

SpringBoot核心内容梳理
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.SpringBoot是什么?
Spring Boot是一个基于Spring框架的快速开发应用程序的工具。它简化了Spring应用程序的创建和开发过程使开发人员能够更快速地创建独立的、生产就绪的Spring应用程序。它采用了“约定优于配置”的原则尽可能地减少开发人员需要进行手动配置的步骤提供了自动配置和快速开发的功能从而让开发人员可以更加专注于业务逻辑的开发。
Spring Boot包含许多开箱即用的特性如嵌入式Web服务器、自动配置、约定优于配置、命令行界面等。这些特性可以使开发人员更加容易地开发和部署应用程序并且可以与其他Spring框架的组件如Spring Data、Spring Security等进行无缝集成。
总之Spring Boot为Spring应用程序的开发提供了更加简单、快速、灵活的方式使开发人员能够更快速地创建和部署高质量的应用程序。
2.SpringBoot的优缺点
- 优点
1、创建独立Spring应用
2、内嵌Web服务器
3、自动starter依赖简化构建配置
4、自动配置Spring以及第三方功能
5、提供生产级别的监控、健康检查以及外部优化配置
6、无代码生成、无需编写XML
一句话概括
SpringBoot是整合Spring技术栈的一站式框架
SpringBoot是简化Spring技术栈的快速开发脚手架
- 缺点
1、迭代快
2、封装太深内部原理复杂不容易精通
3. 运行SpringBoot项目的方式
- 1.直接启动
java -jar application.jar
- 2.解包运行
通过将application.jar解压后, 得到如下结构:

BOOT-INF/ 存放class文件和依赖包
META-INF/ maven信息、程序启动入口和ClassPath信息
org/ Spring Boot提供的加载器、和启动类
查看META-INF/MANIFEST.MF,之后运行
java org.springframework.boot.loader.JarLauncher
-
3.自定义运行
在复制BOOT-INF/lib至BOOT-INF/classes中, 编写脚本命令:

这样这个文件夹就是可以单独启动的服务了。 -
4.使用maven插件
4.SpringBoot常用的注解
-
-
@SpringBootApplication
这个注解是Spring Boot最核心的注解用在 Spring Boot的主类上标识这是一个 Spring Boot 应用用来开启 Spring Boot 的各项能力。实际上这个注解是@Configuration,@EnableAutoConfiguration,@ComponentScan三个注解的组合。
-
-
-
@EnableAutoConfiguration
允许 Spring Boot 自动配置注解开启这个注解之后Spring Boot 就能根据当前类路径下的包或者类来配置 Spring Bean。
如当前类路径下有 Mybatis 这个 JAR 包MybatisAutoConfiguration 注解就能根据相关参数来配置 Mybatis 的各个 Spring Bean。@EnableAutoConfiguration实现的关键在于引入了AutoConfigurationImportSelector其核心逻辑为selectImports方法逻辑大致如下
从配置文件META-INF/spring.factories加载所有可能用到的自动配置类
去重并将exclude和excludeName属性携带的类排除
过滤将满足条件@Conditional的自动配置类返回
-
-
-
@Configuration
用于定义配置类指出该类是 Bean 配置的信息源相当于传统的xml配置文件一般加在主类上。如果有些第三方库需要用到xml文件建议仍然通过@Configuration类作为项目的配置主类——可以使用@ImportResource注解加载xml配置文件。
-
-
-
@Autowired
按类型注入。
默认属性required= true当不能确定 Spring 容器中一定拥有某个类的Bean 时 可以在需要自动注入该类 Bean 的地方可以使用 @Autowired(required = false) 这等于告诉Spring在找不到匹配Bean时也不抛出BeanCreationException 异常。@Autowired 和 @Qualifier 结合使用时自动注入的策略就从 byType 转变byName 。
@Autowired可以对成员变量、方法以及构造函数进行注释而 @Qualifier 的标注对象是成员变量、方法入参、构造函数入参。正是由于注释对象的不同所以 Spring 不将 @Autowired 和 @Qualifier 统一成一个注释类。@Autowired @Qualifier("userService") UserService userService; @Autowired @Qualifier("userService1") UserService userService1; //按名称装配Bean,与@Autowired组合使用解决按类型匹配找到多个Bean问题。
-
-
- @Qualifier
当有多个同一类型的Bean时可以用@Qualifier(“name”)来指定。与@Autowired配合使用
- @Qualifier
-
- @Controller
-
- @RestController
用于标注控制层组件表示这是个控制器Bean并且是将函数的返回值直接填入HTTP响应体中,是REST风格的控制器它是@Controller和@ResponseBody的合集。
- @RestController
-
-
@RequestMapping
RequestMapping是一个用来处理请求地址映射的注解提供路由信息负责URL到Controller中的具体函数的映射可用于类或方法上。用于类上表示类中的所有响应请求的方法都是以该地址作为父路径。@RequestMapping(method = RequestMethod.GET) 省略可写成 @GetMapping
@RequestMapping(method = RequestMethod.POST) 省略可写成 @PostMapping
@RequestMapping(method = RequestMethod.PUT) 省略可写成 @PutMapping
@RequestMapping(method = RequestMethod.DELETE) 省略可写成 @DeleteMapping
-
-
-
@ComponentScan
组件扫描。让Spring Boot扫描到Configuration类并把它加入到程序上下文。@ComponentScan注解默认就会装配标识了@Controller@Service@Repository@Component注解的类到Spring容器中。
-
-
- @Service
-
- @ResponseBody
-
- @RequestBody
-
- @Bean
-
-
@Resource
@Resource(name=“name”,type=“type”)
@Resource和@Autowired注解都是用来实现依赖注入的。
只是@AutoWried按by type自动注入而@Resource默认按byName自动注入。
@Resource是JSR-250提供的默认按名称装配,当找不到名称匹配的Bean再按类型装配。
可以写在成员属性上,或写在setter方法上。
可以通过@Resource(name=“beanName”) 指定被注入的Bean的名称, 要是未指定name属性默认使用成员属性的变量名一般不用写name属性。
@Resource(name=“beanName”)指定了name属性按名称注入但没找到bean, 就不会再按类型装配了。
-
-
- @RequestParam
-
- @PathVariable
-
- @Profiles
Spring Profiles提供了一种隔离应用程序配置的方式并让这些配置只能在特定的环境下生效。
通过@Profile注解匹配active参数动态加载内部配置 。
@Profile注解使用范围@Configration 和 @Component 注解的类及其方法其中包括继承了@Component的注解@Service、@Controller、@Repository等
我们除application.properties外还可以根据命名约定 命名格式application-{profile}.properties来配置如果active赋予的参数没有与使用该命名约定格式文件相匹配的话app则会默认从名为application-default.properties 的配置文件加载配置。
如spring.profiles.active=hello-world,sender,dev 有三个参数其中 dev 正好匹配下面配置中的application-dev.properties 配置文件所以app启动时项目会先从application-dev.properties加载配置再从application.properties配置文件加载配置如果有重复的配置则会以application.properties的配置为准
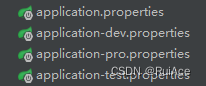
如此我们就不用为了不同的运行环境而去更改大量的环境配置了此处dev、pro、test分别为开发、生产、测试环境配置
- @Profiles
-
- @ConfigurationProperties
Spring Boot可使用注解的方式将自定义的properties文件映射到实体Bean中比如config.properties文件。
- @ConfigurationProperties
-
- @EnablCaching
-
- @Suppresswarnings
-
-
@Transactional
@Transactional 是声明式事务管理 编程中使用的注解
添加位置:接口实现类或接口实现方法上而不是接口类中。
访问权限public 的方法才起作用。@Transactional 注解应该只被应用到 public 方法上这是由 Spring AOP 的本质决定的。
系统设计将标签放置在需要进行事务管理的方法上而不是放在所有接口实现类上只读的接口就不需要事务管理由于配置了@Transactional就需要AOP拦截及事务的处理可能影响系统性能。注意: 错误使用
接口中A、B两个方法A无@Transactional标签B有上层通过A间接调用B此时事务不生效。
接口中异常运行时异常被捕获而没有被抛出。默认配置下Spring 只有在抛出的异常为运行时 unchecked 异常时才回滚该事务也就是抛出的异常为RuntimeException 的子类(Errors也会导致事务回滚)而抛出 checked 异常则不会导致事务回滚 。可通过 @Transactional rollbackFor进行配置。
多线程下事务管理因为线程不属于 Spring 托管故线程不能够默认使用 Spring 的事务, 也不能获取Spring 注入的 Bean 。在被 Spring 声明式事务管理的方法内开启多线程多线程内的方法不被事务控制。一个使用了@Transactional 的方法如果方法内包含多线程的使用方法内部出现异常不会回滚线程中调用方法的事务。
-
-
- @Value
-
- @Component
-
- @Scope
-
- @PostConstruct
-
- @PreDestroy
-
- @Repository
5.什么是Spring Boot Starter?
