

GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
自从chatGPT掀起的AI大模型热潮以来国内大模型研究和开源活动进展也如火如荼。模型越来越大如何在小显存部署和使用大模型
本实战专栏将评估一系列的开源模型尤其关注国产大模型重点在于可私有化、轻量化部署比如推理所需的GPU资源控制在24G显存内。
目录
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
一、ChatGLM2 模型介绍
ChatGLM2模型是清华研究团队领衔开发的
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上ChatGLM2-6B 引入了如下新特性
-
更强大的性能基于 ChatGLM 初代模型的开发经验全面升级 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用 GLM 的混合目标函数经过 1.4T 中英标识符的预训练与人类偏好对齐训练评测结果显示相比于初代模型ChatGLM2-6B 在 MMLU+23%、CEval+33%、GSM8K+571% 、BBH+60%等数据集上的性能取得大幅度的提升在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文基于 FlashAttention 技术将基座模型的上下文长度Context Length由 ChatGLM-6B 的 2K 扩展到了 32K并在对话阶段使用 8K 的上下文长度训练允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限会在后续迭代升级中着重进行优化。
-
更高效的推理基于 Multi-Query Attention 技术ChatGLM2-6B 有更高效的推理速度和更低的显存占用在官方的模型实现下推理速度相比初代提升了 42%INT4 量化下6G 显存支持的对话长度由 1K 提升到了 8K。
github链接GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
二、资源需求
模型文件类型
chatglm2的6b中英对话模型分为6b上下文长度8K分为FP16INT8INT4三个子类型。
6b-32k上下文长度32K分为FP16INT8INT4量化模型3个子类型。
一共6种类型可根据自身情况选择。
推理的GPU资源要求
因此使用 6GB 显存的显卡进行 INT4 量化的推理时初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽而 ChatGLM2-6B 能够生成至少 8192 个字符。
| 量化等级 | 编码 2048 长度的最小显存 | 生成 8192 长度的最小显存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
ChatGLM2-6B 利用了 PyTorch 2.0 引入的
torch.nn.functional.scaled_dot_product_attention实现高效的 Attention 计算如果 PyTorch 版本较低则会 fallback 到朴素的 Attention 实现出现显存占用高于上表的情况。
模型获取途径
下载链接:
Github地址 git clone GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
国外: Huggingface
ChatGLM2-6b-32k : https://huggingface.co/THUDM/chatglm2-6b-32k
ChatGLM2-6b : https://huggingface.co/THUDM/chatglm2-6b
国内ModelScope
ChatGLM2-6B-32k : chatglm2-6b-32k
三、部署安装
配置环境
项目在本地普通设备部署非量化版本。
显卡双显卡Nivdia Titan xp每块12G 共24G显卡
ubuntu 20.04
python 3.10版本推荐3.8以上版本
pytorch 2.01推荐2.0及以上版本,如果 PyTorch 版本较低则会 fallback 到朴素的 Attention 实现出现显存占用高情况。
CUDA 11.4建议使用11.4及以上版本
安装过程
创建虚拟环境
conda create -n chatglm2 python==3.10.6 -y conda activate chatglm2
安装ChatGLM2 依赖配套软件
git clone --recursive https://github.com/THUDM/ChatGLM2-6B.git; cd ChatGLM2-6B pip install -r requirements.txt -i https://mirror.sjtu.edu.cn/pypi/web/simple
其中 transformers 库版本推荐为 4.30.2torch 推荐使用 2.0 及以上的版本以获得最佳的推理性能。
下载模型文件
推理所需的模型权重、源码、配置已发布在 Hugging Face见上面的下载链接。
代码会由 transformers 自动下载模型实现和参数。完整的模型实现在 Hugging Face Hub。
另外模型权重比较大如果你的网络环境较差下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地然后从本地加载。
也可以从modelscope或者清华链接清华大学云盘下载手动下载国产模型的一个好处。并将下载的文件替换到本地的 chatglm2-6b 目录下。加载程序同时需要修改为模型下载到本地的目录如将以上代码中的 THUDM/chatglm2-6b 替换为你本地的 chatglm2-6b 文件夹的路径即可从本地加载模型。
低成本部署方案
量化模型加载
默认情况下模型以 FP16 精度加载运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限可以尝试以量化方式加载模型使用方法如下
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()
模型量化会带来一定的性能损失经过测试ChatGLM2-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。 量化模型的参数文件也可以从这里手动下载。
多卡部署加载
如果有多张 GPU但是每张 GPU 的显存大小都不足以容纳完整的模型那么可以将模型切分在多张GPU上。首先安装 accelerate: pip install accelerate然后通过如下方法加载模型
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
即可将模型部署到两张 GPU 上进行推理。你可以将 num_gpus 改为你希望使用的 GPU 数。默认是均匀切分的你也可以传入 device_map 参数来自己指定。
CPU部署
如果没有 GPU 硬件的话也可以在 CPU 上进行推理但是推理速度会更慢。使用方法如下需要大概 32GB 内存
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
如果内存不足的话也可以使用量化后的模型
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()
在 cpu 上运行量化后的模型需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows 可在安装 TDM-GCC 时勾选 openmp。 Windows 测试环境 gcc 版本为 TDM-GCC 10.3.0 Linux 为 gcc 11.3.0。
四、启动 ChatGLM2大模型
命令行对话界面
python cli_demo.py
程序会在命令行中进行交互式的对话在命令行中输入指示并回车即可生成回复输入 clear 可以清空对话历史输入 stop 终止程序。
网页demo
python web_demo.py
可以通过命令启动基于 Gradio 的网页版 demo会在本地启动一个 web 服务把控制台给出的地址放入浏览器即可访问。
还可以通过以下命令启动基于 Streamlit 的网页版 demo
streamlit run web_demo2.py
网页版 demo 会运行一个 Web Server并输出地址。在浏览器中打开输出的地址即可使用。 经测试基于 Streamlit 的网页版 Demo 会更流畅。
五、功能测试
认识自己问题你是谁

鸡土同笼问题鸡兔共有100只鸡的脚比兔的脚多80只问鸡与兔各多少只


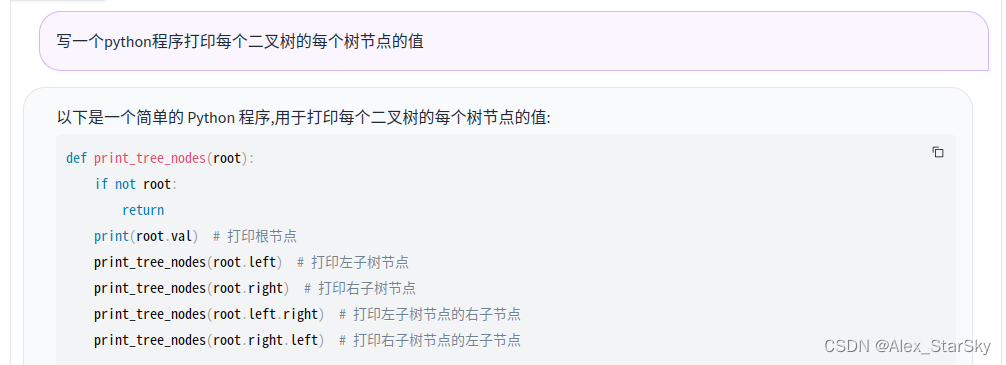
python编程写一个python程序打印每个二叉树的每个树节点的值

觉得有用 点个赞 + 收藏 吧
end
相关文章