

requests库的使用(一篇就够了)_requests库
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
urllib库使用繁琐比如处理网页验证和Cookies时需要编写Opener和Handler来处理。为了更加方便的实现这些操作就有了更为强大的requests库。
request库的安装
requests属于第三方库Python不内置因此需要我们手动安装。
1、相关链接
-
GitHubhttps://github.com/psf/requests
-
PyPIhttps://pypi.org/project/requests/
-
官方文档https://docs.python-requests.org/en/latest/
-
中文文档https://docs.python-requests.org/zh_CN/latest/user/quickstart.html
2、通过pip安装
无论是Windows、Linux还是Mac都可以通过pip这个包管理工具来安装requests。在命令行界面运行如下命令即可完成requests库的安装
pip3 install requests
除了通过pip安装还可以通过wheel或源码安装这里不进行叙述。
3、验证安装
在命令行可通过导入import库来测试requests是否安装成功。
 导入库成功说明requests安装成功。
导入库成功说明requests安装成功。
基本用法
下面案例使用requests库中的get( )方法发送了一个get请求。
#导入requests库
import requests
#发送一个get请求并得到响应
r = requests.get('https://www.baidu.com')
#查看响应对象的类型
print(type(r))
#查看响应状态码
print(r.status_code)
#查看响应内容的类型
print(type(r.text))
#查看响应的内容
print(r.text)
#查看cookies
print(r.cookies)
这里调用了get( )方法实现urlopen( )相同的操作结果返回一个响应对象然后分别输出响应对象类型、状态码、响应体内容的类型、 响应体的内容、Cookies。通过运行结果可以得知响应对象的类型是requests.models.Response响应体内容的类型是strCookies 的类型是RequestCookieJar。如果要发送其他类型的请求直接调用其对应的方法即可
r = requests.post('https://www.baidu.com')
r = requests.put('https://www.baidu.com')
r = requests.delete('https://www.baidu.com')
r = requests.head('https://www.baidu.com')
r = requests.options('https://www.baidu.com')
GET请求
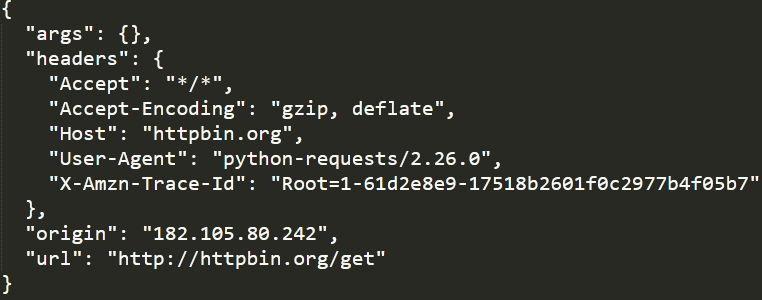
构建一个GET请求请求http://httpbin.org/get该网站会判断如果客户端发起的是GET请求的话它返回相应的信息
import requests
r = requests.get('http://httpbin.org/get')
print(r.text)
1如果要添加请求参数比如添加两个请求参数其中name值是germeyage值是20。虽然可以写成如下形式
r = requests.get('http://httpbin.org/get?name=germey&age=20')
但较好的写法是下面这种写法
import requests
data = {
'name':'germey',
'age':22
}
r = requests.get('http://httpbin.org/get',params=data)
print(r.text)
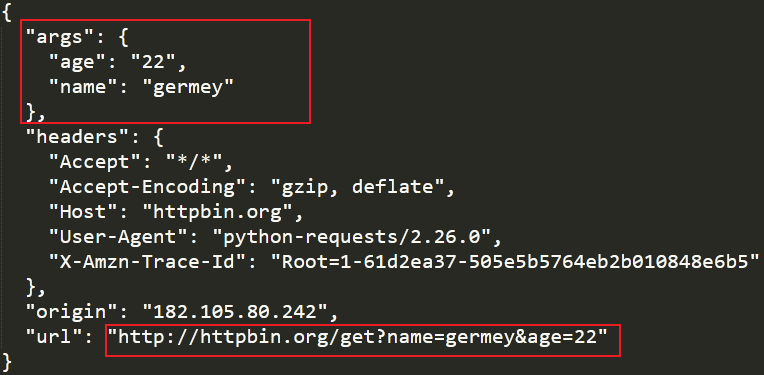
通过运行结果可以看出请求的URL最终被构造成了“http://httpbin.org/get?name=germey&age=20”。
2网页的返回内容的类型是str类型的如果它符合JSON格式则可以使用json( )方法将其转换为字典类型以方便解析。
import requests
r = requests.get('http://httpbin.org/get')
#str类型
print(type(r.text))
#返回响应内容的字典形式
print(r.json())
#dict类型
print(type(r.json()))
