

基于情感分析+聚类分析+LDA主题分析对服装产品类的消费者评论分析(文末送书)-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

♂️ 个人主页@艾派森的个人主页
✍作者简介Python学习者
希望大家多多支持我们一起进步
如果文章对你有帮助的话
欢迎评论 点赞 收藏 加关注+
目录
1.项目背景
随着互联网和电子商务的迅速发展越来越多的消费者选择在线购买服装产品。这种趋势带来了海量的消费者评论这些评论包含了消费者对产品的看法、感受和使用经验是宝贵的信息资源。对这些评论进行情感分析、聚类分析和LDA主题分析有助于企业更全面地了解消费者需求优化产品设计提高服务质量从而实现更高的市场竞争力。
然而传统的分析方法往往只能提供单一的、浅层次的信息难以深入挖掘评论中的多维度信息。因此本研究采用情感分析、聚类分析和LDA主题分析相结合的方法对服装产品类的消费者评论进行综合分析。通过这种方式可以更准确地把握消费者的情感倾向、群体特征和关注热点为企业决策提供更全面、更深入的依据。
具体而言本研究的研究目标包括
- 通过情感分析了解消费者对服装产品的整体情感倾向以及不同产品、不同品牌之间的情感差异。
- 通过聚类分析发现消费者群体的特征和行为模式为企业制定个性化营销策略提供参考。
- 通过LDA主题分析挖掘评论中的关键主题和关注点为企业优化产品设计和改进服务质量提供方向。
综上所述本研究旨在通过对服装产品类的消费者评论进行综合分析为企业提供更全面、更深入的市场洞察和决策支持。同时本研究的方法和结果也可以为其他领域的消费者评论分析提供借鉴和参考。
2.数据集介绍
本数据集来源于kaggle原始数据集共有49338条9个特征变量各变量含义如下
Title评论标题
Review评论内容
Cons_rating评价评级
Cloth_class服饰类型
Materials布料类型
Construction布料结构
Color颜色
Finishing含义未知暂且忽略
Durability耐用性
3.技术工具
Python版本:3.9
代码编辑器jupyter notebook
4.实验过程
4.1加载数据
首先导入本次实验使用到的第三方库并加载原始数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings("ignore")
import math
rc = {
"axes.facecolor": "#E6FFE6",
"figure.facecolor": "#E6FFE6",
"axes.edgecolor": "#000000",
"grid.color": "#EBEBE7",
"font.family": "serif",
