

前度开发面试题-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
面试题总结
vue页面跳转会经过两个钩子函数beforeEach、afterEach
组见守卫
beforeRouteEnter前置组见守卫
*beforeRouteUpdate更新之前
watch和computed区别
数据没有改变则 computed 不会重新计算。若没改变计算属性会立即返回之前缓存的计算结果。
不支持异步当 computed 内有异步操作时无效无法监听数据的变化的值。
watch 支持异步
当一个属性发生变化时需要执行对应的操作一对多时一般用 watch。
不支持缓存数据变或者触发重新渲染时直接会触发相应的操作。
值类型(基本类型)字符串String、数字(Number)、布尔(Boolean)、对空Null、未定义Undefined、Symbol。
引用数据类型对象(Object)、数组(Array)、函数(Function)。
防抖和节流
-
节流: n 秒内只运行一次若在 n 秒内重复触发只有一次生效
-
防抖: n 秒后在执行该事件若在 n 秒内被重复触发则重新计时
继承方式
-
原型链继承
-
构造函数继承借助 call
-
组合继承
-
原型式继承
-
寄生式继承
-
寄生组合式继承
宏任务和微任务
| 宏任务macrotask | 微任务microtask | |
|---|---|---|
| 谁发起的 | 宿主Node、浏览器 | JS引擎 |
| 具体事件 | 1. script (可以理解为外层同步代码) 2. setTimeout/setInterval 3. UI rendering/UI事件 4. postMessageMessageChannel 5. setImmediateI/ONode.js | 1. 2. MutaionObserver 3. Object.observe已废弃Proxy 对象替代 4. process.nextTickNode.js |
| 谁先运行 | 后运行 | 先运行 |
| 会触发新一轮Tick吗 | 会 | 不会 |
SSR和SPA区别
服务端渲染SSR和客户端渲染SPA单页面应用的区别
SSR (Server Side Render)最终HTML文件由服务端来生成然后浏览器直接下载进行显示。支持SSR的框架有基于React的Next和基于Vue的Nuxt。 SPA (Single Page Application)浏览器下载的是整个单页面应用的相关代码框架代码、业务代码资源最终HTML文件通过js代码在浏览器上生成。三大框架Angular、Vue、React均为SPA。 SSR主要解决SPA首屏渲染慢以及不利于SEO的问题其优势为
首屏渲染快。SPA会一次性下载整个单页面应用的所有代码和资源造成首屏渲染缓慢而SSR则对每个页面单独进行服务端渲染的HTML文件这样访问什么页面就下载什么页面并且由于直接下载HTML文件文件容量相对较小所以可以被更快地加载好给带宽较差的访问者带来速度上的提升。 支持SEO。SPA在直到浏览器运行其JS代码前页面的数据是未知的因此无法被爬虫而SSR由于服务端直接输出HTML文件因此可以解决这个问题。一些非最优的解决方案如取巧地将某些需要SEO的页面进行预渲染或者判断访问来源是爬虫时才输出服务端渲染的html否则输出SPA但是这样做也有弊端比如爬虫抓取的数据可能和真实访问数据不一致等等。 SPA与SSR选择
如果采取前后端分离开发SPA效率更高无需后端人员操心前端内容。相反如果采用SSR则需要后端人员也对前端的技能有一定掌握并且前端人员做好页面后需要由后端人员来进行修改。 如果对SEO有需求可采用SSR的方法。 总结若无SEO需求且前后端分离开发首选还是SPA。而在需要加速首屏渲染时可以采用SSR的方法或者webpack的方法等等。若需要SEO则采用SSR或对部分页面预渲染的方法。Nuxt是一个Node程序这是由于我们要把Vue在服务端上运行需要Node环境。当我们访问Nuxt应用时实际上在访问Node程序的路由程序输出为首屏渲染内容+用于重新渲染的SPA的脚本代码。其中路由是由Nuxt中定义好的pages文件夹来生成。
1、SSR渲染的优势
1更利于SEO
2更利于首屏渲染特别是对于缓慢的网络情况或运行缓慢的设备内容更快到达
2、SSR渲染的缺点
1服务器压力大考虑服务器端负载。
2开发条件受限只会执行到ComponentMount之前的生命周期钩子引用第三方库不可用其他生命周期钩子引用库选择产生很大的限制。
3学习成本增大需要学习构建设置和部署的更多要求。
怎样判断对象是否为空
把对象转换为数组来进行判断
父子组件的执行顺序为
父组件beforeCreated ->父组件created ->父组件beforeMounted ->子组件beforeCreated ->子组件created ->子组件beforeMounted ->子组件mounted -> 父组件mounted
为什么用set
由于 Vue 会在初始化实例时进行双向数据绑定使用Object.defineProperty()对属性遍历添加 getter/setter 方法所以属性必须在 data 对象上存在时才能进行上述过程 这样才能让它是响应的。如果要给对象添加新的属性此时新属性没有进行过上述过程不是响应式的所以会出想数据变化页面不变的情况。此时需要用到$set。
任务队列 “ 任务队列 " 是一个先进先出的数据结构排在前面的事件优先被主线程读取。主线程的读取过程基本上是自动的只要执行栈一清空" 任务队列 " 上第一位的事件就会自动进入主线程。
所有任务可以分成两种一种是同步任务synchronous另一种是异步任务asynchronous。
同步任务指的是在主线程上排队执行的任务只有前一个任务执行完毕才能执行后一个任务
异步任务指的是不进入主线程、而进入 " 任务队列 "task queue的任务只有"任务队列"通知主线程某个异步任务可以执行了该任务才会进入主线程执行。
JS如何实现异步操作
JS 的异步是通过回调函数实现的即通过任务队列在主线程执行完当前的任务栈所有的同步操作主线程空闲后轮询任务队列并将任务队列中的任务回调函数取出来执行。
" 回调函数 "callback就是那些会被主线程挂起来的代码。异步任务必须指定回调函数当主线程开始执行异步任务就是执行对应的回调函数。
虽然 JS 是单线程的但是浏览器的内核是多线程的在浏览器的内核中不同的异步操作由不同的浏览器内核模块调度执行异步操作会将相关回调添加到任务队列中。而不同的异步操作添加到任务队列的时机也不同如 onclick setTimeoutajax 处理的方式都不同这些异步操作是由浏览器内核的 webcore 来执行的webcore 包含上图中的3种 webAPI分别是 DOM Binding、network、timer模块。
onclick 由浏览器内核的 DOM Binding 模块来处理当事件触发的时候回调函数会立即添加到任务队列中。 setTimeout 会由浏览器内核的 timer 模块来进行延时处理当时间到达的时候才会将回调函数添加到任务队列中。 ajax 则会由浏览器内核的 network 模块来处理在网络请求完成返回之后才将回调函数添加到任务队列中。 异步执行机制 所有同步任务都在主线程上执行形成一个执行栈execution context stack。 主线程之外还存在一个 " 任务队列 "task queue。只要异步任务有了运行结果就在 " 任务队列 " 之中放置一个事件。 一旦 " 执行栈 " 中的所有同步任务执行完毕系统就会读取 " 任务队列 "看看里面有哪些事件。于是那些对应的异步任务结束等待状态进入执行栈开始执行。 主线程不断重复上面的第三步事件轮询 JS中事件队列的优先级 在 JS 的ES6 中新增的任务队列promise优先级是在事件循环之上的事件循环每次 tick 后会查看 ES6 的任务队列中是否有任务要执行也就是 ES6 的任务队列比事件循环中的任务事件队列优先级更高。
先执行同步代码再执行异步代码先执行微任务再执行宏任务
setTimeout( fn, 0 )它在 " 任务队列 " 的尾部添加一个事件因此要等到同步任务和 " 任务队列 " 现有的事件都处理完才会得到执行。
console.log(1) setTimeout(function () { console.log(6) }, 1000) new Promise(function (resolve, reject) { console.log(2) setTimeout(function () { console.log(3) }, 500) resolve() }).then(function (res) { console.log(4) }) console.log(5)
// 1 2 5 4 3 6 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 微观任务队列 微任务语言标准ECMAScript提供如process.nextTick(node)、Promise、Object.observe、MutationObserver
宏观任务队列 宏任务由宿主环境提供比如setTimeout、setInterval、网络请求Ajax、用户I/O、script整体代码、UI rendering、setImmediatenode
call、apply、bind区别
-
三者都可以改变函数的this对象指向。
-
三者第一个参数都是this要指向的对象如果如果没有这个参数或参数为undefined或null则默认指向全局window。
-
三者都可以传参但是apply是数组而call是参数列表且apply和call是一次性传入参数而bind可以分为多次传入。
-
bind 是返回绑定this之后的函数便于稍后调用apply 、call 则是立即执行 。
query和params区别
区别 1.首先就是写法得不同query 得写法是 用 path 来编写传参地址而 params 得写法是用 name 来编写传参地址你可以看一下编写路由时候得相关属性你也可以输出一下 路由对象信息 看一下
2.接收方法不同 一个用 query 来接收 一个用 params 接收 总结就是谁发得 谁去接收
3.query 在刷新页面得时候参数不会消失而 params 刷新页面得时候会参数消失可以考虑本地存储解决
4.query 传得参数都是显示在url 地址栏当中而 params 传参不会显示在地址栏
http请求状态码
一般我们看不到因为表示请求继续 100 继续请求前面的一部分内容服务端已经接受到了正在等待后续内容 101 请求者已经准备切换协议服务器
2 开头的都是表示成功本次请求成功了只不过不一样的状态码有不一样的含义语义化
200 标准请求成功一般表示服务端提供的是网页 201 创建成功一般是注册的时候表示新用户信息已经添加到数据库 203 表示服务器已经成功处理了请求但是返回的信息可能来自另一源 204 服务端已经成功处理了请求但是没有任何数据返回
3 开头也是成功的一种但是一般表示重定向 301 永久重定向 302 临时重定向 304 使用的是缓存的数据 305 使用代理
4 开头表示客户端出现错误了 400 请求的语法服务端不认识 401 未授权你要登录的网站需要授权登录 403 服务器拒绝了你的请求 404 服务器找不到你请求的 URL
405本页面拒绝访问
407 你的代理没有授权 408 请求超时 410 你请求的数据已经被服务端永久删除
5 开头的表示服务端出现了错误 500 服务器内部错误 503 服务器当前不可用过载或者维护 505 请求的协议服务器不支持
防抖和节流
-
节流: n 秒内只运行一次若在 n 秒内重复触发只有一次生效
function throttled(fn, delay) { let timer = null let starttime = Date.now() return function () { let curTime = Date.now() // 当前时间 let remaining = delay - (curTime - starttime) // 从上一次到现在还剩下多少多余时间 let context = this let args = arguments clearTimeout(timer) if (remaining <= 0) { fn.apply(context, args) starttime = Date.now() } else { timer = setTimeout(fn, remaining); } } } -
防抖: n 秒后在执行该事件若在 n 秒内被重复触发则重新计时
function debounce(func, wait, immediate) {
let timeout;
return function () {
let context = this;
let args = arguments;
if (timeout) clearTimeout(timeout); // timeout 不为null
if (immediate) {
let callNow = !timeout; // 第一次会立即执行以后只有事件执行后才会再次触发
timeout = setTimeout(function () {
timeout = null;
}, wait)
if (callNow) {
func.apply(context, args)
}
}
else {
timeout = setTimeout(function () {
func.apply(context, args)
}, wait);
}
}
}
hash和history区别
hash支持缓存