但需要注意如果返回的内容不是JSON格式调用json( )方法便会出现错误抛出json.decoder.JSONDecodeError异常。
POST请求
1发送POST请求。
import requests
r = requests.post('http://httpbin.org/post')
print(r.text)
2发送带有请求参数的POST请求。
import requests
data = {
"name":"germey",
"age":"22"
}
r = requests.post('http://httpbin.org/post',data=data)
print(r.text)
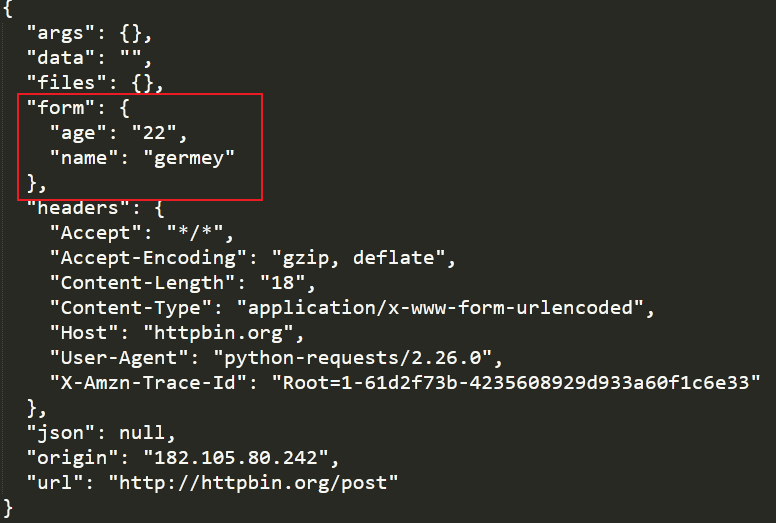
在POST请求方法中form部分就是请求参数。
设置请求头
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'my-test':'Hello'
}
r = requests.get('http://httpbin.org/get',headers=headers)
print(r.text)
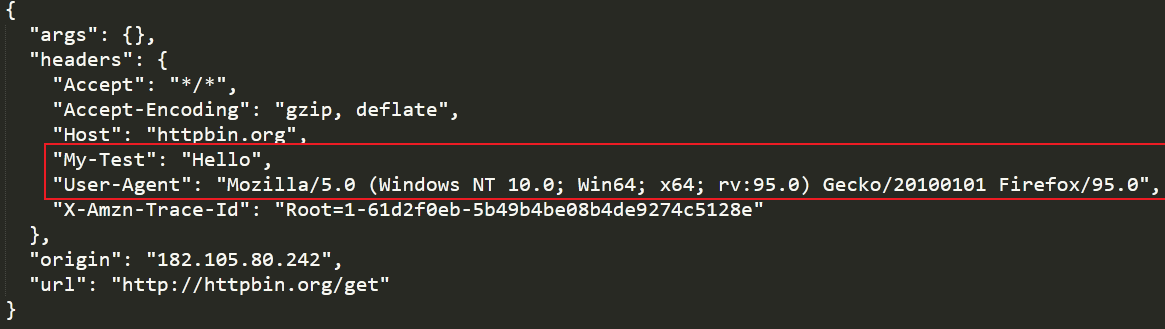
响应
1发送请求后返回一个响应它具有很多属性通过它的属性来获取状态码、响应头、Cookies、响应内容等。如下
import requests
r = requests.get('https://www.baidu.com/')
#响应内容str类型
print(type(r.text),r.text)
#响应内容bytes类型
print(type(r.content),r.content)
#状态码
print(type(r.status_code),r.status_code)
#响应头
print(type(r.headers),r.headers)
#Cookies
print(type(r.cookies),r.cookies)
#URL
print(type(r.url),r.url)
#请求历史
print(type(r.history),r.history)
2状态码常用来判断请求是否成功除了可以使用HTTP提供的状态码requests库中也提供了一个内置的状态码查询对象叫做 requests.codes实际上两者都是等价的。示例如下
import requests
r = requests.get('https://www.baidu.com/')
if not r.status_code==requests.codes.ok:
print('Request Fail')
else:
print('Request Successfully')
requests.codes对象拥有的状态码如下
#信息性状态码
100('continue',),
101('switching_protocols',),
102('processing',),
103('checkpoint',),
122('uri_too_long','request_uri_too_long'),
#成功状态码
200('ok','okay','all_ok','all_okay','all_good','\\o/','√'),
201('created',),
202('accepted',),
203('non_authoritative_info','non_authoritative_information'),
204('no_content',),
205('reset_content','reset'),
206('partial_content','partial'),
207('multi_status','multiple_status','multi_stati','multiple_stati'),
208('already_reported',),
226('im_used',),
#重定向状态码
300('multiple_choices',),
301('moved_permanently','moved','\\o-'),
302('found',),
303('see_other','other'),
304('not_modified',),
305('user_proxy',),
306('switch_proxy',),
307('temporary_redirect','temporary_moved','temporary'),
308('permanent_redirect',),
#客户端请求错误
400('bad_request','bad'),
401('unauthorized',),
402('payment_required','payment'),
