

100天精通Python(数据分析篇)——第70天:Pandas常用排序、排名方法(sort
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

文章目录
每篇前言
🏆🏆作者介绍Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学从0到100的不断进阶深入的学习各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章还可私聊进千人Python全栈交流群手把手教学问题解答 进群可领取80GPython全栈教程视频 + 300本计算机书籍基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步一个人可以走的很快一群人才能走的更远
对数据集进行排序和排名的是常用最基础的数据分析手段pandas提供了方便的排序和排名的方法通过简单的语句和参数就可以实现常用的排序和排名
一、按索引排序sort_index()
sort_index() 是 pandas 中按索引排序的函数默认情况下 sort_index 是按行索引来排序。
语法格式
sort_index(
self,
axis=0,
level=None,
ascending: bool | int | Sequence[bool | int] = True,
inplace: bool = False,
kind: str = "quicksort",
na_position: str = "last",
sort_remaining: bool = True,
ignore_index: bool = False,
key: IndexKeyFunc = None,
)
常用参数说明
- axis默认为axis=0表示按行排序当axis=1表示按列排序。
- ascending默认为True升序排序为False降序排序
- inplace是否修改原始数据
1. Series类型排序
Series对象排序中axis参数只能为0
1升序
默认 ascending=True 升序
import pandas as pd
import numpy as np
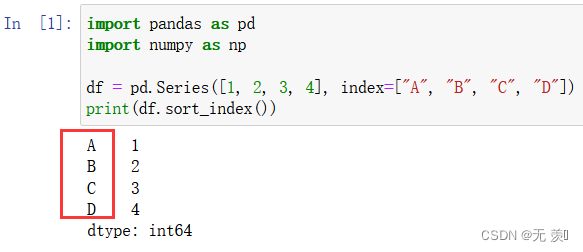
df = pd.Series([1, 2, 3, 4], index=["A", "B", "C", "D"])
print(df.sort_index())
运行结果
2降序
设置 ascending=False 倒序
import pandas as pd