history不支持缓存需要有后台来配置来做兼容
Vue-Router路由模式的选择和底层原理
.路由类型 Hash模式丑无法使用锚点定位。 History模式需要后端配合IE9不兼容(可使用强制刷新处理IE9不兼容) hash路由===》location.hash切换
windos.onhashchange监听路径的切换
hisory路由==》hisory.pushState切换
Windows.onpopstate监听路径的切换
理解
Vue.util.defineReactive_route这个工具库把路由的信息变成了响应式数据而defineReactive()内部就是调用了Object.defineProperty()和依赖收集实现了路由信息的响应式而Vue的data也是通过这种方式实现响应式。 图中左边五种方式都会触发调用updateRoute这个API这个API的功能是修改路由中的响应式数据当响应式数据被改变后就会自动触发router-view的更新router-view会根据url和路由匹配规则进行相应组件的展示。
hash和History原理
hash模式背后的原理是onhashchange事件
-
前端路由的底层原理hashchange 和H5的history API中的popState和replaceState来进行实现的
hash路由===》location.hash切换
windos.onhashchange监听路径的切换
hisory路由==》hisory.pushState切换
Windows.onpopstate监听路径的切换
import和require的区别
import是ES6标准中的模块化解决方案require是node中遵循CommonJS规范的模块化解决方案。
后者支持动态引入也就是require(${path}/xx.js)前者目前不支持但是已有提案。
前者是关键词后者不是。
前者是编译时加载必须放在模块顶部在性能上比后者好一些后者是运行时加载理论来说放在哪里都可以。
前者采用的是实时绑定方式即导入和导出的值都指向同一个内存地址所以导入的值会随着导出值变化而后者在导出时是指拷贝就算导出的值变化了导入的值也不会变化如果想要更新导入的值就要重新导入。
前者会编译成require/exports来执行。
Vue父组件监听子组件值变化
通过this.$emit(‘方法’,监听的值)
vue单页项目常用优化
vue项目是单页应用,项目在第一次加载的时候会将大部分内容都加载进来,故而会导致加载很慢,以下是优化方案:
1.使用cdn加载一些不常变化的文件,比如用到的UI框架,vue脚手架相关的文件 (参见vue项目优化--引入cdn文件)
2.将静态的js,css以及图片放到第三方服务器
3.按需加载路由
4.webpack-parallel-uglify-plugin 可以优化打包js文件
5.在代码层面进行优化:
(1) 将重复的功能分块提取出来,封装成组件,让代码进行有效的复用
(2) 尽量利用computed属性代替for循环来渲染数据
(3) 提取公共方法,减少js代码量
(4) 提取公共的样式,减少页面样式的代码量
(5) 按照功能设置打包的代码块
(6) 尽量用v-if 代替v-show.因为v-show为false只是设置页面的功能模块不可见,它还是会渲染. 而v-if为false,则不会渲染该模块的功能
js是怎样监听数组变化 的
深拷贝一份放在数组原型上Object.defineProperty
数据劫持
vue监听数组变化
Object.defineProperty来监听数组变化
rem单位是基于根节点
JavaScript中的null和undefined的区别
1、null
表示没有对象即该处不应该有值用法如下
作为函数的参数表示该函数的参数不是对象
作为原型链的终点。
2、undefined
表示缺少值就是此处应该有一个值但是还没有定义情况如下
变量被声明了但没有赋值时就等于undefined
调用函数时应该提供的参数没有提供该参数等于undefined
对象没有赋值的属性该属性的值为undefined
函数没有返回值的时默认返回undefined
JS如何判断一个对象为空

2017年09月29日 17:50 · 阅读 4517
关注
原文链接 blog.csdn.net
昨天面试的时候被问到的问题。只怪自己根基不牢没有回答好。然后面试官提示用for in突然恍然大悟然后又查询了网上的一些方法对这个问题做一下整理。
1、最常见的思路for…in…遍历属性为真则为“非空数组”否则为“空数组”
var judgeObj = function(obj){
for(var item in obj){
return true;
}
return false;
}复制代码
2.通过JSON自带的.stringify方法来判断
var judgeObj = function(obj){
if(JSON.stringify(obj) == "{}") return true;
else return false;
}复制代码
3.ES6新增的方法Object.keys()
var judgeObj = function(obj){
if(Object.keys(obj).length == 0) return true;
else return false;
}
JavaScript 判断对象属性是否存在对象是否包含某个属性
一般推荐使用 in 运算符用法是属性名 in 对象如果存在返回 true反之为 false来看个例子
var echo = {
name:'听风是风',
job:undefined
};
console.log('name' in echo); //true
console.log('job' in echo); //true
console.log('age' in echo); //false
1234567
但需要注意的是in 只能判断对象有没有这个属性无法判断这个属性是不是自身属性啥意思咱们接着说。
判断是否是自身属性
一个最简单的构造函数创建实例的例子
function Parent(){
this.name = 'echo';
};
Parent.prototype.age = 26;
var o = new Parent();
o.name//echo
o.age//26
1234567
在这个例子中对于实例 o 而言name 就是是自身属性这是它自己有的而 age 是原型属性o 虽然没有这个属性但在需要时它还是顺着原型链找到了自己的老父亲 Parent并借用了这个属性。
所以当我们用 in 判断时可以发现结果均为 true
'name' in o;//true 'age' in o;//true 12
针对这个问题如果我们还要判断是否是自身属性就得借用方法hasOwnProperty()不信你看
o.hasOwnProperty('name');//true
o.hasOwnProperty('age');//false
12
说到底hasOwnProperty()做了两件事除了判断对象是否包含这个属性还判断此属性是不是对象的自身属性。
所以我们可以简单总结一下如果我们只需判断对象有没有某个属性使用 in 运算符就好了。而如果我们还要关心这个属性是不是自身属性那么推荐hasOwnProperty()方法。
说了这么多这两个判断有什么使用场景呢
关于 in 运算符判断对象有没有某个属性最常见的我们希望给某个对象添加一个方法直接添加又担心其他同事已经声明过存在覆盖的可能性所以使用 in 来判断没有这个属性咱们再加。
当然针对这个问题使用 Symbol 来确保对象 key 的唯一性也是不错的做法这个就看实际场景了。
而关于hasOwnProperty()这个方法呢我目前遇到的就是深拷贝实现时会使用因为我们知道每个对象都有原型而深拷贝时我们只是希望拷贝对象的自身属性使用此方法做个区分就是非常奈斯的做法了
js循环机制
事件循环过程可以简单描述为
a、函数入栈当 Stack 中执行到异步任务的时候就将他丢给 WebAPIs ,接着执行同步任务,直到 Stack 为空;
b、在此期间 WebAPIs 完成这个事件把回调函数放入 CallbackQueue (任务队列)中等待;
c、当执行栈为空时Event Loop 把 Callback Queue中的一个任务放入Stack中,回到第1步。
事件循环Event Loop 是让 JavaScript 做到既是单线程又绝对不会阻塞的核心机制也是 JavaScript 并发模型Concurrency Model的基础是用来协调各种事件、用户交互、脚本执行、UI 渲染、网络请求等的一种机制。在执行和协调各种任务时Event Loop 会维护自己的事件队列。
事件队列是一个存储着待执行任务的队列其中的任务严格按照时间先后顺序执行排在队头的任务将会率先执行而排在队尾的任务会最后执行。事件队列每次仅执行一个任务在该任务执行完毕之后再执行下一个任务,一个任务开始后直至结束不会被其他任务中断。执行栈则是一个类似于函数调用栈的运行容器当执行栈为空时JS 引擎便检查事件队列如果不为空的话事件队列便将第一个任务压入执行栈中运行。
任务队列在JavaScript中异步任务被分为两种一种宏任务MacroTask也叫Task一种叫微任务
宏任务的例子很多包括创建主文档对象、解析HTML、执行主线或全局JavaScript代码更改当前URL以及各种事件如页面加载、输入、网络事件和定时器事件。从浏览器的角度来看宏任务代表一个个离散的、独立工作单元。运行完任务后浏览器可以继续其他调度如重新渲染页面的UI或执行垃圾回收。
而微任务是更小的任务。微任务更新应用程序的状态但必须在浏览器任务继续执行其他任务之前执行浏览器任务包括重新渲染页面的UI。微任务的案例包括promise回调函数、DOM发生变化等。微任务需要尽可能快地、通过异步方式执行同时不能产生全新的微任务。微任务使得我们能够在重新渲染UI之前执行指定的行为避免不必要的UI重绘UI重绘会使应用程序的状态不连续。
当当前执行栈中的事件执行完毕后js 引擎首先会判断微任务对列中是否有任务可以执行如果有就将微任务队首的事件压入栈中执行。当微任务对列中的任务都执行完成后再去判断宏任务对列中的任务。每次宏任务执行完毕都会去判断微任务队列是否产生新任务若存在就优先执行微任务否则按序执行宏任务。
事件循环通常至少需要两个任务队列宏任务队列和微任务队列。两种队列在同一时刻都只执行一个任务。
vue中data为什么是一个函数
vue中的data是一个对象类型对象类型的数据是按引用传值的这就会导致所有组件的实例都共享同一份数据这是不对的我们要的是每个组件实例都是独立的
为了解决对象类型数据共享的问题我们需要将 data 定义成一个函数每个实例需要通过调用函数生成一个独立的数据对象
js中typeof与instanceof分别是什么
一、typeof的定义和用法
返回值是一个字符串用来说明变量的数据类型。
具体用法细节
1、typeof 一般只能返回如下几个结果
'undefined' 这个值未定义。
'boolean'这个值是布尔值。
'string' 这个值是字符串。
'number' 这个值是数值。
'object'这个值是对象或null。
'function' 这个值是函数。 2、typeof 来获取一个变量是否存在如
`if``(``typeof` `a!=``"undefined"``){alert(``"ok"``)}`
而不要去使用 if(a) 因为如果 a 不存在未声明则会出错。
3、对于 Array,Null 等特殊对象使用 typeof 一律返回 object这正是 typeof 的局限性。 二、Instanceof定义和用法
Instanceof定义和用法instanceof 用于判断一个变量是否属于某个对象的实例。也可以用来判断某个构造函数的prototype属性是否存在另外一个要检测对象的原型链上。
前端重绘和重排
有经验的大佬对这个概念一定不会陌生“浏览器输入URL发生了什么”。估计大家已经烂熟于心了从计算机网络到JS引擎一路飞奔到浏览器渲染引擎。 经验越多就能理解的越深。
感兴趣的同学可以看一下这篇文章深度和广度俱佳 《从输入 URL 到页面加载的过程如何由一道题完善自己的前端知识体系》
切回正题我们继续探讨何为重排。浏览器下载完页面所有的资源后就要开始构建DOM树与此同时还会构建渲染树(Render Tree)。其实在构建渲染树之前和DOM树同期会构建Style Tree。DOM树与Style Tree合并为渲染树
DOM树表示页面的结构 渲染树表示页面的节点如何显示
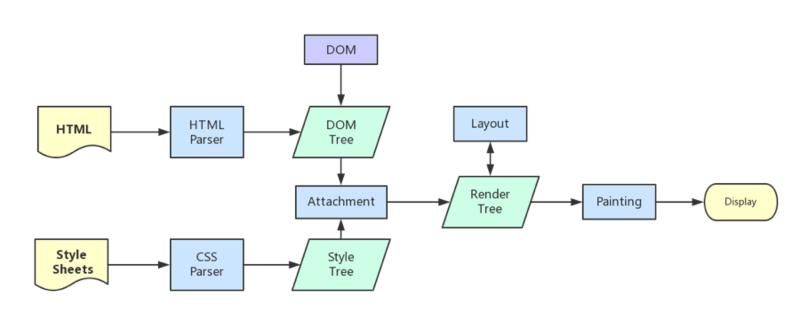
一旦渲染树构建完成就要开始绘制paint页面元素了。
当DOM的变化引发了元素几何属性的变化比如改变元素的宽高元素的位置导致浏览器不得不重新计算元素的几何属性并重新构建渲染树这个过程称为“重排”。完成重排后要将重新构建的渲染树渲染到屏幕上这个过程就是“重绘”。
简单的说重排负责元素的几何属性更新重绘负责元素的样式更新。而且重排必然带来重绘但是重绘未必带来重排。比如改变某个元素的背景这个就不涉及元素的几何属性所以只发生重绘。
二、 重排触发机制绘
上面已经提到了重排发生的根本原理就是元素的几何属性发生了改变那么我们就从能够改变元素几何属性的角度入手
-
添加或删除可见的DOM元素
-
元素位置改变
-
元素本身的尺寸发生改变
-
内容改变
-
页面渲染器初始化
-
浏览器窗口大小发生改变
Vue.nextTick 的原理和用途
Vue在修改数据后视图不会立刻更新而是等同一事件循环中的所有数据变化完成之后再统一进行视图更新。
事件循环
第一个tick本次更新循环
1.首先修改数据这是同步任务。同一事件循环的所有的同步任务都在主线程上执行形成一个执行栈此时还未涉及DOM.