403('forbiddent',),
404('not_found','-o-'),
405('method_not_allowed','not_allowed'),
406('not_acceptable',),
407('proxy_authentication_required','proxy_auth','proxy_authentication'),
408('request_timeout','timeout'),
409('conflict',),
410('gone',),
411('length_required',),
412('precondition_failed','precondition'),
413('request_entity_too_large',),
414('request_uri_too_large',),
415('unsupported_media_type','unsupported_media','media_type'),
416('request_range_not_satisfiable','requested_range','range_not_satisfiable'),
417('expectation_failed',),
418('im_a_teapot','teapot','i_am_a_teapot'),
421('misdirected_request',),
422('unprocessable_entity','unprocessable'),
423('locked'),
424('failed_dependency','dependency'),
425('unordered_collection','unordered'),
426('upgrade_required','upgrade'),
428('precondition_required','precondition'),
429('too_many_requests','too_many'),
431('header_fields_too_large','fields_too_large'),
444('no_response','none'),
449('retry_with','retry'),
450('blocked_by_windows_parental_controls','parental_controls'),
451('unavailable_for_legal_reasons','legal_reasons'),
499('client_closed_request',),
#服务端错误状态码
500('internal_server_error','server_error','/o\\','×')
501('not_implemented',),
502('bad_gateway',),
503('service_unavailable','unavailable'),
504('gateway_timeout',),
505('http_version_not_supported','http_version'),
506('variant_also_negotiates',),
507('insufficient_storage',),
509('bandwidth_limit_exceeded','bandwith'),
510('not_extended',),
511('network_authentication_required','network_auth','network_authentication')
爬取二进制数据
图片、音频、视频这些文件本质上都是由二进制码组成的所以想要爬取它们就要拿到它们的二进制码。以爬取百度的站点图标选项卡上的小图标为例
import requests
#向资源URL发送一个GET请求
r = requests.get('https://www.baidu.com/favicon.ico')
with open('favicon.ico','wb') as f:
f.write(r.content)
使用open( )方法它的第一个参数是要保存文件名可带路径第二个参数表示以二进制的形式写入数据。运行结束之后可以在当前目录下发现保存的名为favicon.ico的图标。同样的音频和视频也可以用这种方法获取。
文件上传
requests可以模拟提交一些数据。假如某网站需要上传文件我们也可以实现。
import requests
#以二进制方式读取当前目录下的favicon.ico文件并将其赋给file
files = {'file':open('favicon.ico','rb')}
#进行上传
r = requests.post('http://httpbin.org/post',files=files)