Starters可以理解为启动器它包含了一系列可以集成到应用里面的依赖包可以一站式集成 Spring和其他技术而不需要到处找示例代码和依赖包。Spring Boot Starter的工作原理是Spring Boot在启动时扫描项目所依赖的JAR包寻找包含spring.factories文件的JAR包根据spring.factories配置加载AutoConfigure类根据@Conditional注解的条件进行自动配置并将Bean注入Spring Context.
6.介绍几种常见的Starter?
Spring Boot常用的starter有很多以下是一些常见的starter
-
- spring-boot-starter-web用于构建Web应用程序的starter包括Spring MVC和Tomcat服务器。它提供了处理HTTP请求和响应的功能。
-
- spring-boot-starter-data-jpa用于与关系型数据库进行交互的starter包括Spring Data JPA和Hibernate。它简化了与数据库的交互提供了常见的CRUD操作。
-
- spring-boot-starter-security用于添加安全性功能的starter包括Spring Security和OAuth2。它提供了身份验证、授权和安全配置的功能。
-
- spring-boot-starter-test用于编写单元测试和集成测试的starter包括JUnit和Spring Test。它提供了测试框架和工具方便进行单元测试和集成测试。
-
- spring-boot-starter-actuator用于监控和管理应用程序的starter包括健康检查、指标收集和远程管理功能。它提供了监控应用程序运行状态的功能。
-
- spring-boot-starter-cache用于添加缓存支持的starter包括Spring Cache和Ehcache。它提供了缓存数据的功能提高应用程序的性能。
-
- spring-boot-starter-data-redis用于与Redis数据库进行交互的starter包括Spring Data Redis。它简化了与Redis的交互提供了常见的操作方法。
-
- spring-boot-starter-mail用于发送电子邮件的starter包括JavaMail和Spring Mail。它提供了发送电子邮件的功能。
-
- spring-boot-starter-log4j2用于使用Log4j2进行日志记录的starter。它提供了日志记录的功能方便调试和错误追踪。
-
- spring-boot-starter-thymeleaf用于使用Thymeleaf模板引擎的starter。它提供了使用Thymeleaf进行页面渲染的功能。
这些starter可以根据应用程序的需求选择使用它们提供了各种功能和便利简化了应用程序的开发和配置过程。
7.SpringBoot的run()方法做了什么事情?
参考:SpringApplication详解(run执行启动)
8.@ComponentScan注解是干什么的
1、@ComponentScan注解的作用
@ComponentScan注解一般和@Configuration注解一起使用主要的作用就是定义包扫描的规则然后根据定义的规则找出哪些需类需要自动装配到Spring的Bean容器中然后交由Spring进行统一管理。
说明针对标注了@Controller、@Service、@Repository、@Component 的类都可以别Spring扫描到。
2、@ComponentScan注解属性介绍
2.1 value: 指定要扫描的包路径
2.2 excludeFilters排除规则: excludeFilters=Filter[] 指定包扫描的时候根据规则指定要排除的组件
2.3 includeFilters包含规则: includeFilters =Filter[] 指定包扫描的时候根据规则指定要包含的组件.
注意:要设置useDefaultFilters = false系统默认为true需要手动设置 includeFilters包含过滤规则才会生效。
2.4 FilterType属性
FilterType.ANNOTATION按照注解过滤
FilterType.ASSIGNABLE_TYPE按照给定的类型,指定具体的类子类也会被扫描到
FilterType.ASPECTJ使用ASPECTJ表达式
FilterType.REGEX正则
FilterType.CUSTOM自定义规则
useDefaultFilters: 配置是否开启可以对加@Component@Repository@Service@Controller注解的类进行检测 针对Java8 语法可以指定多个@ComponentScanJava8以下可以用 @ComponentScans() 配置多个规则
9.@EnableAutoConfiguration注解的作用
@EnableAutoConfiguration是Spring Boot中的注解用于启用自动配置机制。该注解的作用是根据应用程序的类路径和依赖关系自动配置和装配Spring框架和第三方库的功能。
具体来说@EnableAutoConfiguration注解的作用包括以下几个方面
自动装配通过@EnableAutoConfiguration注解Spring Boot会根据项目的依赖关系和类路径自动进行配置和装配。它会根据类路径下的META-INF/spring.factories文件中的配置加载各种自动配置类。这些自动配置类会根据当前项目的依赖和配置自动配置相应的Spring Bean、设置、过滤器、拦截器等。
条件化配置自动配置机制是通过条件化配置实现的。每个自动配置类都包含了一组条件只有当这些条件满足时相关的配置才会被应用。这样可以根据项目的环境、依赖和配置情况动态地选择需要的配置。条件化配置是Spring Boot自动配置的一个重要特性它使得应用程序可以根据不同的情况自动适配配置。
配置加载顺序自动配置类的加载顺序是根据类路径中META-INF/spring.factories文件中的配置顺序来确定的。根据约定这些自动配置类应该按照优先级的顺序列出以确保高优先级的配置先被应用。通过自动配置的加载顺序可以确保配置的正确性和一致性。
自定义配置通过在应用程序中添加自定义的配置类可以覆盖和扩展自动配置机制。自定义配置类可以通过添加@Configuration注解来实现并且会在自动配置之前加载。这样可以在保留自动配置的基础上根据项目的需求进行定制和调整。
总之@EnableAutoConfiguration注解是Spring Boot自动配置机制的入口点它根据项目的类路径和依赖关系自动加载和应用适当的配置。通过@EnableAutoConfiguration注解开发人员可以方便地利用Spring Boot的自动配置功能减少配置的工作量提高开发效率。
10.@Import注解的三种用法
@Import是一个非常有用的注解它可以通过配置来控制是否注入该Bean也可以通过条件来控制注入哪些Bean到Spring容器中。
比如我们熟悉的@EnableAsync 、@EnableCaching、@EnableScheduling等等统一采用的都是借助@Import注解来实现的。
一、引入普通类
有个用户类如下
public class Test implements InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("注入成功");
}
}
那么如何通过@Import注入容器呢
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
@Import({Test.class})
@Configuration
public class Myclass2 {
}
当在@Configuration标注的类上使用@Import引入了一个类后就会把该类注入容器中。
当然除了@Configuration 比如@Component、@Service等一样也可以。
二、引入ImportSelector的实现类
1、静态import场景注入已知的类
我们先将上面的示例改造下
自定义MyImportSelector实现ImportSelector接口重写selectImports方法
public class MyImportSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata annotationMetadata) {
return new String[]{"com.example.eureka.config.Test"};
}
}
然后在配置类引用
package com.example.eureka.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
@Import({MyImportSelector.class})
@Configuration
public class Myclass2 {
}
2、动态import场景注入指定条件的类
我们来思考一种场景就是你想通过开关来控制是否注入该Bean或者说通过配置来控制注入哪些Bean这个时候就有了ImportSelector的用武之地了。
我们来举个例子通过ImportSelector的使用实现条件选择是注入本地缓存还是Redis缓存。
1)、定义缓存接口和实现类
package com.example.eureka.cache;
public interface CacheService {
void setData(String key);
}
本地缓存 实现类
package com.example.eureka.cache.impl;
import com.example.eureka.cache.CacheService;
public class LocalServicempl implements CacheService {
@Override
public void setData(String key) {
System.out.println("本地存储数据成功key="+key);
}
}
redis缓存实现类
public class RedisServicempl implements CacheService {
@Override
public void setData(String key) {
System.out.println("redis存储数据成功 key= " + key);
}
}
2)、定义ImportSelector实现类
以下代码中根据EnableMyCache注解中的不同值来切换缓存的实现类再spring中的注册。
public class MyCacheSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata annotationMetadata) {
Map<String, Object> annotationAttributes = annotationMetadata.getAnnotationAttributes(EnableMyCache.class.getName());
CacheType type = (CacheType)annotationAttributes.get("type");
switch (type){
case LOCAL:
return new String[]{
LocalServicempl.class.getName()
};
case REDIS:
return new String[]{
RedisServiceImpl.class.getName()
};
default:
throw new RuntimeException();
}
}
}
3)、定义注解
package com.example.eureka.cache.Annotion;
import com.example.eureka.cache.Enums.CacheType;
import org.springframework.context.annotation.Import;
import java.lang.annotation.*;
@Target(ElementType.TYPE)
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Import({com.example.eureka.cache.MyCacheSelector.class})