2.Vue开启一个异步队列并缓冲在此事件循环中发生的所有数据变化。如果同一个watcher被多次触发只会被推入队列中一次。
第二个tick(‘下次更新循环’)
同步任务执行完毕开始执行异步watcher队列的任务更新DOM。Vue在内部尝试对异步队列使用原生的Promise.then和MessageChannel 方法如果执行环境不支持会采用 setTimeout(fn, 0) 代替。
第三个tick下次 DOM 更新循环结束之后
二、应用场景及原因
1.在Vue生命周期的created()钩子函数进行DOM操作一定要放到Vue.nextTick()的回调函数中。
在created()钩子函数执行的时候DOM 其实并未进行任何渲染而此时进行DOM操作无异于徒劳所以此处一定要将DOM操作的js代码放进Vue.nextTick()的回调函数中。与之对应的就是mounted()钩子函数因为该钩子函数执行时所有的DOM挂载和渲染都已完成此时在该钩子函数中进行任何DOM操作都不会有问题。
2.在数据变化后要执行的某个操作而这个操作需要使用随数据改变而改变的DOM结构的时候这个操作都应该放进Vue.nextTick()的回调函数中。
具体原因在Vue的官方文档中详细解释
Vue 异步执行 DOM 更新。只要观察到数据变化Vue 将开启一个队列并缓冲在同一事件循环中发生的所有数据改变。如果同一个 watcher 被多次触发只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作上非常重要。然后在下一个的事件循环“tick”中Vue 刷新队列并执行实际 (已去重的) 工作。Vue 在内部尝试对异步队列使用原生的Promise.then和MessageChannel如果执行环境不支持会采用setTimeout(fn, 0)代替。
async awit实现原理
async/await 就是 Generator 的语法糖使得异步操作变得更加方便 2async 函数就是将 Generator 函数的星号*替换成 async将 yield 替换成await 3async 是 Generator 的语法糖这个糖体现在这几个方面 async函数内置执行器函数调用之后会自动执行输出最后结果而Generator需要调用next或者配合co模块使用 更好的语义async和await比起星号和yield语义更清楚了async表示函数里有异步操作await表示紧跟在后面的表达式需要等待结果 更广的适用性co模块约定yield命令后面只能是 Thunk 函数或 Promise 对象而async 函数的 await 命令后面可以是 Promise 对象和原始类型的值 返回值是Promiseasync函数的返回值是 Promise 对象Generator的返回值是 IteratorPromise 对象使用起来更加方便 4async/await 函数的实现原理就是将 Generator 函数和自动执行器包装在一个函数里
Promise的构造函数方法
Promise是什么 1、认识Promise Promise 是异步操作的一种解决方案。 先给大家讲一下什么是异步 回调函数其实就是异步操作例
document.addEventListener(
'click',
() => {
console.log('这里是异步的');
},
false
);
console.log('这里是同步的');
2、什么时候使用 Promise Promise 一般用来解决层层嵌套的回调函数回调地狱 callback hell的问题。
在这里插入代码片
Promise的基本用法 1、实例化构造函数生成实例对象 Promise 解决的不是回调函数而是回调地狱即并不是用了Promise就用不了回调函数它们两个是可以共存的。
// 实例化构造函数生成实例对象
const p = new Promise(() => {});
2、Promise 的状态 Promise的状态解决了Promise的一系列行为。Promise 有 3 种状态一开始是 pending未完成执行 resolve变成 fulfilled(resolved)已成功执行 reject变成 rejected已失败Promise 的状态一旦变化就不会再改变了。
一开始是 pending未完成
const p = new Promise((resolve, reject) => {
});
console.log(p); // Promise {<pending>
执行 resolve变成 fulfilled(resolved)已成功
const p = new Promise((resolve, reject) => {
resolve();
});
console.log(p); // Promise {<fulfilled>: undefined}
执行 reject变成 rejected已失败
const p = new Promise((resolve, reject) => {
reject();
});
console.log(p); // Promise {<rejected>: undefined}
但这里请大家注意Promise里面第一个参数是成功状态的回调函数第二个参数是失败状态的回调函数Promise里面的resolve和reject只是形参名字可以随便写想起什么名就起什么名写成resolve和reject的原因是为了语义化更强一些那么请问下面代码执行结果是什么
const p = new Promise((r1,r2) => {
r2();
});
console.log(p);
因为r1 和 r2 只是形参第二个参数是失败状态的回调函数所以调用 r2 就等同于调用 失败状态的回调函数 所以毫无疑问结果是Promise {<rejected>: undefined}在这里只是给大家提个醒大家不要弄迷糊了。
Promise 的状态一旦变化就不会再改变了
const p = new Promise((resolve, reject) => {
resolve();
reject();
});
console.log(p); // Promise {<fulfilled>: undefined}
3、then方法简单说明一下具体在后面讲 这里then传两个函数成功了用第一个函数失败了用第二个函数。
// 失败
const p = new Promise((resolve, reject) => {
reject();
});
p.then(
() => {
console.log('success');
},
() => {
console.log('error');
}
);
// error
// 成功
const p = new Promise((resolve, reject) => {
resolve();
});
p.then(
() => {
console.log('success');
},
() => {
console.log('error');
}
);
// success
4、resolve 和 reject 函数的参数 resolve 和 reject 函数的参数都会传给相应的then方法里面函数的形参即resolve()传它的参数给then里面第一个函数的形参reject()传它的参数给then里面第二个函数的形参举例
// 成功的时候
const p = new Promise((resolve, reject) => {
resolve({username:'Alex'});
});
p.then(
data => {
console.log('success', data);
},
err => {
console.log('error', err);
}
);
// success {username: "alex"}
// 失败的时候
const p = new Promise((resolve, reject) => {
reject(new Error('reason'));
});
p.then(
data => {
console.log('success', data);
},
err => {
console.log('error', err);
}
);
// error Error: reason
// at 2-2.Promise 的基本用法.html:28
// at new Promise (<anonymous>)
// at 2-2.Promise 的基本用法.html:16
then方法 1、什么时候执行 pending->fulfilled 时执行 then 的第一个回调函数 pending->rejected 时执行 then 的第二个回调函数 2、执行后的返回值 then 方法执行后返回一个新的 Promise 对象。
const p = new Promise((resolve, reject) => {
resolve();
// reject();
});
const p2 = p
.then(
() => {},
() => {}
)
.then() // 因为then方法返回的是一个promise所以可以在后面再添加then方法。
.then();
console.log(p, p2, p === p2); // Promise {<fulfilled>: undefined} Promise {<pending>} false
3、then 方法返回的 Promise 对象的状态改变 在前面讲过第一个new 的promise可以决定紧挨着后面then的执行回调函数例
const p = new Promise((resolve, reject) => {
reject();
});
p.then(
() => {
console.log('success');
},
() => {
console.log('err');
});
// err
因为在p中执行reject()所以执行p紧挨着的then的第二个回调函数因此输出err 而我们都知道then方法可以继续使用在上一个then方法的后面的但是大家有没有想过新的then方法是怎么执行的呢下面进行讲解 在讲解之前大家先判断一下下面这块代码的打印出来的值是多少
// 案例1
const p = new Promise((resolve, reject) => {
reject();
});
p.then(
() => {
console.log('success');
},
() => {
console.log('err');
}).then(
data => {
console.log('success2', data);
},
err => {
console.log('err2', err);
}
)
这个值是err success2 undefined 我先给大家分析一下在p中执行reject()所以在第一个then中执行第二个回调函数所以打印出err然后在第一个then中默认返回的永远都是成功状态的 Promise 对象所以在第二个then中调用第第一个回调函数所以接着打印出success2 undefined由此可见后面的then执行第一个回调函数还是第二个回调函数看的是前面的then可能大家对 在第一个then中默认返回的永远都是成功状态的 Promise 对象 这句话不太理解 下面我通过代码给大家演示 先简单通过代码看一下
// 在 then 的回调函数中return 后面的东西会用 Promise 包装一下
return undefined;
// 等价于
return new Promise(resolve => {
resolve(undefined);
});
这是详细讲解 1、在所有函数中都有return值没有写的时候就默认返回undefined所以在第一个then里面就默认返回undefined相当于程序中默认有 return undefined; 这样一行代码
() => {
console.log('err');
// 默认这里有 return undefined;这样一行代码
})
又因为 默认返回的永远都是成功状态的 Promise 对象即
() => {
console.log('err');
// 默认这里有 return undefined;这样一行代码
// 因为默认返回的永远都是成功状态的 Promise 对象所以相当于一个新的Promise里面执行resolve()即
return new Promise((resolve, reject) => {
resolve(undefined); // 因为默认返回undefined所以resolve里面参数是undefined
})
因为上一个then执行resolve所以到第二个then那里就执行第一个回调函数所以打印出 success2 undefined打印出undefined是因为在一个then里面的reject传进去的undefined。讲到这里大家可能会问默认返回的永远都是成功状态的 Promise 对象那么如何返回失败状态的Promise对象呢其实是这样的then里面默认的是返回的永远都是成功状态的 Promise 对象那么我直接给一个失败状态的Promise那么不就不会再出现默认值了呢没错就是这样。举例
const p = new Promise((resolve, reject) => {
reject();
});
p.then(
() => {
console.log('success');
},
() => {
console.log('err');
/
return new Promise((resolve, reject) => {
reject('reason');
});
/
}).then(
data => {
console.log('success2', data);
},
err => {
console.log('err2', err);
}
)
大家注意横线里面的两行代码那样写即程序不会再执行那个 默认的正确状态的Promis对象了而执行自己写的那个错误的Promise对象即/中间的代码所以这个案例的执行结果是err err2 reason原理同案例1一样。
那么简单测试一下上面知识是否掌握了上案例
const p = new Promise((resolve, reject) => {
reject();
});
p.then(
() => {
console.log('success');
},
() => {
// 步骤一
console.log('err');
}).then(
data => {
// 步骤二
console.log('success2', data);
},
err => {
console.log('err2', err);
}
).then(
