

老司机经验分享:生产级中间件系统架构设计实践
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
目录
- 1、Master-Slave架构
- 2、异步日志持久化机制
- 3、检查点机制定时持久化全量数据
- 4、引入检查点节点
- 5、总结 & 思考
这篇文章给大家来聊一个生产级的中间件系统的架构设计实践希望给对中间件系统感兴趣的同学一点启发。
1、Master-Slave架构
这个中间件系统的本质是希望能够用分布式的方式来处理一些数据但是具体的作用涉及到核心技术所以这里不能直接说明。
但是他的核心思想就是把数据分发到很多台机器上来处理然后需要有一台机器来控制N多台机器的分布式处理大概如下图所示。
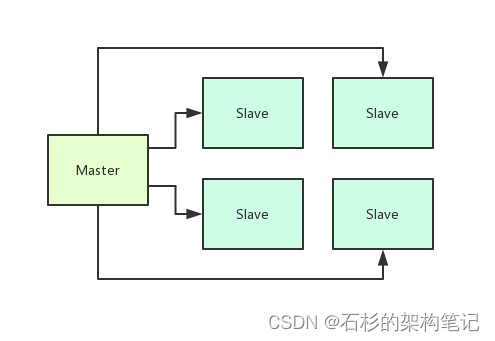
那么既然是分布式的处理就肯定涉及到在Master中要维护这个集群的一些核心元数据。
比如说数据的分发处理是如何调度的处理的具体过程现在什么进度了还有就是对集群里存放数据进行描述的一些核心元数据。
这些核心元数据肯定会不断的频繁的修改大家此时可以想无论你是基于外部的文件还是数据库或者是zookeeper来存放这些元数据的话其实都会导致他的元数据更新性能降低因为要访问外部依赖。
何况这种复杂的元数据其实还不一定能通过zk或者数据库来存放因为他可能是非格式化的。
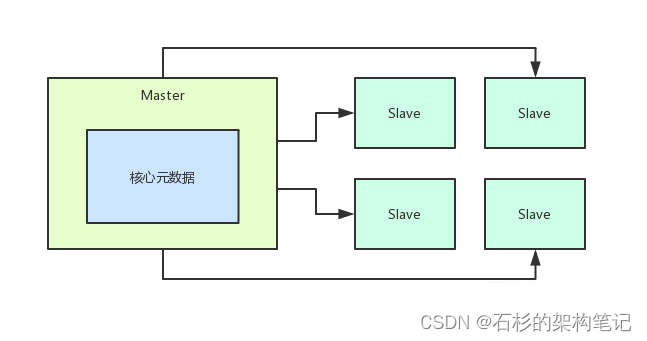
所以这里一个核心的设计就是将核心元数据直接存放在Master的内存里这样可以保证高并发更新元数据的时候他的性能是极高的而且直接基于内存来提供对外的更新服务。
如果Master部署在高配置物理机上比如32核128GB的那种每秒支持10万+的请求都没问题。
2、异步日志持久化机制
但是这里有一个问题假如说Master进程重启或者是突然宕机了那么内存里的数据不就丢失了么
对所以针对这个问题既然已经否决掉了基于外部存储来写入元数据那么这里就可以采取异步持久化日志的机制来通过异步化的方式把元数据的更新日志写入磁盘文件。
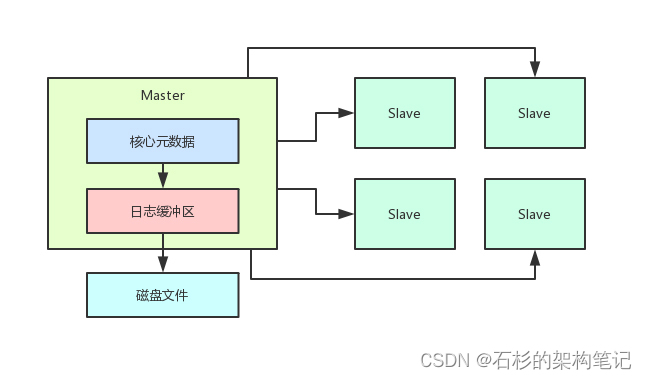
每次Master收到一个请求在内存里更新元数据之后就需要生成一条元数据的更新日志把这个更新日志需要写入到一个内存缓冲里去。
然后等内存缓冲满了之后由一个后台线程把这里的数据刷新到磁盘上去如下图。
肯定会有人说那如果一条更新日志刚写入缓冲区结果Master宕机了此时不是还是会丢失少量数据吗因为还没来得及刷入磁盘。
没错啊这个为了保证高并发请求都是由内存来处理的你必须得用异步持久化磁盘的模式所以必然要容忍极端宕机情况下可能丢失比如几秒钟的数据。
那么如果是正常的Master重启呢
那简单必须先把日志缓冲区清空刷入磁盘然后才能正常重启Master保证数据都在磁盘上不会丢失。
接着重启的时候从磁盘上读取更新日志每一条都依次回访到内存里恢复出来核心元数据即可。
3、检查点机制定时持久化全量数据
但是这里又有一个问题了那个磁盘上的日志文件越来越大因为元数据不断的在更新不断在产生最新的变更日志写入磁盘文件。