public @interface EnableMyCache {
CacheType type() default CacheType.REDIS;
}
4)定义枚举
package com.example.eureka.cache.Enums;
public enum CacheType {
LOCAL,REDIS;
}
三、引入ImportBeanDefinitionRegister的实现类
当配置类实现了 ImportBeanDefinitionRegistrar 接口你就可以自定义往容器中注册想注入的Bean。
这个接口相比与 ImportSelector 接口的主要区别就是ImportSelector接口是返回一个类你不能对这个类进行任何操作但是 ImportBeanDefinitionRegistrar 是可以自己注入 BeanDefinition可以添加属性之类的。
1.定义实体
public class UserConfig implements InitializingBean {
private String username;
private String password;
//...... get set
@Override
public void afterPropertiesSet() throws Exception {
System.out.println(this.username+"-"+this.password);
}
}
2.我们通过实现ImportBeanDefinitionRegistrar的方式来完成注入。
package com.example.eureka.config;
import org.springframework.beans.factory.support.AbstractBeanDefinition;
import org.springframework.beans.factory.support.BeanDefinitionBuilder;
import org.springframework.beans.factory.support.BeanDefinitionRegistry;
import org.springframework.beans.factory.support.BeanNameGenerator;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.context.annotation.ImportBeanDefinitionRegistrar;
import org.springframework.core.type.AnnotationMetadata;
@Configuration
@Import({MyImportBean.class})
public class MyImportBean implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry, BeanNameGenerator importBeanNameGenerator) {
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.rootBeanDefinition(UserConfig.class).addPropertyValue("username", "fengmin").addPropertyValue("password", "12222").getBeanDefinition();
registry.registerBeanDefinition("userconfig",beanDefinition);
}
}
四、复杂运行
Mybatis的@MapperScan就是用这种方式实现的@MapperScan注解指定basePackages扫描Mybatis Mapper接口类注入到容器中。
1.这里我们自定义一个注解@MyMapperScan来扫描包路径下所以带@MyMapperBean注解的类并将它们注入到IOC容器中。
package com.example.eureka.exmple;
import org.springframework.context.annotation.Import;
import java.lang.annotation.*;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Import(MyMapperBeanImport.class)
public @interface MyMapperScan {
/**
* 扫描包路径
*/
String[] basePackages() default {};
}
2.定义MyMapperBean注解
package com.example.eureka.exmple;
import java.lang.annotation.*;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
public @interface MyMapperBean {
}
3.定义ImportBeanDefinitionRegister的实现类
package com.example.eureka.exmple;
import org.springframework.beans.factory.support.BeanDefinitionRegistry;
import org.springframework.context.ResourceLoaderAware;
import org.springframework.context.annotation.ClassPathBeanDefinitionScanner;
import org.springframework.context.annotation.ImportBeanDefinitionRegistrar;
import org.springframework.core.annotation.AnnotationAttributes;
import org.springframework.core.io.ResourceLoader;
import org.springframework.core.type.AnnotationMetadata;
import org.springframework.core.type.filter.AnnotationTypeFilter;
public class MyMapperBeanImport implements ImportBeanDefinitionRegistrar, ResourceLoaderAware {
private final static String PACKAGE_NAME_KEY="basePackages";
private ResourceLoader resourceLoader;
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
AnnotationAttributes annotationAttributes = AnnotationAttributes.fromMap(importingClassMetadata.getAnnotationAttributes(MyMapperScan.class.getName()));
if(annotationAttributes ==null||annotationAttributes.isEmpty() ){
return;
}
String[] basePackages =(String[]) annotationAttributes.get(PACKAGE_NAME_KEY);
ClassPathBeanDefinitionScanner scanner=new ClassPathBeanDefinitionScanner(registry,false);
scanner.setResourceLoader(resourceLoader);
//路径包含MapperBean的注解的bean
scanner.addIncludeFilter(new AnnotationTypeFilter(MyMapperBean.class));
scanner.scan(basePackages);
}
@Override
public void setResourceLoader(ResourceLoader resourceLoader) {
this.resourceLoader=resourceLoader;
}
}
4.测试
package com.example.eureka.exmple;
import com.example.eureka.exmple.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;
@Component
public class TestRunnerApi2 implements ApplicationRunner {
@Autowired
private UserMapper userMapper;
@Override
public void run(ApplicationArguments args) throws Exception {
userMapper.select("user");
}
}
11.SpringBoot自动装配的流程是怎样的?
12.谈谈Sentienl服务熔断的过程?
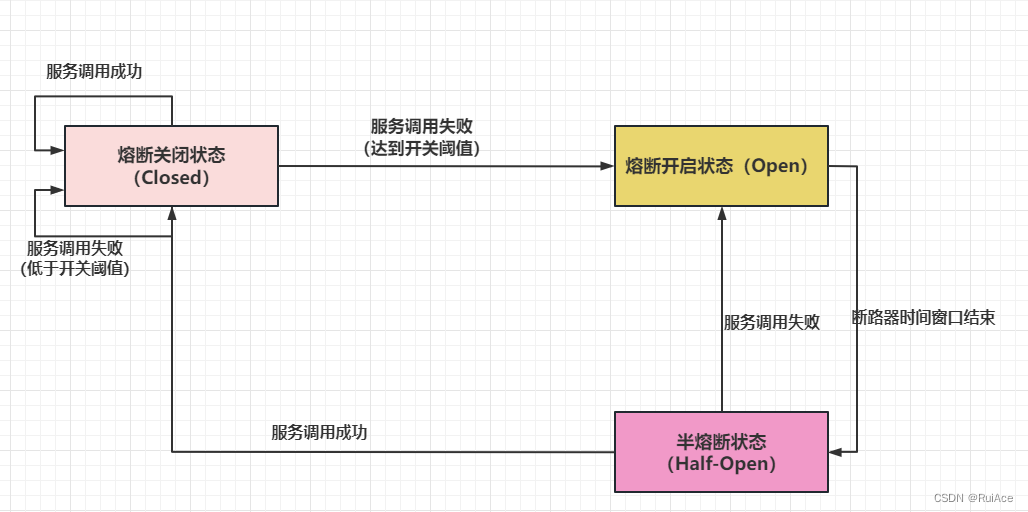
服务熔断一般有三种状态
-
熔断关闭状态Closed
服务没有故障时熔断器所处的状态对调用方的调用不做任何限制 -
熔断开启状态Open
后续对该服务接口的调用不再经过网络直接执行本地的fallback方法 -
半熔断状态Half-Open
尝试恢复服务调用运行有限的流量调用该服务并监控调用的成功率。如果成功率达到预期则说明服务已恢复进入熔断关闭状态如果成功率仍旧很低则重新进入熔断关闭状态。
13.谈谈Sentienl中使用的限流算法
-
1.计数器算法
计数器算法是限流算法中最简单也最容易实现的算法。它使用计数器在周期内累加访问次数当达到设定的限流值时触发限流策略。下一周期开始清零重新计数。举个例子一个接口在1s内的负载限值为100开始时设定一个计数器count=0来一个请求count+11min内count<=100就能正常访问count>100的请求就会被拒绝。
计数器算法的弊端在于只有最开始的100个请求能被访问其余在限制时间内都不能访问。也就是突刺现象。这时就可以用滑动窗口算法解决这个问题。
突刺现象是指在一定时间内的一小段时间内就用完了所有资源后大部分时间中无资源可用。
-
2.滑动窗口算法
滑动窗口算法也是Sentinel的默认算法。滑动窗口算法是将时间周期分为n个小周期分别记录每个小周期内的访问次数 并且根据时间滑动删除过期的小周期。假设时间周期为1min将1min再分割成2个小周期统计每个小周期的访问数量则可以看到第一个时间周期内访问数量为75第二个时间周期内访问数量为100超过100的数量被限流掉了。
由此可见当滑动窗口格子划分得越多那么滑动窗口的滚动就越平滑限流的统计就越精确。可以很好的解决固定窗口的流动问题。 -
3.漏桶算法
漏桶算法是将访问请求放入漏桶中当请求达到限流值则进行丢弃触发限流策略。无论有多少请求请求的速率有多大都按照固定的速率流出对应到系统中就是按照固定的速率处理请求。超过漏桶容量的直接抛弃。 -
4.令牌算法
令牌桶其实和漏桶的原理类似令牌桶按固定的速率往桶里放入令牌并且只要能从桶里取出令牌就能通过令牌桶支持突发流量的快速处理。限流算法比较
(1)计数器算法
优点分布式中实现难度低缺点不能平滑限流存在临界问题前一个周期的最后几秒和下一个周期的开始几秒时间段内访问量很大但没超过周期量计数量时但短时间请求量依旧很高。
(2)令牌桶和漏桶区别
主要区别在于“漏桶算法”能够强行限制数据的传输速率而“令牌桶算法”在能够限制数据的平均传输速率外还允许某种程度的突发传输。在“令牌桶算法”中只要令牌桶中存在令牌那么就允许突发地传输数据直到达到用户配置的门限因此它适合于具有突发特性的流量。
14.在GateWay中怎么实现服务的平滑迁移?