data => {
// 步骤三
console.log('success3', data);
},
err => {
console.log('err3', err);
}
);
只要大家将上面知识理解了那么这个案例就是小菜一碟答案是err success2 undefined success3 undefined执行的分别是步骤一步骤二步骤三。 catch方法 1、有什么用 在前面的then方法中我们知道它里面有两个回调函数第一个处理成功的状态第二个处理失败的状态但在实际开发中一般then只处理成功的状态因此只传一个回调函数因此catch就是用来专门处理失败的状态的即catch 本质上是 then 的特例就是then(null, err => {}); 2、基本用法
new Promise((resolve, reject) => {
// resolve(123);
reject('reason');
}).then(data => {
console.log(data); // then 处理正确的状态
}).catch(err => {
console.log(err); // catch 处理错误的状态
})
// reason
// 上面的catch其实就相当于
.then(null, err => {
console.log(err);
});
catch() 可以捕获它前面的错误一般总是建议Promise 对象后面要跟 catch 方法这样可以处理 Promise 内部发生的错误 catch可以捕获前面的错误如果错误一旦被catc捕获到则错误就消失了。还有就是catch默认也是返回一个成功状态的Promise对象原因很简单catch本质是then因为then默认返回成功状态的Promise对象所以catch也是返回成功状态的Promise对象所以catch后面跟的then只会执行成功的回调函数如果想执行失败状态的回调函数需要自己手动return 失败状态的Promise对象除了这种方法外还有一种方法见代码
new Promise((resolve, reject) => {
// resolve(123);
reject('reason');
})
.then(data => {
console.log(data);
}) /// 第一块
.catch(err => {
console.log(err);
throw new Error('reason');
})
.then(data => {
console.log(data);
}) 第二块
.catch(err => {
console.log(err);
}); /
// reason
// Error: reason
reason是第一块代码执行的结果 Error: reason是第二块代码执行的结果。在第一块代码里扔一个错误那么就会被第二块代码中的catch捕获到这样也不会再执行then里面的成功状态的回调函数了。 Promise.resolve() 和 Promise.reject() 1、Promise.resolve() 是成功状态 Promise 的一种简写形式。
new Promise(resolve => resolve('foo'));
// 这个地方的resolve是一个形参名字想怎么写就怎么写
// 简写
Promise.resolve('foo');
// 这里的resolve是一个固定的方法名不能乱写
参数 1一般参数最应该关注
Promise.resolve('foo').then(data => {
console.log(data);
}); // foo
2特殊参数简单了解一下即可不要深究 1、把Promise当作参数传进去。
const p1 = new Promise(resolve => {
setTimeout(resolve, 1000, '我执行了');
});
Promise.resolve(p1).then(data => {
console.log(data);
}); // 我执行了(注在一秒后打印
这是为什么呢原因是当 Promise.resolve() 接收的是 Promise 对象时直接返回这个 Promise 对象什么都不做。 即上面的代码等同于
const p1 = new Promise(resolve => {
setTimeout(resolve, 1000, '我执行了');
// 上面的setTimeout等同于
// setTimeout(() => {
// resolve('我执行了');
// }, 1000);
});
p1.then(data => {
console.log(data);
}); // 我执行了注一秒后打印
console.log(Promise.resolve(p1) === p1); // true
还有就是当 resolve 函数接收的是 Promise 对象时后面的 then 会根据传递的 Promise 对象的状态变化决定执行哪一个回调。 上代码进行描述
const p1 = new Promise(resolve => {
setTimeout(resolve, 1000, '我执行了');
});
new Promise(resolve => resolve(p1)).then(data => {
console.log(data);
});
上面那句话的意思就是如果函数接收的是一个Promise对象即上面代码的p1时后面的then受p1支配因为p1在一秒后执行了resolve('我执行了');所以就给then里面传了个 ‘我执行了’ 所以then执行后打印出 我执行了。
2、具有 then 方法的对象 因这种形式在实际开发中不咋用这里不再细讲大家知道有这个东西就行。要是碰到了直接查文档就完事了
2、Promise.reject() 失败状态 Promise 的一种简写形式。
new Promise((resolve, reject) => {
reject('reason');
});
// 等价于
Promise.reject('reason');
参数 不管什么参数都会原封不动地向后传递作为后续方法的参数。跟resolve相比简单多了
还有一个Promise.resolve() 和 Promise.reject()的用处就是用在then方法的return中如
new Promise((resolve, rejcet) => {
resolve(123);
})
.then(data => {
// return data;
// return Promise.resolve(data); // 传失败状态的Promise对象的简写
return Promise.reject('reason'); // 传失败状态的Promise对象的简写
})
.then(data => {
console.log(data);
})
.catch(err => console.log(err));
// reason
Promise.all() 1、有什么用 Promise.all() 关注多个 Promise 对象的状态变化可以在Promise对象中传入多个 Promise 实例包装成一个新的 Promise 实例返回。 2、基本用法 Promise.all() 的状态变化与所有传入的 Promise 实例对象状态有关 所有状态都变成 resolved最终的状态才会变成 resolved 只要有一个变成 rejected最终的状态就变成 rejected 见代码
// 封装一个延迟函数
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return 'p1'; // 默认返回成功状态的Promise对象
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return 'p2'; // 默认返回成功状态的Promise对象
});
const p = Promise.all([p1, p2]);
p.then(
data => {
console.log(data);
},
err => {
console.log(err);
}
);
上面代码中的执行结果是p1完成了一秒后p2完成了 (2) [“p1”, “p2”] 两秒后 这块代码是最终的状态是 resolved 再看下面的代码
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return Promise.reject('reason');
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return 'p2';
});
const p = Promise.all([p1, p2]);
p.then(
data => {
console.log(data);
},
err => {
console.log(err);
}
);
这块代码的结果是p1完成了 reason 注一秒后打印 p2完成了 注两秒后打印 这块代码中有rejected所以最终状态就是rejected可能大家疑惑为什么reason在 p1完成了 后面出现大家可以这样理解因为系统检测到某个地方出现了rejected所以直接判定Promise.all的状态是rejected所以直接执行p后面then方法的第二个回调函数所以打印出reason又因为那个rejected的状态是在p1中检测到的所以reason出现在 p1完成了 的后面。 大家可以通过下面的例子检测字迹是否理解
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return 'p1';
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return Promise.reject('reason');
});
const p = Promise.all([p1, p2]);
p.then(
data => {
console.log(data);
},
err => {
console.log(err);
}
);
这里的结果是p1完成了注一秒后打印出来 p2完成了 reason注两秒后打印出来 Promise.race() 和 Promise.allSettled() 先声明一下这两个方法大家简单了解一下即可。 1、Promise.race() Promise.race() 的状态取决于第一个完成的 Promise 实例对象如果第一个完成的成功了那最终的就成功如果第一个完成的失败了那最终的就失败。
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return 'p1';
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return 'p2';
});
const racePromise = Promise.race([p1, p2]);
racePromise.then(
data => {
console.log(data);
},
err => {
console.log(err);
}
);
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return 'p1';
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return Promise.reject('reason');
});
const racePromise = Promise.race([p1, p2]);
racePromise.then(
data => {
console.log(data);
},
err => {
console.log(err);
}
);
这里提供两个例子供大家自己自行下去进行验证学习这里就不细讲了大家在自己编译器上一运行就一目了然了。 2、Promise.allSettled() Promise.allSettled() 的状态与传入的Promise 状态无关它后面的then方法永远执行成功的回调函数它只会忠实的记录下各个 Promise 的表现。见代码
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return 'p1';
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return Promise.reject('reason');
});
const allSettledPromise = Promise.allSettled([p1, p2]);
allSettledPromise.then(data => {
console.log('succ', data);
});
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return Promise.reject('reason');
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return Promise.reject('reason');
});
const allSettledPromise = Promise.allSettled([p1, p2]);
allSettledPromise.then(data => {
console.log('succ', data);
});
上面两个例子大家自行演示看到结果大家都会明白的。 Promise的注意事项 1、resolve 或 reject 函数执行后的代码 推荐在调用 resolve 或 reject 函数的时候加上 return不再执行它们后面的代码。 如
new Promise((resolve, reject) => {
// // return resolve(123);
return reject('reason');
});
虽然 resolve 或 reject 函数的后面的代码仍可以执行。如
new Promise((resolve, reject) => {
// // return resolve(123);
return reject('reason');
console.log('hi');
}); // hi
但是不建议这样写。 2、Promise.all/race/allSettled 的参数问题 参数如果不是 Promise对象 的数组系统会默认的将不是 Promise 的数组元素转变成 Promise对象 的数组。
Promise.all([1, 2, 3]).then(datas => {