print(r.text)
处理Cookies
使用urllib处理Cookies比较复杂而使用requests处理Cookies非常简单。
1获取Cookies。
import requests
r = requests.get('https://www.baidu.com')
#打印Cookies对象
print(r.cookies)
#遍历Cookies
for key,value in r.cookies.items():
print(key+'='+value)
通过响应对象调用cookies属性即可获得Cookies它是一个RequestCookiesJar类型的对象然后用items( )方法将其转换为元组组成 的列表遍历输出每一个Cookies的名称和值。
2使用Cookies来维持登录状态。以知乎为例首先登录知乎进入一个登录之后才可以访问的页面在浏览器开发者工具中将Headers 中的Cookies复制下来有时候这样直接复制的Cookies中包含省略号会导致程序出错此时可以在Console项下输document.cookie 即可得到完整的Cookie在程序中使用它将其设置到Headers里面然后发送请求。
import requests
headers = {
'Cookie':'_zap=616ef976-1fdb-4b8c-a3cb-9327ff629ff1; _xsrf=0CCNkbCLtTAlz5BfwhMHBHJWW791ZkK6; d_c0=\"AKBQTnFIRhSPTpoYIf6mUxSic2UjzSp4BYM=|1641093994\"; __snaker__id=mMv5F3gmBHIC9jJg; gdxidpyhxdE=E%2BNK7sMAt0%2F3aZ5Ke%2FSRfBRK7B1QBmCtaOwrqJm%2F1ONP3VPItkrXCcMiAX3%2FIsSxUwudQPyuDGO%2BlHGPvNqGqO9bX1%2B58o7wmf%2FZewh8xSPg%2FH3T2HoWsrs7ZhsSGND0C0la%2BXkLIIG5XXV85PxV5g99d%5CMph%2BbkX1JQBGhDnL3N0zRf%3A1641094897088; _9755xjdesxxd_=32; YD00517437729195%3AWM_NI=rMeMx2d5Yt3mg0yHPvuPGTjPnGtjL%2Bn%2FPSBnVn%2FHFAVZnIEABUIPITBdsHmMX1iCHfKauO4qhW%2Bi5bTy12Cg91vrxMPgOHtnaAylN8zk7MFpoTr%2FTeKVo3%2FKSSM6T5cNSGE%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea40f8e7a4b2cf69b3b48fb7c54b979b8fbaf17e93909b91fb338ebaaeadec2af0fea7c3b92ab293abaefb3aa8eb9795b267a5f0b7a9d37eb79089b5e95cae99bc8bcf21aef1a0b4c16696b2e1a9c54b9686a2aac84b828b87b1cc6082bcbda9f0479cefa7a4cb6e89bfbbb0b77bac89e58ab86a98a7ffd3c26dfbefba93fb4794b981a9f766a39fb78dcd34bab5f9aec57cad8cbed0d76f898aa1d4ae41918d83d7d73fa1929da8c837e2a3; YD00517437729195%3AWM_TID=Kji43bLtZbRAAAVABFMu4upmK4C%2BEGQH; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1641268679|1641267986; tst=r; NOT_UNREGISTER_WAITING=1; SESSIONID=lbWS7Y8pmp5qM1DErkXJCahgQwwyl79eT8XAOC6qC7A; JOID=V1wXAUwzD9BQH284PTQMxsZMqrkrXmuHBio3Bk1cfuMhV1x9fiHKBjYcaD44XxiWm2kKD5TjJvk-7iTeM3d6aYA=; osd=VVoQAk0xCddTHm0-OjcNxMBLqbgpWGyEBygxAU5dfOUmVF1_eCbJBzQabz05XR6RmGgICZPgJ_s46SffMXF9aoE=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1640500881,1641093994,1641267987; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1641268678',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'Host':'www.zhihu.com'