那么系统运行一段时间以后每次重启都需要从磁盘读取历史全部日志一条一条回放到内存来恢复核心元数据吗
不可能所以这里一定要配合引入检查点机制。
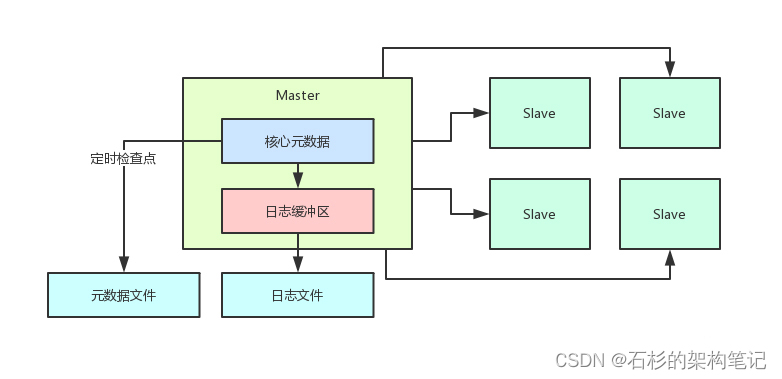
也就是说每隔一段时间就需要开启一个后台线程把内存里的全部核心元数据序列化后写入磁盘上的元数据文件作为这个时间的一个快照文件同时清空掉日志文件这个叫做检查点操作。
下次重启只要把元数据文件读取出来直接反序列化后方入内存然后把上次检查点之后的变更日志从日志文件里读出来回放到内存里就可以恢复出来完整的元数据了。
这种方式可以让Master重启很快因为大部分数据都是在检查点写入的那个元数据文件里。
整个过程如下图所示
4、引入检查点节点
但是这个时候又有一个问题了。
大家可以想一下Master内存里的元数据需要高并发的被人访问和修改同时每隔一段时间还要检查点写入磁盘。
那么在检查点过程中是不是需要把内存数据全部加锁不允许别人修改
在加锁的时候把不会变动的数据写入磁盘文件中但是这个过程是很慢的意味着此时别人高并发的写入操作都需要等待核心元数据的锁。
因为此时别人锁住了你无法加锁去写数据进去这会导致系统在几秒内出现卡顿无法响应请求的问题。
所以此时需要在架构设计里引入一个检查点节点专门负责同步Master的变更日志。
然后在自己内存里维护一份一模一样的核心元数据每隔一段时间由检查点节点来负责将内存数据写入磁盘接着上传发送给Master。
这样做就不需要Master自己执行检查点的时候对自己内存数据进行加锁了如下图。
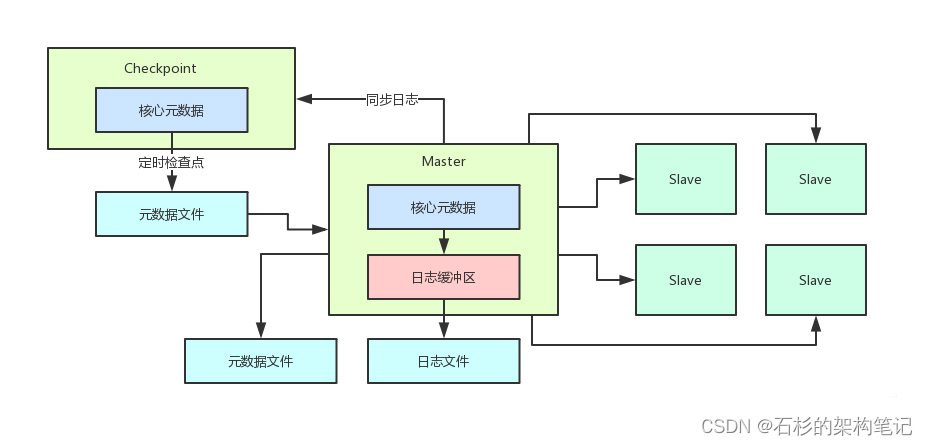
在这样的一个架构下对Master来说他只需要一个后台线程负责接收Checkpoint进程定时传送过来的元数据文件快照然后写入本地磁盘就可以了完全规避掉了对自己内存元数据的锁冲突的问题。
5、总结 & 思考
总结一下这个架构设计其实就是Master基于内存维护元数据这样一台物理机可以支撑每秒10万+的高并发请求。
每次元数据出现更新写一条日志到内存缓冲区然后后台线程去刷新日志到日志文件里去同时需要发送一条日志到Checkpoint节点去。
Checkpoint节点会在自己内存里维护一份一模一样的元数据然后每隔一段时间执行checkpoint检查点写一份元数据文件快照。
接着上传给Master节点后清空掉他的日志文件。然后Master节点每次重启的时候直接读取本地元数据文件快照加上回放上次checkpoint之后的日志即可。
这里可能大家会提几个问题比如说Master节点突然宕机会如何
那很简单直接影响就是他内存缓冲里的那些日志丢了导致少量数据丢失这个在我们的场景下可以容忍。
如果Checkpoint节点宕机怎么办
那不要紧因为他之前上传过元数据文件的快照所以对Master而言最多就是无法同步数据过去。
但是Master重启还是可以读取最近一次的元数据快照然后回放日志即可。
等Checkpoint节点恢复了可以继续接着上一次同步日志然后继续执行checkpoint操作。