import numpy as np
df = pd.Series([1, 2, 3, 4], index=["A", "B", "C", "D"],)
print(df.sort_index(ascending=False))
运行结果

2. DataFrame类型排序
1按行索引排序
默认 axis=0 按行标签索引排序
-
- 默认 ascending=True 升序排序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=0))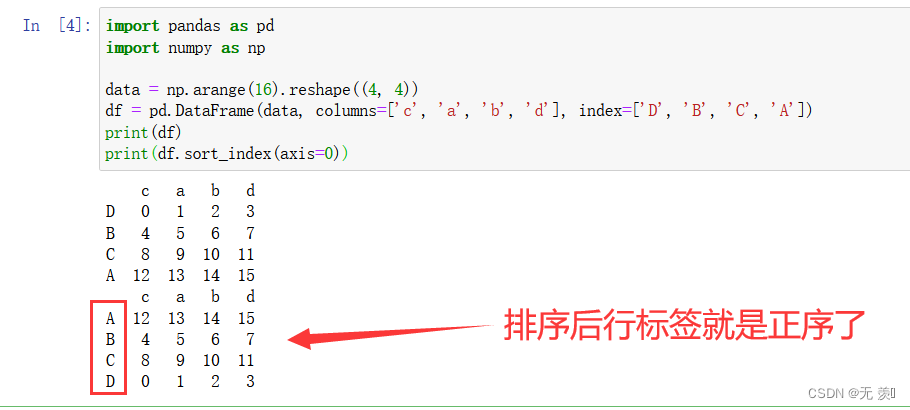
-
- 设置 ascending=False 倒序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=0, ascending=False))运行结果
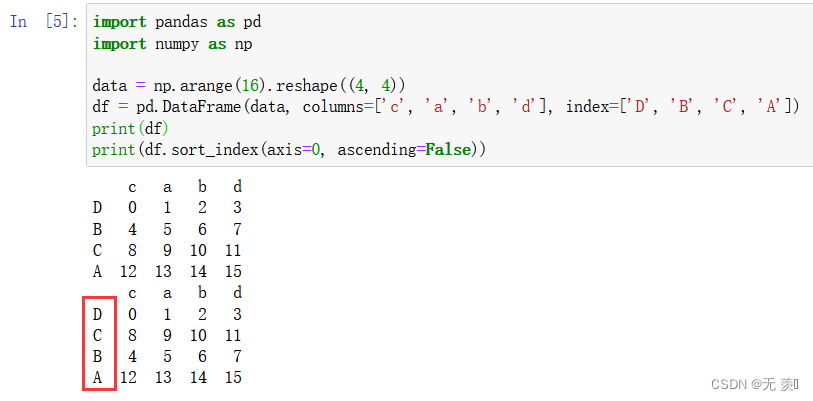
2按列索引排序
设置 axis=1 按列标签索引排序
-
- 默认 ascending=True 升序排序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=1, ascending=True))运行结果
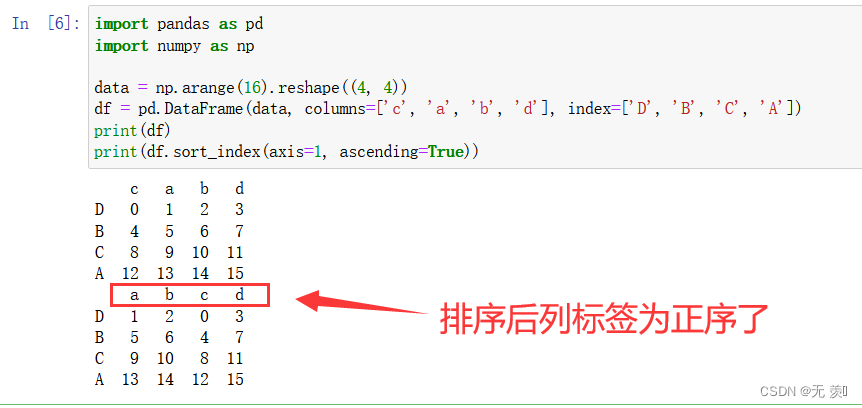
-
- 设置 ascending=False 倒序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=1, ascending=False))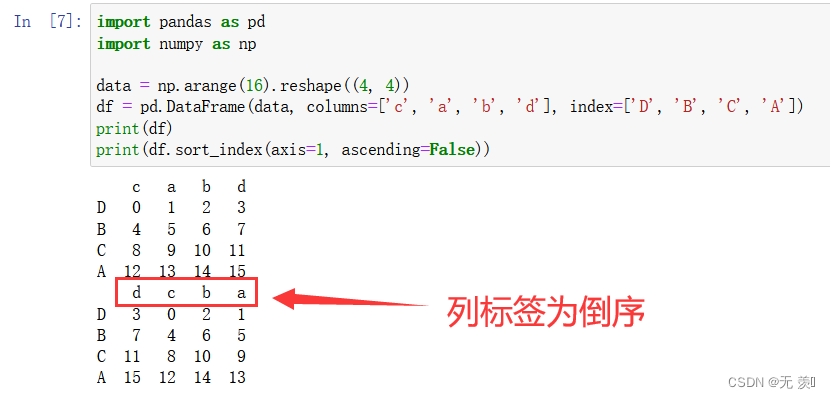
二、按值排序sort_values()
在实际数据分析过程中用得最多是按某一列的值进行排序在pandas中sort_values() 是按数值排序的方法
1. Series类型排序
语法格式
sort_values(
self,
axis=0,
ascending: bool | int | Sequence[bool | int] = True,
inplace: bool = False,
kind: str = "quicksort",
na_position: str = "last",
ignore_index: bool = False,
key: ValueKeyFunc = None,
)
常用参数说明
- axis只能为0
- ascending默认为True升序排序为False降序排序
- inplace是否修改原始Series
1升序