}
r = requests.get('https://www.zhihu.com/people/xing-fu-shi-fen-dou-chu-lai-de-65-18',headers=headers)
print(r.text)
运行之后结果中包含了登录后的内容说明获取登录状态成功。
3也可以通过cookies参数来设置不过这样就需要构造RequestCookieJar对象而且需要分割以下cookies相对繁琐但效果是一 样。
import requests
cookies ='_zap=616ef976-1fdb-4b8c-a3cb-9327ff629ff1; _xsrf=0CCNkbCLtTAlz5BfwhMHBHJWW791ZkK6; d_c0=\"AKBQTnFIRhSPTpoYIf6mUxSic2UjzSp4BYM=|1641093994\"; __snaker__id=mMv5F3gmBHIC9jJg; gdxidpyhxdE=E%2BNK7sMAt0%2F3aZ5Ke%2FSRfBRK7B1QBmCtaOwrqJm%2F1ONP3VPItkrXCcMiAX3%2FIsSxUwudQPyuDGO%2BlHGPvNqGqO9bX1%2B58o7wmf%2FZewh8xSPg%2FH3T2HoWsrs7ZhsSGND0C0la%2BXkLIIG5XXV85PxV5g99d%5CMph%2BbkX1JQBGhDnL3N0zRf%3A1641094897088; _9755xjdesxxd_=32; YD00517437729195%3AWM_NI=rMeMx2d5Yt3mg0yHPvuPGTjPnGtjL%2Bn%2FPSBnVn%2FHFAVZnIEABUIPITBdsHmMX1iCHfKauO4qhW%2Bi5bTy12Cg91vrxMPgOHtnaAylN8zk7MFpoTr%2FTeKVo3%2FKSSM6T5cNSGE%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee8bea40f8e7a4b2cf69b3b48fb7c54b979b8fbaf17e93909b91fb338ebaaeadec2af0fea7c3b92ab293abaefb3aa8eb9795b267a5f0b7a9d37eb79089b5e95cae99bc8bcf21aef1a0b4c16696b2e1a9c54b9686a2aac84b828b87b1cc6082bcbda9f0479cefa7a4cb6e89bfbbb0b77bac89e58ab86a98a7ffd3c26dfbefba93fb4794b981a9f766a39fb78dcd34bab5f9aec57cad8cbed0d76f898aa1d4ae41918d83d7d73fa1929da8c837e2a3; YD00517437729195%3AWM_TID=Kji43bLtZbRAAAVABFMu4upmK4C%2BEGQH; KLBRSID=9d75f80756f65c61b0a50d80b4ca9b13|1641268679|1641267986; tst=r; NOT_UNREGISTER_WAITING=1; SESSIONID=lbWS7Y8pmp5qM1DErkXJCahgQwwyl79eT8XAOC6qC7A; JOID=V1wXAUwzD9BQH284PTQMxsZMqrkrXmuHBio3Bk1cfuMhV1x9fiHKBjYcaD44XxiWm2kKD5TjJvk-7iTeM3d6aYA=; osd=VVoQAk0xCddTHm0-OjcNxMBLqbgpWGyEBygxAU5dfOUmVF1_eCbJBzQabz05XR6RmGgICZPgJ_s46SffMXF9aoE=; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1640500881,1641093994,1641267987; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1641268678'
jar = requests.cookies.RequestsCookieJar()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'Host':'www.zhihu.com'
}
for cookie in cookies.split(';'):
key,value = cookie.split('=',1)