使用Weight路由的断言工厂进行服务权重的配置并将配置放到Nacos配置中心进行动态迁移。
Weight路由断言工厂
规则
该断言工厂中包含两个参数分别是用于表示组 group与权重 weight。对于同一组中的多个uri地址路由器会根据设置的权重按比例将请求转发给相应的uri实现负载均衡。
group组权重根据组来计算
weight 权重值是一个int的数值
spring:
cloud:
gateway:
routes:
- id: weight_high
uri: https://www.baidu.com
predicates:
- Weight=group1,8
- id: weight_low
uri: https://www.baidu.com
predicates:
- Weight=group1,2
15.Seata支持哪些事务模式?
Seata目前支持以下四种分布式事务模式
XA 模式强一致性的两阶段提交协议需要数据库支持XA接口牺牲了一定的可用性无业务侵入。
AT 模式最终一致性的两阶段提交协议通过自动补偿机制实现数据回滚无业务侵入也是Seata的默认模式。
TCC 模式最终一致性的两阶段提交协议需要业务实现Try、Confirm和Cancel三个操作有业务侵入灵活度高。
SAGA 模式长事务模式通过状态机编排或者注解方式实现业务逻辑需要业务实现正向和反向两个操作有业务侵入。
16.请简述2PC流程及其优缺点?
2PCTwo Phase Commitment Protocol当一个事务操作需要跨越多个分布式节点的时候为了保持事务处理的 ACID特性就需要引入一个“协调者”TM来统一调度所有分布式节点的执行逻辑这些被调度的分布式节点被称为 AP。TM 负责调度 AP 的行为并最终决定这些 AP 是否要把事务真正进行提交因为整个事务是分为两个阶段提交所以叫 2PC
二阶段提交协议将事务提交分为两个阶段来进行处理其执行流程过程如下
-
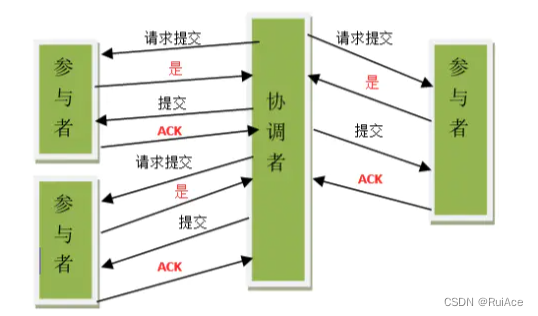
阶段一提交事务请求
1.事务询问
协调者向所有的参与者发送事务内容询问是否可以执行事务提交操作并开始等待各参与者的响应
2.执行事务
各个参与者节点执行事务操作并将 Undo 和 Redo 信息记录到事务日志中尽量把提交过程中所有消耗时间的操作和准备都提前完成确保后面 100%成功提交事务各个参与者向协调者反馈事务询问的响应:
如果各个参与者成功执行了事务操作那么就反馈给参与者yes 的响应表示事务可以执行
如果参与者没有成功执行事务就反馈给 协调者 no 的响应表示事务不可以执行
上面这个阶段有点类似协调者组织各个参与者对一次事务操作的投票表态过程因此 2PC 协议的第一个阶段称为“投票阶段”即各参与者投票表明是否需要继续执行接下去的事务提交操作` -
阶段二执行事务提交
在这个阶段协调者会根据各参与者的反馈情况来决定最终是否可以进行事务提交操作正常情况下包含两种可能:执行事务提交、中断事务1.执行事务提交
当协调者节点从所有参与者节点获得的相应消息都为”yes”响应时那么就会执行事务提交
(1).发送提交请求
协调者节点向所有参与者节点发出commit的请求。
(2).事务提交
参与者节点接收到commit请求后会正式执行事务提交操作并在完成提交之后释放整个事务期间内占用的资源。
(3).反馈事务提交结果
参与者节点在完成事务提交之后向协调者发送ack消息
(4).完成事务
协调者节点接收到所有参与者节点反馈的ack消息后完成事务。
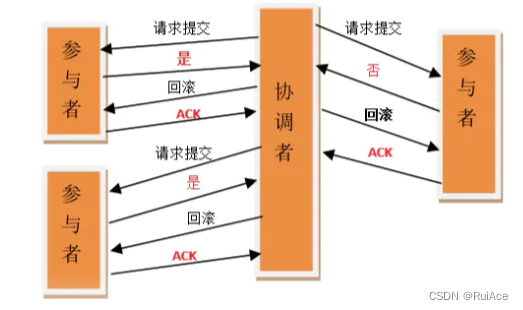
2.中断事务
如果任一参与者节点在第一阶段返回的响应消息为NO相应或者等待超时之后协调者节点尚无法接收到所有参与者的反馈响应那么就会中断事务
(1).发送回滚请求
协调者节点向所有参与者节点发出rollback的请求。
(2).事务回滚
参与者节点利用之前写入的Undo信息执行回滚并释放在整个事务期间内占用的资源。
(3).反馈事务回滚结果
参与者节点向协调者节点发送”回滚完成”之后向协调者发送Ack消息
(4).中断事务
协调者接收到所有参与者反馈的ack消息后完成事务中断
优点2PC的优点是很显然的原理简单实现方便。
目前绝大多数关系型数据库都是采用两阶段提交协议来完成分布式事务处理的。
缺点2PC的缺点也很致命同步阻塞单点问题数据不一致太过保守
- 1、同步阻塞问题。
在二级段提交的执行过程中所有参与该事务操作的逻辑的都在阻塞状态也就是说各个参与者在等待其他参与者响应的过程中将无法进行其他的任务操作 - 2、单点故障。
协调者的角色在整个二级段提交协议中起到了非常重要的作用一旦协调者出现问题那么整个第二阶段提交流程将无法运转更为严重的是协调者在阶段二中出现问题的话那么其他的参与者将会处于锁定事务资源的状态中而无法继续完成事务操作。 - 3.数据不一致
在二阶段提交的阶段二中即提交事务提交的时候当协调者向参与者发送commit请求之后发生了局部网络异常或者在发送commit请求过程中协调者发生了故障这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。 - 4、太过保守
如果在协调者指示参与者进行事务提交询问的过程中参与者出现故障而导致协调者始终无法获取到所有参与者的响应的消息的话这时协调者只能依靠其自身的超时机制来判断是否中断事务这样的策略比较保守换句话说二阶段提交协议没有设计相应的容错机制当任意一个参与者节点宕机那么协调者超时没收到响应就会导致整个事务回滚失败。
17.Seata中,xid在Feign中怎么进行全局传递
1.Feign的调用String xid = RootContext.getXID(); 获取xid,并添加到header请求头中.