"axes.labelcolor": "#000000",
"xtick.color": "#000000",
"ytick.color": "#000000",
"grid.alpha": 0.4
}
sns.set(rc=rc)
from colorama import Style, Fore
red = Style.BRIGHT + Fore.RED
blu = Style.BRIGHT + Fore.BLUE
mgt = Style.BRIGHT + Fore.MAGENTA
gld = Style.BRIGHT + Fore.YELLOW
res = Style.RESET_ALL
df= pd.read_table("data_amazon.xlsx - Sheet1.csv", delimiter=",")
df.head()
查看数据大小

查看数据基本信息
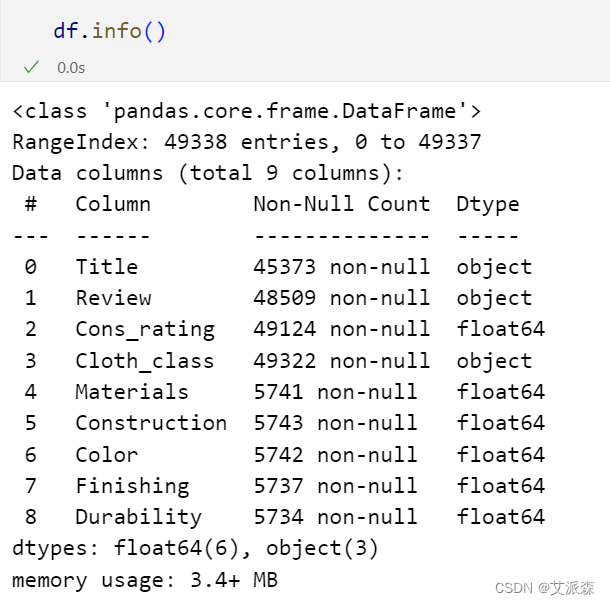
可以看出最后五列变量存在大量缺失值后续需要进行处理
4.2数据预处理
首先查看原始数据集中的缺失值情况
import missingno as msno
# 缺失值分析
fig, ax = plt.subplots(2,2,figsize=(12,7))
axs = np.ravel(ax)
msno.matrix(df, fontsize=9, color=(0.25,0,0.5),ax=axs[0]);
msno.bar(df, fontsize=8, color=(0.25,0,0.5), ax=axs[1]);
msno.heatmap(df,fontsize=8,ax=axs[2]);
msno.dendrogram(df,fontsize=8,ax=axs[3], orientation='top')
fig.suptitle('Missing Values Analysis', y=1.01, fontsize=15)
# plt.savefig('missing_values_analysis.png') # 保存图片
plt.show()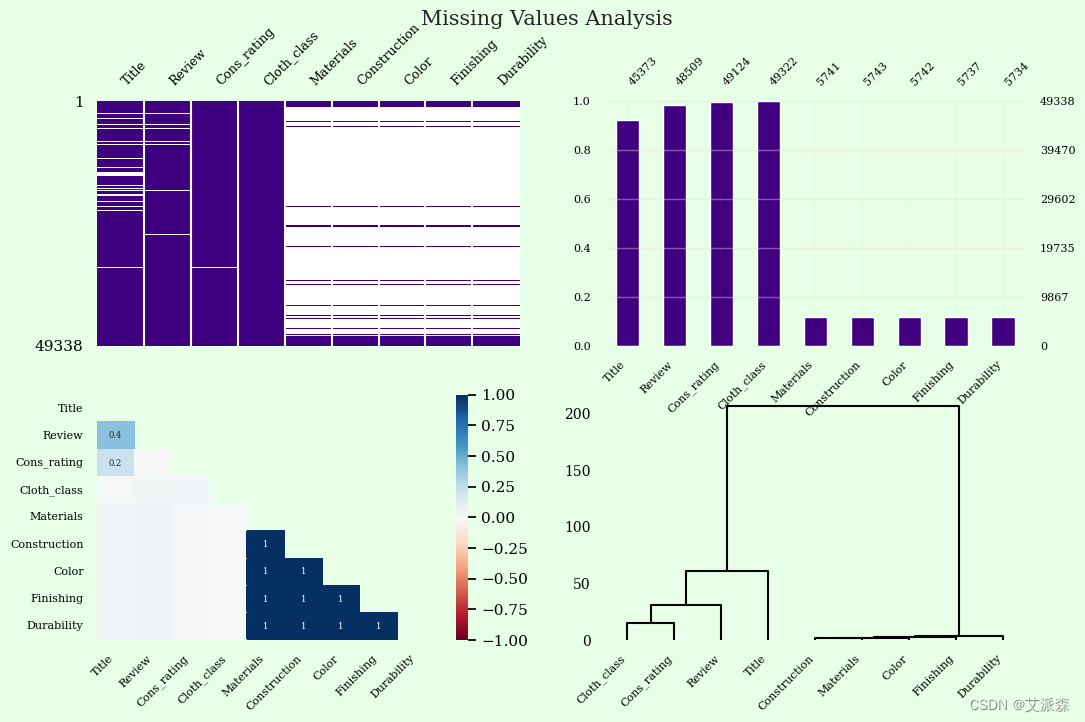
填充缺失值并删除重复值
df.fillna(0, inplace=True) # 使用0填充缺失值
df = df.drop_duplicates() # 剔除重复值
df.info()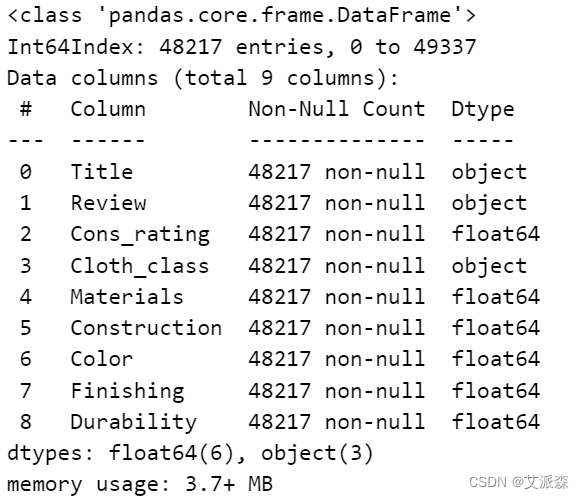
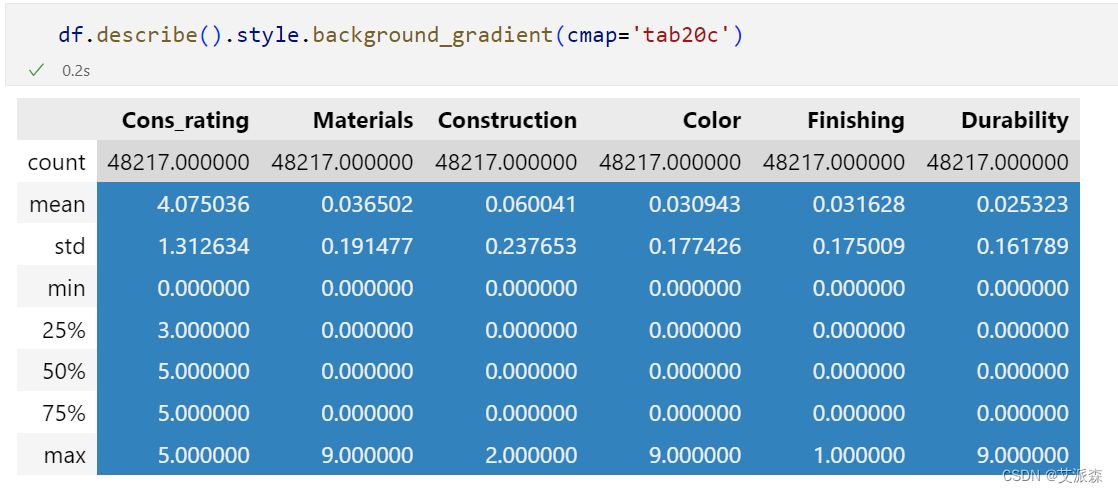
描述性统计提供了数据集的主要特征的摘要。这包括均值、中位数、标准差、最小值、最大值等度量。
4.3数据可视化