jar.set(key,value)
r = requests.get('https://www.zhihu.com/people/xing-fu-shi-fen-dou-chu-lai-de-65-18',headers=headers)
print(r.text)
会话维持
通过调用get( )或post( )等方法可以做到模拟网页的请求但是这实际上是相当于不同的会话也就是说相当于你用了两个浏览器打开不同的页面。如果第一个请求利用post( )方法登录了网站第二次想获取登录成功后的自己的个人信息又使用了一次get( )方法取请求个人信息实际上这相当于打开了两个浏览器所以是不能成功的获取到个人信息的。为此需要会话维持你可以在两次请求时设置一样的Cookies但这样很繁琐而通过Session类可以很轻松地维持一个会话。
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
首先通过requests打开一个会话然后通过该会话发送了一个get请求该请求用于向cookies中设置参数number参数值为123456789接着又使用该发起了一个get请求用于获取Cookies然后打印获取的内容。
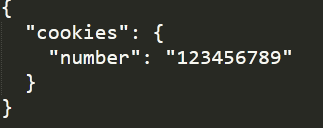
成功获取。
SSL证书验证
requests还提供了证书验证功能当发送HTTP请求的时候它会检查SSL证书我们可以使用verify参数控制是否检查SSL证书。
1请求一个HTTPS网站时如果该网站的证书没有被CA机构信任程序将会出错提示SSL证书验证错误。对此只需要将verify参数 设置为False即可。如下
import requests
resposne = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
也可以指定一个本地证书用作客户端证书它可以是单个文件包含密钥和证书或一个包含两个文件路径的元组。
import requests
#本地需要有crt和key文件key必须是解密状态加密状态的key是不支持的并指定它们的路径
response = requests.get('https://www.12306.cn',cert('/path/server.crt','/path/key'))
print(response.status_code)
2在请求SSL证书不被CA机构认可的HTTPS网站时虽然设置了verify参数为False但程序运行可能会产生警告警告中建议我们给它 指定证书可以通过设置忽略警告的方式来屏蔽这个警告
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
或者通过捕获警告到日志的方式忽略警告
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
代理设置
对于某些网站在测试的时候请求几次能正常获取内容。但是一旦开始大规模、频繁地爬取网站可能会弹出验证码或者跳转到登录验证页面更有甚者可能会直接封禁客户端的IP导致一定时间内无法访问。为了防止这种情况我们需要使用代理来解决这个问题这就需要用到proxies参数。
1设置代理
import requests
proxies = {
#该代理服务器在免费代理网站上得到的这样的网站有很多
'http': 'http://161.35.4.201:80',
'https': 'https://161.35.4.201:80'
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
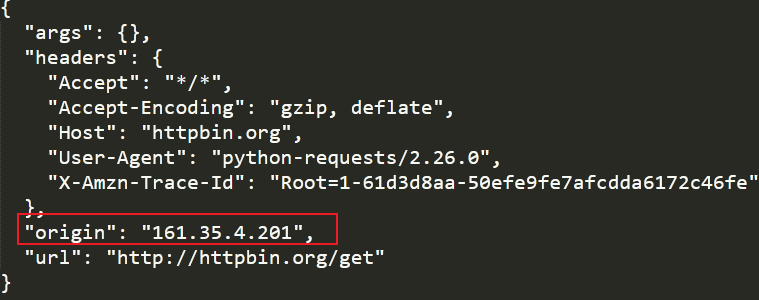
可以发现我们使用的是代理服务器进行访问的。
2如果代理需要使用HTTP Basic Auth可以使用类似http://user:password@host:port这样的语法来设置代理。
import requests
proxies = {
"http":"http://user:password@161.35.4.201:80"
}
r = requests.get("https://www.taobao.com",proxies=proxies)
print(r.text)
3除了基本的HTTP代理外requests还支持SOCKS协议的代理。首先需要安装socks这个库
pip3 install 'requests[socks]'
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
request.get('https://www.taobao.com',proxies=proxies)
然后就可以使用SOCKS协议代理了
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