Seata对feign的client做了一层wrap,在execute http请求的基础上设置了Http Header.
public class SeataFeignClient implements Client {
private final Client delegate;
private final BeanFactory beanFactory;
private static final int MAP_SIZE = 16;
SeataFeignClient(BeanFactory beanFactory) {
this.beanFactory = beanFactory;
this.delegate = new Client.Default((SSLSocketFactory)null, (HostnameVerifier)null);
}
SeataFeignClient(BeanFactory beanFactory, Client delegate) {
this.delegate = delegate;
this.beanFactory = beanFactory;
}
public Response execute(Request request, Request.Options options) throws IOException {
Request modifiedRequest = this.getModifyRequest(request);
return this.delegate.execute(modifiedRequest, options);
}
private Request getModifyRequest(Request request) {
String xid = RootContext.getXID();
if (StringUtils.isEmpty(xid)) {
return request;
} else {
Map<String, Collection<String>> headers = new HashMap(16);
headers.putAll(request.headers());
List<String> seataXid = new ArrayList();
seataXid.add(xid);
headers.put("TX_XID", seataXid); //设置xid
return Request.create(request.method(), request.url(), headers, request.body(), request.charset());
}
}
}
2.服务端,从header请求头中获取xid,绑定到Rootcontext中.Spring-webmvc使用的是HandlerInterceptor进行拦截绑定xid.
public class SeataHandlerInterceptor implements HandlerInterceptor {
private static final Logger log = LoggerFactory.getLogger(SeataHandlerInterceptor.class);
public SeataHandlerInterceptor() {
}
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
String xid = RootContext.getXID();
String rpcXid = request.getHeader("TX_XID");//从header中获取xid
if (log.isDebugEnabled()) {
log.debug("xid in RootContext {} xid in RpcContext {}", xid, rpcXid);
}
if (StringUtils.isBlank(xid) && rpcXid != null) {
RootContext.bind(rpcXid);
if (log.isDebugEnabled()) {
log.debug("bind {} to RootContext", rpcXid);
}
}
return true;
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception e) {
if (StringUtils.isNotBlank(RootContext.getXID())) {
String rpcXid = request.getHeader("TX_XID");
if (StringUtils.isEmpty(rpcXid)) {
return;
}
String unbindXid = RootContext.unbind();
if (log.isDebugEnabled()) {
log.debug("unbind {} from RootContext", unbindXid);
}
if (!rpcXid.equalsIgnoreCase(unbindXid)) {
log.warn("xid in change during RPC from {} to {}", rpcXid, unbindXid);
if (unbindXid != null) {
RootContext.bind(unbindXid);
log.warn("bind {} back to RootContext", unbindXid);
}
}
}
}
}
18.分布式事务应用的典型场景?
随着互联网的快速发展软件系统由原来的单体应用转变为分布式应用.
分布式系统会把一个应用系统拆分为可独立部署的多个服务因此需要服务与服务之间远程协作才能完成事务操作这种分布式系统环境下由不同的服务之间通过网络远程协作完成事务称之为分布式事务例如用户注册送积分事务、创建订单减库存事务银行转账事务等都是分布式事务。
分布式事务产生的场景
1、典型的场景就是微服务架构 ,微服务之间通过远程调用完成事务操作。 比如订单微服务和库存微服务下单的同时订单微服务请求库存微服务减库存。 简言之跨JVM进程产生分布式事务。
2、单体系统访问多个数据库实例 当单体系统需要访问多个数据库实例时就会产生分布式事务。 比如用户信息和订单信息分别在两个MySQL实例存储用户管理系统删除用户信息需要分别删除用户信息及用户的订单信息由于数据分布在不同的数据实例需要通过不同的数据库链接去操作数据此时产生分布式事务。 简言之跨数据库实例产生分布式事务。
3、多服务访问同一个数据库实例 比如订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务原因就是跨JVM进程两个微服务持有了不同的数据库链接进行数据库操作此时产生分布式事务。
19.Ribbon底层怎样实现不同服务的不同配置
为不同服务创建不同的Spring上下文不同的Spring上下文中存放对应这个服务所有的配置
SpringClientFactory中可以获取到所有Ribbon中的信息
public class SpringClientFactory extends NamedContextFactory<RibbonClientSpecification> {
static final String NAMESPACE = "ribbon";
public SpringClientFactory() {
super(RibbonClientConfiguration.class, "ribbon", "ribbon.client.name");
}
// ...... 省略部分代码
public IClientConfig getClientConfig(String name) {
//获取配置信息
return (IClientConfig)this.getInstance(name, IClientConfig.class);
}
public <C> C getInstance(String name, Class<C> type) {
C instance = super.getInstance(name, type);
if (instance != null) {
return instance;
} else {
IClientConfig config = (IClientConfig)this.getInstance(name, IClientConfig.class);
return instantiateWithConfig(this.getContext(name), type, config);
}
}
}
//获取配置的父类代码
public abstract class NamedContextFactory<C extends Specification> implements DisposableBean, ApplicationContextAware {
// ...... 省略部分代码
public <T> T getInstance(String name, Class<T> type) {
//从Spring容器中获取上下文信息
AnnotationConfigApplicationContext context = this.getContext(name);
try {
return context.getBean(type);
} catch (NoSuchBeanDefinitionException var5) {
return null;
}
}
}
20.Ribbon的属性配置和类配置那个优先级高
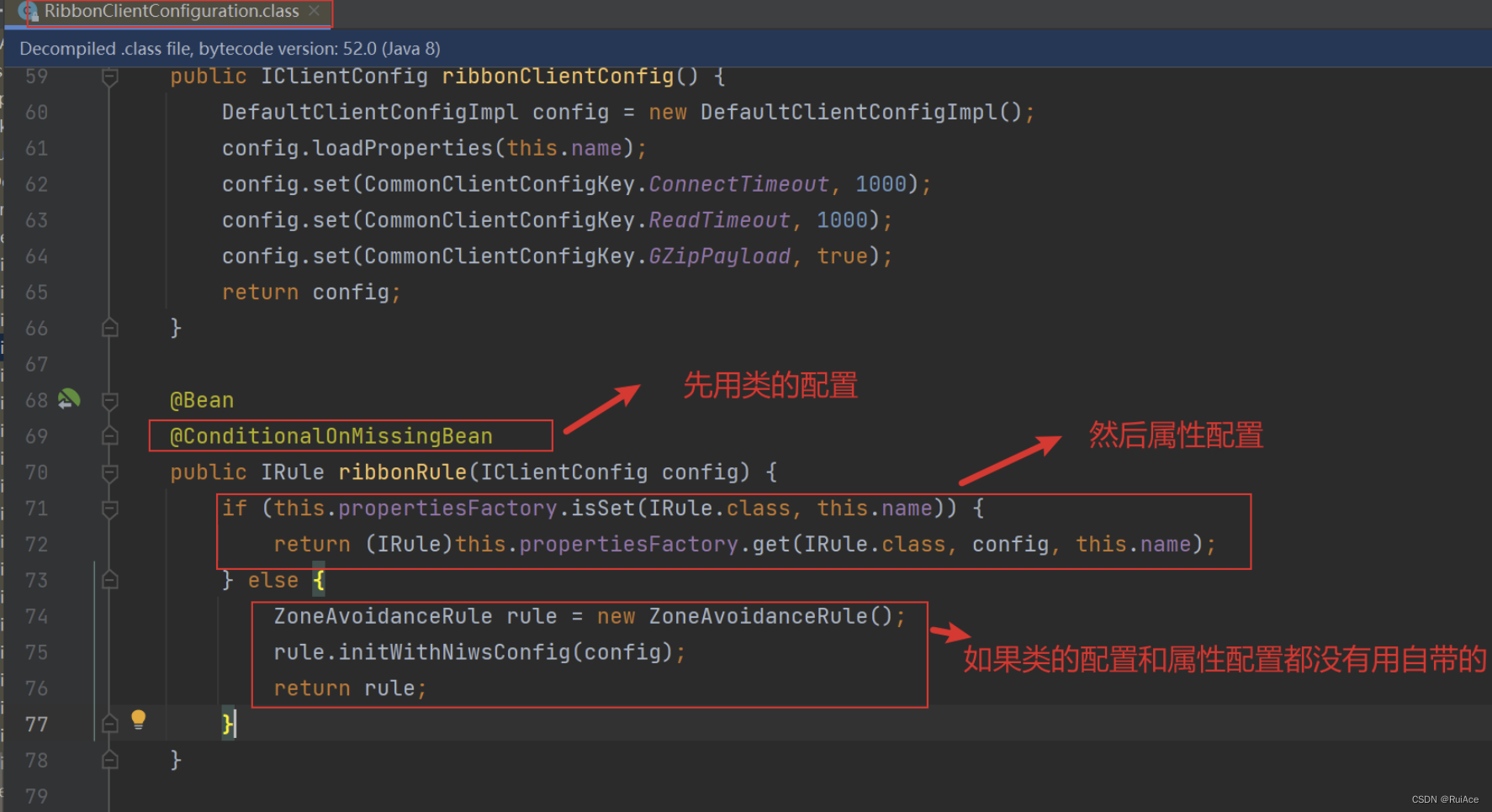
类配置优先级高
通过RibbonClientConfiguration类中的ribbonRule方法可知优先使用类配置然后属性配置最后如果类配置和属性配置都没有使用,则使用Ribbon自带的默认配置
21.为什么Feign第一次调用耗时很长
首先要了解Feign是如何进行远程调用的这里面包括注册中心、负载均衡、FeignClient之间的关系微服务通过不论是eureka、nacos也好注册到服务端Feign是靠Ribbon做负载的而Ribbon需要拿到注册中心的服务列表将服务进行负载缓存到本地然后FeignClient客户端在进行调用大概就是这么一个过程。
Ribbon默认是懒加载的,只有第一次调用的时候才会生成Ribbon对应的组件,这就导致首次调用的会很慢.