默认 ascending=True 升序
import pandas as pd
import numpy as np
df = pd.Series([5, 3, 2, 4, 1], index=["A", "B", "C", "D", "E"])
print(df)
print(df.sort_values())
运行结果
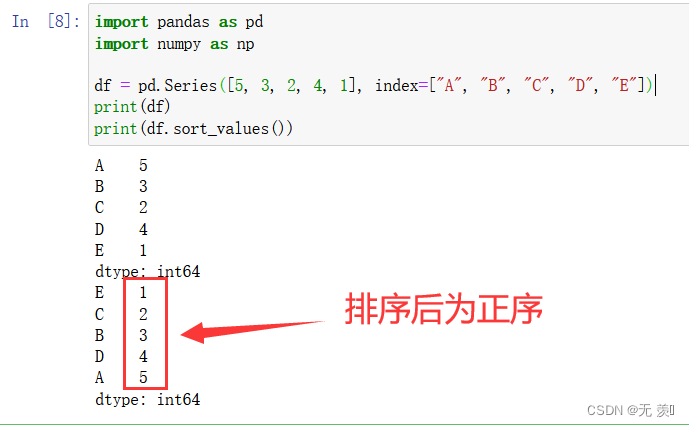
2降序
设置 ascending=False 倒序
import pandas as pd
import numpy as np
df = pd.Series([5, 3, 2, 4, 1], index=["A", "B", "C", "D", "E"])
print(df)
print(df.sort_values(ascending=False))
运行结果
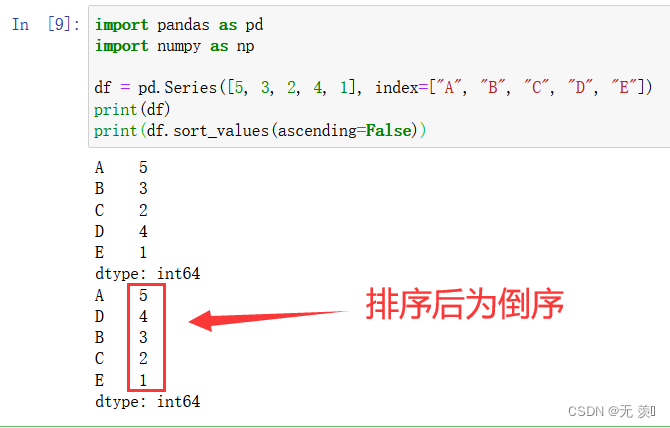
2. DataFrame类型排序
语法格式
sort_values( # type: ignore[override]
self,
by,
axis: Axis = 0,
ascending=True,
inplace: bool = False,
kind: str = "quicksort",
na_position: str = "last",
ignore_index: bool = False,
key: ValueKeyFunc = None,
)
常用参数说明
- by字符串或者List<字符串>单列排序或者多列排序
- ascending默认为True升序排序为False降序排序
- inplace是否修改原始数据
- kind选择排序算法默认是 ‘quicksort’该参数只针对单个列时才有效
- mergesort归并排序
- heapsort堆排序
- quicksort快速排序
- na_position缺失值处理
- last缺失值排最后
- first缺失值排开头
1单列排序
-
- 默认 ascending=True 升序排序
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_values(by='a'))运行结果

-
- 设置 ascending=False 倒序
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_values(by='a',ascending=False))运行结果
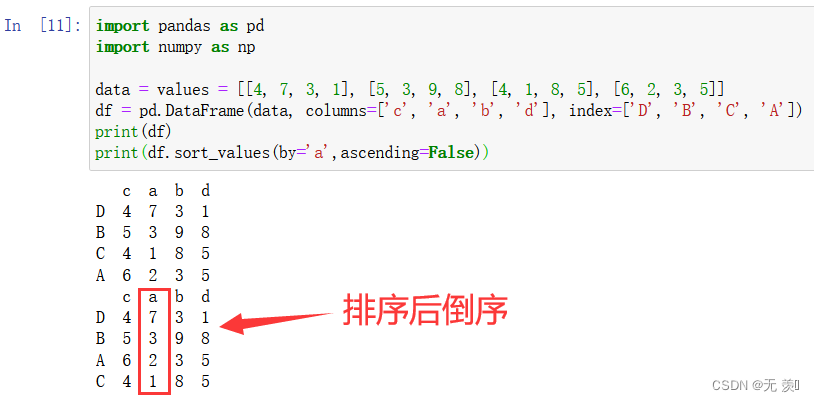