# 计算每个布料类别的出现频率
cloth_class_counts = df['Cloth_class'].value_counts()
plt.figure(figsize=(8, 8))
plt.pie(cloth_class_counts, labels=cloth_class_counts.index, autopct='%1.1f%%', startangle=140, colors=sns.color_palette('pastel'))
plt.title('Distribution of Cloth Classes', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.axis('equal')
plt.savefig('Distribution of Cloth Classes.png')
plt.show()这个饼状图将提供数据集中不同服装类别分布的可视化表示。每个切片代表一个不同的类切片的大小表示它在数据集中的比例。
# 评级的分布
plt.figure(figsize=(12, 6))
sns.histplot(df['Cons_rating'], kde=True, color='skyblue')
plt.title('Distribution of Cons Ratings', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.xlabel('Cons Rating', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.ylabel('Frequency', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.savefig('Distribution of Con Ratings.png')
plt.show()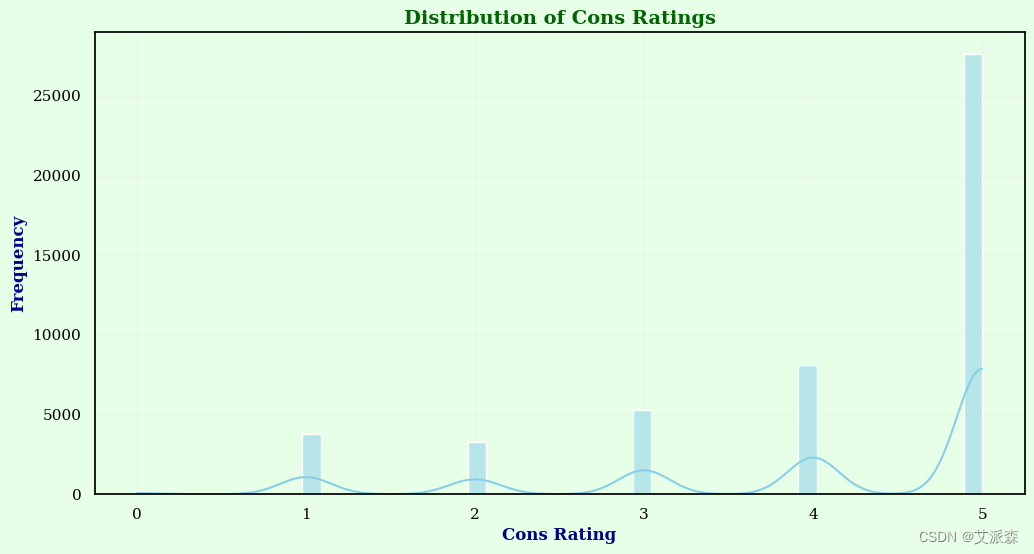
这个直方图可视化了“con_rating”的分布。它显示了每个评级在数据集中出现的频率。它有助于理解关于产品缺点的意见分布。
# 优点与缺点评分
plt.figure(figsize=(12, 6))
sns.boxplot(x='Construction', y='Cons_rating', data=df, palette='pastel')
plt.title('Construction vs. Cons Ratings', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.xlabel('Construction', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.ylabel('Cons Rating', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.savefig('Construction vs. Cons Ratings.png')
plt.show()
这个箱形图有助于可视化“Construction”和“con_rating”之间的关系。它显示了不同质量等级的缺点等级的分布。这有助于理解质量和评级之间是否存在相关性。
# 颜色分布
plt.figure(figsize=(12, 6))
sns.countplot(x='Color', data=df, palette='pastel')
plt.title('Distribution of Colors', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.xlabel('Color', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.ylabel('Frequency', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.xticks(rotation=45)
plt.savefig('Distribution of Colors.png')
plt.show()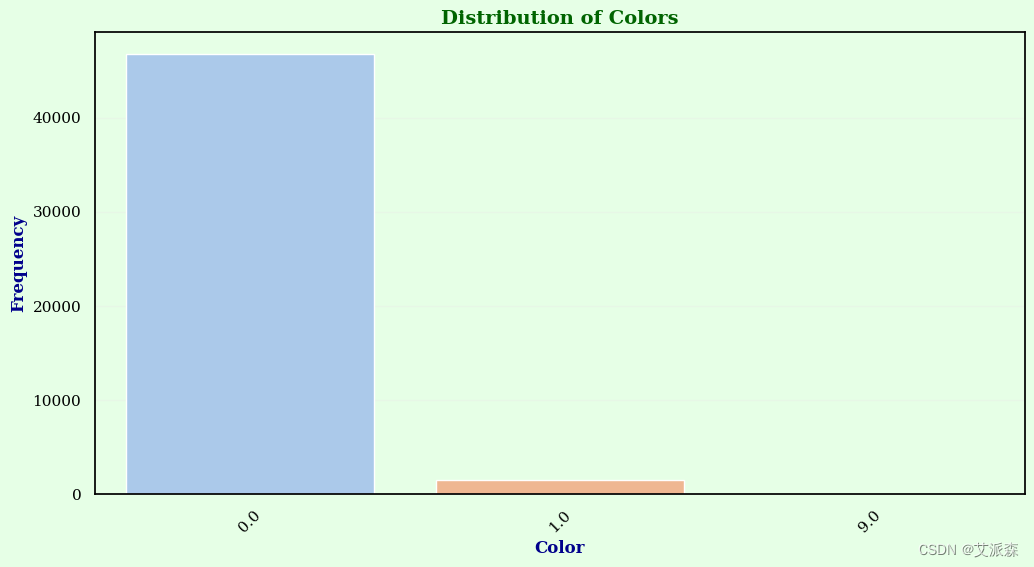
这个柱状图显示了不同颜色出现的频率。它提供了数据集中颜色分布的概览。
sns.pairplot(df[['Cons_rating', 'Materials', 'Construction', 'Finishing', 'Durability']], diag_kind='kde')
plt.suptitle('Pairplot of Numerical Variables', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.savefig('Pairplot of Numerical Variables.png')
plt.show()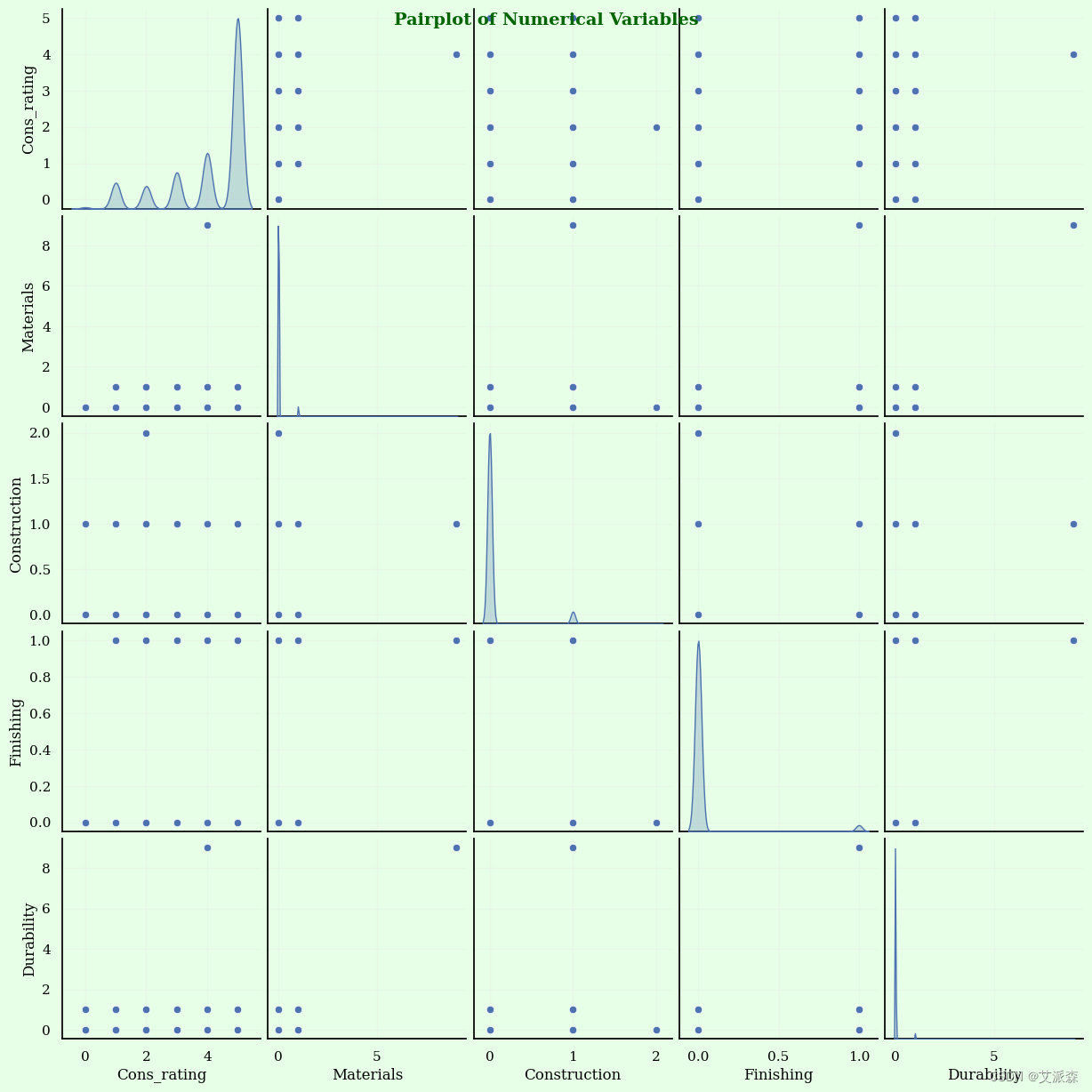
这个成对图显示了数值变量相互之间的散点图以及每个变量的直方图。它对于可视化数字属性之间的关系和分布非常有用。
df['Review'] = df['Review'].astype(str)
from wordcloud import WordCloud
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(' '.join(df['Review']))
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title('Word Cloud of Reviews', fontsize = 14, fontweight = 'bold', color = 'darkblue')
plt.axis('off')
# plt.savefig('Word Cloud of Reviews.png') 保存图片
plt.show()
这个词云直观地表示了评论中出现频率最高的单词。每个单词的大小与其频率成正比。它给出了在评论中表达的主要主题或观点的快速概述。
4.4情感分析
情感分析涉及使用自然语言处理技术来确定一段文本中表达的情感或情感。在本例中它被应用于“Review”列以评估评论通常是积极的、消极的还是中立的。
我们使用TextBlob库它为常见的NLP任务(包括情感分析)提供了一个简单的API。对于每个评论我们计算极性这是一种从-1(消极)到1(积极)的情绪度量。
from textblob import TextBlob
df['Sentiment'] = df['Review'].apply(lambda x: TextBlob(x).sentiment.polarity)
plt.figure(figsize=(12, 4))
sns.histplot(df['Sentiment'], kde=True, color='skyblue')
plt.title('Distribution of Sentiment Scores', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.xlabel('Sentiment Score', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.ylabel('Frequency', fontsize = 12, fontweight = 'bold', color = 'darkblue')
# plt.savefig('Distribution of Sentiment Scores.png')
plt.show()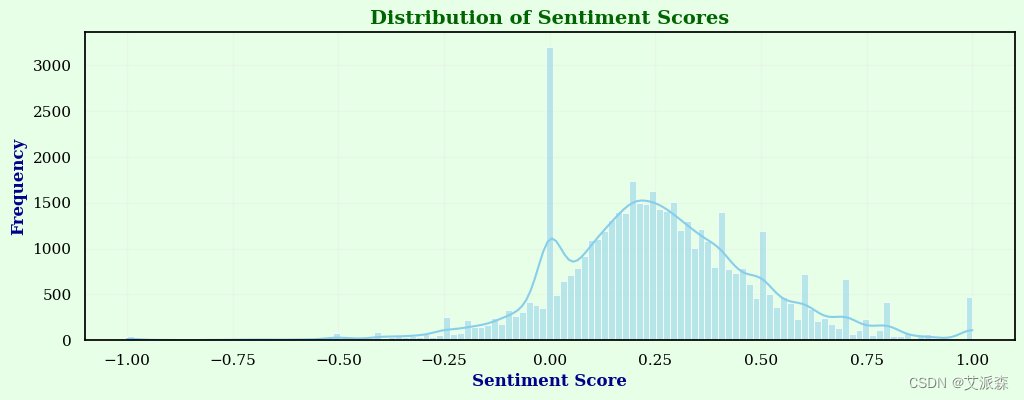
可以看出评论的情绪分值集中在0.25附近说明还是正面评论占多数。
4.5相关性分析
这里使用热力图的形式展示变量之间的相关系数的关系
# 删除非数字列
df_numeric = df.drop(columns=['Title', 'Review', 'Cloth_class'])
correlation_matrix = df_numeric.corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title("Correlation Heatmap", fontsize = 14, fontweight = 'bold', color = 'darkblue')
plt.savefig('Correlation Heatmap.png')
plt.show()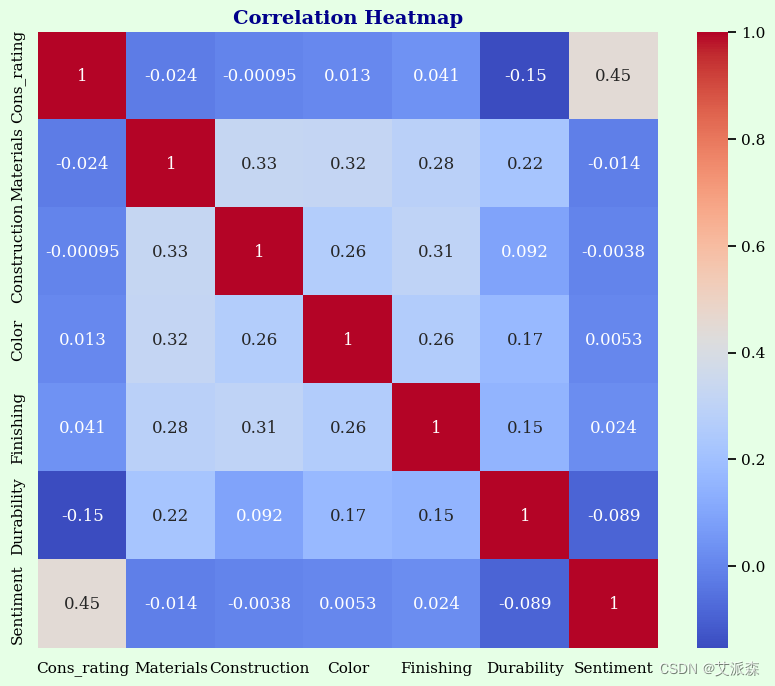
4.6特征重要性分析
特征重要性分析确定哪些变量对预测模型中的目标变量影响最大。它有助于理解哪些属性在做出预测时最具影响力。 我们使用随机森林回归器来估计基于训练模型的特征重要性。
X = df.drop(columns=['Cons_rating', 'Title', 'Review', 'Cloth_class'])
y = df['Cons_rating']
model = RandomForestRegressor()
model.fit(X, y)
feature_importance = pd.Series(model.feature_importances_, index=X.columns).sort_values(ascending=False)
print("\nFeature Importance:")
print(feature_importance)
4.7聚类分析
聚类是一种用于将相似数据点分组在一起的技术。它有助于发现数据中的模式和结构。我们使用K-Means聚类算法基于“Materials”、“Construction”等属性对项目进行聚类。将结果集群分配给每个项目。
from sklearn.cluster import KMeans
X_cluster = df[['Materials', 'Construction', 'Color', 'Finishing', 'Durability']]
kmeans = KMeans(n_clusters=3, random_state=0).fit(X_cluster)
df['Cluster'] = kmeans.labels_
plt.figure(figsize=(12, 4))
plt.scatter(X_cluster['Materials'], X_cluster['Construction'], c=df['Cluster'], cmap='viridis')
plt.xlabel('Materials', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.ylabel('Construction', fontsize = 12, fontweight = 'bold', color = 'darkblue')
plt.title('Clustering of Materials vs. Construction', fontsize = 14, fontweight = 'bold', color = 'darkgreen')
plt.colorbar(label='Cluster')
plt.savefig('Clustering of Materials vs. Construction.png')
plt.show()
cluster_counts = df['Cluster'].value_counts()
print("Cluster Counts:")
print(cluster_counts)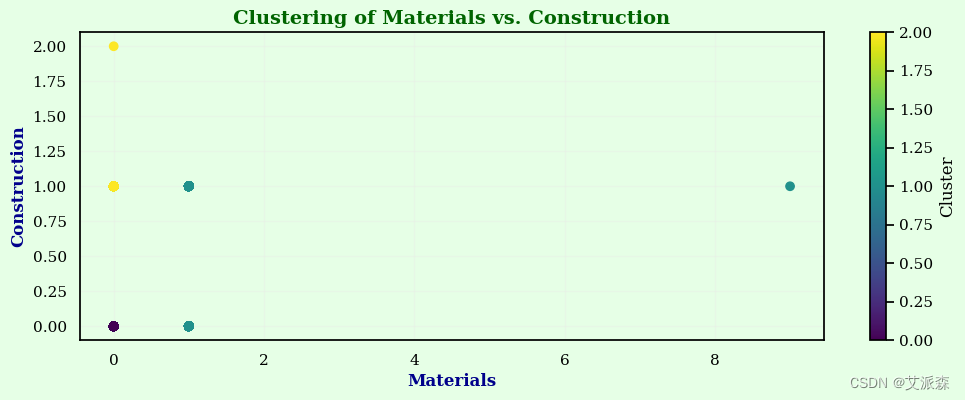
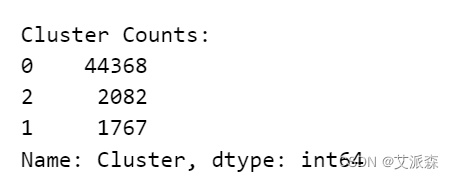
从聚类的数量以及前面的情感分析结果来看0类应该是正面评论1是负面评论2是中性评论。
4.8LDA主题分析
主题建模是一种用于发现文本文档集合中的主题或主题的技术。这有助于理解评论中讨论的主要主题。我们使用一种流行的主题建模算法潜狄利克雷分配(Latent Dirichlet Allocation, LDA)来识别评论中的主题。
from sklearn.decomposition import LatentDirichletAllocation
vectorizer = CountVectorizer(max_features=1000, stop_words='english')
X_nlp = vectorizer.fit_transform(df['Review'])
lda = LatentDirichletAllocation(n_components=5, random_state=0)
topics = lda.fit_transform(X_nlp)
# 找出每个主题的关键词
feature_names = vectorizer.get_feature_names()
top_words = []
for topic_idx, topic in enumerate(lda.components_):
top_words_idx = topic.argsort()[:-10-1:-1]
top_words.append([feature_names[i] for i in top_words_idx])
# 打印出每个主题的关键词
for i, words in enumerate(top_words):
print(f"Topic {i+1}:")
print(", ".join(words))
5.总结
本实验采用情感分析、聚类分析和LDA主题分析相结合的方法对服装产品类的消费者评论进行了综合分析。通过实验我们得到了丰富而有价值的结果以下是对实验的总结
- 情感分析有效地揭示了消费者对服装产品的情感倾向。通过评论的情感标签我们观察到大部分消费者的情感是积极的展现了对产品的满意和喜爱。同时我们也发现了一些负面情感的评论这为企业提供了改进产品的机会和方向。
- 聚类分析帮助我们发现了消费者群体的不同特征和行为模式。通过聚类我们将消费者划分为不同的群体每个群体都有其独特的购买偏好和消费习惯。这为企业制定个性化营销策略提供了重要的参考可以针对不同群体采取不同的推广措施。
- LDA主题分析挖掘了评论中的关键主题和关注点。通过主题分析我们发现消费者关注的主要包括产品质量、舒适度、款式设计、价格等方面。这为企业优化产品设计和改进服务质量提供了明确的方向可以针对消费者的关注点进行产品改进和提升。
综上所述本实验通过对服装产品类的消费者评论进行综合分析提供了更全面、更深入的市场洞察和决策支持。企业可以根据实验结果调整产品策略改进服务质量提升市场竞争力。同时本实验的方法和结果也对其他领域的消费者评论分析具有一定的借鉴意义和参考价值。在未来可以进一步拓展分析方法结合更多维度的数据以更准确地洞察消费者需求和市场趋势。
文末推荐与福利
《巧用chatgpt系列》3选1免费包邮送出3本

内容简介
随着人工智能技术的迅速发展越来越多的工具和应用程序被应用于职场中以提高我们的工作效率。其中ChatGPT作为一种先进的自然语言处理技术正在逐渐引起人们的关注。
巧用ChatGPT系列书籍《巧用chatGPT快速搞定数据分析》《 巧用ChatGPT快速提高职场晋升力》《巧用ChatGPT玩转新媒体运营》由北京大学出版社出版介绍ChatGPT在职场中的实际应用以及它如何帮助我们提高工作效率、解决工作中遇到的问题以及提升职业技能。随着人工智能技术的不断发展和应用的深入相信ChatGPT将会成为我们工作生活中的得力助手。
- 抽奖方式评论区随机抽取3位小伙伴免费送出
- 参与方式关注博主、点赞、收藏、评论区评论“人生苦短拒绝内卷”切记要点赞+收藏否则抽奖无效每个人最多评论三次
- 活动截止时间2023-11-11 20:00:00
《巧用chatGPT快速搞定数据分析》
京东购买链接https://item.jd.com/13810483.html
《 巧用ChatGPT快速提高职场晋升力》
京东购买链接https://item.jd.com/13832713.html
《巧用ChatGPT玩转新媒体运营》
名单公布时间2023-11-11 21:00:00
免费资料获取更多粉丝福利关注下方公众号获取
