000000 3.9110000
sum 642.9000000 4694.0000000 102.9520000
median 19.2000000 123.0000000 3.3250000
mean 20.0906250 146.6875000 3.2172500
SE.mean 1.0654240 12.1203173 0.1729685
CI.mean.0.95 2.1729465 24.7195501 0.3527715
var 36.3241028 4700.8669355 0.9573790
std.dev 6.0269481 68.5628685 0.9784574
coef.var 0.2999881 0.4674077 0.3041285
4. psych包中的describe( ) 、describeBy( )
1️⃣describe( )
psych包中也有一个describe()函数可以计算
非缺失值的数量、平均数、标准差、中位数、截尾的均值、最大值、最小值、偏度和峰度等等内容
截尾的均值是去掉两头的数据取均值就像打分时去掉一个最低分、去掉一个最高分然后中间数据求均值。可以通过设置trim参数设置去除比例如trim=0.1则是去除数据中最高和最低的10%的部分
当两个包的函数名一样时后面载入的包的函数会覆盖前面载入的包的函数如果要使用前面一个包的函数只需要在包后加冒号再使用即可如Hmisc::describe()
>install.packages("psych")
>library(psych)
> A <- c("mpg", "hp", "wt")
> describe(mtcars[A],trim = 0.1) # 这里是psych包下优先考虑最后导入的包
vars n mean sd median trimmed mad min max range skew kurtosis se
mpg 1 32 20.09 6.03 19.20 19.70 5.41 10.40 33.90 23.50 0.61 -0.37 1.07
hp 2 32 146.69 68.56 123.00 141.19 77.10 52.00 335.00 283.00 0.73 -0.14 12.12
wt 3 32 3.22 0.98 3.33 3.15 0.77 1.51 5.42 3.91 0.42 -0.02 0.17
2️⃣describeBy( )
library(psych)
A <- c("mpg", "hp", "wt")
> describeBy(mtcars[A], list(am=mtcars$am))
Descriptive statistics by group
am: 0
vars n mean sd median trimmed mad min max range skew kurtosis se
mpg 1 19 17.15 3.83 17.30 17.12 3.11 10.40 24.40 14.00 0.01 -0.80 0.88
hp 2 19 160.26 53.91 175.00 161.06 77.10 62.00 245.00 183.00 -0.01 -1.21 12.37
wt 3 19 3.77 0.78 3.52 3.75 0.45 2.46 5.42 2.96 0.98 0.14 0.18
------------------------------------------------------------------------
am: 1
vars n mean sd median trimmed mad min max range skew kurtosis se
mpg 1 13 24.39 6.17 22.80 24.38 6.67 15.00 33.90 18.90 0.05 -1.46 1.71
hp 2 13 126.85 84.06 109.00 114.73 63.75 52.00 335.00 283.00 1.36 0.56 23.31
wt 3 13 2.41 0.62 2.32 2.39 0.68 1.51 3.57 2.06 0.21 -1.17 0.17
>
describeBy( )适合详细查看每一个分组的统计值但缺点是给出的统计值是固定不变的没办法使用自定义的函数
5. Aggregate( ) 【动词聚合】
> # 使用mass这个包中的cars93数据集【93年许多不同汽车的指标】
> library(MASS)
> # 选取其中三列
> B <- Cars93[c("Min.Price","Price","Max.Price","MPG.city")]
> #根据汽车制造商Cars93$Manufacturer来对数据进行分组统计计算每个汽车制造商这三列的平均值
> aggregate(B , by=list(Manufacturer=Cars93$Manufacturer) , mean)
Manufacturer Min.Price Price Max.Price MPG.city
1 Acura 21.05000 24.90000 28.750 21.50000
2 Audi 28.35000 33.40000 38.450 19.50000
3 BMW 23.70000 30.00000 36.200 22.00000
4 Buick 20.75000 21.62500 22.550 19.00000
5 Cadillac 35.25000 37.40000 39.500 16.00000
6 Chevrolet 16.08750 18.18750 20.325 19.62500
7 Chrylser 18.40000 18.40000 18.400 20.00000
8 Chrysler 22.00000 22.65000 23.300 21.50000
9 Dodge 12.51667 15.70000 18.900 21.66667
10 Eagle 12.70000 15.75000 18.850 24.50000
11 Ford 12.43750 14.96250 17.500 22.00000
12 Geo 9.10000 10.45000 11.750 38.00000
一共有32列..
> #根据产地计算平均值
> aggregate(B,by=list(Origin=Cars93$Origin),mean)
Origin Min.Price Price Max.Price MPG.city
1 USA 16.53542 18.57292 20.62708 20.95833
2 non-USA 17.75556 20.50889 23.25556 23.86667
# 计算标准差
aggregate(B,by=list(Manufacturer=Cars93$Manufacturer),sd)
aggregate(B,by=list(Origin=Cars93$Origin),sd)
也可以一次性使用多个分组条件只需要在列表中添加即可例如同时使用产地和制造商来分组
> aggregate(B, by=list(Origin=Cars93$Origin,Manufacturer=Cars93$Manufacturer),mean)
Origin Manufacturer Min.Price Price Max.Price MPG.city
1 non-USA Acura 21.05000 24.90000 28.750 21.50000
2 non-USA Audi 28.35000 33.40000 38.450 19.50000
3 non-USA BMW 23.70000 30.00000 36.200 22.00000
4 USA Buick 20.75000 21.62500 22.550 19.00000
5 USA Cadillac 35.25000 37.40000 39.500 16.00000
6 USA Chevrolet 16.08750 18.18750 20.325 19.62500
7 USA Chrylser 18.40000 18.40000 18.400 20.00000
8 USA Chrysler 22.00000 22.65000 23.300 21.50000
9 USA Dodge 12.51667 15.70000 18.900 21.66667
10 USA Eagle 12.70000 15.75000 18.850 24.50000
一共有32列..
aggregate函数的缺点是一次只用使用一个统计函数比如只能返回平均值、方差等可以使用一些扩展包来进行分组计算并实现返回多种描述性统计量
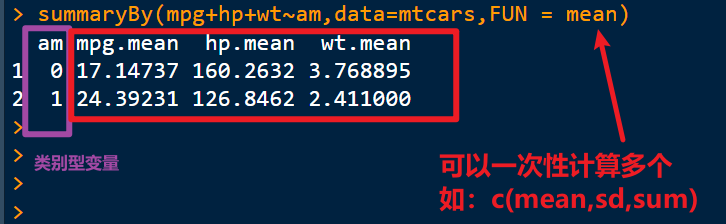
6. doBy包中的summaryBy( )
summary_by(data, formula,id = NULL,FUN = mean..)
data参数指定数据集
formula格式为波浪线左侧 ~ 波浪线右侧
波浪线左侧是需要分析的数值型变量直接写数据框中的列的名字就可以不需要添加引号不同变量之间用+号表示
右侧的变量是“类别型”的分组变量
fun参数指定统计函数也可以是自定义函数