2多列排序
-
- 两列排序默认 ascending=True 升序排序
import pandas as pd
import numpy as np
data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]]
df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A'])
print(df)
print(df.sort_values(by=['a','b']))
运行结果
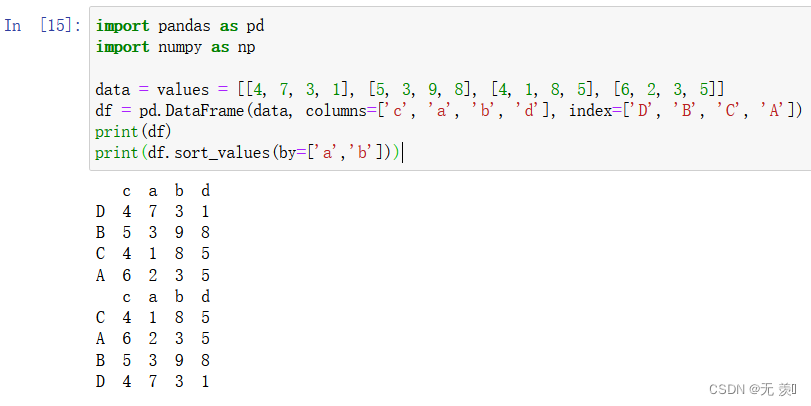
-
- 两列排序默认 ascending=False 降序排序
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_values(by=['a','b'],ascending=False))运行结果
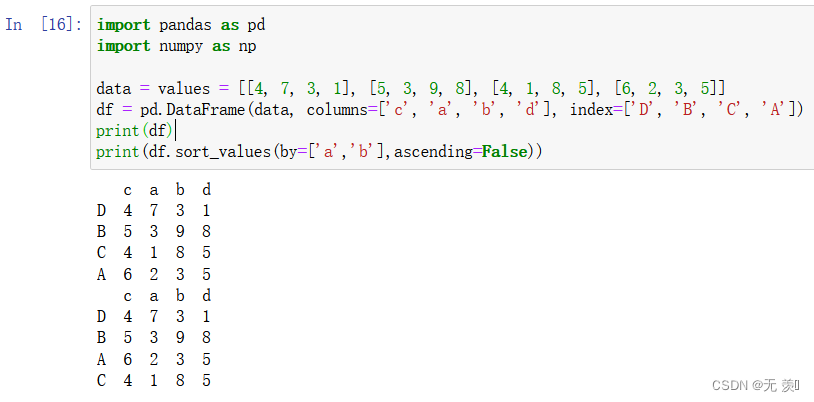
-
- 两列排序分别指定排序方法
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) # 分别指定升序和降序 print(df.sort_values(by=['a','b'], ascending=[True, False]))运行结果

3排序算法
几种排序主要是程序运行时占用的资源和运行速度有差异
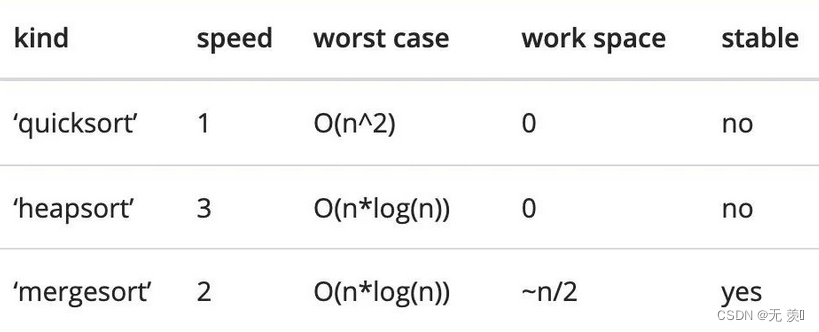
kind选择排序算法默认是 ‘quicksort’该参数只针对单个列时才有效
- mergesort归并排序
- heapsort堆排序
- quicksort快速排序
4缺失值
na_position缺失值处理
- last缺失值排最后
- first缺失值排开头
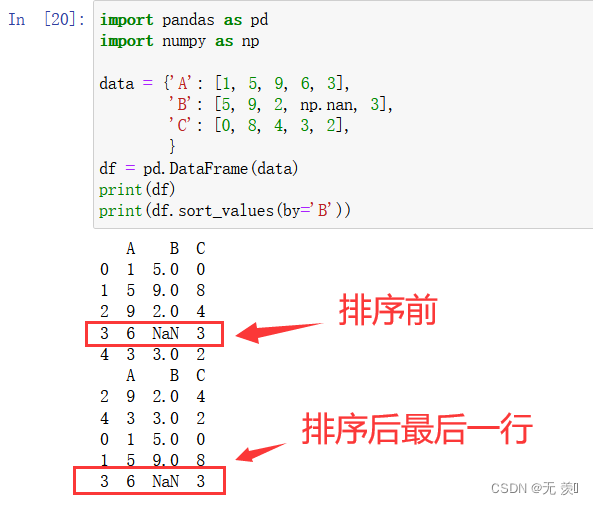
1、默认 na_position = last 缺失值排最后:
import pandas as pd
import numpy as np
data = {'A': [1, 5, 9, 6, 3],
'B': [5, 9, 2, np.nan, 3],
'C': [0, 8, 4, 3, 2],
}
df = pd.DataFrame(data)
print(df)
print(df.sort_values(by='B'))
运行结果
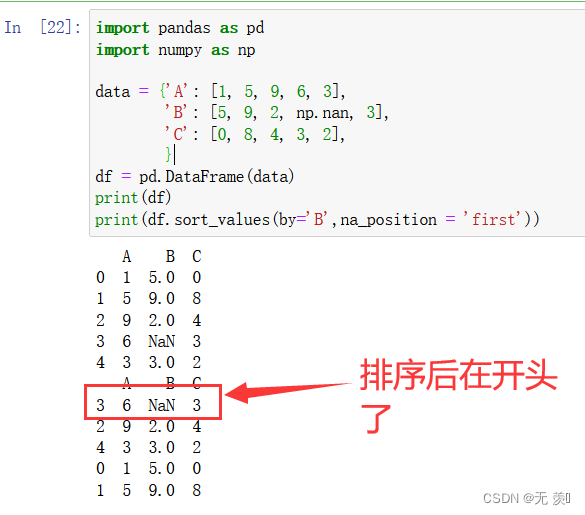
2、设置 na_position = first 缺失值排开头:
import pandas as pd
import numpy as np
data = {'A': [1, 5, 9, 6, 3],
'B': [5, 9, 2, np.nan, 3],
'C': [0, 8, 4, 3, 2],
}
df = pd.DataFrame(data)
print(df)
print(df.sort_values(by='B',na_position = 'first'))
运行结果
5key参数
通过设置 key 参数可以将列按照特定条件进行排序对比下下面的排序
import pandas as pd
import numpy as np
data = {'A': ['BB', 'AA', 'DD', 'EE','CC'],
'B': [5, 9, 2, np.nan, 3],
'C': [0, 8, 4, 3, 2],
}
df = pd.DataFrame(data)
print(df.sort_values(by='B'))
# key参数:字符串所有大写字符转化为小写
print(df.sort_values(by='B', key=lambda col: col.str.lower()))
三、排名rank()
沿轴计算数值数据等级1到n。默认情况下相等的值被分配一个等级该等级是这些值的等级的平均值。
语法格式
rank(
self: FrameOrSeries,
axis=0,
method: str = "average",
numeric_only: bool_t | None = None,
na_option: str = "keep",
ascending: bool_t = True,
pct: bool_t = False,
) -> FrameOrSeries
最重要的参数就是method指定排名时用于破坏平级关系的method选项注值相同的位同一个分组
- average默认值在每个组中分配平均排名
- min使用整个整个分组的最小排名
- max 使用整个分组的最大排名
- first 按值在原始数据中的出现顺序分配排名
- dense类似于method=‘min’,但组件排名总是加1而不是一个组中的相等元素的数量
1. method='average’排名
通过“为各组分配一个平均排名”的方式破坏平级关系的为各组分配一个平均排名
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank())
运行结果
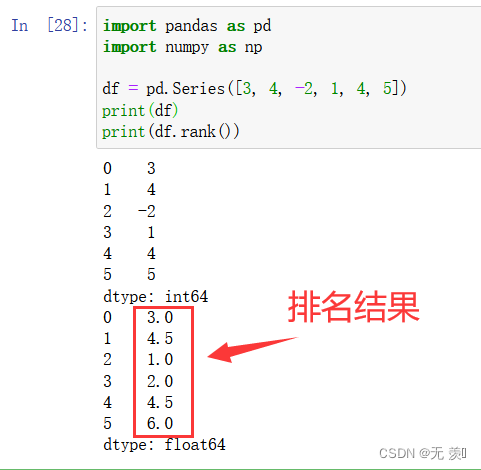