console.log(datas);
});
// 等价于
Promise.all([
Promise.resolve(1),
Promise.resolve(2),
Promise.resolve(3)
]).then(datas => {
console.log(datas);
});
参数不只是数组任何可遍历的都可以作为参数 如原生可遍历的数组、字符串、Set、Map、NodeList、arguments 和非原生可遍历的通过Iterate 举个栗子
// Set作为参数
Promise.all(new Set([1, 2, 3])).then(datas => {
console.log(datas);
});
3、Promise.all/race/allSettled 的错误处理 单独处理
// 第一个案例
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return Promise.reject('reason');
}).catch(err => {
console.log('p1', err);
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return Promise.reject('reason');
}).catch(err => {
console.log('p2', err);
});
const allPromise = Promise.all([p1, p2]);
allPromise.then(datas => {
console.log(datas);
});
统一处理
// 第二个案例
const delay = ms => {
return new Promise(resolve => {
setTimeout(resolve, ms);
});
};
const p1 = delay(1000).then(() => {
console.log('p1 完成了');
return Promise.reject('reason');
});
const p2 = delay(2000).then(() => {
console.log('p2 完成了');
return Promise.reject('reason');
});
const allPromise = Promise.all([p1, p2]);
allPromise.then(datas => {
console.log(datas);
}).catch(err => console.log(err));
错误既可以单独处理也可以统一处理
一旦被处理就不会在其他地方再处理一遍上面第二个案例
宏任务和微任务
异步队列当所有的同步任务执行完成之后会执行异步任务。如果异步队列中还有异步那么就会牵涉到异步轮询机制会先走微任务在执行宏任务。当前宏任务周期的所有微任务都执行完成之后会执行下一个宏任务。
宏任务运行环境提供的异步
微任务语言提供的异步
js事件轮询
事件轮询 (eventloop) 是"一个解决和处理外部事件时将它们转换为回调函数的调用的实体(entity)"
JavaScript 语言的一大特点就是单线程也就是说同一个时间只能做一件事。所有任务都需要排队前一个任务结束才会执行后一个任务。如果前一个任务耗时很长后一个任务就不得不一直等着。
任务队列 “ 任务队列 " 是一个先进先出的数据结构排在前面的事件优先被主线程读取。主线程的读取过程基本上是自动的只要执行栈一清空" 任务队列 " 上第一位的事件就会自动进入主线程。
所有任务可以分成两种一种是同步任务synchronous另一种是异步任务asynchronous。
同步任务指的是在主线程上排队执行的任务只有前一个任务执行完毕才能执行后一个任务
异步任务指的是不进入主线程、而进入 " 任务队列 "task queue的任务只有"任务队列"通知主线程某个异步任务可以执行了该任务才会进入主线程执行。
JS如何实现异步操作 JS 的异步是通过回调函数实现的即通过任务队列在主线程执行完当前的任务栈所有的同步操作主线程空闲后轮询任务队列并将任务队列中的任务回调函数取出来执行。
" 回调函数 "callback就是那些会被主线程挂起来的代码。异步任务必须指定回调函数当主线程开始执行异步任务就是执行对应的回调函数。
虽然 JS 是单线程的但是浏览器的内核是多线程的在浏览器的内核中不同的异步操作由不同的浏览器内核模块调度执行异步操作会将相关回调添加到任务队列中。而不同的异步操作添加到任务队列的时机也不同如 onclick setTimeoutajax 处理的方式都不同这些异步操作是由浏览器内核的 webcore 来执行的webcore 包含上图中的3种 webAPI分别是 DOM Binding、network、timer模块。
onclick 由浏览器内核的 DOM Binding 模块来处理当事件触发的时候回调函数会立即添加到任务队列中。 setTimeout 会由浏览器内核的 timer 模块来进行延时处理当时间到达的时候才会将回调函数添加到任务队列中。 ajax 则会由浏览器内核的 network 模块来处理在网络请求完成返回之后才将回调函数添加到任务队列中。 异步执行机制 所有同步任务都在主线程上执行形成一个执行栈execution context stack。 主线程之外还存在一个 " 任务队列 "task queue。只要异步任务有了运行结果就在 " 任务队列 " 之中放置一个事件。 一旦 " 执行栈 " 中的所有同步任务执行完毕系统就会读取 " 任务队列 "看看里面有哪些事件。于是那些对应的异步任务结束等待状态进入执行栈开始执行。 主线程不断重复上面的第三步事件轮询 JS中事件队列的优先级 在 JS 的ES6 中新增的任务队列promise优先级是在事件循环之上的事件循环每次 tick 后会查看 ES6 的任务队列中是否有任务要执行也就是 ES6 的任务队列比事件循环中的任务事件队列优先级更高。
先执行同步代码再执行异步代码先执行微任务再执行宏任务
setTimeout( fn, 0 )它在 " 任务队列 " 的尾部添加一个事件因此要等到同步任务和 " 任务队列 " 现有的事件都处理完才会得到执行。 803
块级作用域
1.在ES6之前JavaScript是没有块级作用域的,所有的变量都通过var关键字去声明,即在控制语句中的变量也可以在外部的作用域去访问。
2.随着ES6的到来JavaScript给我们带来的let 和 const关键字也让它本身拥有了块级作用域的概念( { }内部都是块级作用域,在测试小demo的时候可以使用{ }来创建一个块级作用域来避免变量名称的冲突 )。我们在控制语句中使用let 和 const定义的
for循环中使用let定义的变量在全局作用域访问
3.用处在你需要一些临时的变量的时候块级作用域就可以发挥他的作用。而通过创建块级作用域我们就不会担心会不会搞乱其他人定义的全局变量我们就可以根据自己的想法来定义自己的变量了
全局作用域
JavaScript中的全局作用域中的变量,在任何地方都是可以访问的,全局作用域中的变量在定义的时候生成,浏览器关闭的时候销毁。
函数作用域
js中可以通过函数来创建一个独立作用域称为函数作用域函数可以嵌套所以作用域也可以嵌套
自由变量的概念
在当前作用域没有定义的变量,但是却被访问了。向上级作用域一层一层向上查找,直到找到全局作用域如果没有找到会抛出xx is not defined 的错误
作用域链自由变量的向上级作用域一层一层查找直到找到为止最高找到全局作用域就形成了作用域链
作用域链的理解
对于一个变量引擎从当前作用域开始查找变量如果找不到就会向上一级继续查找。当抵达最外层全局作用域时无论找到还是没有找到查找过程中都会停止。
TCP和UDP的区别
连接性
TCP是面向连接的协议在收发数据前必须和对方建立可靠的连接建立连接的3次握手、断开连接的4次挥手为数据传输打下可靠基础;UDP是一个面向无连接的协议数据传输前源端和终端不建立连接发送端尽可能快的将数据扔到网络上接收端从消息队列中读取消息段。
可靠性
TCP提供可靠交付的服务传输过程中采用许多方法保证在连接上提供可靠的传输服务如编号与确认、流量控制、计时器等确保数据无差错不丢失不重复且按序到达;UDP使用尽可能最大努力交付但不保证可靠交付。
TCP报文结构
TCP协议面向字节流将应用层报文看成一串无结构的字节流分解为多个TCP报文段传输后在目的站重新装配;UDP协议面向报文不拆分应用层报文只保留报文边界一次发送一个报文接收方去除报文首部后原封不动将报文交给上层应用。
吞吐量控制
TCP拥塞控制、流量控制、重传机制、滑动窗口等机制保证传输质量;UDP没有。
双工性
TCP只能点对点全双工通信;UDP支持一对一、一对多、多对一和多对多的交互通信
从上面TCP、UDP编程步骤可以看出UDP 服务器端不需要调用监听(listen)和接收(accept)客户端连接而客户端也不需要连接服务器端(connect)。UDP协议中任何一方建立socket后都可以用sendto发送数据、用recvfrom接收数据不必关心对方是否存在是否发送了数据。
TCP和UDP的使用场景
为了实现TCP网络通信的可靠性增加校验和、序号标识、滑动窗口、确认应答、拥塞控制等复杂的机制建立了繁琐的握手过程增加了TCP对系统资源的消耗;TCP的重传机制、顺序控制机制等对数据传输有一定延时影响降低了传输效率。TCP适合对传输效率要求低但准确率要求高的应用场景比如万维网(HTTP)、文件传输(FTP)、电子邮件(SMTP)等。
UDP是无连接的不可靠传输尽最大努力交付数据协议简单、资源要求少、传输速度快、实时性高的特点适用于对传输效率要求高但准确率要求低的应用场景比如域名转换(DNS)、远程文件服务器(NFS)等。
prototype 和 proto 区别是什么
原型是为了实现对象间的联系解决构造函数无法数据共享而引入的一个属性而原型链是一个实现对象间联系即继承的主要方法
-
prototype是构造函数的属性
-
__proto__是每个实例都有的属性可以访问 [[prototype]] 属性 -
实例的
__proto__与其构造函数的prototype指向的是同一个对象 -
显式原型
prototype 每一个函数在创建之后便会拥有一个prototype属性这个属性指向函数的原型对象显示原型的作用是用来实现基于原型的继承与属性的共享
隐式原型
*proto__上面说的这个原型是JavaScript中的内置属性prototype此属性继承自object对象但Firefox、Safari和Chrome在每个对象上都支持一个属性proto*隐式原型的作用是用来构成原型链实现基于原型的继承
作者漫卷诗书喜欲狂链接[JS]深入理解原型和原型链以及区别(包含面试题详解) - 掘金来源稀土掘金著作权归作者所有。商业转载请联系作者获得授权非商业转载请注明出处。
react事件
react并不会真正的绑定事件到每一个具体元素上而是采用事件代理模式
stestate处在同步逻辑异步更新状态更新真实dom
stestate处在异步逻辑同步更新状态同步更新真实dom
stestate接受第二个参数第二个参数回调函数状态和dom更新完就会被触发
VUE SEO 几种方案
1、SSR服务器渲染
Vue.js 是构建客户端应用程序的框架。默认情况下可以再浏览器中输出Vue组件进行生成DOM和操作DOM。然而也可以将同一个组件渲染未服务器端的HTML字符串将它们直接发送到浏览器最后将这些静态标记“激活”为客户端上完全可交互的应用程序。
服务端渲染的Vue.js应用程序也可以被认为是“同构”或“通用”因为应用程序的大部分代码都可以在服务器和客户端上运行。
权衡之处
-
开发条件所限浏览器特定的代码只能在某些生命周期钩子函数lifecycle hook中使用一些外部扩展库external library可能需要特殊处理才能在服务器渲染应用程序中运行。
-
环境和部署要求更高需要Node.js server运行环境
-
高流量的情况下需要准备相应的服务器负载并明智地采用缓存策略。
优势
-
更好的SEO因为搜索引擎爬虫抓取工具可以直接查看完全渲染的页面
-
更快的内容到达时间time-to-content),特别是对于缓慢的网络情况或运行缓慢的设备。
不足
-
一套代码两套执行环境会引起各种问题比如服务端没有window、document对象处理方式是增加判断如果是客户端才执行
-
涉及构建设置和部署的更多要求需要处于node server的运行环境
-
更多的服务端负载
2、Nuxt静态化
Nuxt.js框架官方是这样介绍的 从头搭建一个服务端渲染的应用是相当复杂的。幸运的是我们有一个优秀的社区项目Nuxt.js这让一切变得非常简单。Nuxt是一个基于Vue生态的更高层的框架为开发服务端渲染的Vue应用提供了极其便利的开发体验。更酷的是你甚至可以用它来做为静态站生成器。
静态化是Nuxt.js打包的另一种方式算是Nuxt.js的一个创新点页面加载速度很快。
注意在Nuxt.js执行 generate静态化打包时动态路由会被忽略。
优势
-
纯静态文件访问速度超快
-
对比SSR不涉及到服务器负载方面问题
-
静态网页不宜遭到黑客攻击安全性更高。
不足
-
如果动态路由参数多都化不适用。
3、 预渲染 prerender-spa-plugin
如果你只是用来改善少数营销页面例如 //about,/contact等=的SEO那么你可能需要预渲染。无需使用Web服务器实时动态编译HTML而是使用预渲染方式在构建时build time简单地生成针对特定路由等静态HTML文件。优点是设置预渲染更简单并可以将你的前端作为一个完全静态的站点。
优势
-
改动过小引入插件配置即可
不足
-
无法使用动态路由
-
只使用少量页面的项目页面多达几百个的情况下打包会非常慢
4、使用Phantomjs针对爬虫做处理
Phantomjs是一个基于webkit内核的无头浏览器即没有UI界面即它就是一个浏览器只是其内的点击、翻页等人为相关操作需要程序设计实现。
虽然“PhantomJS宣布终止开发”但是已经满足对Vue 的SEO处理。
这种解决方案其实是一种旁路机制原理就是通过Nginx配置判断访问来源UA是否是爬虫访问如果是则将搜索引擎的爬虫请求转发到一个node server,再通过PhantomJS来解析完整的HTML返回给爬虫。
优势
-
完全不用改动项目代码按原本的SPA开发即可对比开发SSR成本小的不要太多
-
对已用SPA开发完成的项目这是不二之选。
不足
-
部署需要node 服务器支持。
-
爬虫访问比网页访问要慢一些因为定时要定时资源加载完成才返回给爬虫
-
如果呗恶意模拟百度爬虫大量循环爬取会造成服务器负载方面问题解决方法是判断访问的IP是否是百度官方爬虫的IP
5、总结
如果构建大型网站如商城类不要犹豫直接上SSR服务端渲染当然也有相应的坑等你社区较成熟英文好一些 一切问题都迎刃而解。
如果只是个人博客、公司官网这类其余三种都可以。
如果对已用SPA开发完成的项目进行SEO优化而且支持node服务器请使用Phantomjs。
对于VUE SSR项目已经接手开发过好几个目前也是维护的状态。 从01的项目搭建 开发使用Vue-SSR中也确实遇到一些坑和问题 但这些都能得到解决办法总比困难多的哈哈。
JS判断数组是数组
通过instanceof判断
通过constructor判断
通过Object.prototype.toString.call()判断
通过Array.isArray()判断
js如何合并对象
vue3 +TS 父子组件之间的传值 通信
-
import { definedProps, definedEmits } from 'vue'//使用语法糖才能使用他们
css绝对定位如何居中css绝对定位居中的四种实现方法
1、兼容性不错的主流css绝对定位居中的用法
.conter{
width: 600px; height: 400px;
position: absolute; left: 50%; top: 50%;
margin-top: -200px; /* 高度的一半 */
margin-left: -300px; /* 宽度的一半 */
}
注意这种方法有一个很明显的不足就是需要提前知道元素的尺寸。否则margin负值的调整无法精确。此时往往要借助JS获得。
2、css3的出现使得有了更好的解决方法就是使用transform代替margin. transform中translate偏移的百分比值是相对于自身大小的可以这样实现css绝对定位居中
.conter{
width: 600px; height: 400px;
position: absolute; left: 50%; top: 50%;
transform: translate(-50%, -50%); /* 50%为自身尺寸的一半 */
}
3、margin:auto实现绝对定位元素的居中(上下左右均0位置定位margin: auto)
.conter{
width: 600px; height: 400px;
position: absolute; left: 0; top: 0; right: 0; bottom: 0;
margin: auto; /* 有了这个就自动居中了 */
}
4、使用css3盒模型:flex布局实现css绝对定位居中。这种情况是在不考虑低版本浏览器的情况下可以使用。
1.数组常用方法之 push==改变原数组产生新数组==
-
push是用来在数组的末尾追加一个元素,返回添加以后的长度var arr = [1, 2, 3] // 使用 push 方法追加一个元素在末尾 arr.push(4) console.log(arr) // [1, 2, 3, 4] var res = arr.push(1,2,3,34); res//8
2.数组常用方法之 pop==改变原数组产生新数组==
-
pop是用来删除数组末尾的一个元素,返回删除的元素var arr = [1, 2, 3] // 使用 pop 方法删除末尾的一个元素 var res = arr.pop() console.log(arr) // [1, 2]
3.数组常用方法之 unshift==改变原数组产生新数组==
-
unshift是在数组的最前面添加一个元素var arr = [1, 2, 3] // 使用 unshift 方法想数组的最前面添加一个元素 arr.unshift(4) console.log(arr) // [4, 1, 2, 3]
4.数组常用方法之 shift==改变原数组产生新数组==
-
shift是删除数组最前面的一个元素var arr = [1, 2, 3] // 使用 shift 方法删除数组最前面的一个元素 arr.shift() console.log(arr) // [2, 3]
5.数组常用方法之 splice==改变原数组==
-
splice是截取数组中的某些内容按照数组的索引来截取 -
语法
splice(从哪一个索引位置开始截取多少个替换的新元素)第三个参数可以不写var arr = [1, 2, 3, 4, 5] // 使用 splice 方法截取数组 var res = arr.splice(1, 2) console.log(arr) // [1, 4, 5] console.log(res)//[2,3] - `arr.splice(1, 2)` 表示从索引 1 开始截取 2 个内容 - 第三个参数没有写就是没有新内容替换掉截取位置 ```javascript var arr = [1, 2, 3, 4, 5] // 使用 splice 方法截取数组 arr.splice(1, 2, '我是新内容') console.log(arr) // [1, '我是新内容', 4, 5]
1、删除元素,并返回删除的元素 可以删除任意数量的项只需指定 2 个参数要删除的第一项的位置和要删除的项数。例如 splice(0,2)会删除数组中的前两项。 var arr = [1,3,5,7,9,11]; var arrRemoved = arr.splice(0,2); console.log(arr); //[5, 7, 9, 11] console.log(arrRemoved); //[1, 3] 2、向指定索引处添加元素 可以向指定位置插入任意数量的项只需提供 3 个参数起始位置、 0要删除的项数和要插入的项。例如splice(2,0,4,6)会从当前数组的位置 2 开始插入 4 和 6。 var array1 = [22, 3, 31, 12]; array1.splice(1, 0, 12, 35); //[] console.log(array1); // [22, 12, 35, 3, 31, 12] 3、替换指定索引位置的元素 可以向指定位置插入任意数量的项且同时删除任意数量的项只需指定 3 个参数起始位置、要删除的项数和要插入的任意数量的项。插入的项数不必与删除的项数相等。例如splice (2,1,4,6)会删除当前数组位置 2 的项然后再从位置 2 开始插入 4 和 6。 const array1 = [22, 3, 31, 12]; array1.splice(1, 1, 8); //[3] console.log(array1); // [22, 8, 31, 12] 作者物理达人Physics侯老师 https://www.bilibili.com/read/cv9715493/ 出处bilibili
-
arr.splice(1, 2, '我是新内容')表示从索引 1 开始截取 2 个内容 -
然后用第三个参数把截取完空出来的位置填充
6.数组常用方法之 reverse==改变原数组产生新数组==
-
reverse是用来反转数组使用的var arr = [1, 2, 3] // 使用 reverse 方法来反转数组 arr.reverse() console.log(arr) // [3, 2, 1]
7.数组常用方法之 sort==改变原数组产生新数组==
-
sort是用来给数组排序的默认按照字典排序 先按==照第一位排序-==如果第一位相等就按照第二位var arr = [2, 3, 1] // 使用 sort 方法给数组排序 arr.sort() console.log(arr) // [1, 2, 3]
-
这个只是一个基本的简单用法
// 升序 arr4.sort(function (a, b) { return a - b }) // 降序 arr4.sort(function (a, b) { return b - a })let arr5 = [{ username: 'zhangsan', age: 19 }, { username: 'lisi', age: 10 }, ] // 按照对象的年龄 降序 // a b 数组的元素 arr5.sort(function (a, b) { return b.age - a.age }) -
8.数组常用方法之 concat==不====改变原数组==
-
concat是把多个数组进行拼接 -
和之前的方法有一些不一样的地方就是
concat==不会改变原始数组而是返回一个新的数组==var arr = [1, 2, 3] // 使用 concat 方法拼接数组 var newArr = arr.concat([4, 5, 6]) console.log(arr) // [1, 2, 3] console.log(newArr) // [1, 2, 3, 4, 5, 6]
-
注意 ==
concat方法不会改变原始数组==
-
9.数组常用方法之 join==不会改变原始数组而是把链接好的字符串返回==
-
join是把数组里面的每一项内容链接起来变成一个字符串 -
可以自己定义每一项之间链接的内容
join(要以什么内容链接)默认使用逗号作为分隔符 -
不会改变原始数组而是把链接好的字符串返回
var arr = [1, 2, 3] // 使用 join 链接数组 var str = arr.join('-') console.log(arr) // [1, 2, 3] console.log(str) // 1-2-3-
注意 join 方法不会改变原始数组而是返回链接好的字符串
-
10.slice 复制数组的一部分 ==不改变原始数组返回一个新的数组==
var arr9 = [9,8,7,6,5,4,3,2]; // 参数 两个 开始位置 结束位置,不包含结束位置,不改变原数组 var res9 = arr9.slice(1,3) console.log(res9)//[8, 7] // 第二个参数不传入,复制到最后 console.log(arr9.slice(1))//[8, 7, 6, 5, 4, 3, 2] // 如果传入负数,倒着数位置,最后一个是 -1 console.log(arr9.slice(1,-2))// [8, 7, 6, 5, 4]
注
如果之只传入一个大于数组长度的参数则返回一个空数组 无论是如何提取数组元素原数组始终保持不变
ES5 中常见的数组常用方法
11.indexOf
接收两个参数要查找的项和可选的表示查找起点位置的索引。
indexOf()从数组的开头位置 0开始向后查找。
lastIndexOf从数组的末尾开始向前查找。
这两个方法都返回要查找的项在数组中的位置或者在没找到的情况下返回-1。在比较第一个参数与数组中的每一项时会使用全等操作符。
-
indexOf用来找到数组中某一项的索引 -
语法
indexOf(你要找的数组中的项)var arr = [1, 2, 3, 4, 5] // 使用 indexOf 超找数组中的某一项 var index = arr.indexOf(3) console.log(index) // 2
-
我们要找的是数组中值为 3 的那一项
-
返回的就是值为 3 的那一项在该数组中的索引
-
-
如果你要找的内容在数组中没有那么就会返回 -1
var arr = [1, 2, 3, 4, 5] // 使用 indexOf 超找数组中的某一项 var index = arr.indexOf(10) console.log(index) // -1
-
你要找的值在数组中不存在那么就会返回 -1
-
12.forEach
-
和
for循环一个作用就是用来遍历数组的 -
这个方法没有返回值。参数都是 function 类型默认有传
-
语法
arr.forEach(function (item, index, arr) {})var arr = [1, 2, 3] // 使用 forEach 遍历数组 arr.forEach(function (item, index, arr) { // item 就是数组中的每一项 // index 就是数组的索引 // arr 就是原始数组 console.log('数组的第 ' + index + ' 项的值是 ' + item + '原始数组是', arr) })-
forEach()的时候传递的那个函数会根据数组的长度执行 -
数组的长度是多少这个函数就会执行多少回
-
13.map ==不改变原数组返回新数组==
-
和
forEach类似只不过可以对数组中的每一项进行操作==返回一个新的数组==var arr = [1, 2, 3] // 使用 map 遍历数组 var newArr = arr.map(function (item, index, arr) { // item 就是数组中的每一项 // index 就是数组的索引 // arr 就是原始数组 return item + 10 }) console.log(newArr) // [11, 12, 13]
14.filter==不改变原数组返回新增数组==
-
和
map的使用方式类似按照我们的条件来筛选数组 -
把原始数组中满足条件的筛选出来组成一个新的数组返回
var arr = [1, 2, 3] // 使用 filter 过滤数组 var newArr = arr.filter(function (item, nindex, arr) { // item 就是数组中的每一项 // index 就是数组的索引 // arr 就是原始数组 return item > 1 }) console.log(newArr) // [2, 3]-
我们设置的条件就是
> 1 -
返回的新数组就会是原始数组中所有
> 1的项
15.every 返回布尔值
判断 是否数组所有的元素都满足条件
let flag = arr.every(function(item,index,arr){ return 条件 }) let res4 = arr4.every(function (v) { return v >= 18 }) console.log(res4); -
16.some 返回布尔值
判断是否数组有一些元素满足条件
let flag = arr.some(function(item,index,arr){
return 条件
})
let res5 = arr4.some(function (v) {
return v >= 18
})
console.log(res5);//true
17.find
查找数组中第一个满足条件的元素
var arr6 = [10, 19, 17, 20];
let res6 = arr6.find(function (v, i) {
return v === 19
})
console.log(res6);
var arr7 = [{ id: 1, name: 'zs' }, { id: 2, name: 'lisi' }];