可以通过将超时时间改长,或者禁用超时;
如果是SpringCloud Finchley.SR2以上的版本可以通过配置earger-load 进行初始化客户端
ribbon.eager-load.enabled:代表是否开启Ribbon的饥饿加载模式;
ribbon.earger-load.clients: 指定需要饥饿加载的服务名称,多个用逗号隔开
ribbon:
eager-load:
enabled: true
clients: order-service,org-service
22.Feign性能优化?
1. 设置合理的日志
OpenFeign提供了日志打印的功能我们可以调整日志的输出级别去了解OpenFeign的http请求的细节。即对OpenFeign远程接口调用的情况进行监控和日志输出。
OpenFeign的日志级别
NONE默认级别不显示日志
BASIC仅记录请求方法、URL、响应状态及执行时间
HEADERS除了BASIC中定义的信息之外还有请求和响应头信息
FULL除了HEADERS中定义的信息之外还有请求和响应正文及元数据信息
OpenFeign的默认日志级别为NONE不记录任何请求信息SpringBoot默认的日志级别是info,而FeignClient日志级别是debug,debug<info。所以当我们修改完FeignClient的日志级别后需要修改SpringBoot的日志级别为debug日志输出才会生效。
feign:
client:
config:
default: #表示所有的feign 也可以写具体的feign
loggerLevel: full #开启feign日志
logging:
level:
com.xxx.feign: debug
2.http连接池的配置
Feign默认使用HttpURLConnection去发送请求每次请求都会建立、关闭连接很消耗时间。但是Feign还支持使用Apache的HttpClient 以及OKHTTP去发送请求其中Apache的HTTPClient和OKHTTP都是支持连接池的。
3.gzip压缩
减少文件大小有两个明显的好处一是可以减少存储空间二是通过网络传输文件时可以减少传输的时间。gzip 是在 Linux 系统中经常使用的一个对文件进行压缩和解压缩的命令既方便又好用。
介绍Gzip是若干种文件压缩程序的简称是一种数据可是采用DEFLATE无损数据压缩算法。
作用Gzip压缩纯文本是的效果非常好可以减少70以上的文件大小压缩后可以大大降低了网络传输的字节数使用Gzip的好处就是可以加快网页加载的速度
#项目中启用gzip压缩1和2两过程可以只开一个压缩也可以两个过程都开压缩
# 1浏览器和consumer之间的压缩
server:
compression: #是否开启压缩
enabled: true #浏览器<------>consumer的gzip压缩
#配置支持的压缩mime-types 下面的是默认值可以不写
mime-types: text/html,text/xml,text/plain,application/xml,application/json
# 2consumer与provider之间的压缩
feign:
compression:
request:
enabled: true #consumer<------>provider的gzip压缩
#配置支持的压缩mime-types 下面的是默认值可以不写
mime-types: text/html,text/xml,text/plain,application/xml,application/json
response:
enabled: true
4.Feign超时时长设置
ribbon:
ConnectionTimeout: 5000
ReadTimeout: 5000
#或者是
# client:
# config:
# default:
# Feign-provider: #具体的某个服务的超时配置
# ConnectionTimeout: 5000
# ReadTimeout: 5000
23.在Feign中怎么实现认证的传递
方法一:
实现RequestInterceptor接口,通过header实现认证传递
public interface RequestInterceptor {
void apply(RequestTemplate var1);
}
public class TokenRequestIntecepor implements RequestInterceptor {
@Override
public void apply(RequestTemplate requestTemplate) {
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes srat = (ServletRequestAttributes) requestAttributes;
HttpServletRequest request = srat.getRequest();
String token = request.getHeader("token");
if (StringUtils.isNotBlank(token)) { //将token传递出去
requestTemplate.header("token", token);
}
}
}
先获取到HTTPServletRequest
接着在从request中获取到header的“token”
将这个token传递给requestTemplate
Interceptor实现之后还需要对这个Interceptor设置配置
并在Feign中添加相关配置
feign:
client:
config:
default:
loggerLevel: full
requestInterceptors:
- com.example.feigndemo.interceptor.TokenRequestIntecepor
方法二:
在请求调用方的微服务方法头中添加@RequestHeader用来接收用户端请求时传入的token
@RequestMapping("/deleteByOpenId")