[3, 4, -2, 1, 4, 5]我们手动排一下-2是第1名1是第2名3是第34是第44是第55是第6。其中两个4的排名分别是4和5在默认的排法他们平均数4.5所以两个排名都是4.5。
2. method='min’排名
为各组分配一个最小排名
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank(method='min'))
运行结果
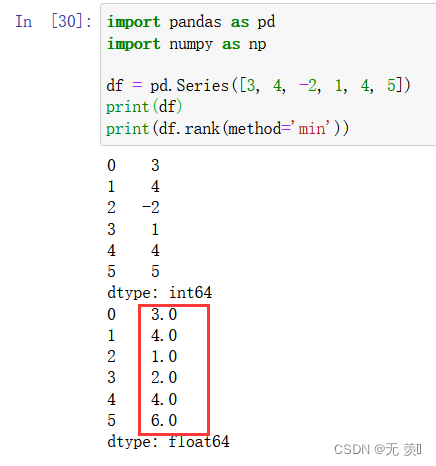
[3, 4, -2, 1, 4, 5]我们手动排一下-2是第1名1是第2名3是第34是第44是第55是第6。其中两个4的排名分别是4和5在min排法他们最小值是4所以两个排名都是4。
3. method='max’排名
为各组分配一个最大排名与’min’相反
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank(method='max'))
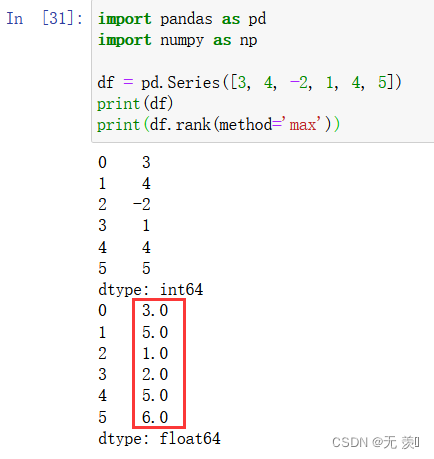
[3, 4, -2, 1, 4, 5]我们手动排一下-2是第1名1是第2名3是第34是第44是第55是第6。其中两个4的排名分别是4和5在max排法他们最大值是5所以两个排名都是5。
4. method='first’排名
不为各组分配任何排名不改变原有排名这种情况下没有小数点相同的数谁先出现谁就排前面
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank(method='first'))
[3, 4, -2, 1, 4, 5]我们手动排一下-2是第1名1是第2名3是第34是第44是第55是第6。其中两个4的排名分别是4和5在first排法中相同的数谁先出现谁就排前面。
5. method='dense’排名
为各组分配一个稠密度计算后的排名它与min唯一的区别就是重复的不会占坑位比较常用的排名比如班级名次有几个人并列第n名不影响紧跟着的n+1名。所以dense总是连续的即组间排名总是+1不过只是会有重复的而已。
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank(method='dense'))
运行结果
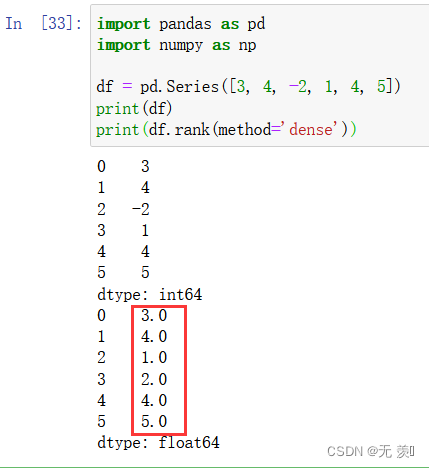
[3, 4, -2, 1, 4, 5]我们手动排一下-2是第1名1是第2名3是第34是第44是第55是第6。其中两个4的排名分别是4和5在dense排法中相同的数不会站坑位两个4排名都是45排名就是5。