var obj = arr7.find(function (v) {
return v.id == 2
})
console.log(obj);
console.log(obj.name);
18.findIndex
查找数组中第一个满足条件的元素的下标
var res7 = arr7.findIndex(function (v) {
return v.id == 2
})
console.log(res7);
19.reduce
let res8 = arr8.reduce(function (a, b) {
console.log(a, b);
//a 第一次是 数组中第一个元素
//10+19 =29
// 然后几次 就是前面 数字的和
//a = 29
// b 17
return a + b;
})
console.log(res8);
let res9 = arr8.reduce(function (a, b) {
console.log(a, b);
//a 是累积变量 1000就是累积变量的初始值
// b 是数组的元素
return a + b;
}, 1000)
console.log(res9);
20.fill() es6 新增 ==会改变原数组==
fill()方法能使用特定值填充数组中的一个或多个元素。当只是用一个参数时该方法会用该参数的值填充整个数组。
let arr = [1, 2, 3, cc , 5]; arr.fill(1); console.log(arr);//[1,1,1,1,1];
如果不想改变数组中的所有元素而只是想改变其中一部分那么可以使用可选的起始位置参数与结束位置参数不包括结束位置的那个元素
3 个参数 填充数值起始位置参数结束位置参数不包括结束位置的那个元素
let arr = [1, 2, 3, arr , 5]; arr.fill(1, 2); console.log(arr);//[1,2,1,1,1] arr.fill(0, 1, 3); console.log(arr);//[1,0,0,1,1];
21.includes() es7 新增返回布尔值
includes() 方法用来判断一个数组是否包含一个指定的值如果是返回 true否则 false。
参数有两个其中第一个是必填需要查找的元素值第二个是可选开始查找元素的位置
const array1 = [22, 3, 31, 12, arr ]; const includes = array1.includes(31); console.log(includes); // true const includes1 = array1.includes(31, 3); // 从索引3开始查找31是否存在 console.log(includes1); // false
需要注意的是includes使用===运算符来进行值比较仅有一个例外NaN 被认为与自身相等。
let values = [1, NaN, 2]; console.log(values.indexOf(NaN));//-1 console.log(values.includes(NaN));//true
22.toLocaleString() 和 toString()
将数组转换为字符串
const array1 = [22, 3, 31, 12]; const str = array1.toLocaleString(); const str1 = array1.toString(); console.log(str); // 22,3,31,12 console.log(str1); // 22,3,31,12
23.copyWithin() [es6 新增]==该方法会改变现有数组==
copyWithin() 方法用于从数组的指定位置拷贝元素到数组的另一个指定位置中。
//将数组的前两个元素复制到数组的最后两个位置 let arr = [1, 2, 3, arr , 5]; arr.copyWithin(3, 0); console.log(arr);//[1,2,3,1,2]
默认情况下copyWithin()方法总是会一直复制到数组末尾不过你还可以提供一个可选参数来限制到底有多少元素会被覆盖。这第三个参数指定了复制停止的位置不包含该位置本身。
let arr = [1, 2, 3, arr , 5, 9, 17]; //从索引3的位置开始粘贴 //从索引0的位置开始复制 //遇到索引3时停止复制 arr.copyWithin(3, 0, 3); console.log(arr);//[1,2,3,1,2,3,17]
24.flat() 和 flatMap() es6 新增==该方法返回一个新数组不改变原数组。==
flat() 方法会按照一个可指定的深度递归遍历数组并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。
该方法返回一个新数组对原数据没有影响。
参数 指定要提取嵌套数组的结构深度默认值为 1。
const arr1 = [0, 1, 2, [3, 4]]; console.log(arr1.flat()); // expected output: [0, 1, 2, 3, 4] const arr2 = [0, 1, 2, [[[3, 4]]]]; console.log(arr2.flat(2)); // expected output: [0, 1, 2, [3, 4]] //使用 Infinity可展开任意深度的嵌套数组 var arr4 = [1, 2, [3, 4, [5, 6, [7, 8, [9, 10]]]]]; arr4.flat(Infinity); // [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] // 扁平化数组空项,如果原数组有空位flat()方法会跳过空位 var arr4 = [1, 2, , 4, 5]; arr4.flat(); // [1, 2, 4, 5]
flatMap()方法对原数组的每个成员执行一个函数相当于执行Array.prototype.map(),然后对返回值组成的数组执行flat()方法。
该方法返回一个新数组不改变原数组。
// 相当于 [[2, 4], [3, 6], [4, 8]].flat() [2, 3, 4].flatMap((x) => [x, x * 2]) // [2, 4, 3, 6, 4, 8]
25、 entries(),keys() 和 values() 【ES6】
entries()keys()和values() —— 用于遍历数组。它们都返回一个遍历器对象可以用for...of循环进行遍历
区别是keys()是对键名的遍历、values()是对键值的遍历entries()是对键值对的遍历
for (let index of [ a , b ].keys()) {
console.log(index);
}
// 0
// 1
for (let elem of [ a , b ].values()) {
console.log(elem);
}
// a
// b
for (let [index, elem] of [ a , b ].entries()) {
console.log(index, elem);
}
// 0 "a"
// 1 "b"
如果不使用for...of循环可以手动调用遍历器对象的next方法进行遍历。
let letter = [ a , b , c ]; let entries = letter.entries(); console.log(entries.next().value); // [0, a ] console.log(entries.next().value); // [1, b ] console.log(entries.next().value); // [2, c ]
JS 如何终止 forEach 循环 break 报错return 跳不出循环
-
终止 forEach 可以使用 try catch 内部抛出错误catch 捕获错误。
let arr = [1, 2, 3] try { arr.forEach(item => { if (item === 2) { throw('循环终止') } console.log(item) }) } catch(e) { console.log('e: ', e) } 复制代码
当然我们大可以用其他方法代替
-
Array.prototype.some
当 return true 的时候会终止遍历
-
Array.prototype.every
当 return false 的时候会终止遍历
JS的节流、防抖及使用场景
结合应用场景
-
debounce
-
search搜索联想用户在不断输入值时用防抖来节约请求资源。
-
window触发resize的时候不断的调整浏览器窗口大小会不断的触发这个事件用防抖来让其只触发一次
-
-
throttle
-
鼠标不断点击触发mousedown(单位时间内只触发一次)
-
监听滚动事件比如是否滑到底部自动加载更多用throttle来判断
-
JS 运行机制-EventLoop事件循环 javascript 是单线程的 JavaScript语言的一大特点就是单线程也就是说同一个时间只能做一件事。那么为什么JavaScript不能有多个线程呢这样能提高效率啊。
JavaScript的单线程与它的用途有关。作为浏览器脚本语言JavaScript的主要用途是与用户互动以及操作DOM。这决定了它只能是单线程否则会带来很复杂的同步问题。比如假定JavaScript同时有两个线程一个线程在某个DOM节点上添加内容另一个线程删除了这个节点这时浏览器应该以哪个线程为准
所以为了避免复杂性从一诞生JavaScript就是单线程。
为了利用多核CPU的计算能力HTML5提出Web Worker标准允许JavaScript脚本创建多个线程但是子线程完 全受主线程控制且不得操作DOM。所以这个新标准并没有改变JavaScript单线程的本质。
主线程和任务队列 单线程就意味着所有任务需要排队。所有任务可以分成两种一种是同步任务synchronous另一种是异步任务asynchronous。
同步任务在主线程上排队执行的任务只有前一个任务执行完毕才能执行后一个任务
异步任务不进入主线程、而进入"任务队列"task queue的任务只有"任务队列"通知主线程某个异步任务可以执行了该任务才会进入主线程执行。
具体来说
-
所有同步任务都在主线程上执行形成一个执行栈execution context stack。
-
主线程之外还存在一个"任务队列"task queue。只要异步任务有了运行结果就在"任务队列"之中放置一个事件
-
一旦"执行栈"中的所有同步任务执行完毕系统就会读取"任务队列"根据顺序循环调用异步任务进入执行栈开始执行直到所有任务队列异步任务执行完
-
另外任务队列中的每一个事件都是一个宏任务执行栈执行的过程中也会有微任务他们的执行顺序是见下面总结
下图就是主线程和任务队列的示意图
主线程从"任务队列"中读取事件这个过程是循环不断的所以整个的这种运行机制又称为Event Loop事件循环。 只要主线程空了就会去读取"任务队列"这就是JavaScript的运行机制。
JS中Map和ForEach的区别
区别
forEach()方法不会返回执行结果而是undefined。也就是说forEach()会修改原来的数组。而map()方法会得到一个新的数组并返回。
css实现0.5px线
使用scale缩放
<style>
.hr.scale-half {
height: 1px;
transform: scaleY(0.5);
}
</style>
<p>1px + scaleY(0.5)</p>
<div class="hr scale-half"></div>
css实现三角形
.triangle {
width: 0; height: 0;
border: 100px solid; border-color: orangered skyblue gold yellowgreen;
}
localStorage、sessionStorage、cookie区别
一、区别
-
localStorage: localStorage 的生命周期是永久的关闭页面或浏览器之后 localStorage 中的数据也不会消失。localStorage 除非主动删除数据否则数据永远不会消失
-
sessionStorage: sessionStorage 的生命周期是仅在当前会话下有效。sessionStorage 引入了一个“浏览器窗口”的概念sessionStorage 是在同源的窗口中始终存在的数据。只要这个浏览器窗口没有关闭即使刷新页面或者进入同源另一个页面数据依然存在。但是 sessionStorage 在关闭了浏览器窗口后就会被销毁。同时独立的打开同一个窗口同一个页面sessionStorage 也是不一样的
-
cookie: cookie生命期为只在设置的cookie过期时间之前一直有效即使窗口或浏览器关闭。 存放数据大小为4K左右, 有个数限制各浏览器不同一般不能超过20个。缺点是不能储存大数据且不易读取
正文 Cookie 数据生命性一般由服务器生成可设置失效时间。(也可以由客户端生成) 存放数据大小 一般大小不能超过4KB 作用域Cookie的作用域仅仅由domain和path决定与协议和端口无关 与服务器端通信浏览器每次向服务器发出请求就会自动把当前域名下所有未过期的Cookie一同发送到服务器会带来额外的性能开销 易用性缺乏数据操作接口(document.cookie)。 适用场景只有那些每次请求都需要让服务器知道的信息保持用户的登录状态才应该放在 Cookie 里面。 localStorage 数据生命性存储在 localStorage 的数据可以长期保留 存放数据大小 一般为5MB 作用域localStorage的作用域是限定在文档源级别的。文档源通过协议、主机名以及端口三者来确定。 与服务器端通信不会自动把数据发给服务器仅在本地保存。 易用性有很多易用的数据操作接口比如setItem、getItem、removeItem 适用场景常用于长期登录+判断用户是否已登录适合长期保存在本地的数据 sessionStorage 数据生命性sessionStorage 里面的数据在页面会话结束(关闭对应浏览器标签或窗口)时会被清除。 存放数据大小 一般为5MB 作用域sessionStorage的作用域也是限定在文档源级别。但需要注意的是如果相同文档源的页面渲染在不同的标签中sessionStorage的数据是无法共享的。 与服务器端通信不会自动把数据发给服务器仅在本地保存。 易用性有很多易用的数据操作接口比如setItem、getItem、removeItem 适用场景敏感账号一次性登录 Web Storage localStorage、sessionStorage的优势 存储空间更大 更节省流量没有额外性能开销 获取数据从本地获取会比服务器端获取快得多所以显示更快 IndexedDB补充内容 IndexedDB 就是浏览器提供的本地数据库它可以被网页脚本创建和操作。
IndexedDB 不属于关系型数据库不支持 SQL 查询语句更接近 NoSQL 数据库。
IndexedDB储存空间大,一般来说不少于 250MB甚至没有上限。
IndexedDB不仅可以储存字符串还可以储存二进制数据ArrayBuffer 对象和 Blob 对象。
提供查找接口还能建立索引
异步操作IndexedDB 操作时不会锁死浏览器用户依然可以进行其他操作这与 LocalStorage 形成对比后者的操作是同步的。异步设计是为了防止大量数据的读写拖慢网页的表现。
JS中find和filter的区别
find的用法
通俗的讲find是找到数组中符合条件的第一项看下面代码
filter的用法
filter的功能也是过滤不过是在遍历数组后拿到所有符合条件的item项
nuxt上线
.nuxt文件、nuxt.config.js、package.json、static
原生js怎样获取参数
window.location.search
在JavaScript中可以使用window.location对象来获取地址栏传递的参数。具体可以通过以下几种方式获取
-
使用
window.location.search获取查询字符串参数
javascriptCopy code// 假设当前页面的URL为http://example.com?param1=value1¶m2=value2
const queryString = window.location.search; // 获取查询字符串部分即 "?param1=value1¶m2=value2"
// 使用URLSearchParams解析查询字符串
const params = new URLSearchParams(queryString);
// 获取特定参数的值
const param1Value = params.get('param1'); // "value1"
const param2Value = params.get('param2'); // "value2"
-
使用
window.location.href获取完整URL然后通过字符串操作截取参数
javascriptCopy code// 假设当前页面的URL为http://example.com?param1=value1¶m2=value2
const url = window.location.href; // 获取完整URL
// 截取参数部分
const queryString = url.split('?')[1];
// 使用URLSearchParams解析查询字符串
const params = new URLSearchParams(queryString);
// 获取特定参数的值
const param1Value = params.get('param1'); // "value1"
const param2Value = params.get('param2'); // "value2"
请注意URLSearchParams是ES6引入的新特性用于处理URL查询字符串。在使用前请确保浏览器的兼容性。
使用以上方法您可以在JavaScript中获取地址栏传递的参数。首先获取完整URL或查询字符串然后使用适当的方式解析和提取参数的值。
ts接口定义类型怎样使用里面某一个类型的值
在TypeScript中可以使用接口定义类型并且可以通过类型注解将接口中的某个属性的类型应用到其他变量或函数中。
以下是一个示例展示了如何使用接口中的某个类型的值
typescriptCopy codeinterface Person {
name: string;
age: number;
}
// 定义一个接口类型的变量
const person: Person = {
name: 'John',
age: 25,
};
// 使用接口中的某个类型的值
let personName: string = person.name;
let personAge: number = person.age;
console.log(personName); // 输出 "John"
console.log(personAge); // 输出 25
在这个示例中我们定义了一个名为Person的接口该接口包含name和age属性的类型定义。然后我们创建了一个person变量该变量符合Person接口的定义。
接下来我们使用person对象中的name和age属性的类型注解将其应用到personName和personAge变量上。这样personName的类型就是stringpersonAge的类型就是number并且它们分别被赋值为person对象中对应的属性值。
通过这种方式我们可以在TypeScript中定义接口并利用接口中的某个类型的值以便在其他变量或函数中使用相应的类型
js存储数组方式
数组的存储结构 1.基本数据类型变量都存储在栈区域 2.引用变量存储在堆区域如对象。 3.复杂数据类型是存储在堆区域赋值时是将对象在堆区域的地址赋值给变量 4.- 因为复杂数据类型变量存储的是地址真实内容在 堆空间 内存储
-
所以赋值的时候相当于把 obj 存储的那个地址复制了一份给到了 obj1变量
现在 obj 和 obj1 两个变量存储的地址一样指向一个内存空间
-
所以使用 obj1 这个变量修改空间内的内容obj 指向的空间也会跟着改变了
vue2为啥不对数组进行劫持呢
Vue.js 2.x中的响应式系统使用了一种称为"劫持"或"代理"的技术来实现对对象属性的监测和响应。然而Vue.js 2.x没有直接对数组进行劫持而是通过重写数组的原型方法来实现对数组的响应式支持。
Vue.js之所以选择不直接对数组进行劫持是因为数组的变异方法例如push、pop、splice等是无法通过普通的对象属性劫持来监听的。如果Vue.js直接对数组进行劫持那么只有通过Vue提供的特殊方法才能保证响应式更新而不能直接使用JavaScript原生的数组方法。这样会导致语法和用法上的不一致增加了学习和使用的复杂性。
相反Vue.js 2.x通过重写数组的原型方法例如push、pop、splice等来捕获数组的变化并触发响应式更新。这意味着当你使用这些变异方法修改数组时Vue.js能够监听到这些变化并更新相关的视图。
总结一下Vue.js 2.x选择不对数组进行直接劫持的原因是为了保持语法和用法上的一致性避免增加复杂性并通过重写数组的原型方法来实现对数组的响应式支持。
浏览输入URL地址会进过那些流程
当你在浏览器中输入URL地址并按下回车键时以下是浏览器的一般流程
-
URL解析浏览器会解析输入的URL提取出协议如HTTP、HTTPS、主机名例如www.example.com和路径如/page等信息。
-
DNS解析浏览器将主机名发送给域名系统DNS服务器以获取与主机名对应的IP地址。这个过程涉及到查询DNS缓存、本地主机文件和递归查询等步骤最终得到主机的IP地址。
-
建立TCP连接使用获取到的IP地址浏览器会与服务器建立TCP连接。这个过程涉及到TCP的三次握手确保浏览器和服务器之间建立可靠的连接。
-
发起HTTP请求建立TCP连接后浏览器会向服务器发送HTTP请求。这个请求包括请求方法如GET、POST、请求头包含一些额外的信息如用户代理、Cookie等以及可能的请求体对于POST请求。
-
服务器处理请求服务器接收到浏览器发送的请求后根据请求的路径和其他信息处理请求并生成响应。
-
接收响应浏览器接收到服务器发送的响应响应包括状态码表示请求成功、失败或其他状态、响应头包含一些元数据如内容类型、缓存控制等和响应体实际的响应数据。
-
渲染页面如果响应的内容是HTML浏览器会解析HTML、构建DOM树和CSSOM树然后将它们合并为渲染树最终绘制到屏幕上。
-
关闭连接页面渲染完成后浏览器会关闭与服务器的TCP连接释放资源。
需要注意的是上述流程是一个简化的描述实际上还包括其他步骤和优化。例如浏览器可能会使用HTTP持久连接来重复使用已经建立的连接减少TCP握手的开销还有缓存机制、安全验证等等。但总体来说上述流程涵盖了从输入URL到页面展示的主要步骤。
js数组方法怎样把二位数组变成一维数组
JavaScript提供了多种方法将二维数组转换为一维数组。以下是几种常见的方法
-
使用
concat()方法和扩展运算符spread operator
javascriptCopy codeconst twoDimensionalArray = [[1, 2], [3, 4], [5, 6]]; const flattenedArray = [].concat(...twoDimensionalArray); console.log(flattenedArray);
输出
javascriptCopy code [1, 2, 3, 4, 5, 6]
-
使用
reduce()方法
javascriptCopy codeconst twoDimensionalArray = [[1, 2], [3, 4], [5, 6]]; const flattenedArray = twoDimensionalArray.reduce((result, currentArray) => result.concat(currentArray), []); console.log(flattenedArray);
输出
javascriptCopy code [1, 2, 3, 4, 5, 6]
-
使用
flatMap()方法适用于ES2019及以上版本
javascriptCopy codeconst twoDimensionalArray = [[1, 2], [3, 4], [5, 6]]; const flattenedArray = twoDimensionalArray.flatMap((currentArray) => currentArray); console.log(flattenedArray);
输出
javascriptCopy code [1, 2, 3, 4, 5, 6]
这些方法都能将二维数组中的所有元素合并到一个新的一维数组中。你可以根据自己的需求选择适合的方法来转换二维数组。
1.setup函数怎么实现
import unittest
class TestMyFunction(unittest.TestCase): def setUp(self): # 在这里设置你的测试环境 # 例如初始化一个数据库连接或者创建一个临时文件等 pass
def tearDown(self): # 在这里清理你的测试环境 # 例如关闭数据库连接删除临时文件等 pass def test_my_function(self): # 在这里编写你的测试代码 pass
if name == 'main': unittest.main()
2.websocket会不会跨域
WebSocket本身是不存在跨域问题的因此可以利用WebSocket来进行非同源之间的通信。这意味着你可以自由地创建WebSocket实例并通过open方法发送数据到后台同时也可以利用message方法接收后台传来的数据。
然而在实践中你可能仍会碰到一些跨域问题。例如如果你使用socket.io库它只会使用WebSocket传输协议进行连接从而避免一些跨域问题。在前端解决io访问跨域问题可以通过一些配置和选项来实现。
3.怎么封装aixos
要封装axios首先需要安装axios可以通过npm install axios --save命令进行安装。然后在项目中创建一个http.js文件在这个文件中进行二次封装。
封装的主要目的是为了使axios的使用更加方便和高效。以下是一些常见的封装方法
基本配置可以配置默认的请求地址、超时时间等。
请求拦截可以在发送请求之前做一些处理例如添加token到header中等。
响应拦截可以对响应数据进行处理例如统一处理错误信息等。
封装实例可以将axios实例化并在需要的地方引入和使用。
创建API可以根据项目需求创建对应的API如get、post、put、delete等并保持参数格式一致。
4.pinia怎么用
Pinia是一个Vue的状态管理库相当于Vuex的替代品主要用来实现跨组件或页面的状态管理。下面是如何在项目中使用Pinia的步骤
安装Pinia可以通过npm install pinia命令进行安装。
引入Pinia在项目的main.js文件中引入Pinia并创建容器然后挂载到根实例上。例如import { createPinia } from 'pinia' const pinia = createPinia()。
创建Store在项目中创建一个store文件夹然后在该文件夹中新建一个文件例如user.ts用于定义仓库Store。
修改Vue应用在使用app.use(pinia)后你的所有Vue组件现在都可以访问到pinia提供的功能
5.怎么首页白屏优化
减少HTTP请求合并CSS和JavaScript文件使用CSS Sprites等技术来减少请求的数量。 使用CDN加速将静态资源部署到CDN上以加速资源的加载速度。 开启GZIP压缩启用服务器端的GZIP压缩可以减少文件大小从而加快加载速度。 优化图片通过压缩图片大小、选择合适的图片格式等方式来减少图片的加载时间。 服务端渲染在服务端将渲染逻辑处理好然后将处理好的HTML直接返回给前端展示这样既可以解决白屏问题也可以提高SEO效果。
6.vue2和vue3中有哪些优点和缺点
Vue2的优点主要体现在以下几个方面首先Vue2简单易学上手成本低使得开发者能够快速构建用户界面。其次Vue2支持渐进式框架可以适用于小型到大型的项目。最后双向数据绑定和模板语法使Vue2在处理复杂场景时渲染效率较高。然而Vue2也存在一些不足之处例如在处理大型应用时其性能和体积控制不如React好。
Vue3则在许多方面进行了优化和改进。首先Vue3的diff算法的优化使得其在渲染大量静态节点时更加高效。此外Vue3的速度更快相比Vue2来说重写了虚拟 Dom 实现编译模板的优化更高效的组件初始化update性能提高1.3~2倍SSR速度提高了2~3倍。同时通过webpack的tree-shaking功能Vue3可以将无用模块“剪辑”仅打包需要的模块这样既可以帮助开发人员实现更多其他的功能而不必担忧整体体积过大也对使用者有益因为打包出来的包体积变小了。另外