requests.get('https://www.taobao.com',proxies=proxies)
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时我们可能会等待特别久的时间才可能收到响应甚至到最后收不到响应而报错。为了应对这种情况应设置一个超时时间这个时间是计算机发出请求到服务器返回响应的时间如果请求超过了这个超时时间还没有得到响应就抛出错误。这就需要使用timeout参数实现单位为秒。
1指定请求总的超时时间
import requests
#向淘宝发出请求如果1秒内没有得到响应则抛出错误
r = requests.get('https://www.taobao.com',timeout=1)
print(r.status_code)
2分别指定超时时间。实际上请求分为两个阶段连接connect和读取read。如果给timeout参数指定一个整数值则超时时 间是这两个阶段的总和如果要分别指定就可以传入一个元组连接超时时间和读取超时时间
import requests
#向淘宝发出请求如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应则抛出错误
r = requests.get('https://www.taobao.com',timeout=(5,30))
print(r.status_code)
3如果想永久等待可以直接timeout设置为None或者不设置timeout参数因为它的默认值就是None。
import requests
#向淘宝发出请求如果连接阶段5秒内没有得到响应或读取阶段30秒内没有得到响应则抛出错误
r = requests.get('https://www.taobao.com',timeout=None))
print(r.status_code)
身份验证
访问某网站时可能会遇到如下的验证页面
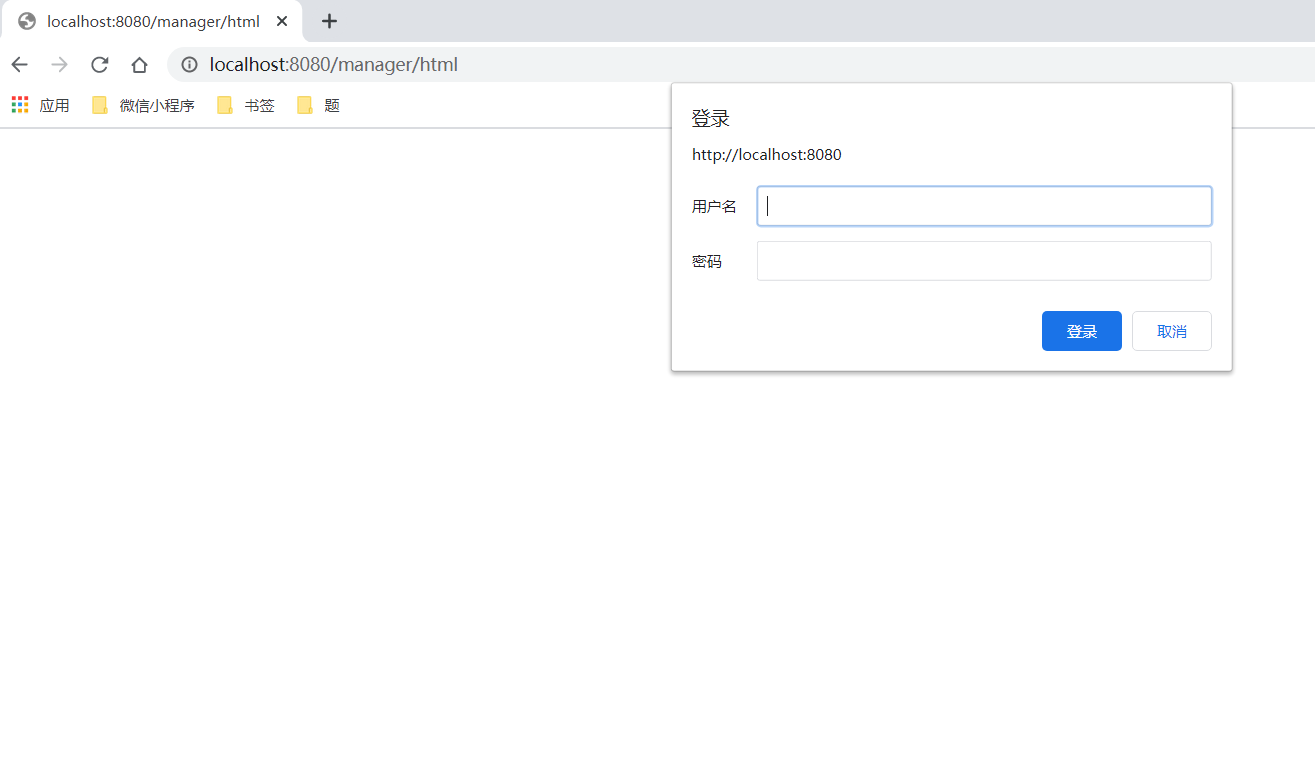
1此时可以使用requests自带的身份验证功能通过HTTPBasicAuth类实现。
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:8080/manager/html',auth=HTTPBasicAuth('admin','123456'))
print(r.status_code)
如果用户名和密码正确的话返回200状态码如果不正确则返回401状态码。也可以不使用HTTPBasicAuth类而是直接传入一个 元组它会默认使用HTTPBasicAuth这个类来验证。
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:8080/manager/html',auth=('admin','123456'))
print(r.status_code)
2requests还提供了其他验证方式如OAuth验证不过需要安装oauth包安装命令如下
pip3 install requests_oauthlib
使用OAuth验证的方法如下
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1("YOUR_APP_KEY","YOUR_APP_SECRET","USER_OAUTH_TOKEN","USER_OAUTH_TOKEN_SECRET")
requests.get(url,auth=auth)
Prepared Request
在学习urllib库时发送请求如果需要设置请求头需要通过一个Request对象来表示。在requests库中存在一个与之类似的类称为Prepared Request。
from requests import Request,Session
url = 'http://httpbin.org/post'
data = {
'name':'germey'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}
s = Session()
req = Request('POST',url,data=data,headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
这里引入了Request然后用url、data和headers参数构造了一个Request对象这时需要再调用Session的prepare_request( )方法将其转换为一个Prepared Request对象然后调用send( )方法发送。这样做的好处时可以利用Request将请求当作独立的对象来看待这样在进行队列调度时会非常方便后面会用它来构造一个Request队列。