public Object deleteByOpenId(@RequestParam("opendId") String opendId, @RequestHeader("token") String token) {
Object integer = appMpLoginAuthFeginClient.deleteByOpenId(opendId, token);
return integer;
}
这里获取到header中的“token”
在采用Feign调用其他微服务时将获取到的Token传入到下一个微服务的请求头中
@RequestMapping("/rest/user-service/in/mpLoginAuth/deleteByOpenId")
Object deleteByOpenId(@RequestParam("opendId") String opendId, @RequestHeader("token") String token);
这里的@RequestHeader的意思是将参数token放入到下个请求的请求头header中。
24.nacos服务领域模型(数据模型)有哪些
Namespace命名空间、 Group分组、集群这些都是为了进⾏归类管理把服务和配置⽂件进⾏归类
归类之后就可以实现⼀定的效果⽐如隔离
对于服务来说不同命名空间中的服务不能够互相访问调⽤
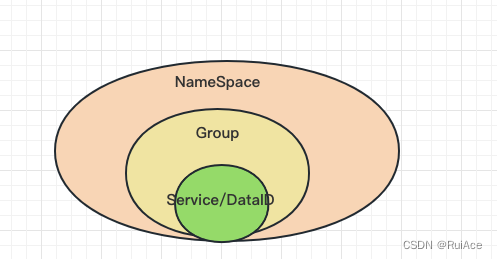
Namespace命名空间对不同的环境进⾏隔离⽐如隔离开发环境、测试环境和⽣产环境
Group分组将若⼲个服务或者若⼲个配置集归为⼀组通常习惯⼀个系统归为⼀个组
Service某⼀个服务⽐如简历微服务
DataId配置集或者可以认为是⼀个配置⽂件
25.Nacos中的Distro协议
Distro它是 Nacos 社区自研的一种 AP 分布式协议也是最终一致性协议。它面向临时实例保证了在某些 Nacos 节点宕机后整个临时实例处理系统依旧可以正常工作。作为一种有状态的中间件应用的内嵌协议Distro 保证了各个 Nacos 节点对于海量注册请求的统一协调和储。
设计思想如下
Nacos 每个节点都是平等的都可以处理写请求同时把新数据同步到其它节点。每个节点只负责部分数据定时发送自己负责数据的校验值到其它节点来保持数据一致性。每个节点独立处理读请求及时从本地发出响应。
数据初始化(源码参考 DistroConsistencyServiceImpl)
新加入的 Distro 节点会进行全量数据拉取。轮询所有的 Distro 节点通过向其它机器发送请求拉取全量数据。
在全量拉取操作完成之后Nacos 的每台机器上都维护了当前的所有注册的临时实例数据。
数据校验(源码参考 TimedSync)
在 Distro 集群启动之后每台机器会定期发送心跳。心跳信息主要为各个机器上的所有数据的元数据。这种数据校验会以心跳的形式进行即每台机器在固定时间间隔默认 5 秒会向其它机器发起一次数据校验请求。
一旦在数据校验过程中某台机器发现其它机器上的数据与本地数据不一致则会发起一次全量拉取请求将数据补齐。
写数据(源码参考 DistroConsistencyServiceImpl、DistroFilter、TaskScheduler)
对于一个已经启动的 Distro 集群在一次客户端发起写操作的流程中当注册临时实例的写请求打到某台 Nacos 服务器时Distro 集群的处理流程如下
前置的 Filter 拦截请求并根据请求中的包含的 IP 和 port 信息计算其所属的 Distro 责任节点。当该节点接收到不属于该节点负责的实例的写请求时将在集群内部路由转发给对应的节点从而完成读写。
责任节点上的 Controller 将写请求进行解析。
Distro 协议定期执行 sync 任务将本机所负责的所有实例信息同步到其它节点上。
读数据
由于每台机器上数据存储在缓存中都存放了全量数据因此在每一次读操作中Distro 机器会直接从本地拉取数据快速响应。这种机制保证了 Distro 协议可以作为一种 AP 协议对于读操作可以及时响应即使出现网络分区的情况下也能正常返回。等到网络恢复时各个 Distro 节点会把各数据分片的数据进行合并恢复。
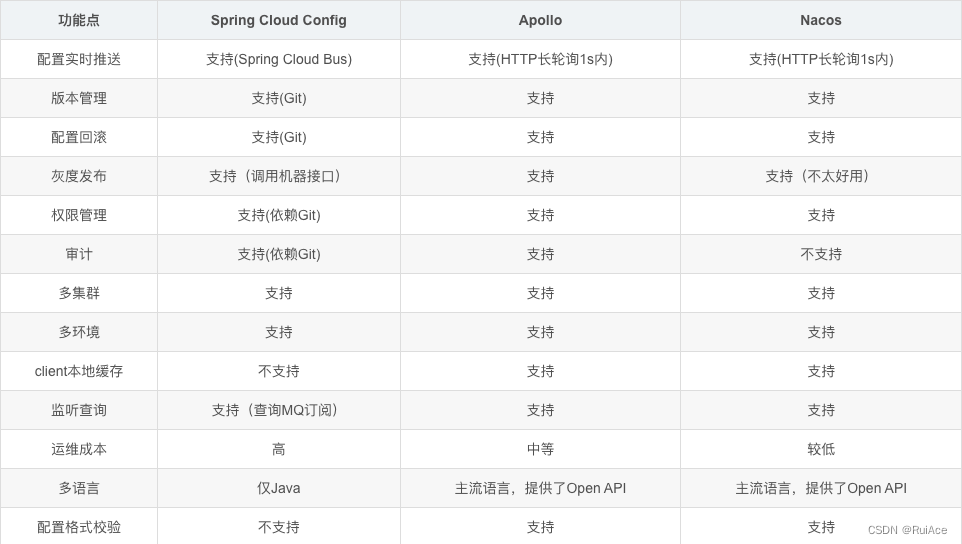
26.配置中心的技术选型
1、Spring Cloud Config
2014年9月开源Spring Cloud 生态组件可以和Spring Cloud体系无缝整合。Spring Cloud Netfix生态常用
2、携程 Apollo
2016年5月携程开源的配置管理中心具备规范的权限、流程治理等特性
3、Spring Cloud Alibaba生态Nacos
2018年6月阿里开源的配置中心也可以做DNS和RPC的注册中心与服务发现。Spring Cloud Alibaba生态常用
27.Nacos1.x 配置中心长轮询机制
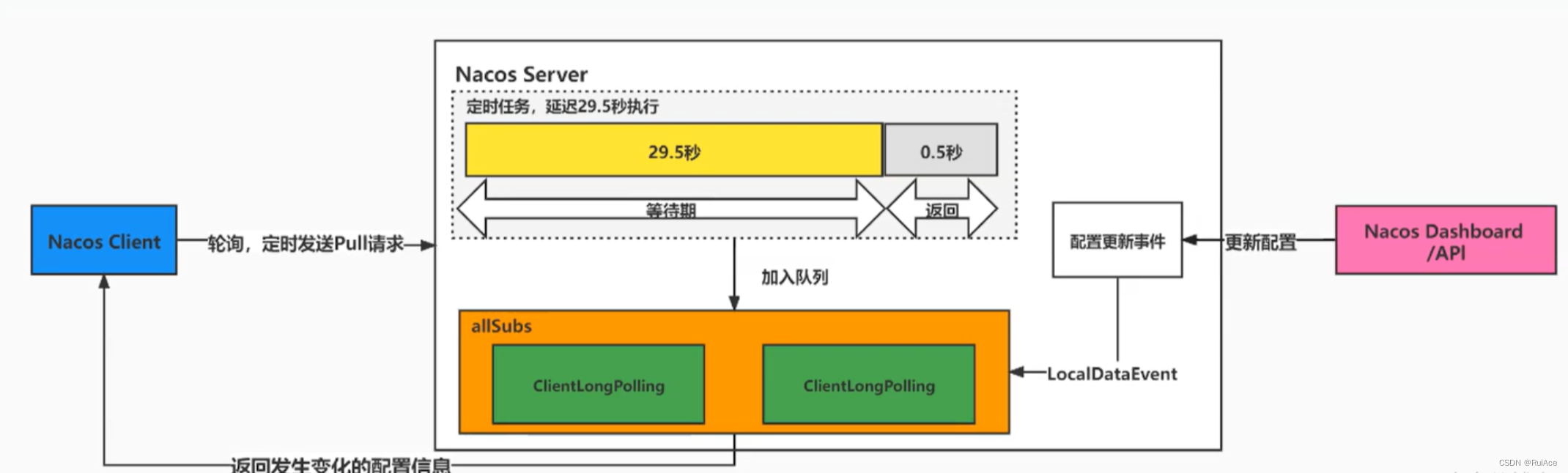
客户端会轮询向服务端发出一个长连接请求这个长连接最多30s就会超时服务端收到客户端的请求会先判断当前是否有配置更新有则立即返回;如果没有,服务端会将这个请求拿住“hold”29.5s加入队列最后0.5s再检测配置文件无论有没有更新都进行正常返回但等待的29.5s期间有配置更新可以提前结束并返回。
28.Nacos1.x 作为注册中心的原理
Nacos致力于解决微服务中的统一配置服务注册和发现等问题。Nacos集成了注册中心和配置中心。其相关特性包括
- 服务发现和服务健康监测
- 动态配置服务
- 动态 DNS 服务
- 服务及其元数据管理
服务实例启动时注册到服务注册表、关闭时则注销服务注册。
服务消费者可以通过查询服务注册表来获得可用的实例服务发现。
服务注册中心需要调用服务实例的健康检查API来验证其是否可以正确的处理请求健康检查。
Nacos服务注册和发现的实现原理的图如下
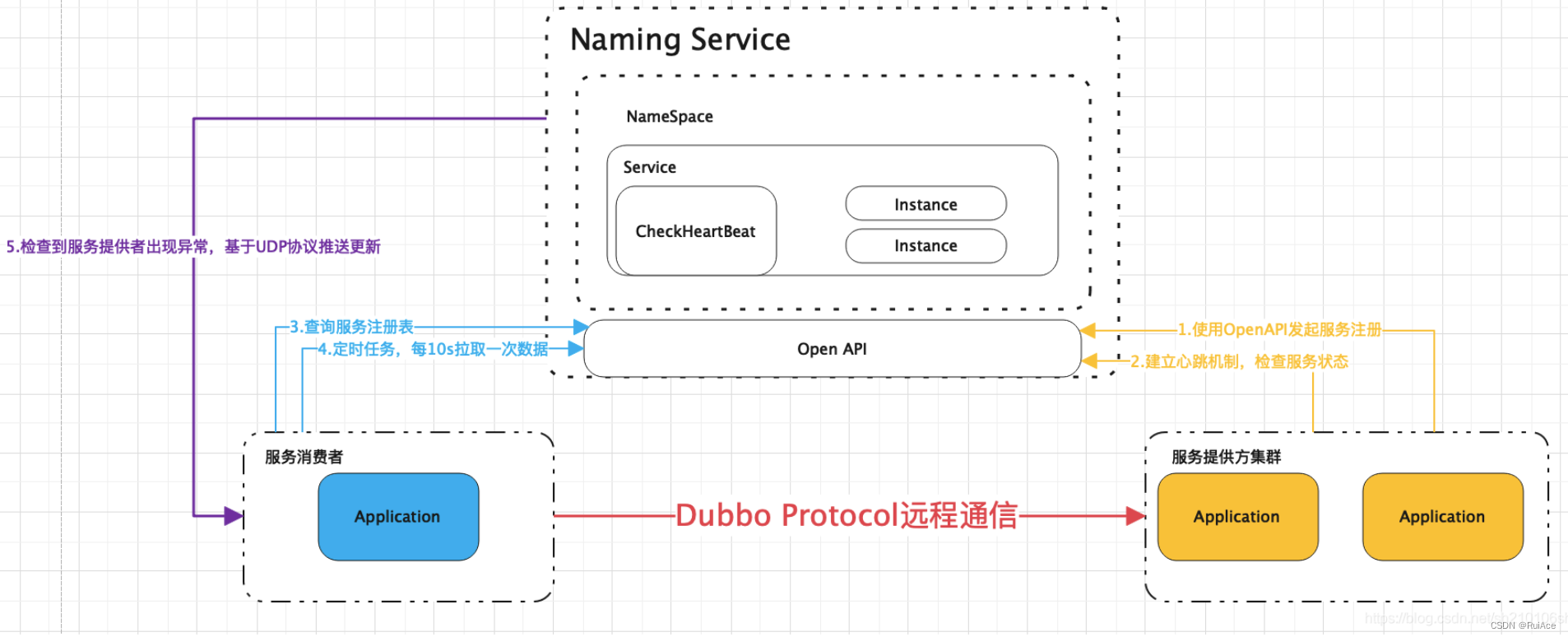
29.Nacos配置中心配置优先级
Nacos配置中心配置优先级优先级从1.1到1.5由低到高递增
1.1、应用名+环境变量名.文件扩展名
语法
a
p
p
l
i
c
a
t
i
o
n
.
n
a
m
e
−
{application.name}-
application.name−{profile}.${file-extension}
示例: nacos-config-prod.yaml
1.2、应用名.文件扩展名
语法
a
p
p
l
i
c
a
t
i
o
n
.
n
a
m
e
.
{application.name}.
application.name.{file-extension}
示例: nacos-config.yaml
1.3、应用名
语法${application.name}
示例: nacos-config
1.4、扩展配置文件
语法extensionConfigs
示例:
#支持一个应用有多个DataId配置mybatis.yaml datasource.yaml
spring.cloud.nacos.config.extension-configs[o].data-id=datasource.yaml
spring.cloud.nacos.config.extension-configs[o].group=DEFAULT_GROUP
spring.cloud.nacos.config.extension-configs[o].refresh=true
1.5、多个微服务公共配置
语法sharedConfigs
示例:
#自定义Data Id的配置 共享配置 (sharedcenfigs)
spring.cloud.nacos.config.shared-configs[o].data-id= common.yaml
#可以不配置使用默认
spring.cloud.nacos.config.shared-configs[o].group=DEFAULT_GROUP
#这里需要设置为true动态可以刷新默认为false
spring.cloud.nacos.config.shared-configs[o].refresh=true
29.Nacos2.x 客户端探活机制
Nacos2.0之后的架构有了很大的变化。其中临时实例的心跳机制变为了通过长连接来维持的设计。
官方对健康检查的设计说明:
OpenAPI 的注册方式实际是用户根据自身需求调用 Http 接口对服务进行注册然后通过 Http 接口发送心跳到注册中心。在注册服务的同时会注册⼀个全局的客户端心跳检测的任务。在服务⼀段时间没有收到来自客户端的心跳后该任务会将其标记为不健康如果在间隔的时间内还未收到心跳那么该任务会将其剔除。
SDK 的注册方式实际是通过 RPC 与注册中心保持连接Nacos 2.x 版本中旧版的还是仍然通过OpenAPI 的方式客户端会定时的通过 RPC 连接向 Nacos 注册中心发送心跳保持连接的存活。如果客户端和注册中心的连接断开那么注册中心会主动剔除该 client 所注册的服务达到下线的效果。同时 Nacos 注册中心还会在注册中心启动时注册⼀个过期客户端清除的定时任务用于删除那些健康状态超过⼀段时间的客户端。
简单来说Nacos在2.0之前是OpenAPI 的Http接口保持心跳。2.0之后如果采用的是SDKNacos Client注册的那么默认的是使用RPC长连接来保持心跳。
不管是OpenAPI还是RPC心跳设计都是一个原理。
首先客户端主动上报心跳刷新活跃时间。然后服务端有线程定时检查客户端的活跃时间。活跃时间超过限制的将会被服务器踢出。
所以接下来介绍Nacos的RPC心跳和Http心跳的时候主要介绍的就是5个点
- 主动上报心跳
- 刷新活跃时间
- 服务端定时检查活跃时间
- 服务器主动探测RPC长连接
- 清除不健康客户端
RPC长连接的心跳设计:
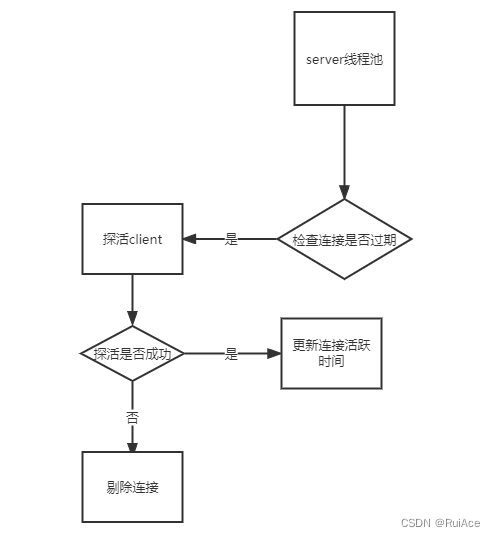
连接活跃检测的线程池为COMMON_SERVER_EXECUTOR
RPC长连接模式就是服务端把每一个连接都做了缓存。会有一个定时任务检查连接的活跃时间。与OpenAPI不同的是RPC模式不能自定义连接的不健康和需要删除的时间写死20s。
//ConnectionManager.java
private static final long KEEP_ALIVE_TIME = 20000L;
服务端健康检查大概流程。
为什么Nacos2.0会推出长连接Nacos官方文档给出了答案。
配置和服务器模块的数据推送通道不统⼀http 短连接性能压力巨大未来 Nacos 需要构建能够 同时支持配置以及服务的长链接通道以标准的通信模型重构推送通道。
30.如何设计一个注册中心
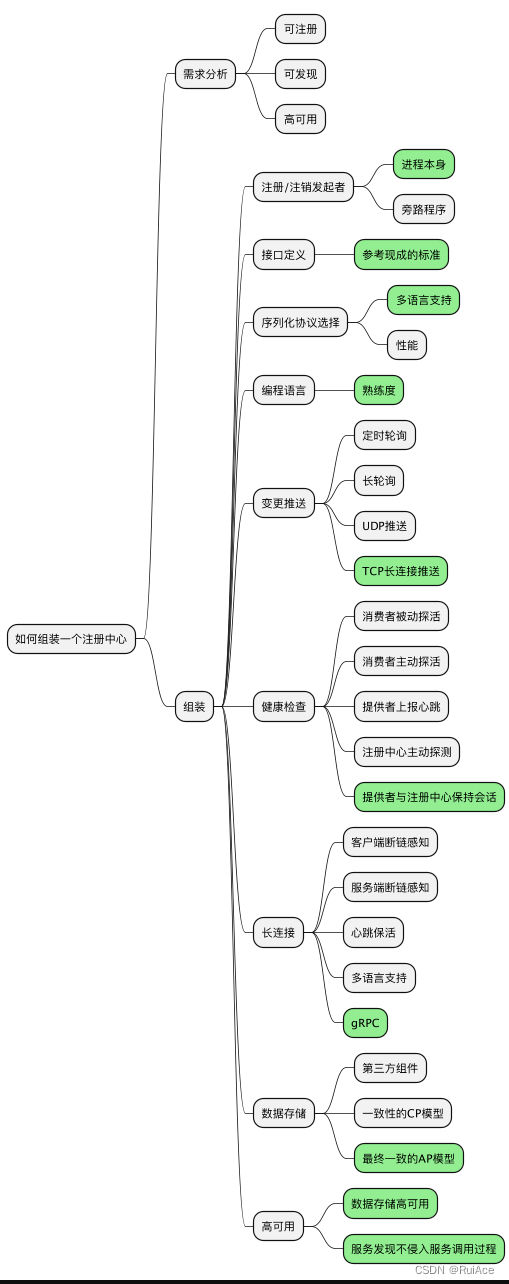
分布式环境下服务之间的调度消费者需要知道服务提供者的ip和port等参数。如果将ip和port等参数写死再消费者中那生成者的ip就不能变了。如今在云原生时代pod/容器没升级发版一次它的ip多将会产生变化。再把服务提供者的ip和port等参数写死就不可取了这是需要有个叫注册中心的中间件将服务提供者的ip、port信息注册到上面去供消费者动态获取、更新。
组装一个线上可用的注册中心最小集从需求分析出发每一步都有许多选择通过一些核心的技术选型来描绘出一个大致蓝图剩下的工作就是用代码将这些组装起来。
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |